Building application management systems in a distributed cluster infrastructure based on MESOS technology
Nowadays, the term “BIG DATA” is widely heard. After the appearance in the network and in the press of numerous publications related to the processing of "big data", interest in this topic is constantly growing. Database management systems with
using technology NoSQL. Everyone understands that in order to build “BIG DATA” systems it is necessary to have impressive hardware resources. It is even more important to be able to optimally use the computing resources of the system and effectively scale them. This inevitably changes the approach to building data processing systems. If earlier systems were built on the principle of centralizing the data warehouse, with which a set of powerful computing servers works, now this approach is gradually fading into the background. There are more and more systems built on the basis of a cluster of a large number of standard servers of medium power. There is no centralized storage in such a system. To work with data inside the cluster, a modular distributed storage system is used using the local disk resources of each server. If earlier scaling was carried out by adding disks to a centralized storage system and upgrading computing servers, now these same issues are solved simply by adding standard nodes to the cluster. This approach is gaining ground.
In the process of operating such systems, one often has to deal with problems of lack of computing resources at some nodes. There are situations when the load on the nodes of the cluster is distributed unevenly - one part of the nodes is idle, and the other is overloaded with various tasks. These problems can be solved "extensively" by adding more and more nodes to the cluster - which many, by the way, practice. However, it is possible to apply an “intensive” approach, optimizing the distribution of resources between various tasks and various cluster nodes.
One way or another, there has recently become an urgent need for a system capable of quickly and flexibly redistributing available resources in response to changing load conditions. In practice, to implement the above functions, the system must ensure the fulfillment of three main conditions:
The idea of creating a cluster management system with generalized computing resources some time ago was implemented by the Apache Foundation in a product called MESOS. This product allows you to just ensure the fulfillment of the first condition - to combine the computing resources of several hardware servers into one distributed set of resources, organizing a cluster computing system.

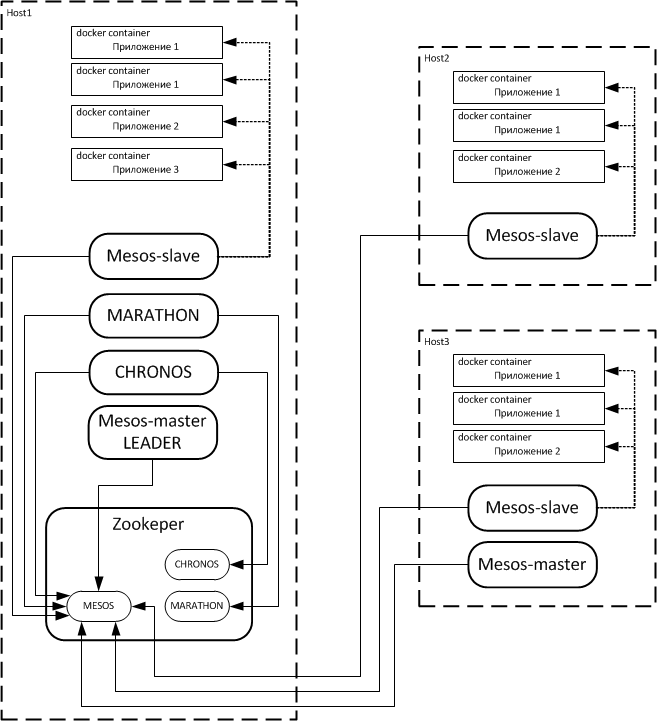
In a nutshell, how it works: on each node of the cluster, the MESOS service is launched, and it can work in two modes - mesos-master and mesos-slave. Thus, each cluster node receives either the mesos-slave role, or the mesos-master role, or both roles in place, which is also possible. Mesos-slave nodes are designed to run applications on a command received from the mesos-master node. The mesos-master nodes control the process of launching applications on the cluster nodes, thus ensuring that the second condition is fulfilled - they allow you to start an arbitrary application on an arbitrary cluster node. Mesos-master nodes are usually 2 or 3 to provide fault tolerance. Since by default both roles are launched on the node at the same time, it is advisable to disable the mesos-master role on most nodes. Interaction of mesos-slave and mesos-master nodes is carried out by means of Apache Zookeeper. The functionality of the Apache MESOS system can be flexibly expanded by integrating third-party applications into MESOS as frameworks.
The Apache MESOS key approach is that mesos-slave nodes take into account the free hardware resources available on them - CPU and RAM - telling mesos-master nodes about their number. As a result, mesos-master has complete information about the computing resources available on mesos-slave nodes. At the same time, he not only issues a slave command to the node to launch the application, but is also able to force the amount of computing resources that this application can have. This problem is solved using the application containerization mechanism. The process starts in the so-called. container - a closed operating environment. The basis of the container is the image file in which the OS kernel is installed, the root FS, all the necessary system libraries are deployed, and so on. When the container starts, the kernel of the system is launched from the image. After that, the application itself is launched in a dedicated, pre-prepared operating environment for it. It turns out a kind of virtual machine for one process. It is important that the use of containerization allows you to allocate for each container a fixed amount of RAM and a fixed number of CPU cores (including fractional, less than 1 - 0.5 cores, for example).

Thus, we can ensure the fulfillment of the third condition as well - we realize the ability to allocate to each task a certain amount of computing resources from a common set. It should be noted that initially Apache MESOS solved the stated problems using its own application containerization algorithms, however, after the docker product appeared on the market, the latter completely replaced the built-in Apache MESOS containerization tools. One way or another, at the moment, docker integration into solutions with Apache MESOS is widespread and is the de facto standard. Docker’s position in this area has been further strengthened thanks to the docker hub service, a system for the free distribution of containerized applications, ideologically similar to the well-known git-hub service. Using this service,
Now, if resources are exhausted on a mesos-slave node, the mesos-master node immediately “becomes aware” of it, and it cannot start the application on such a slave node. In this case, mesos-master will be forced to look for another, less loaded mesos-slave. This leads to the fact that tasks that are more demanding on the availability of computing resources will be “posted” to less loaded cluster nodes. Thus, we get a full-fledged cluster with generalized resources, which can set a certain amount of resources allocated to the application for work.
Unfortunately, the obvious drawback of Apache MESOS-based solutions is their focus on the simultaneous launch of one copy of the application on a separate cluster node, without monitoring the state of the application and without maintaining its performance on a long-term basis. However, this problem was recently solved by MESOSPHERE. MARATHON and CHRONOS products were introduced to the market. These products allow you to control the launch of applications in the Apache MESOS environment. Interacting through Apache zookeeper with mesos-master, they are built into its structures as frameworks, providing the system with new functionality. MARATHON is designed to run applications that must run continuously for a long time. It implements the capabilities of scale-up and monitoring of the operability of applications launched with its help. The set of standard MARATHON functions includes the ability to simultaneously launch an application instance on all cluster nodes, launch the application on a specific part of the cluster nodes, control the number of copies of the application running on one cluster node, and so on. CHRONOS, in turn, having similar functionality, is focused on launching one-time tasks on a schedule.
Both of these applications are equipped with their own management interface, which is implemented using the HTTP protocol and REST API technology. In fact, MARATHON stands between the user and mesos-master, accepting a request to launch the application using the REST API in JSON format. In the request, the user, among other things, can configure the total number of instances of the launched application on a cluster scale, the number of application instances per node, the number of system resources issued to each application instance, etc.
As mentioned above, many developers are starting to distribute their applications as docker containers. In particular, MESOSPHERE successfully uses this approach, as a result of which the MARATHON and CHRONOS applications discussed in this article are currently available as ready-made containers. Their use simplifies the process of servicing these subsystems, allows you to easily move them between cluster nodes, significantly speeds up the process of updating versions, and so on. The experience of our own developments, as well as the experience of third-party companies makes it possible to consider this approach as the most likely technology development trend in this industry.
To summarize, we can say that we have at our disposal a technology that can solve the problems formulated at the beginning of the article, fulfill three main requirements: provide the ability to transparently use the generalized computing resources of an IT system, provide the ability to run arbitrary tasks on an arbitrary node of the system, and to establish a mechanism for assigning a certain amount of computing resources from a common cluster set to each task separately.
In conclusion, it will not be out of place to note that the effectiveness of the approach described in the article is confirmed by the successful experience of implementing and operating the solutions developed using the technologies described above by several St. Petersburg IT companies.
The technologies discussed in this article are described in more detail.here .
using technology NoSQL. Everyone understands that in order to build “BIG DATA” systems it is necessary to have impressive hardware resources. It is even more important to be able to optimally use the computing resources of the system and effectively scale them. This inevitably changes the approach to building data processing systems. If earlier systems were built on the principle of centralizing the data warehouse, with which a set of powerful computing servers works, now this approach is gradually fading into the background. There are more and more systems built on the basis of a cluster of a large number of standard servers of medium power. There is no centralized storage in such a system. To work with data inside the cluster, a modular distributed storage system is used using the local disk resources of each server. If earlier scaling was carried out by adding disks to a centralized storage system and upgrading computing servers, now these same issues are solved simply by adding standard nodes to the cluster. This approach is gaining ground.
In the process of operating such systems, one often has to deal with problems of lack of computing resources at some nodes. There are situations when the load on the nodes of the cluster is distributed unevenly - one part of the nodes is idle, and the other is overloaded with various tasks. These problems can be solved "extensively" by adding more and more nodes to the cluster - which many, by the way, practice. However, it is possible to apply an “intensive” approach, optimizing the distribution of resources between various tasks and various cluster nodes.
One way or another, there has recently become an urgent need for a system capable of quickly and flexibly redistributing available resources in response to changing load conditions. In practice, to implement the above functions, the system must ensure the fulfillment of three main conditions:
- Provide the ability to combine the computing resources of individual servers into a common set.
- Provide the ability to run an arbitrary application on an arbitrary cluster node.
- Provide the ability to allocate computing resources from a common set to each task individually in a certain amount.
The idea of creating a cluster management system with generalized computing resources some time ago was implemented by the Apache Foundation in a product called MESOS. This product allows you to just ensure the fulfillment of the first condition - to combine the computing resources of several hardware servers into one distributed set of resources, organizing a cluster computing system.
In a nutshell, how it works: on each node of the cluster, the MESOS service is launched, and it can work in two modes - mesos-master and mesos-slave. Thus, each cluster node receives either the mesos-slave role, or the mesos-master role, or both roles in place, which is also possible. Mesos-slave nodes are designed to run applications on a command received from the mesos-master node. The mesos-master nodes control the process of launching applications on the cluster nodes, thus ensuring that the second condition is fulfilled - they allow you to start an arbitrary application on an arbitrary cluster node. Mesos-master nodes are usually 2 or 3 to provide fault tolerance. Since by default both roles are launched on the node at the same time, it is advisable to disable the mesos-master role on most nodes. Interaction of mesos-slave and mesos-master nodes is carried out by means of Apache Zookeeper. The functionality of the Apache MESOS system can be flexibly expanded by integrating third-party applications into MESOS as frameworks.
The Apache MESOS key approach is that mesos-slave nodes take into account the free hardware resources available on them - CPU and RAM - telling mesos-master nodes about their number. As a result, mesos-master has complete information about the computing resources available on mesos-slave nodes. At the same time, he not only issues a slave command to the node to launch the application, but is also able to force the amount of computing resources that this application can have. This problem is solved using the application containerization mechanism. The process starts in the so-called. container - a closed operating environment. The basis of the container is the image file in which the OS kernel is installed, the root FS, all the necessary system libraries are deployed, and so on. When the container starts, the kernel of the system is launched from the image. After that, the application itself is launched in a dedicated, pre-prepared operating environment for it. It turns out a kind of virtual machine for one process. It is important that the use of containerization allows you to allocate for each container a fixed amount of RAM and a fixed number of CPU cores (including fractional, less than 1 - 0.5 cores, for example).
Thus, we can ensure the fulfillment of the third condition as well - we realize the ability to allocate to each task a certain amount of computing resources from a common set. It should be noted that initially Apache MESOS solved the stated problems using its own application containerization algorithms, however, after the docker product appeared on the market, the latter completely replaced the built-in Apache MESOS containerization tools. One way or another, at the moment, docker integration into solutions with Apache MESOS is widespread and is the de facto standard. Docker’s position in this area has been further strengthened thanks to the docker hub service, a system for the free distribution of containerized applications, ideologically similar to the well-known git-hub service. Using this service,
Now, if resources are exhausted on a mesos-slave node, the mesos-master node immediately “becomes aware” of it, and it cannot start the application on such a slave node. In this case, mesos-master will be forced to look for another, less loaded mesos-slave. This leads to the fact that tasks that are more demanding on the availability of computing resources will be “posted” to less loaded cluster nodes. Thus, we get a full-fledged cluster with generalized resources, which can set a certain amount of resources allocated to the application for work.
Unfortunately, the obvious drawback of Apache MESOS-based solutions is their focus on the simultaneous launch of one copy of the application on a separate cluster node, without monitoring the state of the application and without maintaining its performance on a long-term basis. However, this problem was recently solved by MESOSPHERE. MARATHON and CHRONOS products were introduced to the market. These products allow you to control the launch of applications in the Apache MESOS environment. Interacting through Apache zookeeper with mesos-master, they are built into its structures as frameworks, providing the system with new functionality. MARATHON is designed to run applications that must run continuously for a long time. It implements the capabilities of scale-up and monitoring of the operability of applications launched with its help. The set of standard MARATHON functions includes the ability to simultaneously launch an application instance on all cluster nodes, launch the application on a specific part of the cluster nodes, control the number of copies of the application running on one cluster node, and so on. CHRONOS, in turn, having similar functionality, is focused on launching one-time tasks on a schedule.
Both of these applications are equipped with their own management interface, which is implemented using the HTTP protocol and REST API technology. In fact, MARATHON stands between the user and mesos-master, accepting a request to launch the application using the REST API in JSON format. In the request, the user, among other things, can configure the total number of instances of the launched application on a cluster scale, the number of application instances per node, the number of system resources issued to each application instance, etc.
As mentioned above, many developers are starting to distribute their applications as docker containers. In particular, MESOSPHERE successfully uses this approach, as a result of which the MARATHON and CHRONOS applications discussed in this article are currently available as ready-made containers. Their use simplifies the process of servicing these subsystems, allows you to easily move them between cluster nodes, significantly speeds up the process of updating versions, and so on. The experience of our own developments, as well as the experience of third-party companies makes it possible to consider this approach as the most likely technology development trend in this industry.
To summarize, we can say that we have at our disposal a technology that can solve the problems formulated at the beginning of the article, fulfill three main requirements: provide the ability to transparently use the generalized computing resources of an IT system, provide the ability to run arbitrary tasks on an arbitrary node of the system, and to establish a mechanism for assigning a certain amount of computing resources from a common cluster set to each task separately.
In conclusion, it will not be out of place to note that the effectiveness of the approach described in the article is confirmed by the successful experience of implementing and operating the solutions developed using the technologies described above by several St. Petersburg IT companies.
The technologies discussed in this article are described in more detail.here .