Handlersocket Protocol in detail
Hello everyone. I decided to publish the Russian version of my own article, “HandlerSocket protocol explained,” published at http://wk-photo.ru/en/events/view/handlersocket-protocol-explained/ .
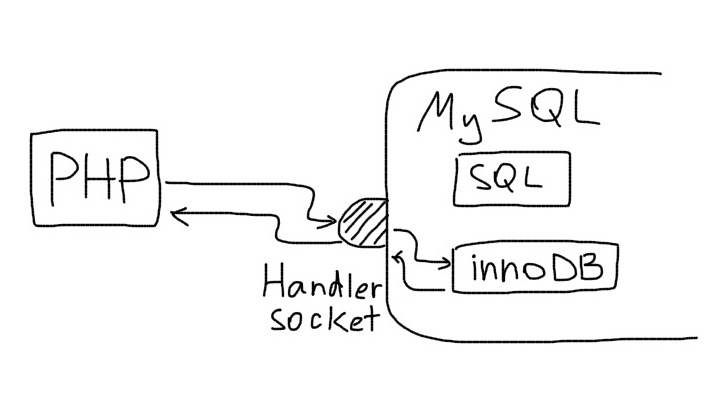
So, you went, went and came to HandlerSocket . Pure honey. This is a devilishly fast voodoo. And the protocol used is really simple, like two pennies. Well, if to be honest, who cares about the details of the protocol, if anyway some kind of library is used that takes care of everything? If, in spite of everything, you still want to know what kind of neonka is inside, you can google this page . A few hours - and you are an expert. Well, or you want everything in 15 minutes. Then good deed under kat!
It is assumed that you are already at least remotely familiar with the Handlersocket, you have MySQL / MariaDB / Percona server with the plugin turned on. I used MariaDB, the Handlersocket is there by default, you just need to enable the plugin, seasoning my.cnf with a small number of lines to taste .
As an advertisement: https://github.com/crocodile2u/zhandlersocket - my extension for PHP to work with Handlersocket.
Go. I log in to the MariaDB console and create a table:
Now connect to the Handlersocket. Port 9999, that is, the default port for writing: with this connection, I can both read and write. Since usually you still need to read more often than write, it will be more efficient to think in advance what actions will be needed in the application and open the connection to the port for reading or reading / writing, respectively. For reference: by default, the Handlersocket starts 16 workers for processing read-only connections and one worker for processing read-write connections.
Class. Now try to talk with this thing. The first thing to do when using the Handlersocket is to open the index. For any queries you send to HS to find or modify data, you need an index identifier. Let's see what the documentation says: The
request " open_index " has the following syntax:
Well, everything is clear ... Oh, andwhose pants with a motor are what is this / indexid /? This is the index identifier your application should provide. It is not generated by the Handlersocket. In fact, the application can send a request, consisting of a number of lines, to HS simultaneously:
This is only possible if the index ID is assigned by the application, otherwise you would have to first send a request to HS to open the index, get an identifier from HS, and only then use this identifier in your queries.
We will continue our exercises in the HS console (telnet). Forgot to say, request parts in HS are separated by TABs. In our example, I use the optional parameter / fcolumns / for the first index. We still need it.
What is it? Doca claims that in return we should get "0 1"! A. Well, yes, it's my fault, I forgot the / indexname / parameter.
Now the order. We are going to knock on the table with the primary key, so that / indexname / we will have PRIMARY. Let's open another HS index, for a MySQL index called genre:
You, you will feed. And this one opened. Let's now add lines to the plate? What do we have in the documentation?
... and we should get an answer like this:
Let's try ...
Oops The answer is not quite like in the dock. Additional unit. Let's see what happens with the table in the MariaDB console:
It worked! Come on, come on ...
Again look at MariaDB:
Oops! The unknown third digit that HS returns is exactly the same as the AUTO_INCREMENT id field!
Now let's try to specify the value for id manually ...
OK. A “1” in the first position of the answer tells us that an error has occurred. HS, however, is not too verbose. From the additional information we only have the magic number "121", which means ... Yes, the devil knows it, actually, but I think that in such a simple way we are hinted at an error like "DUPLICATE KEY". One more time…
We look in MariaDB, our new record is added with ID = 4:
Something like this, we insert records into tables via HS and get the values of the AUTO_INCREMENT field. The documentation is silent about this. Perhaps because in the old days HS did not support AUTO_INCREMENT.
Be careful with columns that have dynamic defaults . Such as "created_at DATETIME DEFAULT CURRENT_TIMESTAMP" or "updated_at DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP". When inserts and updates, you must set their values manually ! Otherwise, instead of the current time stamp, when you insert into the created_at field, you will get "0000-00-00 00:00:00". And if you do not specify a value for updated_at during the update, the previous value will be there.
We finished with INSERTs, uhh ... Now let's try to choose something from HS. We look in man ...
Well, everything is clear at a glance. Let's go further.
Okay, okay, joking. Let's try to find the record by ID. First comes / indexid / - in our case it is 1 (the index that we opened for the primary key). Then / op /: we want to get the entry with id = 1, so that would be "=". Then, / vlen /. This is the number of columns in the index. An index can consist of several columns. In our case, however, this is 1. Then comes the part / v1 / ... / vn /. These are the column values, in our example one column and a value of 1:
Hooray, it worked! The result can be interpreted as follows:
What if we try another operation (/ op /)? For example, get entries with id> 1:
How so? Only one entry? But we had more, I give a tooth! Oook, this is in the documentation: “LIM is optional. / limit / and / offset / are numbers. When omitted, it works as if 1 and 0 are specified. " Let's try to specify enough LIMIT to get all the rows that interest us.
All results are returned in one line:
All this will need to be analyzed in the client application (we know the number of columns, we know the order in which we listed them when opening the index, so there is no problem). Maybe you ask yourself a question: what will happen if there is a tab character in our data? Still sprinkled! The protocol describes the transmission of characters from 0x00 to 0x0f. Client libraries must encode these characters using a simple algorithm (the prefix 0x01 is added to them and shifted by 0x40). The client library should take care of this. For simplicity, we will not use characters in our examples that require coding.
In addition, we have another IN request.- that is, you can get data immediately heaps of records by their keys, in one request! I conducted several experiments. For starters, I did not know what to do with / op /, / vlen / and / v1 / ... / vn /. After all, we are going to indicate all the id that we want to get, in the IN part . Well, let's try the same as we tried with a simple search by id.
The IN condition is "@ 0 1 2", that is, column number 0, one value, and this value is 2.
"Modop". Thank HandlerSocket Now everything is clear! Let's try to change a little ...
Again. What do you want? What if I specify LIMIT?
That's it! It seems like you need to specify LIMIT and OFFSET for IN queries. / op /, / vlen / and / v1 / ... / vn / should also be specified, although this is only confusing. In the example below, I specify a value of 1 instead of 0 in the / vn / - section and get exactly the same answer!
I will try to change / op /:
And where is this from? Well, let's try to get more than one id:
Damn, I forgot about LIMIT. We indicate that we need 2 two entries:
Obviously, our ids were ignored, and HS returned records with id> 1. In the end, I found out that in the IN request you can safely specify "=" as / op /, and 0 as the value / v1 /. You may notice that we got the results exactly in the order we specified them in the IN condition. However, I do not know if this is a coincidence or not. I would not rely on it.
Let's move on to the filters? What if we take our last request and ask HS to filter by genre = 'Sci-Fi'? Remember when we opened the index, we specified / fcolumns /? Now they are useful to apply additional filters. If we did not specify / fcolumns /, any query with filters would return “2 1 filterfld”.
It worked! OK, that’s probably all about getting records from HS. Now let's move on to UPDATEs. What about documentation?
The first part looks familiar. We only saw all this when we looked at FIND queries, and it looks like these are WHERE conditions for our UDPATE. Update the series with id = 1 and set view_count = 100:
modop. So glad. How clear! What if you specify LIMIT?
Soooo Let's look at MariaDB:
Let's try a little more complicated. Increase view_count for all comedies by 10.
Looks like a norm! Let's look at MariaDB:
No, it didn’t work. At least it didn't work well. The counter really increased by 10, but also all other columns were updated. Since the id is numeric, and we said to increase it by 0, it remained untouched. I will return everything back:
I can say right away that specifying a value for the “genre” and “title” columns in the increment request will not work. They will get the value “0”, just as happened on our first attempt. In order for the increment to work as it should, you need to open a separate index, which will contain only the columns "id" and "view_count":
Well, another thing:
That's all. Happy handlersocketing!
So, you went, went and came to HandlerSocket . Pure honey. This is a devilishly fast voodoo. And the protocol used is really simple, like two pennies. Well, if to be honest, who cares about the details of the protocol, if anyway some kind of library is used that takes care of everything? If, in spite of everything, you still want to know what kind of neonka is inside, you can google this page . A few hours - and you are an expert. Well, or you want everything in 15 minutes. Then good deed under kat!
It is assumed that you are already at least remotely familiar with the Handlersocket, you have MySQL / MariaDB / Percona server with the plugin turned on. I used MariaDB, the Handlersocket is there by default, you just need to enable the plugin, seasoning my.cnf with a small number of lines to taste .
As an advertisement: https://github.com/crocodile2u/zhandlersocket - my extension for PHP to work with Handlersocket.
Go. I log in to the MariaDB console and create a table:
CREATE TABLE movie (
id int not null auto_increment primary key,
genre varchar(20) not null,
title varchar(100) not null,
view_count int default 0,
key(genre)
) engine innodb;Now connect to the Handlersocket. Port 9999, that is, the default port for writing: with this connection, I can both read and write. Since usually you still need to read more often than write, it will be more efficient to think in advance what actions will be needed in the application and open the connection to the port for reading or reading / writing, respectively. For reference: by default, the Handlersocket starts 16 workers for processing read-only connections and one worker for processing read-write connections.
~/ telnet localhost 9999
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.Class. Now try to talk with this thing. The first thing to do when using the Handlersocket is to open the index. For any queries you send to HS to find or modify data, you need an index identifier. Let's see what the documentation says: The
request " open_index " has the following syntax:
P /indexid/ /dbname/ /tablename/ /indexname/ /columns/ [/fcolumns/]
- / indexid / is a number in decimal.
- / dbname /, / tablename /, and / indexname / are strings. To open the primary key, use PRIMARY as / indexname /.
- / columns / is a comma-separated list of column names.
- / fcolumns / is a comma-separated list of column names. This parameter is optional.
Well, everything is clear ... Oh, and
Open index 1
Find row(s) in index 1
Find/Modify row(s) in index 1
...This is only possible if the index ID is assigned by the application, otherwise you would have to first send a request to HS to open the index, get an identifier from HS, and only then use this identifier in your queries.
We will continue our exercises in the HS console (telnet). Forgot to say, request parts in HS are separated by TABs. In our example, I use the optional parameter / fcolumns / for the first index. We still need it.
~/ telnet localhost 9999
...
P 1 test movie id,genre,title,view_count genre
2 1 idxnumWhat is it? Doca claims that in return we should get "0 1"! A. Well, yes, it's my fault, I forgot the / indexname / parameter.
P 1 test movie PRIMARY id,genre,title,view_count genre
0 1Now the order. We are going to knock on the table with the primary key, so that / indexname / we will have PRIMARY. Let's open another HS index, for a MySQL index called genre:
P 2 test movie genre id,genre,title,view_count
0 1You, you will feed. And this one opened. Let's now add lines to the plate? What do we have in the documentation?
The 'insert' request has the following syntax./indexid/ + /vlen/ /v1/ ... /vn/
- / vlen / indicates the length of the trailing parameters / v1 / ... / vn /. This must be smaller than or equal to the length of / columns / specified by the corresponding 'open_index' request.
- / v1 / ... / vn / specify the column values to set. For columns not in / columns /, the default values for each column are set.
... and we should get an answer like this:
If 'insert' is succeeded, HanderSocket returns a line of the following syntax.
0 1
Let's try ...
1 + 3 0 Sci-Fi Star wars
0 1 1Oops The answer is not quite like in the dock. Additional unit. Let's see what happens with the table in the MariaDB console:
SELECT * FROM movie;
+----+--------+-----------+
| id | genre | title |
+----+--------+-----------+
| 1 | Sci-Fi | Star wars |
+----+--------+-----------+It worked! Come on, come on ...
1 + 3 0 Comedy Dumb & Dumber
0 1 2
1 + 3 0 Thriller The Silence of the Lambs
0 1 3Again look at MariaDB:
SELECT * FROM movie;
+----+----------+--------------------------+
| id | genre | title |
+----+----------+--------------------------+
| 1 | Sci-Fi | Star wars |
| 2 | Comedy | Dumb & Dumber |
| 3 | Thriller | The Silence of the Lambs |
+----+----------+--------------------------+Oops! The unknown third digit that HS returns is exactly the same as the AUTO_INCREMENT id field!
Now let's try to specify the value for id manually ...
1 + 3 1 Sci-Fi Star Trek
1 1 121OK. A “1” in the first position of the answer tells us that an error has occurred. HS, however, is not too verbose. From the additional information we only have the magic number "121", which means ... Yes, the devil knows it, actually, but I think that in such a simple way we are hinted at an error like "DUPLICATE KEY". One more time…
1 + 3 4 Sci-Fi Star Trek
0 1 0We look in MariaDB, our new record is added with ID = 4:
SELECT * FROM movie;
+----+----------+--------------------------+
| id | genre | title |
+----+----------+--------------------------+
| ... |
| 4 | Sci-Fi | Star Trek |
+----+----------+--------------------------+Something like this, we insert records into tables via HS and get the values of the AUTO_INCREMENT field. The documentation is silent about this. Perhaps because in the old days HS did not support AUTO_INCREMENT.
Be careful with columns that have dynamic defaults . Such as "created_at DATETIME DEFAULT CURRENT_TIMESTAMP" or "updated_at DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP". When inserts and updates, you must set their values manually ! Otherwise, instead of the current time stamp, when you insert into the created_at field, you will get "0000-00-00 00:00:00". And if you do not specify a value for updated_at during the update, the previous value will be there.
We finished with INSERTs, uhh ... Now let's try to choose something from HS. We look in man ...
The 'find' request has the following syntax.
/ indexid / / op / / vlen / / v1 / ... / vn / [LIM] [IN] [FILTER ...]
LIM is a sequence of the following parameters.
/ limit / / offset /
IN is a sequence of the following parameters.@ /icol/ /ivlen/ /iv1/ ... /ivn/
FILETER is a sequence of the following parameters./ftyp/ /fop/ /fcol/ /fval/
- / indexid / is a number. This number must be an / indexid / specified by a 'open_index' request executed previously on the same connection.
- / op / specifies the comparison operation to use. The current version of HandlerSocket supports '=', '/', '/ =', '/', and '/ ='.
- / vlen / indicates the length of the trailing parameters / v1 / ... / vn /. This must be smaller than or equal to the number of index columns specified by the / indexname / parameter of the corresponding 'open_index' request.
- / v1 / ... / vn / specify the index column values to fetch.
- LIM is optional. / limit / and / offset / are numbers. When omitted, it works as if 1 and 0 are specified. These parameter works like LIMIT of SQL. These values don't include the number of records skipped by a filter.
- IN is optional. It works like WHERE ... IN syntax of SQL. / icol / must be smaller than the number of index columns specified by the / indexname / parameter of the corresponding 'open_index' request. If IN is specified in a find request, the / icol / -th parameter value of / v1 / ... / vn / is ignored.
- FILTERs are optional. A FILTER specifies a filter. / ftyp / is either 'F' (filter) or 'W' (while). / fop / specifies the comparison operation to use. / fcol / must be smaller than the number of columns specified by the / fcolumns / parameter of the corresponding 'open_index' request. Multiple filters can be specified, and work as the logical AND of them. The difference of 'F' and 'W' is that, when a record does not meet the specified condition, 'F' simply skips the record, and 'W' stops the loop.
Well, everything is clear at a glance. Let's go further.
Okay, okay, joking. Let's try to find the record by ID. First comes / indexid / - in our case it is 1 (the index that we opened for the primary key). Then / op /: we want to get the entry with id = 1, so that would be "=". Then, / vlen /. This is the number of columns in the index. An index can consist of several columns. In our case, however, this is 1. Then comes the part / v1 / ... / vn /. These are the column values, in our example one column and a value of 1:
1 = 1 1
0 3 1 Sci-Fi Star warsHooray, it worked! The result can be interpreted as follows:
0 - no errors;
3 - number of columns
[1 Sci-Fi Star wars] - the row that we've got from InnoDB.What if we try another operation (/ op /)? For example, get entries with id> 1:
1 > 1 1
0 3 2 Comedy Dumb & DumberHow so? Only one entry? But we had more, I give a tooth! Oook, this is in the documentation: “LIM is optional. / limit / and / offset / are numbers. When omitted, it works as if 1 and 0 are specified. " Let's try to specify enough LIMIT to get all the rows that interest us.
1 > 1 1 10 0
0 3 2 Comedy Dumb & Dumber 3 Thriller The Silence of the Lambs 6 Sci-Fi Star TrekAll results are returned in one line:
0 - no errors;
3 - number of columns
[2 Comedy Dumb & Dumber] - row 1
[3 Thriller The Silence of the Lambs] - row 2
[6 Sci-Fi Star Trek] - row 3All this will need to be analyzed in the client application (we know the number of columns, we know the order in which we listed them when opening the index, so there is no problem). Maybe you ask yourself a question: what will happen if there is a tab character in our data? Still sprinkled! The protocol describes the transmission of characters from 0x00 to 0x0f. Client libraries must encode these characters using a simple algorithm (the prefix 0x01 is added to them and shifted by 0x40). The client library should take care of this. For simplicity, we will not use characters in our examples that require coding.
In addition, we have another IN request.- that is, you can get data immediately heaps of records by their keys, in one request! I conducted several experiments. For starters, I did not know what to do with / op /, / vlen / and / v1 / ... / vn /. After all, we are going to indicate all the id that we want to get, in the IN part . Well, let's try the same as we tried with a simple search by id.
The IN condition is "@ 0 1 2", that is, column number 0, one value, and this value is 2.
1 = 1 1 @ 0 1 2
2 1 modop"Modop". Thank HandlerSocket Now everything is clear! Let's try to change a little ...
1 = 1 0 @ 0 1 2
2 1 modopAgain. What do you want? What if I specify LIMIT?
1 = 1 0 1 0 @ 0 1 2
0 3 2 Comedy Dumb & DumberThat's it! It seems like you need to specify LIMIT and OFFSET for IN queries. / op /, / vlen / and / v1 / ... / vn / should also be specified, although this is only confusing. In the example below, I specify a value of 1 instead of 0 in the / vn / - section and get exactly the same answer!
1 = 1 1 1 0 @ 0 1 2
0 3 2 Comedy Dumb & DumberI will try to change / op /:
1 > 1 1 1 0 @ 0 1 2
0 3 3 Thriller The Silence of the LambsAnd where is this from? Well, let's try to get more than one id:
1 > 1 1 1 0 @ 0 2 2 3
0 3 3 Thriller The Silence of the LambsDamn, I forgot about LIMIT. We indicate that we need 2 two entries:
1 > 1 1 2 0 @ 0 2 2 3
0 3 3 Thriller The Silence of the Lambs 6 Sci-Fi Star TrekObviously, our ids were ignored, and HS returned records with id> 1. In the end, I found out that in the IN request you can safely specify "=" as / op /, and 0 as the value / v1 /. You may notice that we got the results exactly in the order we specified them in the IN condition. However, I do not know if this is a coincidence or not. I would not rely on it.
Let's move on to the filters? What if we take our last request and ask HS to filter by genre = 'Sci-Fi'? Remember when we opened the index, we specified / fcolumns /? Now they are useful to apply additional filters. If we did not specify / fcolumns /, any query with filters would return “2 1 filterfld”.
1 = 1 0 3 0 @ 0 3 2 3 1 F = 0 Sci-Fi
0 3 1 Sci-Fi Star warsIt worked! OK, that’s probably all about getting records from HS. Now let's move on to UPDATEs. What about documentation?
The 'find_modify' request has the following syntax./indexid/ /op/ /vlen/ /v1/ ... /vn/ [LIM] [IN] [FILTER ...] MOD
MOD is a sequence of the following parameters./mop/ /m1/ ... /mk/
- / mop / is' U '(update),' + '(increment),' - '(decrement),' D '(delete),' U? ',' +? ',' -? ', or' D ? '. If the '?' suffix is specified, it returns the contents of the records before modification (as if it's a 'find' request), instead of the number of modified records.
- / m1 / ... / mk / specifies the column values to set. The length of / m1 / ... / mk / must be smaller than or equal to the length of / columns / specified by the corresponding 'open_index' request. If / mop / is 'D', these parameters are ignored. If / mop / is '+' or '-', values must be numeric. If / mop / is '-' and it attempts to change a column value from negative to positive or positive to negative, the column value is not modified.
The first part looks familiar. We only saw all this when we looked at FIND queries, and it looks like these are WHERE conditions for our UDPATE. Update the series with id = 1 and set view_count = 100:
1 = 1 1 U 1 Sci-Fi Star Wars 100
2 1 modopmodop. So glad. How clear! What if you specify LIMIT?
1 = 1 1 1 0 U 1 Sci-Fi Star Wars 100
0 1 1Soooo Let's look at MariaDB:
SELECT * FROM movie WHERE id = 1;
+----+--------+-----------+------------+
| id | genre | title | view_count |
+----+--------+-----------+------------+
| 1 | Sci-Fi | Star Wars | 100 |
+----+--------+-----------+------------+Let's try a little more complicated. Increase view_count for all comedies by 10.
1 / 1 0 1000 0 F = 0 Comedy + 0 0 0 10
0 1 1Looks like a norm! Let's look at MariaDB:
SELECT * FROM movie;
+----+----------+--------------------------+------------+
| id | genre | title | view_count |
+----+----------+--------------------------+------------+
| 1 | Sci-Fi | Star Wars | 100 |
| 2 | 0 | 0 | 10 |
| 3 | Thriller | The Silence of the Lambs | 0 |
| 6 | Sci-Fi | Star Trek | 0 |
+----+----------+--------------------------+------------+No, it didn’t work. At least it didn't work well. The counter really increased by 10, but also all other columns were updated. Since the id is numeric, and we said to increase it by 0, it remained untouched. I will return everything back:
1 = 1 2 1 0 U 2 Comedy Dumb & Dumber 10I can say right away that specifying a value for the “genre” and “title” columns in the increment request will not work. They will get the value “0”, just as happened on our first attempt. In order for the increment to work as it should, you need to open a separate index, which will contain only the columns "id" and "view_count":
P 3 test movie PRIMARY id,view_count genre
0 1
3 / 1 0 1000 0 F = 0 Comedy + 0 10
0 1 1Well, another thing:
SELECT * FROM movie;
+----+----------+--------------------------+------------+
| id | genre | title | view_count |
+----+----------+--------------------------+------------+
| 1 | Sci-Fi | Star Wars | 100 |
| 2 | Comedy | Dumb & Dumber | 30 |
| 3 | Thriller | The Silence of the Lambs | 0 |
| 6 | Sci-Fi | Star Trek | 0 |
+----+----------+--------------------------+------------+That's all. Happy handlersocketing!