Články podle tagu: clickhouse

Skipping indexy ClickHouse: bloom, set, minmax
Jak skipping indexy v ClickHouse urychlují dotazy na sloupce mimo ORDER BY. Rozbor minmax, set, bloom_filter, ngrambf_v1, tokenbf_v1 s příklady z gamingu a EXPLAIN.

Materializovaná zobrazení ClickHouse: triggery na INSERT
Jak fungují MV v ClickHouse: inkrementální agregace, řetězce minuta→hodina→den, vzor Null+Kafka, POPULATE a jeho nebezpečí. Příklady s SummingMergeTree a AggregatingMergeTree.
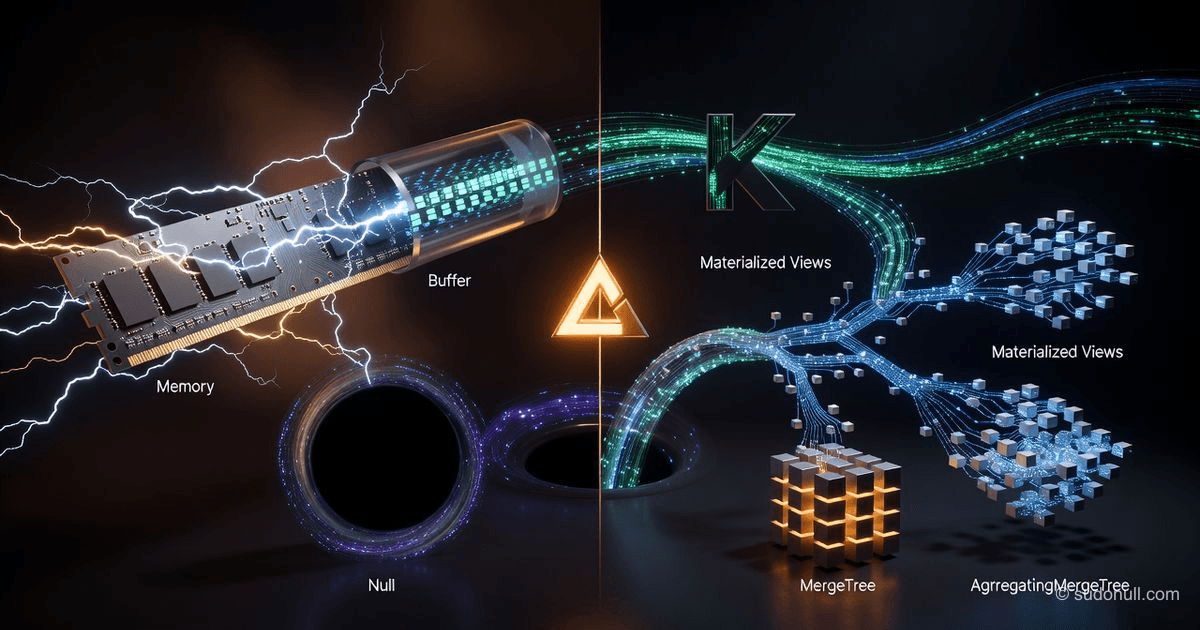
Speciální enginy ClickHouse: když MergeTree není potřeba
Přehled enginů ClickHouse Memory, Buffer, Null, Log, URL, S3 a PostgreSQL. Příklady pro cache koeficientů, bufferizaci vložení z Kafka a live dat z externích DB.

Slovníky v ClickHouse: rychlý lookup bez JOIN
Jak používat slovníky ClickHouse k nahrazení JOIN mikrosekundovým vyhledáváním v paměti. Typy flat/hashed/range, zdroje dat, dictGet a příklady pro gaming.

TTL v ClickHouse: správa životního cyklu dat
Jak TTL v ClickHouse automaticky maže, přesouvá na HDD/S3, agreguje a anonymizuje data. Příklady pro GDPR, tiered storage a seskupování starých záznamů.

ORDER BY a PRIMARY KEY v ClickHouse: výběr indexu
Jak správně vybrat ORDER BY v ClickHouse: sparse index, kardinalita sloupců, rovnost vs rozsah, kontrola pomocí EXPLAIN. Pravidla a příklady pro gambling.

Partitionování v ClickHouse: strategie a operace
Jak partitionování v ClickHouse urychluje DROP a správu dat. Výběr velikosti partition, system.parts, DETACH/ATTACH, FREEZE, MOVE na SSD/HDD a skript pro mazání starých dat.

CollapsingMergeTree v ClickHouse: aktualizace bez UPDATE
Jak CollapsingMergeTree a VersionedCollapsingMergeTree nahrazují UPDATE v ClickHouse: sign-sloupec, sbalování párů, SUM(amount*sign), problém pořadí a řešení pomocí verzí.

SummingMergeTree a AggregatingMergeTree v ClickHouse
Inkrementální agregace v ClickHouse: jak SummingMergeTree a AggregatingMergeTree urychlují dashboardy 100krát. Příklady, materializovaná zobrazení, nástrahy a srovnání.

ReplacingMergeTree v ClickHouse: úplný průvodce
Zjistěte, jak ReplacingMergeTree odstraňuje duplicity, pracuje s verzemi a FINAL. Příklady, nástrahy a srovnání s CollapsingMergeTree pro pokročilou deduplikaci.

ClickHouse: proč sloupcové DBMS urychlují analytiku 100krát
Vysvětlujeme na reálných benchmarkách a schématu sázek: ClickHouse versus PostgreSQL a MySQL. Architektura, příklady dotazů, use cases. Čtení na 5 minut.
Materializovaná zobrazení ClickHouse: nuancí a řešení
Jak fungují MV v ClickHouse? Kritické rozdíly oproti klasickým DBMS, omezení UPDATE/DELETE a osvědčené postupy. Zjistěte, jak se vyhnout chybám v návrhu.

ClickHouse: deduplikace a ztráty v MV
Rozbor ztrát dat v ClickHouse kvůli deduplikaci bloků v materialized views. Nastavení insert_deduplicate=0 a deduplicate_blocks_in_dependent_materialized_views=1. Nastavte úložiště bez ztrát – čtěte podrobnosti.

Kafka Engine ClickHouse: atomarita bez ztrát
Nastavení Kafka Engine v ClickHouse pro spolehlivé vkládání ze streamů. Demonstrace offset-commitu, vyhnutí se ztrátám při selháních. Průvodce pro middle/senior dev.

ClickHouse s Airflow místo PostgreSQL pro Big Data
Zjistěte, proč Airflow + ClickHouse vytlačuje PostgreSQL v analýze. Srovnání výkonu, příklady pro data engineers. Přejděte na columnar DB pro ETL-pipeline.

CTE v ClickHouse: makro místo optimalizace
Rozkládáme, proč se WITH v ClickHouse spouští opakovaně a jak ho nahradit dočasnými tabulkami. Příklady kódu, explain, srovnání pro vývojáře. Zrychlete dotazy bez pastí.

Diagnostika CPU 80 % v ClickHouse
Nástroje pro hledání problematických dotazů v ClickHouse: system.processes, query_log, EXPLAIN. Kroky diagnostiky, příklady SQL, checklist. Optimalizujte zátěž bez výpadku.