Artykuły według tagu: clickhouse

Skipping indeksy ClickHouse: bloom, set, minmax
Jak skipping indeksy w ClickHouse przyspieszają zapytania po kolumnach spoza ORDER BY. Analiza minmax, set, bloom_filter, ngrambf_v1, tokenbf_v1 z przykładami z gamingu i EXPLAIN.

Materializowane widoki ClickHouse: wyzwalacze na INSERT
Jak działają MV w ClickHouse: agregacja inkrementalna, łańcuchy minuta→godzina→dzień, wzorzec Null+Kafka, POPULATE i jego zagrożenia. Przykłady z SummingMergeTree i AggregatingMergeTree.
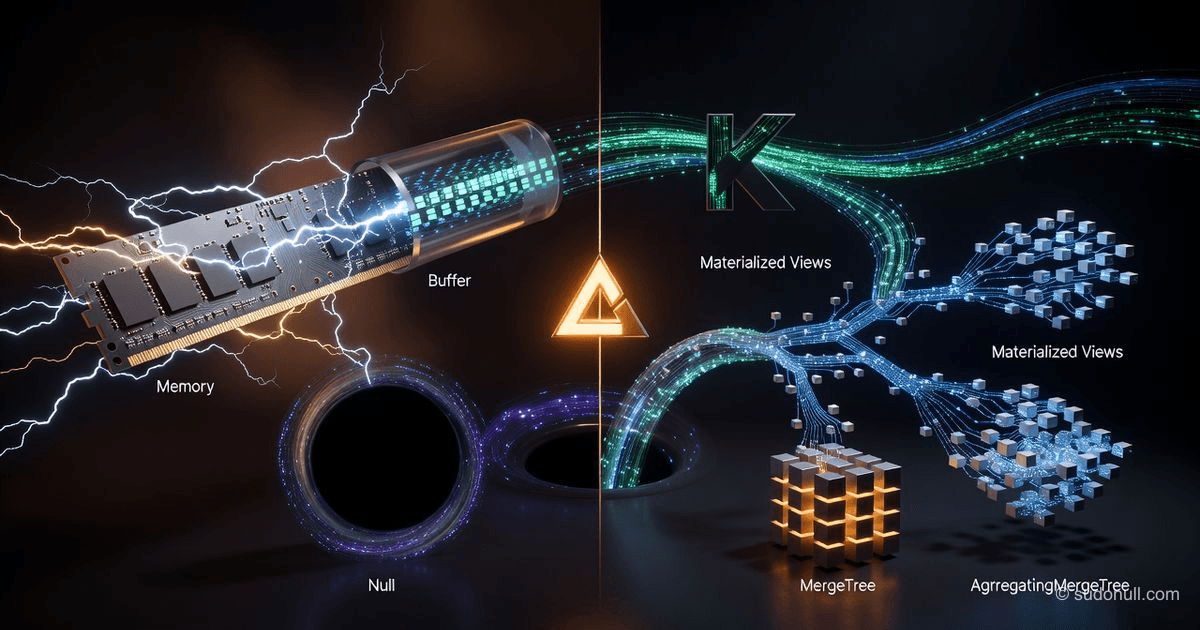
Specjalne silniki ClickHouse: kiedy MergeTree nie jest potrzebny
Przegląd silników ClickHouse: Memory, Buffer, Null, Log, URL, S3 i PostgreSQL. Przykłady dla pamięci podręcznej współczynników, buforowania wstawek z Kafka i danych na żywo z zewnętrznych baz danych.

Słowniki w ClickHouse: szybki lookup bez JOIN
Jak używać słowników ClickHouse do zastąpienia JOIN mikrosekundowym wyszukiwaniem w pamięci. Typy flat/hashed/range, źródła danych, dictGet i przykłady dla gamingu.

TTL w ClickHouse: zarządzanie cyklem życia danych
Jak TTL w ClickHouse automatycznie usuwa, przenosi na HDD/S3, agreguje i anonimizuje dane. Przykłady dla GDPR, tiered storage i grupowania starych rekordów.

ORDER BY i PRIMARY KEY w ClickHouse: wybór indeksu
Jak prawidłowo wybrać ORDER BY w ClickHouse: sparse index, kardynalność kolumn, równość vs zakres, sprawdzenie przez EXPLAIN. Zasady i przykłady dla gamlingu.

Partycjonowanie w ClickHouse: strategie i operacje
Jak partycjonowanie w ClickHouse przyspiesza DROP i zarządzanie danymi. Wybór rozmiaru partycji, system.parts, DETACH/ATTACH, FREEZE, MOVE na SSD/HDD i skrypt usuwania starych danych.

CollapsingMergeTree w ClickHouse: aktualizacja bez UPDATE
Jak CollapsingMergeTree i VersionedCollapsingMergeTree zastępują UPDATE w ClickHouse: kolumna sign, zwijanie par, SUM(amount*sign), problem kolejności i rozwiązanie przez wersje.

SummingMergeTree i AggregatingMergeTree w ClickHouse
Inkrementalna agregacja w ClickHouse: jak SummingMergeTree i AggregatingMergeTree przyspieszają dashboardy 100 razy. Przykłady, widoki zmaterializowane, pułapki i porównanie.

ReplacingMergeTree w ClickHouse: kompletny przewodnik
Dowiedz się, jak ReplacingMergeTree usuwa duplikaty, działa z wersjami i FINAL. Przykłady, pułapki i porównanie z CollapsingMergeTree dla zaawansowanej deduplikacji.

ClickHouse: dlaczego kolumnowe bazy danych przyspieszają analitykę 100 razy
Wyjaśniamy na rzeczywistych benchmarkach i schemacie zakładów: ClickHouse vs PostgreSQL i MySQL. Architektura, przykłady zapytań, przypadki użycia. Czytać 5 minut.
Materializowane widoki ClickHouse: niuanse i rozwiązania
Jak działają MV w ClickHouse? Krytyczne różnice od klasycznych systemów zarządzania bazami danych, ograniczenia UPDATE/DELETE i praktyczne wskazówki. Dowiedz się, jak uniknąć błędów w projektowaniu.

ClickHouse: deduplikacja i straty w MV
Analiza strat danych w ClickHouse z powodu deduplikacji bloków w materialized views. Ustawienia insert_deduplicate=0 i deduplicate_blocks_in_dependent_materialized_views=1. Skonfiguruj przechowywanie bez strat — przeczytaj szczegóły.

Kafka Engine ClickHouse: atomowość bez strat
Konfiguracja Kafka Engine w ClickHouse dla niezawodnych wstawek ze strumieni. Demonstracja offset-commitu, unikanie strat przy awariach. Przewodnik dla middle/senior dev.

ClickHouse z Airflow zamiast PostgreSQL dla Big Data
Dowiedz się, dlaczego Airflow + ClickHouse wypiera PostgreSQL w analityce. Porównanie wydajności, przykłady dla data engineers. Przechodź na columnar DB dla ETL-pipeline’ów.

CTE w ClickHouse: makro zamiast optymalizacji
Rozbieramy, dlaczego WITH w ClickHouse wykonuje się wielokrotnie i jak zastąpić tabelami tymczasowymi. Przykłady kodu, explain, porównania dla deweloperów. Przyspiesz zapytania bez pułapek.

Diagnostyka CPU 80% w ClickHouse
Narzędzia do wyszukiwania problematycznych zapytań w ClickHouse: system.processes, query_log, EXPLAIN. Kroki diagnostyki, przykłady SQL, lista kontrolna. Optymalizuj obciążenie bez przestojów.