Artykuły według tagu: postgresql

MongoDB vs PostgreSQL Kiedy użyć każdego: Kluczowe różnice
MongoDB vs PostgreSQL kiedy użyć każdego: porównaj zgodność ACID, skalowalność, elastyczność schematu i moc zapytań. Wybierz odpowiednią bazę danych dla swojego projektu.

PostgreSQL vs MySQL: Który Wybrać?
PostgreSQL vs MySQL który wybrać? Porównaj funkcje, wydajność, skalowalność i przypadki użycia. Podejmij świadomą decyzję dla swojego projektu dzięki temu opartemu na danych przewodnikowi.
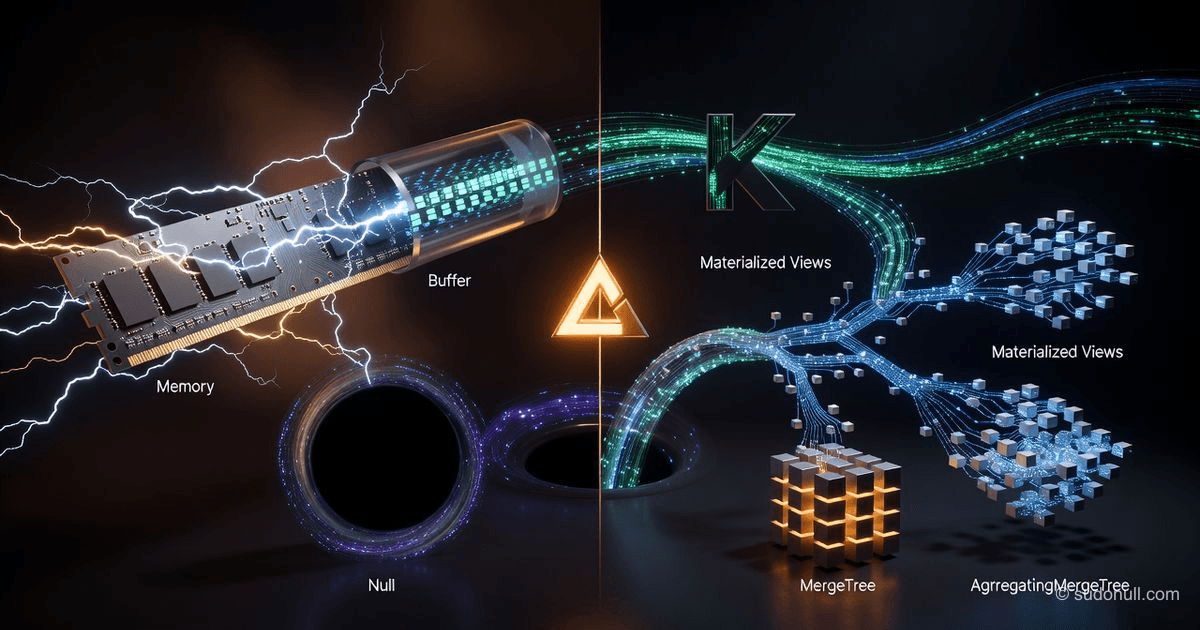
Specjalne silniki ClickHouse: kiedy MergeTree nie jest potrzebny
Przegląd silników ClickHouse: Memory, Buffer, Null, Log, URL, S3 i PostgreSQL. Przykłady dla pamięci podręcznej współczynników, buforowania wstawek z Kafka i danych na żywo z zewnętrznych baz danych.

Konflikty BufferPin w PostgreSQL: jak znaleźć i wyeliminować
Analizujemy ukryte konflikty BufferPin w PostgreSQL, wpływające na repliki i autovacuum. Metody diagnostyki, monitoringu i optymalizacji dla DBA i deweloperów.

Integracja Next.js z 1C-Bitrix: asynchroniczne przekazywanie leadów
Zaimplementuj niezawodne przekazywanie leadów bez kolejek. Szczegółowy rozbiór wzorca z after(), retry i zarządzaniem błędami. Dowiedz się, jak uniknąć timeoutów Bitrix REST API.
Obserwowalność w Go: QueryTracer, metryki i OTel
Porównujemy narzędzia obserwowalności w Go: QueryTracer, metryki i OpenTelemetry. Dowiedz się, kiedy używać każdego i jak uniknąć błędów we wdrażaniu.
Hybrydowe wyszukiwanie w PostgreSQL | Konfiguracja VectorChord
Omawiamy konfigurację infrastruktury hybrydowego wyszukiwania w PostgreSQL i VectorChord. Automatyzacja rozszerzeń, projektowanie tabel, potoki przetwarzania. Dowiedz się jak.
Analiza PostgreSQL: epistemologiczne podejście do incydentów wydajności
Jak łączyć techniczną analizę PG_EXPECTO z filozoficznymi metodologiami dla wiarygodnej diagnostyki incydentów. Kwantyfikacja pewności i metody krytycznego myślenia.

Tuning PostgreSQL: AI przeciwko testom obciążeniowym
Porównanie rekomendacji AI i rzeczywistych benchmarków PostgreSQL. Dowiedz się, jak konfiguracje OLTP i OLAP wpływają na wydajność i dlaczego testy są ważniejsze od teorii.

Linux 7.0 regresja PostgreSQL ARM64
Programista Amazon znalazł spadek wydajności PostgreSQL dwukrotny na Linux 7.0 z powodu PREEMPT_LAZY. Analiza, poprawki z rseq i stanowisko Zijlstry. Testujcie na ARM64.
Architektura bazy danych do parsowania taryf na PostgreSQL
Poznaj schemat gwiazdy do przechowywania taryf internetu i TV: tabele faktów, wymiary, triggery historyczności, indeksy. Pełny kod SQL dla programistów middle/senior. Zaimplementuj monitoring dostawców bez utraty danych.

Opanuj C# od zera: darmowy program
Osiągnij umiejętności programisty C# za darmo: od podstaw CS do ASP.NET Core i EF Core. Pełny plan na 8–10 miesięcy z kursami i poradami dla stanowisk junior. Zacznij teraz!

ltree w PostgreSQL z JPA: przechowywanie drzew
Integracja ltree dla danych hierarchicznych w PostgreSQL i JPA. Porównanie wydajności z rekurencyjnym SQL. Zastosowanie w mikrousługach dla deweloperów.

System BI na DataLens i PostgreSQL dla WB Ozon
Dowiedz się, jak zbudować skalowalny system BI dla marketplace'ów: od wyodrębniania API po zoptymalizowane dashboardy. Wersjonowanie kosztu własnego, przedobliczenia, automatyzacja. Instrukcja dla programistów.

Projekt walidacji biletów QR dla kin
Analiza projektowania systemowego weryfikacji biletów QR: podpis offline, idempotentność, atomowe aktualizacje. Rozwiązanie timeoutów i blokowania HoL dla high-load. Praktyczne przykłady SQL.

Przywracanie PostgreSQL bez backupu 2.5 TB
Rzeczywisty przypadek zniszczenia klastra PostgreSQL przez usunięcie WAL i SIGKILL. Kroki przywracania z ignore_system_indexes, crash_info i patchy pg_dump. Lekcje dla DBA 1C.

Health Score dla PostgreSQL: monitorowanie zdrowia
Dowiedz się, jak Health Score łączy 150 metryk PostgreSQL w jeden wskaźnik. Formuły, zapytania SQL, wagi kategorii i autodiagnostyka dla DBA. Wdroż w swojej infrastrukturze.

pgvector vs pgvectorscale vs VectorChord: porównanie
Techniczne porównanie rozszerzeń PostgreSQL dla wyszukiwania wektorowego: pgvector, pgvectorscale, VectorChord. Benchmarki, indeksy HNSW/DiskANN, kompresja RaBitQ. Konfiguracja Docker i kod dla 1M rekordów. Wybierz optymalne rozwiązanie.

Opanuj stack technologiczny PM: AI-asystent na FastAPI
Krok po kroku przewodnik dla PM: rozwój SaaS z FastAPI, PostgreSQL, RAG. 10 etapów od bota Telegram do wyszukiwania hybrydowego. Pogłęb technikę bez uproszczeń.

Równomierny sharding BD: strategie dystrybucji i wyszukiwania danych
Poznaj metody równomiernego shardingu do poziomego skalowania baz danych. Dowiedz się o generowaniu ID, paginacji i optymalizacji zapytań w systemach rozproszonych.