Classification of tables in relational databases by signs of data integrity and redundancy
The content of the article
Justification of the article and some key concepts;
1. Directories and bundles;
1.1. Types of tables;
1.2. Types of directories;
1.3. Types of ligaments;
2. Generalization of classification;
2.1. Classification in tabular form;
2.2. Classification in a schematic form;
3. Some comments on the application of the classification;
3.1. The use of classification in the normalization of tables;
Conclusion
Justification of the article and some key concepts
Very often attended the training discipline "Databases". I studied once myself ... Somehow I even had to conduct a whole course for friends and acquaintances. During the training, I noticed that difficulties arise already at the stage of understanding the tables and how to use them. Many simply could not and cannot develop the simplest databases. After a more detailed consideration of such a concept as tables and a small classification, the difficulties of perceiving tables in relational databases almost always disappear. So!
In this article, a small classification of tables by signs of integrity and redundancy will be considered. What does it mean? This means that examples will be given with a description of what table structure can be done to prevent (try to prevent) redundancy and achieve integrity in relational databases.
For understanding, we give brief definitions of data integrity and redundancy:
Data integrity is a property of the ability to restore others from one data, without losing the semantic unity of this data and the relationship between them (between data).
Redundancy of data is the state of the database, in which there is extra data in the tables.
Data integrity may be compromised by data modification operations. If deletion and update operations are prohibited in the database, the integrity can be violated only as a result of the add operation, as well as incorrectly written scripts to display data.
1. Directories and links
1.1. Types of tables
Let's go a little deeper into a small classification of tables according to the types of their structure. We divide the tables into two general views. The first type will be reference tables, the second link tables.

Figure 1. Directories and links
Information in the tables can be divided into two types. For information that describes objects (subjects), communications and information that describes actions, processes, events, etc.
The directories contain information about objects and subjects, relationships. Bundles contain information about actions, processes, events, and so on.
Bundles store data taken from reference tables. Since it is unprofitable to repeat the same data when describing objects (subjects) and when describing their interaction, data about objects (subjects) are entered in reference books, and data tables of objects (subjects) are not stored in pure form, but only links to them (foreign key). Thus, bundles store data on the interaction of objects (subjects) and links to the objects (subjects) themselves (foreign key). These "links" are the primary keys in the tables of directories. But more about that later ...
The difference between a reference book and a bunch is expressed in the fact that the reference tables can be independent and independent (that is, when reading the data of some directories you can generally understand the semantics), and link tables almost never.
1.2. Types of directories
Directories can be divided into several types. These are static, static-dynamic and dynamic reference books. Of course, one can hardly call an absolutely static reference book, since everything can change in this world. Or almost everything.
A static reference book is a reference book containing information about objects, subjects, relationships in which either they never undergo modifications after the initial modification, or modifications are so rare that they can be neglected.
An example of such directories is a list of months with names and numbers, a list of days of the week, a list of seasons, a list of oceans, and so on ...
| room | Name |
| 1 | January |
| 2 | February |
| 3 | March |
| 4 | April |
| 5 | May |
| 6 | June |
| 7 | July |
| 8 | August |
| 9 | September |
| 10 | October |
| eleven | November |
| 12 | December |
Table 1. An example of static directories A static
-dynamic reference book is a directory in which data about connections is stored if the links are of a reference nature. Such a directory may contain foreign keys.
The most successful example would be a table with medical data such as weight. The list of people whose weight is measured does not change often. But the data on their weight can change every day. Static-dynamic directories are the only directories where you can consciously repeat any information. Another example would be a salary guide for posts (by job code).
| Position Code | Salary | Update date |
| 1001 | 12,000 | 02/05/2015 |
| 1002 | 17,000 | 02/01/2015 |
| 1003 | 11 500 | 02/01/2015 |
| 1004 | 25,450 | 02/01/2015 |
| 1005 | 10,000 | 02/01/2015 |
| 1006 | 6,000 | 02/04/2015 |
Table 2. Example of static-dynamic directories
Dynamic directories are tables, data about objects, subjects, relationships in which they change frequently and are used in other tables. From static directories they differ only in the frequency of modification of data in them.
An example of such tables can be lists of projects. In fact, data on opening or closing projects can be in the project directory itself, which in most cases is incorrect and violates the integrity. On the other hand, if you keep a history of changes in the opening and closing (suspension) of projects, then you can get data redundancy. The integrity and redundancy of the data will struggle with each other for a long time, as well as winter and summer.
| Project code | Project | Regulatory deadline | Date Added | User |
| PT102 | Window painting | fifteen | 01/03/2014 | 1547 |
| PT103 | Door installation | 10 | 01/04/2014 | 9874 |
| PT587 | Checking Fire Faucets | 2 | 01/04/2014 | 1456 |
| PT588 | Hatches Replacement | 3 | 01/02/2014 | 0147 |
| PT133 | Channel cleaning | eleven | 02/09/2015 | 1547 |
Table 3. An example of dynamic directories
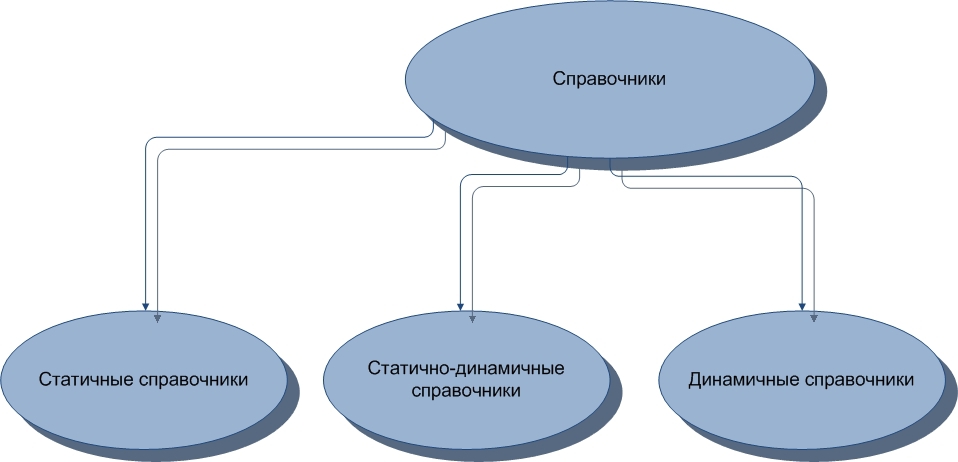
Figure 2. Types of directories
1.3. Types of ligaments
Bundle tables can be divided into two types.
This is a reference book (we’ll immediately clarify that a reference book is not a reference, it is named because there are fields in it that form a reference, but cannot be highlighted in the reference). A table in which foreign keys, data that is not reference, and fields containing data that form the directory, but cannot be allocated to a separate reference table, are stored.
An example of a reference-link will be a table of payment transactions. Or a table with data about a football match.
| Transaction Code | Payer | Recipient | Amount | date | A comment |
| EEVS-doodi4 | 100045 | 57457 | -10,000 | 07/25/2014 | On boots |
| UDFD-ioeed9 | 455780 | 10024 | -900 | 06/24/2014 | Null |
| PEDD-jdksl4 | 144770 | 56698 | -6980 | 01/01/2015 | Null |
| FDFE-keiiii0 | 447757 | 1 | 120 | 07/08/2014 | Null |
Table 4. An example of a reference-bunch
And a bunch (yes, just a bunch). This is a table in which only foreign keys and data that cannot be attributed to reference ones are stored, for example, date or values of logical fields.
An example of a bundle would be an automatic logging table of a data processing terminal.
By the way, it is easy to guess that the bundles are almost never used, since most often there is data that can be written to the database, but not contained in directories, so it is impossible to match the foreign key to them.
| The code | Client code | Meter reading | Month |
| 2334 | 35643 | fifty | 01/01/2015 |
| 2335 | 235673 | 49 | 01/01/2015 |
| 2335 | 436345 | 56 | 01/01/2015 |
| 2335 | 574733 | 24 | 01/01/2015 |
Table 5. An example of a bunch.
It is necessary to explain what these fields are, which form a directory, but cannot be selected in a separate reference table. An example of such fields are the fields “comment”, “complaint”, “description”, “proposal”. In short, if you give a popular example, then the “message” field in the database table of any social network ...
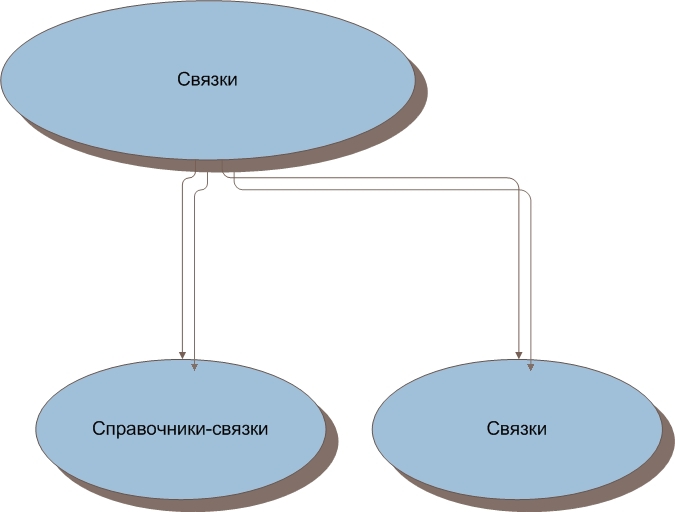
Figure 3. Types of bundles
2. Generalization of classification
2.1. Table classification
| Table view | Description | Examples | Pros (+) | Minuses(-) |
| Static reference | Table. The data from it is taken for other tables. From the directory in other tables, you can use only the primary key. A static reference should contain information that either does not change at all, or changes so rarely that this can be neglected. A static reference is referred to (foreign key) when you need to get names, symbols, norms, quantitative or qualitative indicators. Other | Directory of (names and numbers) months. Directory of warehouses and workshops of the enterprise. Guide to the rules of the game. | Sometimes it replaces the DBMS system functions and allows more flexible work with some data. In case rarely changing information changes, warns against serious consequences. | Using a table with any structure can slow down if the table replaces the system storage. We have to write additional functions and processing for this table, which are not always correctly optimized. In some cases, it is impossible to optimize. |
| Static Dynamic Reference | Table. The data from it is taken for other tables. From the directory in other tables, you cannot use the foreign key of this directory, however, you can use the primary key. | Salary reference by job title. Handbook (shoe sizes, weight, height, head size) physiological parameters. Directory (of managers, companies) containing the companies and managers that these companies serve and take into account. | Allows flexible normalization according to the scheme “Reference-link” = “Link” + “Static-dynamic reference”. | A reference book, isolated from a reference book, does not go anywhere and does not have any relational connection that would allow it to turn into a static or dynamic reference book. Which means it is always redundant. |
| Dynamic reference | Table. Data from it is often taken for other tables. From the directory in other tables, you can use only the primary key. A dynamic reference should contain information that changes frequently. | Customer reference. Directory of suppliers. Reference book of counterparties. Directory of company managers. Directory of workers. Directory of students. | Allows you to store dynamic data, while making it possible to uniquely refer to them. | Most often, the accumulative type and do not divide, which creates a certain redundancy. |
| Reference book | Table. Data from it cannot be contained in other tables, but based on them data can be created in other tables. | Payment transactions. Sales. Interplant movements. Schedule of transportation. | Allows flexible normalization according to the scheme “Reference-link” = “Link” + “Static-dynamic reference”. | A reference-link after normalization turns into a bunch and minimizes data redundancy without affecting integrity, but it is not divisible and cannot be optimized when archiving in the current table. |
| Bunch | Table. Data from it cannot be contained in other tables, but based on them data can be created in other tables. A table cannot contain tuples whose attribute values are indivisible and not unique. | Automatic error log in the program. Server request log Trace results. Reports on the unloading and loading of components. Automatic security reports. | The bundle minimizes data redundancy without compromising integrity. | Accumulating is an indivisible table. It’s hard to optimize. |
Table 6. Classification
2.2. Schematic classification
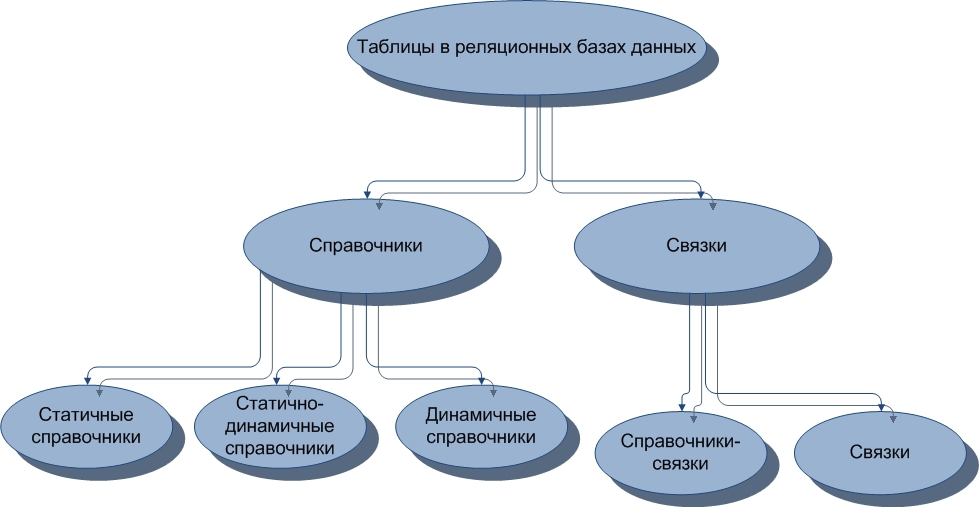
Figure 4. Scheme for classifying tables in relational databases by signs of data integrity and redundancy
3. Some comments on the application of classification
3.1. Using classification to normalize tables
The normalization process, if you do not take into account some stages (But take into account the results of these stages!), Is the usual “splitting” of tables into smaller tables with the creation of a relational relationship between them directly or through intermediate tables (many-to-many relationship). A relational relationship may not always mean a relational relationship!
Converting a dynamic or static reference to a static-dynamic reference, and a link-link to a link, as well as a static-dynamic reference to a link, is nothing more than splitting tables. That is, converting one type of table to another through the classification shown above in order to avoid data redundancy - this is how normalization can be defined (one of the definitions).
For example. Let there be a database in which the only data modification operation is the addition. In this case, it becomes ineffective each time you change a particular attribute of an entity to “copy” the remaining attribute values into another tuple. In this case, they use NULL or create a static-dynamic reference book, which describes a series of attributes of one semantics or one attribute, and only a foreign key with the primary key of the sequence is duplicated. The same method can be used in a traditional data modification scheme with updating and deleting data.
Conclusion
This classification was created by me on the basis of observations in the design of databases, as well as on the basis of a read theory on designing in relational DBMSs. To my friends and acquaintances studying the discipline of the “database” and involved in the design of databases, and this classification has seriously simplified the “life” and allowed in many situations to pre-select the most suitable and, as it turned out later, the right kind of table for storing those or other data.
The classification can be expanded by dividing the existing species in it into subspecies (perhaps even by adding new species). This classification also showed that in some situations it is better not to use one or another type of table. Some types of tables from this classification are better used less frequently (dynamic reference books). And some try to replace with others (reference-bundles to bundles).
I hope that this classification will not help anyone else while mastering the discipline “Databases” and when designing databases in relational DBMSs.