Our Zabbix

A short summary: an article about the successful implementation of Zabbix with automation of most processes, does not claim to be tutorial, but if you need more details, I can provide it.
For many years our companyused proven and proven monitoring monit + cacti. But everything flows - everything changes. And we grew so much that monit stopped coping. The verification cycle has grown from a minute to 10-20 minutes, which is simply unacceptable! Since monit developers could not help us, it was decided to add (there is never too much monitoring) a new monitoring system. The principle of "work - do not touch" here does not work anymore. Long, short, but the choice fell on Zabbix. Why? They read, argued, thought, and the performer decided. Each system has pros and cons, there is more than enough information about this and everyone chooses what is convenient for him. For example, I already knew how to monitor OracleDB in Zabbix. Perhaps this article will push someone to the side of Zabbix - I will be glad.
So, the main goal I pursued: reliable, fast, convenient and without unnecessary gestures (laziness is the engine of everything). They didn’t bother with iron, they took an old ex6 server from hetzner and hooked up a container there, characteristic:
- CPU: Intel Corporation Xeon E3-1200 Processor
- RAM: 16 GB
- HDD: SATA software RAID 1
In general and in general, it is not impressive, but it will come down at least to the implementation stage.
Zabbix-server is installed and configured on the office. instructions + tuned the database a couple of times. Used CentOS 6.5 nginx + apache + mysql.
Now you need to understand that we will automate (everything?). For this, I’ll tell you what we use the main tools: configuration management system and Redmine. So you need to take the list of hosts and plug-in templates from the configuration management system (did not abbreviate it) and do the tasks automatically in Redmine.
An example of how host lists are stored, for example, the domain.ru client. There is a domain.ru.conf file, and there is a list of servers in it according to the following principle:
d1.domain.ru:
nginx.domain.d1
mysql.domain.d1
zabbix.domain.d1
role4.domain.d1
etc.
Add servers to Zabbix-server.
For this we will use Actions - Auto registration. The thing is very useful. Through the configuration management system, on servers where there is a Zabbix role, we install zabbix-agent and register it in the HostMetadata = d.domain.ru config. you could do just domain, but we have from d. or v. it depends on the node or the container. We register all other settings (server host), restart the zabbix-agent and the whole business.
Now the fraud on the server. For each domain, you need to make host groups and the Auto registration rule itself. And there are a lot of them, and they are arriving. Here ZabbixApi hurries to help us. Documentationit’s good, it is mastered quite easily. There are of course several things that bother, for example, not being able to add a template to the host without overwriting the old templates ... And so, who will need examples of my work with api (I wrote a separate lib in python for myself) I can put it somewhere.
Having mastered ZabbixApi, we just take the current state of the projects (we have the domain.ru.conf files) and create / delete groups and auto-registration rules according to the changes.
I will give an example of the auto-registration rule for a node:

Well, here we went to add a server with standard templates. Now you need to add additional templates according to the server roles in the configuration management system. We write a parser that takes the latest information, compares it with the standard, does or does not do something, and overwrites the standard. Here I ran into the problem that in ZabbixApi you can’t just add a template, the rest are overwritten and you can’t just “not add” it - the history and triggers are not deleted. In the same script, we delete the hosts that are in the template, but which are not in the configuration management system. I will not load the article by listing these scripts, there are a lot of lines, describe the principles:
The simplest is to delete the host, delete if it is in the standard, but according to new data it is not. With the addition, it is worse, that is, if there isn’t in the standard but according to new data, we ignore the host. because we add them through the rules of auto-registration. The main work is on the list of templates. If the host has a new role, then we add to it with one request all the old templates + new. If you deleted one role, then firstly check if there was such a template and if it was, then clean it and untie it from the host.
That's it with the addition of hosts and templates! From us now we only need to add the server to the configuration management system, register the necessary roles for it, and we can enjoy life.
Now the second point, mail notifications is interesting, but we're used to tasks in Redmine. Yes, and Redmine sends us all sorts of SMS and customers see activity on tasks. Redmine also has an API. What we do: configure in Zabbix actions, which under certain conditions executes the Remote command on the Zabbix server. For example, our client site checks for the correct substring in the response, the command looks like this:
/srv/scripts/redmine_api_content.py {TRIGGER.DESCRIPTION} {TRIGGER.STATUS} {TRIGGER.SEVERITY} '{TRIGGER.NAME}' '{ITEM.NAME2} {ITEM.KEY2}: {ITEM.VALUE2}' >> /var/log/zabbix/redmine_api_content.log 2>&1
In the script {TRIGGER.DESCRIPTION} - this is the project in which the task will be created, in ordinary checks (ping, etc.) it passes {HOST.NAME} from which the project identifier is generated. {TRIGGER.STATUS} - if PROBLEM and there is no task with that name, then we create it, if there is a task then add a comment to it. If OK and there is a task - then add a comment otherwise we do nothing. {TRIGGER.SEVERITY} - the importance of the trigger is converted to the task status (high, Crash!). {TRIGGER.NAME} - what’s actually happening :) this will be the name of the task. {ITEM.NAME2} {ITEM.KEY2}: {ITEM.VALUE2} here I add information about the reason for the web check (web.test.error).
I will give a listing of this script, it uses the python-redmine package :
#!/usr/bin/python
import sys, time
from redmine import Redmine
from datetime import datetime, timedelta, date, time as dt_time
if len (sys.argv) != 6:
print "use params: project, status, priority, trigger_name, item_value."
print sys.argv
sys.exit("Erorr! Wrong arguments!")
else:
PROJECT_NAME = sys.argv[1]
TRIGGER_STATUS = sys.argv[2]
TRIGGER_PRIORITY = sys.argv[3]
TRIGGER_NAME = sys.argv[4]
ITEM_VALUE = sys.argv[5]
REDMINE_URL = 'https://factory.example.com'
REDMINE_KEY = 'API_KEY'
# Идентификатор пользователя группы в Redmine на которого назначать задачу
ADMINS_ID = 33
#Идентификатор приоритета задачи
priority = 4
if TRIGGER_PRIORITY == "Disaster":
priority = 14
if TRIGGER_PRIORITY == "High":
priority = 5
#подключаемся к Redmine
redmine = Redmine(REDMINE_URL, key=REDMINE_KEY)
#проверяем наличие такой задачи
issueExist = redmine.issue.filter(
project_id = PROJECT_NAME,
subject = "PROBLEM: "+ TRIGGER_NAME
)
#это используется для файлового лога (избытки привычек)
print datetime.now()
print TRIGGER_STATUS +": "+ TRIGGER_NAME + "\n" + ITEM_VALUE
#Создание задач/комментариев в зависимости от условий
if TRIGGER_STATUS == "PROBLEM":
if issueExist:
print "Issue already exist. Create comment"
issue = redmine.issue.update(
issueExist[0].id,
notes = TRIGGER_STATUS +": "+ TRIGGER_NAME + "\n" + ITEM_VALUE
)
else:
print "Issue not exist. Create issue"
issue = redmine.issue.create(
project_id = PROJECT_NAME,
subject = TRIGGER_STATUS +": "+ TRIGGER_NAME,
tracker_id = 3,
description = TRIGGER_STATUS +": "+ TRIGGER_NAME + "\n" + ITEM_VALUE,
status_id = 1,
priority_id = priority,
assigned_to_id = ADMINS_ID
)
if TRIGGER_STATUS == "OK":
if issueExist:
print "Add comments"
issue = redmine.issue.update(
issueExist[0].id,
notes = TRIGGER_STATUS +": "+ TRIGGER_NAME + "\n" + ITEM_VALUE
)
What we did with the load, it was not in vain that I brought the configuration of iron. With such data:
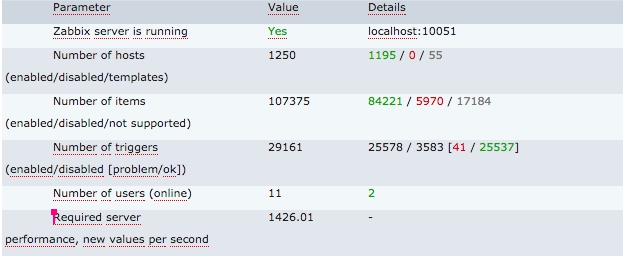
The load on the server is kept in the region of 2-3 la, that is, it is quite worthy. Disks suffer the most because RAM is small. Of course, the system will now be overgrown with new templates and checks, the load will increase and will have to move to new hardware. By the way, a little advice. Exclude from history all history * tables.
Total: Got a working, stuffed with functionality and automated monitoring system. Tasks are created so actively and sensitive to problems that
Author: Roman Burnashev, chief system administrator, centos-admin.ru