Colossus. Google Distributed File System
Colossus (or GFS2) is a proprietary distributed file system from Google, launched on production servers in 2009. Colossus is an evolutionary development of GFS. Like its predecessor, GFS, Colossus is optimized for working with large data sets , scales perfectly, is a highly accessible and fault-tolerant system, and also allows you to reliably store data.
At the same time, Colossus solves some of the problems that GFS could not cope with, and eliminates some of the bottlenecks of its predecessor.

One of the fundamental limitations of the GFS + Google MapReduce bundle, as well as the analogous HDFS + Hadoop MapReduce (Classic) bundle (before YARN ), was its focus solely on batch processing . While more and more Google services - social services, cloud storage, map services - required significantly less delays than those typical of batch processing.
Thus, Google is faced with the need to support near-real-time responses for some types of requests.
In addition, in GFS, the chunk has a size of 64 MB (although the size of the chunk is configurable), which, in general, is not suitable for the services Gmail, Google Docs, Google Cloud Storage - most of the space allocated for chunk remains unoccupied .
Reducing the size of chunk would automatically lead to an increase in the metadata table in which file-to-chunk mapping is stored. And since:
In addition, modern services are geographically distributed. Geo-distribution allows you to both remain available to the service during force majeure, and reduces the delivery time of content to the user who requests it. But the GFS architecture, described in [1], as a classic "Master-Slave" architecture, does not imply the implementation of geographic distribution (at least without significant costs).
(Disclaimer: I did not find a single reliable source that fully describes Colossus architecture, so there are both gaps and assumptions in the architecture description.)
Colossus was designed to solve the GFS problems described above. So the size of chunk was reduced to 1 MB (by default), although it remained configurable. The increasing requirements of the Master servers for the amount of RAM required to maintain the metadata table were met by the new “multi cell” -oriented Colossus architecture .
So in Colossus there is a pool of Master servers and a pool of chunk serversdivided into logical cells. The ratio of the Master server cell (up to 8 Master servers in the cell) to the cells of the Chunk servers is one to many, that is, one cell of the Master servers serves one or more cells of the Chunk servers.
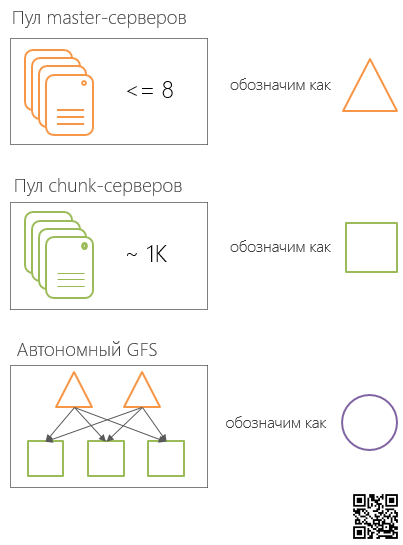
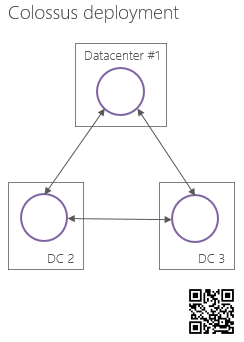
Inside the data center, the group, the Master server cell and the Chunk server cells controlled by it, form a certain autonomous file system (independent of other groups of this type) (hereinafter referred to as SCI, Stand-alone Colossus Instance ). Such SCIs are located in several Google data centers and interact with each other through a specially designed protocol.
Because Since there is no detailed Colossus internal device described by Google engineers in open access, it is not clear how the conflict problem is solved, both between SCI and inside the cell Master servers.
One of the traditional ways of resolving conflicts between peers is quorum of servers . But if there is an even number of participants in the quorum, then situations are not excluded when the quorum does not come to anything — half “for”, half “against”. And since the information about Colossus very often sounds that there can be up to 8 nodes in the Master server cell, the resolution of conflicts with the help of a quorum is called into question.
It is also completely unclear how one SCI knows what data another SCI operates on . If we assume that SCI does not have such titles, then this means that this knowledge should possess:
In general, Colossus as a whole is more likely a “black box” than a “clear architecture” for building geo-distributed file systems that operate on petabytes of data.
Conclusion
As you can see, the changes in Colossus affected almost all elements of the predecessor file system (GFS) - from chunk to cluster composition; at the same time, the continuity of ideas and concepts embodied in GFS is preserved.
One of Colossus' most stellar customers is Caffeine, Google’s latest search engine infrastructure.
[1] Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung. The Google File System. ACM SIGOPS Operating Systems Review, 2003.
[10] Andrew Fikes. Storage Architecture and Challenges. Google Faculty Summit, 2010.
* A complete list of sources used to prepare the cycle.
Dmitry Petukhov,
MCP,PhD Student , IT zombie, a
man with caffeine instead of red blood cells.
At the same time, Colossus solves some of the problems that GFS could not cope with, and eliminates some of the bottlenecks of its predecessor.
Why did you need GFS2? GFS Limitations
One of the fundamental limitations of the GFS + Google MapReduce bundle, as well as the analogous HDFS + Hadoop MapReduce (Classic) bundle (before YARN ), was its focus solely on batch processing . While more and more Google services - social services, cloud storage, map services - required significantly less delays than those typical of batch processing.
Thus, Google is faced with the need to support near-real-time responses for some types of requests.
In addition, in GFS, the chunk has a size of 64 MB (although the size of the chunk is configurable), which, in general, is not suitable for the services Gmail, Google Docs, Google Cloud Storage - most of the space allocated for chunk remains unoccupied .
Reducing the size of chunk would automatically lead to an increase in the metadata table in which file-to-chunk mapping is stored. And since:
- access, relevance support and metadata replication is the responsibility of the Master server;
- in GFS, as in HDFS, metadata is fully loaded into the server’s RAM,
In addition, modern services are geographically distributed. Geo-distribution allows you to both remain available to the service during force majeure, and reduces the delivery time of content to the user who requests it. But the GFS architecture, described in [1], as a classic "Master-Slave" architecture, does not imply the implementation of geographic distribution (at least without significant costs).
Architecture
(Disclaimer: I did not find a single reliable source that fully describes Colossus architecture, so there are both gaps and assumptions in the architecture description.)
Colossus was designed to solve the GFS problems described above. So the size of chunk was reduced to 1 MB (by default), although it remained configurable. The increasing requirements of the Master servers for the amount of RAM required to maintain the metadata table were met by the new “multi cell” -oriented Colossus architecture .
So in Colossus there is a pool of Master servers and a pool of chunk serversdivided into logical cells. The ratio of the Master server cell (up to 8 Master servers in the cell) to the cells of the Chunk servers is one to many, that is, one cell of the Master servers serves one or more cells of the Chunk servers.
Inside the data center, the group, the Master server cell and the Chunk server cells controlled by it, form a certain autonomous file system (independent of other groups of this type) (hereinafter referred to as SCI, Stand-alone Colossus Instance ). Such SCIs are located in several Google data centers and interact with each other through a specially designed protocol.
Because Since there is no detailed Colossus internal device described by Google engineers in open access, it is not clear how the conflict problem is solved, both between SCI and inside the cell Master servers.
One of the traditional ways of resolving conflicts between peers is quorum of servers . But if there is an even number of participants in the quorum, then situations are not excluded when the quorum does not come to anything — half “for”, half “against”. And since the information about Colossus very often sounds that there can be up to 8 nodes in the Master server cell, the resolution of conflicts with the help of a quorum is called into question.
It is also completely unclear how one SCI knows what data another SCI operates on . If we assume that SCI does not have such titles, then this means that this knowledge should possess:
- either the client (which is even less likely);
- either (conditionally) Supermaster (which, again, is a single point of failure);
- or this information (essentially a critical state ) must be located in the storage shared by all SCI. Here, as expected, there are problems of locks, transactions, replication. The latter are successfully handled by PaxosDB, or a repository that implements the Paxos algorithm (or similar).
In general, Colossus as a whole is more likely a “black box” than a “clear architecture” for building geo-distributed file systems that operate on petabytes of data.
Conclusion
As you can see, the changes in Colossus affected almost all elements of the predecessor file system (GFS) - from chunk to cluster composition; at the same time, the continuity of ideas and concepts embodied in GFS is preserved.
One of Colossus' most stellar customers is Caffeine, Google’s latest search engine infrastructure.
List of sources*
[1] Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung. The Google File System. ACM SIGOPS Operating Systems Review, 2003.
[10] Andrew Fikes. Storage Architecture and Challenges. Google Faculty Summit, 2010.
* A complete list of sources used to prepare the cycle.
Dmitry Petukhov,
MCP,
man with caffeine instead of red blood cells.