Web document content extractor

Hello, Habr!
This is my first post in which I want to share my best practices in solving such a problem as highlighting content on a page. Actually, the puzzle has long hung in my head in the background. But it so happened that right now I needed the tool myself, besides I came across an article on the hub: habrahabr.ru/company/mailru/blog/200394 and decided it was time. Okay, let's go.
The way of thinking
Actually, why such a picture at the beginning of the article? The fact is that the problem can be solved in completely different ways. I will not be struck by long discussions about possible solutions, their pros and cons. The main thing is that in this post I approach the task as a classification problem. So, here is the train of thought:
- We come up with a set of factors so that any element in the DOM can be vectorized.
- Somehow we are collecting a bundle of documents.
- In each document, we vectorize all the elements in the DOM below the BODY in the tree. Again somehow.
- For each of the vectorized elements, assign a class of 1 or 0. 0 is not the target, 1 is the target.
- We beat the sample into two parts in a proportion of 50/50 or so.
- We train our classifier on one piece, on the other we test it, we get the result in the form of completeness, accuracy. Well, or any metric like F-score
thousands of them.
An astute reader will surely say that instead of the last two points it is better to do, for example, cross-validation and will be right. In general, this is not important in this case, because the article is primarily devoted to the tool, and not to the associated mathematical / algorithmic details.
Everything seems to be clear about the ideological side of things. Let's look at the technological side.
- I chose python as the language. Mostly because I like it (:
- Sklearn was immediately selected as a math library for learning .
- Since
for some reason Idecided that javascript pages should also be processed successfully, PyQt4 was chosen as the engine for parsing. As it turns out, this is a very good choice.
Decision
As usual, it turned out that the idea does not take into account all sorts of unpleasant "little things." But the fact is that everything sounds great in the previous paragraph, but it is completely not clear how to mark the sample? Those. How to choose target elements in the DOM for further training? And then the correct thought came to my mind: let it be an interactive browser. We will select the target blocks using the mouse and keyboard. A kind of visualized markup process without leaving the browser.
The following was thought: there is a browser in which you can drive with the mouse, and the element under the mouse is “highlighted”. When the desired item is selected, the user clicks a specific hotkey. As a result, the page is parsed, the DOM is vectorized, and the selected element gets class 1, while the rest gets class 0.
results
I don’t want to copy the footcloths from the code here - everything is in the clear and available in the repository . To whom it is necessary - read there. Yes, to whom laziness can be set using pip , but keep in mind, wrote and tested only on Ubuntu> = 12.04.
The result was a library with three main features:
- Interactive content recognition training in the browser. The resulting classifier model is serialized to a file.
- Interactive testing of recognition of content in the browser. Elements that have been classified as targeted on the page are highlighted.
- A console tool that can tear out the html of the target DOM element at a given URL and a model file.
By the way, after installing the constractor bag, two scripts will be available for launch:
- constractor_train.py is an interactive tutorial / test. Tulsa can highlight an element under the mouse pointer, vectorize a page by pressing a hotkey, learn from the data received from different pages, save factors and model to files, load them from files, highlight an element based on the current model.
- constractor_predict.py is the html console rip-off of target elements. In general, this is all that tulza knows (:
Images
For very lazy, I give examples with pictures. For example, we want to teach tulza to determine the cap of Habr.
1) Point the mouse at the header. When the desired area is highlighted (black background), press Ctrl + S. Thus, we added vectorized elements to the selection.
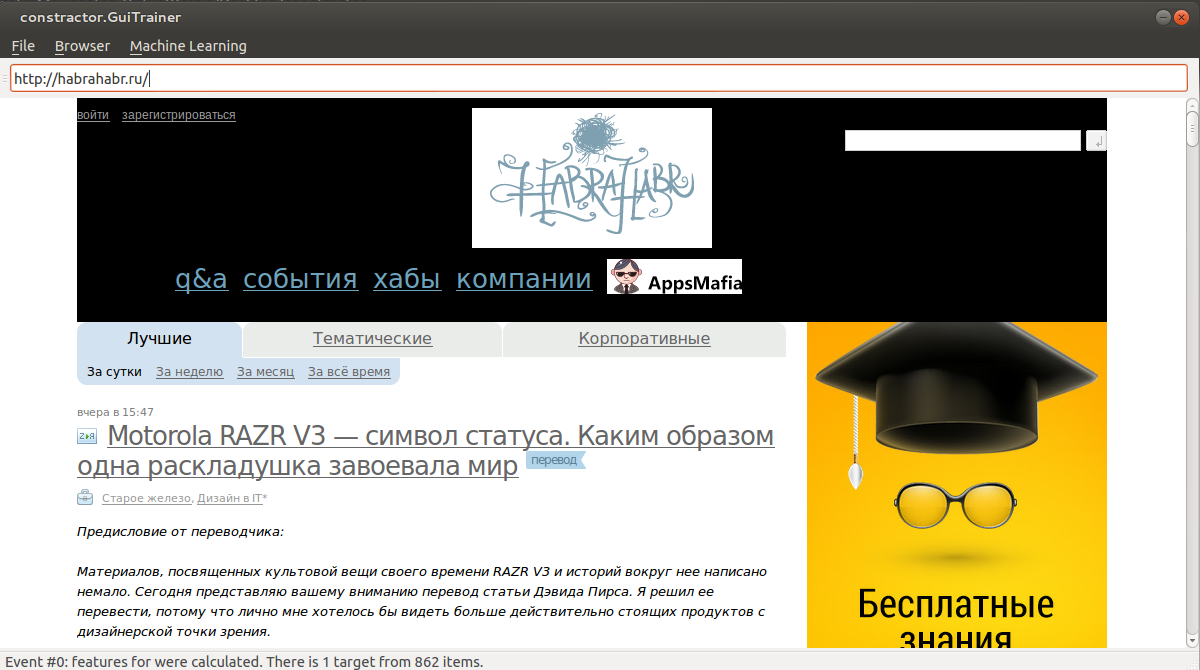
Repeat the procedure several times.

2) Next, press Ctrl + T to learn. We go to an arbitrary page with our header. Press Ctrl + P to forecast.
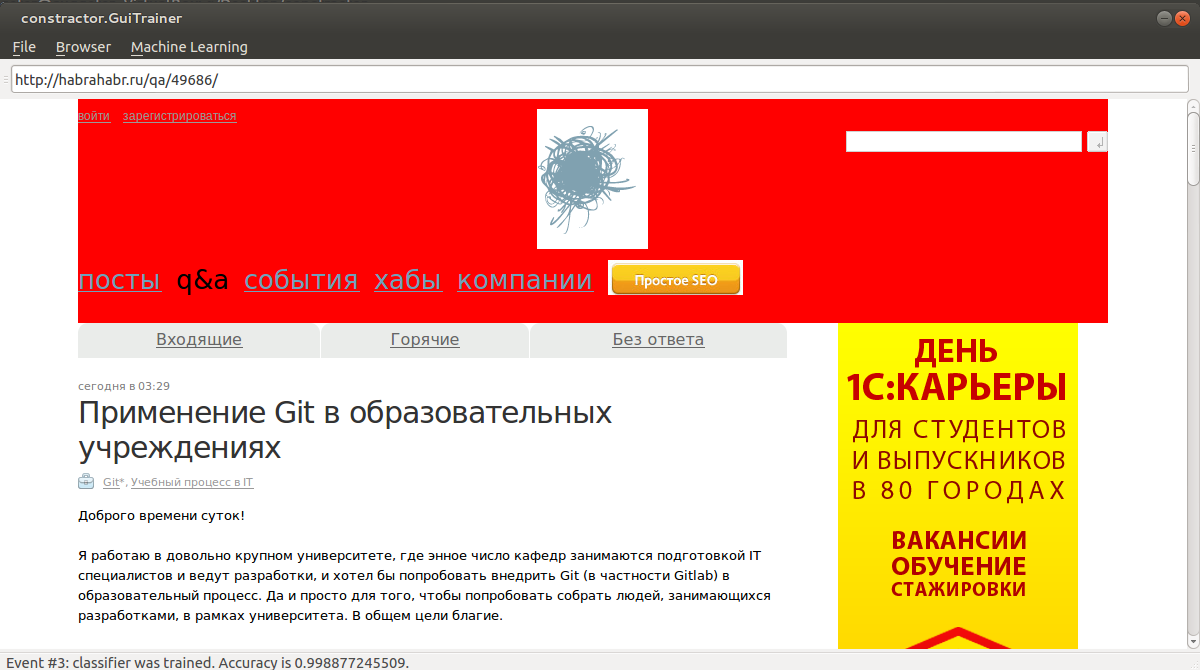
Conclusion
The library is still very raw and requires a lot of improvements, I ask you not to criticize strictly with your
Of the plans for improvements: the expansion of many default factors, the addition of built-in models for recognizing different types of blocks and much more. Of course, I will gradually cut all this in my free time. However, I will be very grateful if there are habro-volunteers who are also ready to donate to the library in their free time.
Thanks for attention!