How to do it: parsing articles

For me, it was always some kind of magic how Getpocket, Readability and Vkontakte parsed links to pages and offer ready-made articles for viewing without ads, sidebars and menus. However, they are almost never mistaken. And recently, a similar task has matured in our project, and I decided to dig a little deeper. I must say right away that this is “white” parsing, webmasters themselves voluntarily use our service.
In an ideal world, all the information on the pages should be semantically marked out. Smart people have come up with a lot of useful things like Microdata, OpenGraph, Article, Nav ... etc tags, but I wouldn’t be in a hurry to rely on the webmasters' consciousness in terms of semantics. It is enough to see the code of the pages of popular sites yourself. Open Graph, by the way, is the most popular format, everyone wants to look beautiful in social networks. networks
The separation of the title of the article and the picture is beyond the scope of my post, since the title is usually taken from title or og, and the picture if it is not taken from og: image is a separate story.
We pass to the most interesting thing - isolating the body of the article.
It turns out that there are quite scientific papers devoted to this problem (including from Google employees). There is even a CleanEval competition with a set of test pages from which to extract data, and algorithms compete in who makes it more accurately.
The following approaches are distinguished:
- Data extraction using only html document (DOM and text layer). We will discuss this technique below.
- Extract data using a rendered document using computer vision. This is a very accurate algorithm, but also the most complex and gluttonous. You can see how it works, for example, here: www.diffbot.com (a project by the guys from Stanford).
- Extracting data at the site level as a whole, comparing pages of the same type and finding the differences between them (different blocks are essentially the right content). Big search engines are doing this.
We are now interested in approaches to extracting an article with only one html document on hand. In parallel, we can solve the problem of defining pages with lists of articles from paginations. In this article, we are talking about methods and approaches, not the final algorithm.
We will parse the page http://habrahabr.ru/post/198982/
List of candidates to become an article
We take all the markup elements of the page structure (for simplicity - a div ) and the text that they contain (if any). Our task is to get a flat list of DIV element -> text in it.
For example, a menu block on the Habré:
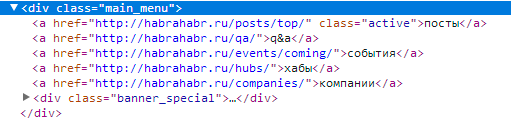
Gives us an element containing the text "posts q & a events of the company’s hub"
If there are nested div elements, their contents are discarded. Child divs will be processed in turn. Example:
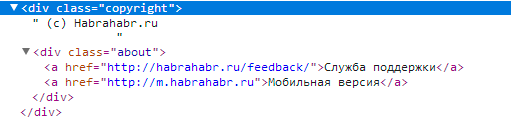
We will receive two elements, in one text © habrahabr.ru , and in the second Support Service Mobile version
We assume that in the 21st century elements that are semantically intended for marking up a structure (div) are not used for marking up paragraphs in the text, and this is true for the top 100 news sites.
As a result, we get a flat set of wood:

And so, we have a set in which we need to classify the article. Further, using various fairly simple algorithms for each element, we will lower or increase the probability coefficient for the presence of articles in it.
We do not throw out the DOM tree, we will need it in the algorithms.
Find repeating patterns.
In all elements of the DOM tree, we find elements with repeating patterns in the attributes (class, id ..). For example, if you look closely at the comments:

It becomes clear what a repeating pattern is:
- The same set of classes for elements
- Same text substring in id
We pessimize all these elements and their “children”, that is, we put a certain lowering coefficient depending on the number of repetitions found.
When I talk about "kids" I mean that all nested elements (including those that fell into our classification set) will receive pessimization. For example, an element with comment text also falls under the distribution:
The ratio of links to plain text in an element.
The idea is clear - in the menu and in the columns we see solid links, which is clearly not like an article. We go over the elements from our set and each affix a coefficient.
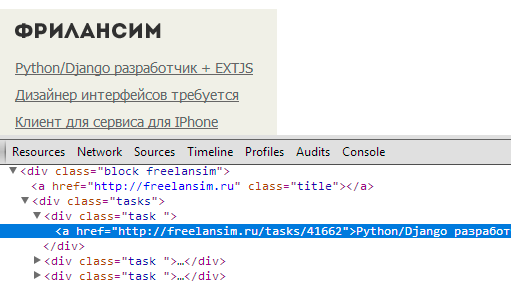
For example, the text in the elements in the Freelansim block (we already got a minus for a repeating class), get a minus in the catch for an ugly ratio of links to text equal to one. It is clear that the smaller this coefficient, the more the text looks like a meaningful article:
The ratio of text markup to text elements
The more block of any markup (lists, hyphenation, span ...), the less chance that this article. For example, advertising probably a respected SEO company is not very similar to an article, since it is a complete list. The lower the markup to text ratio, the better.

The number of points (sentences) in the text.
Here we have almost crawled into the territory of numerical linguistics. The fact is that in the headers and menus the dots are practically not put. But in the body of the article there are many of them.
If some menus and lists of new materials on the site still crawled through the previous filters, then you can finish off by counting points. Not very many of them in the block are the best: the

more points, the better, and we increase the chances of this element to receive the proud title of the article
The number of blocks with text about the same length
Many blocks with text about the same length are a bad sign, especially if the text is short. We are pessimizing such blocks. The idea will work well on a similar layout:
In the example, not Habr, since this algorithm works better on more strict grids. On comments on Habré for example, it will not work very well.
The length of the text in the element.
There is a direct correlation - the longer the text in the element, the greater the chance that this article.

Moreover, the contribution of this parameter to the final grade of the element is very significant. 90% of cases of article parsing can be solved by this method alone. All previous surveys will raise this chance to 95%, but at the same time they eat the lion's share of processor time.
But imagine: a comment the size of the article itself. If you simply determine the article by the length of the text, confusion will occur. But there is a high chance that the previous algorithms will slightly cut the wings of our graph commentator, as the element will be pessimized for a repeating pattern in id or class.
Or another case - a weighty drop-down menu made using
Готовые алгоритмы для вашего языка можно найти по запросам "boilerplate algorithm", "readability algorithm"