Using the Haar Cascade to Compare Images
The signs of Haar, which I will talk about, are known to most people who are somehow connected with recognition systems and machine learning, but, apparently, few people use them to solve problems outside the standard scope. The article is devoted to the use of Haar cascades for comparing close images, in the tasks of tracking an object between adjacent frames of a video, finding a match in several photos, searching for an image in an image, and other similar tasks.

In most cases, when you need a simple comparison of two fairly similar fragments of an image, it is realized through their covariance (or something similar). A sample is taken (flower in the photo) and moves along the image along X and Y in search of a point where the difference between the sample ( J ) and the image ( I ):
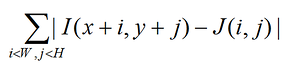
reaches its minimum.
This method is very fast to implement, intuitive and thoroughly known. Perhaps I have not met a single development group wherever it is used. Of course, everyone knows his flaws wonderfully:
- Instability when changing lighting
- Instability when zooming or rotating the image
- Instability if part of the image is a changing background
- Low speed - if you need to detect the n * n region in the m * m image, the number of operations will be proportional to n2 ∙ (mn) 2.
Everyone also knows how to deal with these shortcomings.
- Lighting is neutralized by normalization or the transition to binarization of the area .
- Scale changes and small turns are neutralized by a change in resolution during correlation.
- With this approach, no one fights with this approach.
- Speed is optimized by searching in large steps or at low resolution.
In situations where the results of correlation are not enough, they switch to more complex methods, such as comparing feature point maps ( SURF ), borders, or directly selecting objects. But these algorithms are completely different: in most cases they are quite slow, they are difficult to write from scratch (especially on any DSP processor), there are limitations on the image structure.
At some point, thinking over the next project, I ran into a problem where it was required to compare several variable areas in the image. And I thought, until I remembered the Predator algorithm , once mentioned on Habr , where fast and stable object tracking in video was shown. With a little thought, I realized that this whole approach, allowing to solve a large class of problems, passed me by.
Let me remind you what the signs of Haar are. Cascades of features are commonly referred to as the basis for constructing systems for distinguishing complex objects such as faces , hands, or other objects . In most articles, this approach is inextricably linked to the AdaBoosta learning algorithm . The Haar cascade itself is a set of primitives for which their convolution with an image is considered. The simplest primitives are used, consisting of rectangles and having only two levels, +1 and -1. In addition, each rectangle is used several times in different sizes. By convolution here we mean s = XY , where Y is the sum of the image elements in the dark region, and X- the sum of the image elements in the bright region (you can also take X / Y , then there will be stability when zooming).

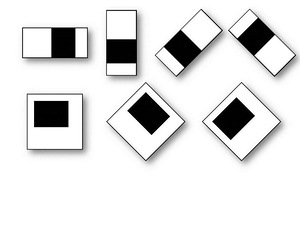
Such convolutions emphasize the structural information of the object: for example, the following convolution will always be negative for the center of a person’s face: The


eyes will be darker than the area between them, just as the area of the mouth will be darker than the forehead. The more different primitives are used, the more accurately you can then classify an object. Moreover, if an exact classification is not needed - you can use fewer primitives.
Here we can mention that in the problem of object recognition, after the sets of features for the test sample are built, training algorithms ( AdaBoost , SVM) determine the sequence (cascade) of convolutions corresponding to the object. When an object is recognized in the image, it is compared with the test image.
What is Haar's plus, and why one cannot use such wonderful and physical curves as, for example, sinusoids and Gaussians instead of these ugly rectangles?
The plus is that Haar cascades are very quickly counted through the integral representation of images . This is described in more detail by reference, and here I will only briefly say that the integrated image is represented as:
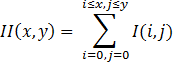
The value at the point X, Y of the matrix ( II ) obtained from the original image ( I) is the sum of all points in the rectangle (0,0, X, Y). Then the integral over any rectangle (ABCD) in the image can be represented as:
SumOfRect (ABCD) = II (A) + II (C) - II (B) - II (D)
Which gives only 4 memory accesses and 3 mathematical actions for counting the sum of all elements of a rectangle, regardless of its size. When calculating other convolutions other than convolutions of Haar primitives, a number of actions is required proportional to the square of the size of the primitive (if not calculated through the FFT, which is not possible for any patterns).
Let's get back to our task. Suppose we want to find a small fragment ( J ) in a large image ( I) In order to do this, training is not required. One fragment is still impossible to produce. Haar's primitives will help get the image of J and look for exactly it on I. It is enough to get convolutions J with a set of Haar signs and compare with a set of convolutions of the same primitives calculated on I in windows proportional to a small fragment.
Pros:
- Resistance to change of lighting, even if it is a local change of lighting, resistance to noise (primitives are the simplest band-pass filter ).
- If the primitives were not very small, then correlation is much more stable when changing the scale (the size of the primitives will not affect the accuracy, if bypassing with a small step).
- If the signs on a large image are calculated in advance, and when the search window is shifted, it’s already calculated and relevant for it - the search will be much faster than correlation (you need to compare fewer elements).
Moreover, it is clear that a number of fairly simple optimizations can be carried out that will accelerate and refine this approach.
If someone wanted to play, I wrote a small program in which the simplest version of this algorithm is implemented. The program maintains the selected fragment in the video stream. EmguCV for camera hooking and simple image transformations (Haar done manually).