What is it - it looks like a memekesh, behaves like a memekesh, but not a memekesh?
Good day, colleagues!

Today I will tell you about how, without making a large number of changes to the application, improve its performance. It will be about our small "bicycle" [1], designed to replace memcache in some cases.
The article was written according to my report “Around is cheating or using standard protocols for non-standard things” [2] on DevConf'12 .
Introduction
We recently talked about the architecture of the Plus1 WapStart mobile advertising network . If you have not read, you can read the link.
We are constantly monitoring bottlenecks in our application . And at one point, the logic for selecting a banner became such a bottleneck for us. The matter was complicated by the fact that over the years the application has existed, our code has grown with a large number of poorly documented business logic. And, as you know, rewriting from scratch was not possible for obvious reasons.
The logic of selecting a banner can be divided into 3 stages:
- Determining the characteristics of the request.
- Selection of banners suitable for request.
- Cutoffs at runtime.
The stage number 1 turned out to be problematic for us. Moreover, the trouble came from where they did not wait - from
India.
India is considered here for the reason that for us it is a rare traffic and there was a real business case when India came to us
Usually, all the data necessary to determine the characteristics of a request is in the cache, and only a small percentage of requests are in the database.

But in the case when India comes to us, we practically have nothing in the cache and 70-90% of requests go to the database. This causes certain problems and we give the banner a little slower than we would like.
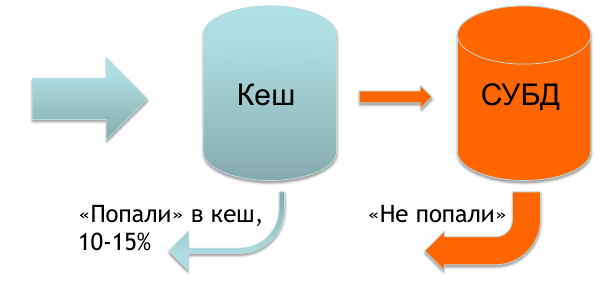
And then we got an idea how to solve the problem of the speed of return of the banner.
Project "Fish": an idea
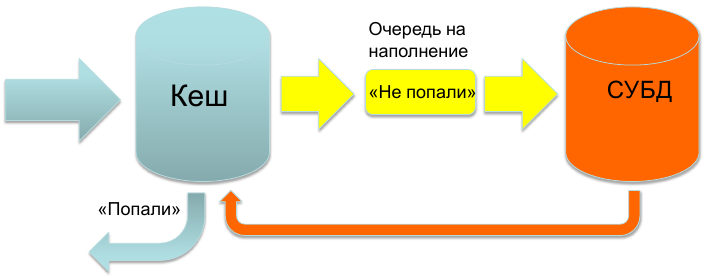
The idea can be expressed quite simply: we must always respond from memory. A request came, we poll the store for the availability of data, if there is data - immediately give an answer. Otherwise, we add the request data to the filling queue and respond with an empty answer, without waiting for the data to appear.
Due to the fact that we use memcache for caching, it was decided to use its protocol to implement the indicated idea.
Project "Fish": the first iteration
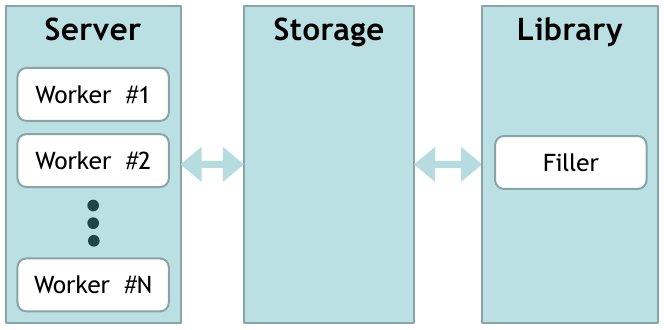
The implementation is fairly standard. There is a set of workers that accept connections (their number is configurable). Workers go to the repository for data. The repository responds. In case there is no data, we add the request to the queue. In addition, there is a separate content flow that takes requests from the queue and asks for data about them from the library. The received data is added to the repository.
The library can be any. In our case, it requests data from the database.
We changed the application logic so that the characteristics of the request are taken from our cache (a key is formed from the request and we ask for get key_with_request_characteristics ). In this configuration, everything worked fine except for a few issues.
Problems and their solution
Firstly, we are faced with the problem of data deletion. Upon reaching the limit on the allocated memory, the storage began to be cleaned. All existing data was scanned, TTL was checked and, if necessary, the data was deleted. At this point, there were delays in the response due to the fact that the removal is a blocking operation. We solved it quite simply: we introduced limits on the size of the data to be deleted. By varying this parameter, we were able to minimize the loss in speed at the time of cleaning.
The second problem was the presence of a large amount of duplicated data in the storage (slightly different requests may correspond to the same characteristics). Here, for its solution, we came up with the following improvement.
Project "Fish": second iteration

On the whole, the picture remained the same , with the exception of two functional units that we added to the library.
The first is Normalizer . We normalize all queries (we bring to the standard form). And in the store we are looking for data already on the normalized key.
As I wrote above, a key is generated from the request. The key is this composite. For ourselves, we decided to sort the parts of this key in lexicographic order.
The second is Hasher . It serves to compare data. Now we do not add the same data to the storage twice.
If earlier we stored a key-value pair, now we store keys and data separately. There is a one-to-many relationship between keys and data (one data can correspond to many keys).
And again, everything seems to be fine, but again we were faced with the problem of deleting data.
Problems and their solution
Removal is performed according to the following algorithm. We look among the keys for those that are already outdated and delete them. Then we check the data, if there are those for which there are no keys left, we delete them.
Due to the specifics, we get a large number of small keys. To check them all (even before the set limit for deletion) it takes a lot of time (for us a few tenths of a lot).
The solution here seems to me quite obvious. We added an index at the time of adding the key. If it is necessary to delete data, we bypass the keys at this index and delete to the limit, thereby minimizing the time consumption.
In addition to the deletion problem, there is still the “first request problem” - we respond with an empty request when there is no data. It is from the first version, but for us it is permissible and in the near future we do not plan to solve it.
Conclusion
For us, the introduction of "fish" into the battle allowed us to minimize the cost of rewriting the code. The application logic has not changed much, we just began to poll another cache. And now in the case of rare requests, we respond quickly and confidently.
This is certainly not the last implementation (we can consider it alpha), we are working on improving productivity and related tasks. But now the code can be viewed on GitHub [3]. The project was called swordfishd [1]. There you can also find our other products torn to pieces in open-source.