Hg Init: Part 1. Retraining for Subversion Users
- Transfer
Hg Init: Mercurial Tutorial.
 Mercurial is a modern open source distributed version control system. This system is a tempting replacement for earlier systems like Subversion. In this six-part simple tutorial, Joel Spolsky talks about the key principles of Mercurial.
Mercurial is a modern open source distributed version control system. This system is a tempting replacement for earlier systems like Subversion. In this six-part simple tutorial, Joel Spolsky talks about the key principles of Mercurial. If you used Subversion, then Mercurial will be incomprehensible. This part talks about the main differences when working with Mercurial. If you have never used Subversion, you can simply skip this part .
Part 1. Retraining for Subversion Users
What confusion I was when the programmers in my company decided to change Subversion to Mercurial!
 To begin with, I began to give all kinds of stupid reasons why we do not need to change anything. “We need to store the repository on a central server, it's safer,” I said. You know what? I was wrong. When working with Mercurial, each developer has a full copy of the repository on their hard drive. It is actually safer . In any case, in almost every team using Mercurial, a central repository also exists. And you can backup this repository with all the necessary obsession. And you can arrange a three-stage defense with Cylon , Attack aircraft and lovely Labradoodle.or whatever your IT department requires.
To begin with, I began to give all kinds of stupid reasons why we do not need to change anything. “We need to store the repository on a central server, it's safer,” I said. You know what? I was wrong. When working with Mercurial, each developer has a full copy of the repository on their hard drive. It is actually safer . In any case, in almost every team using Mercurial, a central repository also exists. And you can backup this repository with all the necessary obsession. And you can arrange a three-stage defense with Cylon , Attack aircraft and lovely Labradoodle.or whatever your IT department requires. “The problem with distributed version control systems is that they make branching too easy,” I said. "And branches always bring problems." It turns out that here I was also wrong. The wave has gone. The branches are a problem when working with Subversion , because Subversion does not store enough information to merge (merge) worked fine. In Mercurial, merging is painless and easy, and therefore branching is common and harmless.
Then I said: "Well, I will use this system, but do not expect that I can figure it out." And I asked Jacob to make a cheat sheet for me, which will be everything that I usually did in Subversion, with analogues in Mercurial.
I can show you this cheat sheet, but I won’t, because it prevented my brains from rebuilding for several months.
It turns out that if you used Subversion, then your head is a little ... Uh, how would you say softer? You are wounded in the head! No, it didn’t work out. You need retraining. I walked around so wounded for six months and thought Mercurial was more complicated than Subversion. But this is because I did not understand how the new system actually worked. As soon as I understood how it works, it turned out - oops! yes it is simple enough.
So I wrote this manual for you, in which I tried very hard not toexplain everything in Subversion terms, because there are enough already wounded in the head. There are enough of them. Instead, for those who switch to Mercurial with Subversion, I wrote this part at the beginning of the tutorial, which will try to eliminate as much harm as possible so that you can learn Mercurial from scratch.
If you have never used Subversion, you can skip to the next article ( “Mercurial Basics” ) and don't miss a thing.
Ready? Ok, let's start with a short survey.
Question one: Do you always write the perfect code the first time?
If you answered “Yes” to the first question, then you are a liar and a swindler. Get a “banana” and come for a retake.
The new code is buggy. It takes time for him to start working decently. In the meantime, this code can hurt the rest of the developers on the team.
And here is how Subversion works:
- When you bring new code into the repository, everyone gets it.
Since all the new code you write contains bugs, you have a choice.
- You can make buggy code and drive people crazy, or
- You can hold on to the new code until you completely debug it.
Subversion constantly confronts you with this terrible choice. Either the repository is full of buggy code because it contains new code that has just been written, or new code that has just been written is not added to the repository.
As users of Subversion, we are so used to this dilemma that it is difficult to imagine a system where this dilemma does not exist.
A team using Subversion often adds nothing to the repository for days or weeks. In such teams, newcomers are afraid to upload something to the repository due to fear of breaking the build, or pissing off Mike, the lead developer, or for similar reasons. Mike once became so angry because of the changes that broke the build that he burst into the trainee, brushed everything off his desk and yelled: “This is your last day!” This day was not the last, but the poor trainee practically wet his pants.
All of these fears and concerns mean that people write code week after week without taking advantage of the version control system , and then look for someone experienced to put the code into the repository. And why the repository, if it cannot be used?
Here is a simple illustration of life with Subversion:

When working with Mercurial , each developer has their own repository that lives on their computer:
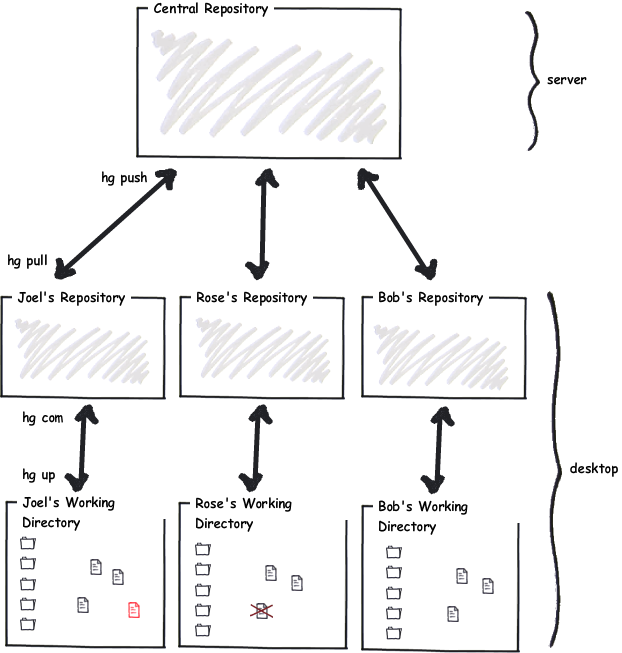
So you can make changes to your repository and enjoy all the benefits of the version control system whenever you want. Each time, having slightly improved the code, you can add it to the repository.
When the code is reliable and you want to let others use it, you push your changes from your repository to the central repository. Everyone pulls general changes from the central repository and sooner or later everyone will receive your new code. When he is ready.
Mercurial separates the moment the code is entered into the repository and the time it is received by all the others.
And that means you can commit (
hg com), but everyone else will not get your changes. When you have accumulated changes that suit you, that are stable and cool, you push (hg push) them to the main repository.Another big conceptual difference
Do you know that every street has a name?
 Well, it turns out that in Japan this is not entirely true. The Japanese usually just number the blocks between the streets and only very, very important streets have names.
Well, it turns out that in Japan this is not entirely true. The Japanese usually just number the blocks between the streets and only very, very important streets have names. Subversion and Mercurial have a similar difference.
Subversion thinks in revisions . Revision is how the entire file system looks at a particular point in time.
In Mercurial, you think in sets of changes . A change set is a clear list of changes between two adjacent revisions.
Six or half a dozen of it - what's the difference?
That is the difference. Imagine that you and I are working together on some kind of code. And we made branches of this code, and each went to his own place and made many, many independent changes in the code, so that the branches quite diverged in different directions.
When we need to do a merge, Subversion looks at both revisions - my modified code and your modified code - and tries to guess how to mold them together into one big scary mess. Usually, Subversion does not succeed, and you get long lists of conflicts (“merge conflicts”), which are not really conflicts, but simply places where the system could not figure out our changes.
For comparison, if we independently worked in Mercurial, the system saved a series of changes. Thus, when we want to do code merging, Mercurial actually has much more information: the system knows that each of us has changed , and can reapply these changes instead of looking at the final version and trying to guess how to put it all together together.
If, for example, I changed some function a bit and moved it somewhere, then Subversion doesn’t really remember that. So when it comes to merging, she just might decide that a new function appeared in the code from nowhere. At the same time, Mercurial will remember: the function has changed, the function has moved. This means that if you also changed this function, then the likelihood that Mercurial will successfully merge our changes is much greater.
Since Mercurial thinks in terms of change sets, you can do interesting things with these change sets. You can let a friend try these changes instead of making these changes to the central repository and forcing everyone to use them.
If all this seems a little confusing to you - do not worry. As you read this manual, everything will become clear. At the moment, the most important thing you need to know: due to the fact that Mercurial operates with changesets and not revisions, merging code in Mercurial works much better than in Subversion .
And that means you can freely make branches because merging will not be a nightmare.
Want to find out something funny? Almost every team using Subversion that I talked to has a version of the same story. The story is so common that I will simply call it the “Subversion Main Story”. Here is the story: at some point, they tried to make a branch in the development of the code. Usually, in order for the version that was given to customers to be separated from the version with which developers are busy. And everyone told me that when they tried to do this, everything was fine until the moment when they needed to do a merger. And the merger was a nightmare. What was supposed to be a five-minute process turned into six programmers around one computer, who worked for two weeks, trying to manually enter each bugfix from a stable branch into the development branch.
And almost every team told me that they vowed "never again" and abandoned the branches. And now they do this: each new feature in a large
#ifdefblock. So they can always work in the trunk of the repository, and clients never receive new code until it is debugged, and, frankly, this is ridiculous. Separating stable and development code is exactly what a version control system should allow you to do .
With the switch to Mercurial, you may not even realize this, but branching will again be possible and you will not need to be afraid of anything.
This means that you can have team repositories where a small team of programmers is working on a new feature, and when everything is ready, merges its changes into the main repository. And it works !
This means that you may have repositories for the testing service, where a team of testers tries new code. If it works, then the testing service makes changes to the central repository, which, in turn, means that the central repository always has reliable tested code. And it works !
This means that you can conduct experiments in separate repositories, and if the experiments are successful, merge the changes into the main repository, and if they are unsuccessful, simply throw them away. And it works !
And the last big conceptual difference
The last important conceptual difference between Subversion and Mercurial is not so important, but it can put you in an uncomfortable position if you do not know about it. Here it is:
Subversion is essentially a change control system for files , and in Mercurial, change control is applied to the entire directory, including all subdirectories.
This mainly manifests itself as follows: in Subversion, if you are in a subdirectory and make your changes to the repository, then only changes are made from this subdirectory and all its subdirectories. This may cause you to forget to make changes from another subdirectory. And in Mercurial, all commands are always applied to the entire directory tree. If your code is in c: \ code , then when you execute
hg commit, you can be in c: \ code or in any subdirectory - the result will be the same. This is not so important, but if you are used to having one giant repository for the whole company, in which some people work only with certain subdirectories that concern them, then know that this is not the best method when working with Mercurial. You better have a lot of smaller repositories for each project.
And finally ...
Now the part where you just have to take my word for it.
Mercurial is better than Subversion.
Better if you work on the code in a team. Better if you work on the code alone.
Just better .
And, remember my words, if you understand how Mercurial works, and how Mercurial works, and you don’t struggle with this system, and you don’t try to do everything with Mercurial just like you did in Subversion, but instead learn work as Mercurial expects from you, you will be happy, successful, well-fed and you can always find a remote control from the TV.
And at first you will be tempted by the thought - I know, will be - to quit Mercurial and return to Subversion. Because it will be strange as if you live in a foreign country, and you will be pulled back to your homeland, and you will come up with all kinds of excuses like stating that in Mercurial working copies take up too much space, that there is bullshit, since in fact in fact, they take up less space than in Subversion. It's true!
And then you will return to Subversion, because you tried to make branches the same way as in Subversion, and got confused, and it didn’t work out very well, because you really had to do branches as in Mercurial, cloning repositories, not trying to do so, how it worked in Subversion, but to learn the method accepted in Mercurial, which, believe me, works .
And after that, you ask Jacob, or whoever has the equivalent of Jacob in your office, to give you the Subversion to Mercurial cheat sheet, and you will spend three months thinking
hg fetchit’s like svn upnot understanding what it’s actually doing hg fetch, and one day everything will go wrong and you will blame Mercurial, although you should blame yourself for not understanding how Mercurial works. I know you will do so, because that is what I did.
Do not make the same mistake. Learn Mercurial, trust it, figure out how to do everything in its style, and you will advance a whole generation in the field of version control systems. While your competitors spend a week resolving conflicts that arose after the provider updated the library, you’ll print
hg mergeand say to yourself, “Oh, my God, this is cool, it just worked.” And Mike will relax and share a joint with trainees, and spring will come, and young people from a nearby college will change their down jackets to short torn t-shirts, and life will be good. Continued here:
Hg Init: Part 2. The Basics of Mercurial