Cartesian tree: Part 1. Description, operations, applications
Table of contents (currently)
Part 1. Description, operations, applications.
Part 2. Valuable information in the tree and multiple operations with it.
Part 3. Cartesian tree by implicit key.
To be continued ...
Cartesian tree (treap) is a beautiful and easily implemented data structure that with minimal effort will allow you to perform many high-speed operations on your data arrays. What is characteristic, on Habrahabr I found his only mention in the review post of the esteemed winger , but then the continuation of that cycle did not follow. It's a shame, by the way.
I will try to cover everything that I know on the subject - despite the fact that I know relatively little, there will be enough material for two or even three posts. All the algorithms are illustrated by C # sources (and since I am a lover of functional programming, somewhere in the afterword we will also talk about F # - but this is not necessary to read :). So let's get started.
Introduction
As an introduction, I recommend reading a post about binary search trees of the same winger , because without understanding what a tree is, a search tree, as well as without knowing the complexity of the algorithm, much of the material in this article will remain for you a Chinese letter. It's a shame, right?
The next item in our compulsory program is heap . I think that many people also know the data structure, but I will give a brief overview.
Imagine a binary tree with some data (keys) at the vertices. And for each vertex, we without fail require the following: its key is strictly greater than the keys of its immediate sons. Here is a small example of a valid heap:
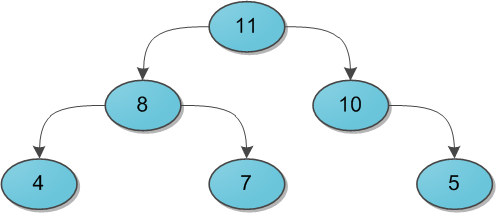
I’ll say right away that it’s not necessary to think of the heap solely as a structure in which the parent has more than his descendants. Nobody forbids to take the opposite option and assume that the parent is smaller than the descendants - most importantly, choose one for the whole tree. For the needs of this article, it will be much more convenient to use the option with the “more” sign.
Now behind the scenes the question remains, how can you add and remove elements from the heap. Firstly, these algorithms require a separate place for inspection, and secondly, we still do not need them.
Problems
When it comes to search trees (you already read the recommended article, right?), The main question posed to the structure is the speed of operations, regardless of the data stored in it, and the sequence of their arrival. So, the binary search tree gives a guarantee that the search for a specific key in this tree will be performed in O (H), where H is the height of the tree. But what height can be - the devil knows him. Under adverse circumstances, the height of the tree can easily become N(the number of elements in it), and then the search tree degenerates into a regular list - and why then is it needed? To achieve this situation, it is enough to add elements from 1 to N in the ascending queue in the search tree - with the standard algorithm for adding to the tree, we get the following picture:
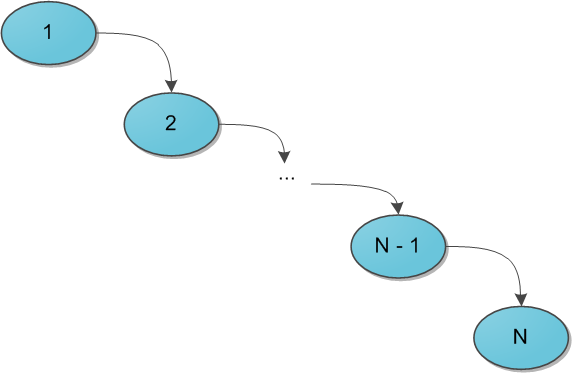
A huge number of so-called balanced search trees were invented - roughly speaking, those in which as the tree exists at Each operation on it maintains the optimality of the maximum depth of the tree. The optimal depth is of the order of O (log 2N) - then the same order has the execution time of each search in the tree. There are many data structures supporting this depth, the most famous are red-black wood or AVL-tree. Their distinguishing feature in most cases is a difficult implementation, based on the size of a hell of a heap of cases in which you can get confused. Conversely, the Cartesian tree compares favorably with its simplicity and beauty, and even gives us in some way the very coveted logarithmic time, but only with a rather high probability ... however, about such details and subtleties later.
Definition
So we have the data of the tree - the keys x (hereinafter it is assumed that the key is the very information that we store in the tree; when later it will be necessary to separate the user information from the keys in meaning, I will say it separately). Let's add another parameter to them in a pair - y , and call it priority . Now we’ll build such a magic tree that stores two parameters at each vertex, and at the same time it ’s a search tree by its keys and a bunch of priorities . Such a tree will also be called Cartesian.
By the way: the name treap is very popular in English literature , which clearly shows the essence of the structure: tree + heap. In the Russian-speaking, one can sometimes find those compiled according to the same principle: deramide (tree + pyramid) or ducha (tree + heap).
Why is a tree called cartesian? This will immediately become clear as soon as we try to draw it. Take some set of key-priority pairs and arrange the corresponding points (x, y) on the grid. And then we connect the corresponding vertices with lines, forming a tree. Thus, the Cartesian tree fits perfectly on the plane due to its limitations, and its two main parameters - the key and priority - in a sense, the coordinates. The result of the construction is shown in the figure: on the left in the standard tree notation, on the right on the Cartesian plane.

So far, it’s not very clear why this is necessary. And the answer is simple, and it lies in the following statements. First, let many keys be given: many different trees, including list-like ones, can be built from the correct search trees. But after adding priorities to them, a tree of these keys can be built only one, regardless of the order of receipt of the keys. This is pretty obvious.
And secondly, let's now make our priorities random. That is, we simply associate a random number from a sufficiently large range with each key, and it will serve as the corresponding player. Then the resulting Cartesian tree with a very high probability of 100% will have a height not exceeding 4 log 2N. (I will leave this fact without proof here.) So, although it may not be perfectly balanced, the search time for a key in such a tree will still be of the order of O (log 2 N), which we, in fact, sought.
Another interesting approach is not to make priorities random, but to remember that we have a huge amount of some additional user information, which, as a rule, has to be stored at the tops of the tree. If there is reason to believe that this information is essentially random enough (the user's birthday, for example), then you can try to use it for personal gain. Take either information directly or the result of some function from it as a priority (only then should the function be reversible in order to restore information from priorities if necessary). However, it is necessary to act here at your own peril and risk - if after some time the tree is very unbalanced and the whole program starts to slow down significantly, you will have to urgently invent something to save the situation.
Further, for simplicity, we assume that all keys and all priorities in the trees are different. In fact, the possibility of equality of keys does not create any special problems, you just need to clearly determine where the elements equal to this x will be located - either only in its left subtree, or only in the right one. Equality of priorities in theory also does not constitute a particular problem, except for contamination of evidence and reasoning by special cases, but in practice it is better to avoid it. The random generation of whole priorities is quite suitable in most cases, real between 0 and 1 - in almost all cases.
Before starting the story about operations, I will give you a blank of the C # class, which will implement our Cartesian tree.
public class Treap { public int x; public int y; public Treap Left; public Treap Right; private Treap(int x, int y, Treap left = null, Treap right = null) { this.x = x; this.y = y; this.Left = left; this.Right = right; } // здесь будут операции... }
For simplicity, I made an exposition of the x and y typesint, but it is clear that in their place there could be any type whose instances we can compare with each other - that is, any that implementsIComparableeither in C # terms. In Haskell, it could be any type from the class , in F # any with restrictions on the comparison operator, in Java it implements an interface , and so on.IComparableOrdComparable
The magic of glue and scissors
The pressing issues on the agenda are how to work with the Cartesian tree. I’ll postpone the question of how to build it from a crude set of keys altogether, but for now suppose that some kind soul of the initial tree has already been built for us, and now we need to change it if necessary.
All the ins and outs of working with the Cartesian tree consists of two main operations: Merge and Split . With the help of them, all other popular operations are elementarily expressed, so let's start with the basics.
The Merge operation accepts two Cartesian trees L and R as input . From it is required to merge them into one, also correct, Cartesian tree T. It should be noted that the Merge operation can work not with any pairs of trees, but only with those for which all the keys of one tree (L) do not exceed the keys of the second (R). (Pay special attention to this condition - it will come in handy more than once in the future!)

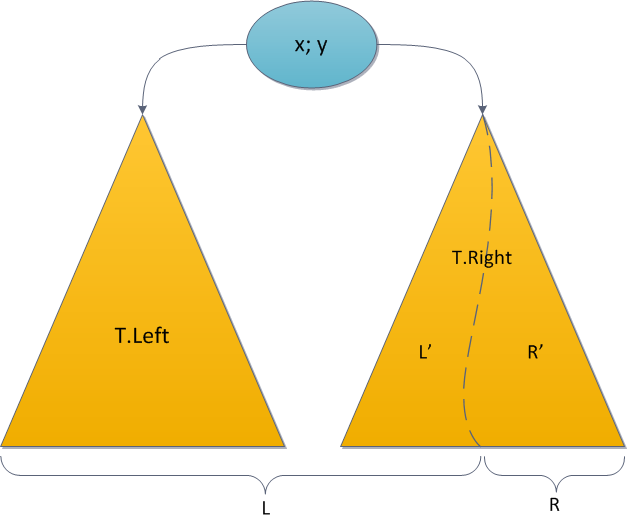
The algorithm of Merge is very simple. Which element will be the root of the future tree? Obviously with the highest priority. We have two candidates for maximum priority - only the roots of two source trees. Compare their priorities; for uniqueness, let the priority y of the left root be greater, and the key in it is equal to x. A new root is defined, now it’s worth considering which elements will appear in its right subtree and which in the left one.
It is easy to understand that the whole tree R will be in the right subtree of the new root, because it has keys greater than x by condition. In the same way, the left subtree of the old L.Left root has all keys smaller than x and should remain the left subtree, and the right subtree L.Right ... but the right subtree should be on the right for the same reasons, however, it’s not clear where to put its elements, and where are the elements of the tree R?
Stop, why is it unclear? We have two trees, the keys in one are less than the keys in the other, and we need to somehow combine them and attach the result to the new root as the right subtree. Just recursively call Merge for L.Right and the R tree, and use the tree returned by it as the new right subtree. The result is obvious.
The figure in blue shows the right subtree of the resulting tree after the Merge operation and the connection from the new root to this subtree.

The symmetric case - when the priority at the root of the tree R is higher - is disassembled similarly. And, of course, we must not forget about the basis of recursion, which in our case occurs if one of the trees L and R, or both, are empty.
Download Source Package Merge:
public static Treap Merge(Treap L, Treap R) { if (L == null) return R; if (R == null) return L; if (L.y > R.y) { var newR = Merge(L.Right, R); return new Treap(L.x, L.y, L.Left, newR); } else { var newL = Merge(L, R.Left); return new Treap(R.x, R.y, newL, R.Right); } }
Now about Split operation. At the input, she receives the correct Cartesian tree T and a certain key x 0 . The task of the operation is to divide the tree into two so that in one of them (L) there are all elements of the source tree with keys less than x 0 , and in the other (R) with large ones. There are no special restrictions on the tree.

We reason in a similar way. Where will the root of the tree T be? If its key is less than x 0 , then in L, otherwise in R. Again, for the sake of clarity, suppose that the root key is less than x 0 .
Then we can immediately say that all the elements of the left subtree T will also be in L - their keys, after all, will also all be less than x 0. Moreover, the root of T will also be the root of L, since its priority is greatest in the whole tree. The left subtree of the root will be completely preserved unchanged, but the right subtree will decrease - you will have to remove elements with keys greater than x 0 from it and put it into the tree R. And save the rest of the keys as the new right subtree L. Again we see the identical task, recursion again begs!
Take the right subtree and cut it recursively using the same key x 0 into two trees L 'and R'. Then it becomes clear that L 'will become the new right subtree of the tree L, and R' is the tree R itself - it consists of those and only those elements that are greater than x 0 .
Symmetric case in which the root key is greater than x 0, also completely identical. The basis of recursion here is when some of the subtrees is empty. Well, the source code of the function:
public void Split(int x, out Treap L, out Treap R) { Treap newTree = null; if (this.x <= x) { if (Right == null) R = null; else Right.Split(x, out newTree, out R); L = new Treap(this.x, y, Left, newTree); } else { if (Left == null) L = null; else Left.Split(x, out L, out newTree); R = new Treap(this.x, y, newTree, Right); } }
By the way, note: the trees issued by the Split operation are suitable as input for the Merge operation: all the keys of the left tree do not exceed the keys in the right. This valuable circumstance will come in handy after a few paragraphs.
The final question is the uptime of Merge and Split. It can be seen from the description of the algorithm that Merge for each iteration of recursion reduces the total height of two merged trees by at least one, so that the total operating time does not exceed 2H, that is, O (H). And with Split, everything is very simple - we work with a single tree, its height decreases with each iteration by at least one as well, and the asymptotic behavior of the operation is also O (H). And since a Cartesian tree with random priorities, as already mentioned, is very likely to have a logarithmic height, Merge and Split work for the desired O (log 2 N), and this gives us tremendous scope for their application.
Tree operations
Now that you and I have perfect knowledge of glue and scissors, it’s not at all difficult to just use them to implement the most necessary actions with the Cartesian tree: adding an element to the tree and deleting it. I will give the simplest version of their implementation, based entirely on Merge and Split. It will work for all the same logarithmic time, however it will differ, as ACM-Olympians say, by a larger constant: that is, the order of the time depends on the size of the tree will still be O (log 2 N), but the exact time will differ several times - a constant time. Say 4 log 2 N vs just log 2 N. In practice, this difference is almost not felt until the size of the tree reaches a truly galactic size.
There are also optimal implementations of additions with deletion, as well as other necessary operations of deramide, whose constant is much smaller. I will definitely present these implementations in one of the following parts of the cycle, and also talk about the pitfalls associated with using the faster option. Pitfalls are primarily associated with the need to support additional queries to the tree and store special information in it ... however, I will not bother the reader with this now, before multiple operations with the tree (an extremely important feature!) Time will come.
So, let us be given a Cartesian tree and some element x that you want to insert into it (as we recall, in the context of the article it is assumed that all elements are different and X is not in the tree yet). I would like to apply the approach from the binary search tree: go down the keys, each time choosing the path left or right, until we find a place where we can insert our x, and add it. But this decision is wrong, because we forgot about priorities. The place where the search tree algorithm wants to add a new vertex uniquely satisfies the restrictions of the search tree by x, however, it may violate the heap restriction by y. So, you have to act a little higher and more abstract.
The second solution is to present the new key as a tree from a single vertex (with a random priority y), and merge it with the original one using Merge. This is again wrong: in the source tree there may be vertices with keys greater than x, and then we break the promise given to the Merge function regarding the relationship between its input trees.
The problem can be fixed. Remembering the versatility of Split / Merge operations, the solution suggests itself almost immediately:
- We split the tree by the key x into the tree L, with the keys smaller than X, and the tree R, with large ones.
- Create from this key a tree M from a single vertex (x, y), where y is the newly generated random priority.
- Combine (merge) in turn L with M, what happened - with R.
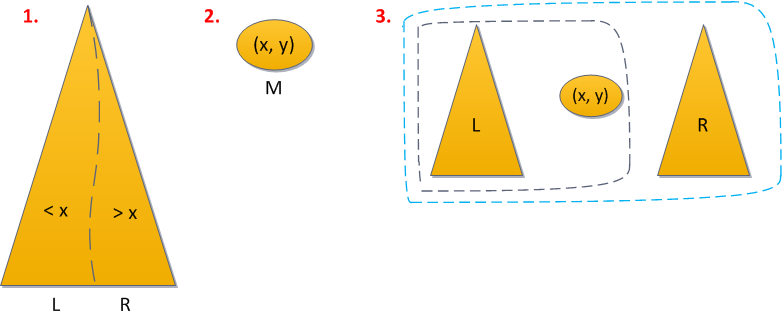
We have 1 Split application here, and 2 Merge applications - the total operating time of O (log 2 N). Short source code attached.
public Treap Add(int x) { Treap l, r; Split(x, out l, out r); Treap m = new Treap(x, rand.Next()); return Merge(Merge(l, m), r); }
With the removal, there are also no questions. Let us be asked to remove an element with the key x from the Cartesian tree. Now I assume that you figured out the equality of keys, giving preference to the left side: in the right subtree of the vertex with the key x, other elements with the same key do not occur, but in the left one they can. Then we perform the following sequence of actions:
- First, divide the tree by the key x-1. All elements less than or equal to x-1 went to the left result, which means that the desired element is in the right.
- We divide the right result by the key x (here it is worth being careful with equality!). All the elements with keys greater than x went to the new right result, and to the "middle" (left from the right) - all less than or equal to x. But since everyone who was strictly smaller after the first step was eliminated, the middle tree is the desired element.
- Now just combine the left tree with the right one again, without the middle one, and the deramide is left without the x keys.
Now it’s clear why I constantly focused on how all the same it is necessary to take into account the equality of keys. Say, if your comparator thought that elements with equal keys should be sent to the right subtree, then in the first step you would have to divide by the key x, and in the second - by x + 1. But if there were no specifics in this matter at all, then the deletion procedure in this option would not have fulfilled the desired at all - after the second step, the middle tree will remain empty, and the desired element will slip somewhere, either left or right, and look for him now.
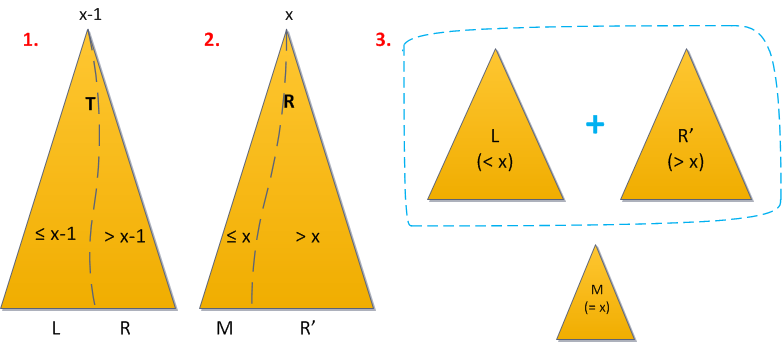
The operation time is still O (log 2 N), since we applied 2 times Split and 1 time Merge.
Source:
public Treap Remove(int x) { Treap l, m, r; Split(x - 1, out l, out r); r.Split(x, out m, out r); return Merge(l, r); }
Act of creation
Now, knowing the algorithm for adding an element to the finished Cartesian tree, we can give the simplest way to build a tree from an incoming set of keys: simply add them in turn using the standard algorithm, starting from a tree from one vertex - the first key. Remembering that the add operation is performed in logarithmic time, we get the total execution time of the complete tree construction - O (N log 2 N).
Interestingly, but can it be faster?
As it turned out, in some cases, yes. Let's imagine that the keys to our input come in ascending order. This, in principle, may well happen if these are some freshly created identifiers with auto increment. So, in this case, there is a simple algorithm for constructing a tree in O (N). True, we will have to pay for this with a temporary overhead from memory: to store for each vertex of the tree under construction a link to its ancestor (in fact, it’s not even necessary for each, but this is subtlety).
We will store the link to the last added vertex in the tree. By compatibility, it will be the rightmost one in it - because it has the largest key of all the keys of the tree currently built. Now suppose that the next key x comes in with some priority y. Where to put it?
The last peak is the most right, therefore, she has no right son. If its priority is greater than the y added, then you can simply ascribe a new vertex to the right son and, with a clear conscience, move on to the next key at the entrance. Otherwise, you need to think. The new vertex still has the largest key, so in the end it will definitely become the rightmost vertex of the tree. Therefore, it makes no sense to look for a place to insert it anywhere, except on the rightmost branch. What we need to find is just a place where the priority of the vertex is greater than y. So, we will rise from the rightmost one up the branch, each time checking the priority of the currently viewed vertex. In the end, we either come to the root, or stop somewhere in the middle of the branch.
Suppose we come to the root. Then it turns out that y is greater than all the priorities in the tree. We have no choice but to make (x, y) a new root and hang an old tree on it with our left son.
If we did not come to the root, the situation is similar. At some vertex of the right branch (x 0 , y 0 ) we have
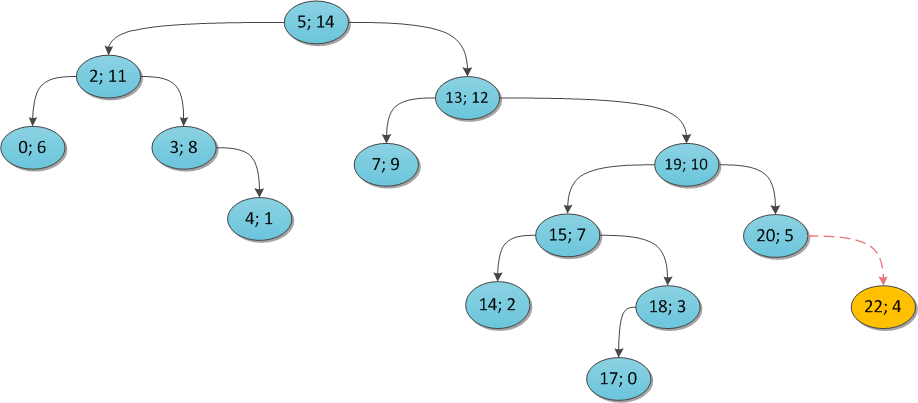
To make it clearer, I will illustrate with examples. Take some Cartesian tree and show what happens if you try to add some vertex to it. The key is the same everywhere (22), and the priority is variable.
y = 4:
y = 16:
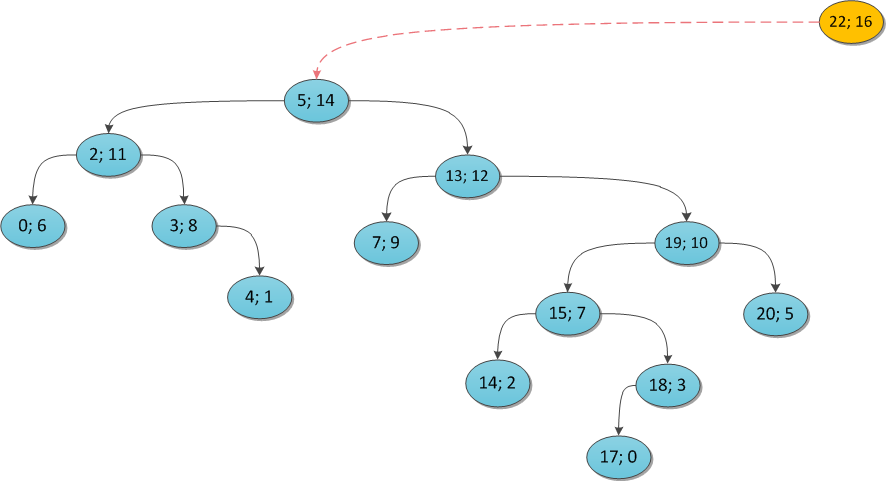
y = 11:

Why does this algorithm work for O (N)? Note that you will visit a maximum of two times in each life of a tree:
- with its direct addition;
- perhaps adding some other while it remains in the right branch. Immediately after this, she will leave the right branch and will not be visited anymore.
For starters - the source code for building on a given array of keys and priorities. Here it is assumed that each vertex of the tree has a property
Parent, and also that the already used private vertex constructor (the fifth in a row) has the same parameter with the same name.public static Treap Build(int[] xs, int[] ys) { Debug.Assert(xs.Length == ys.Length); var tree = new Treap(xs[0], ys[0]); var last = tree; for (int i = 1; i < xs.Length; ++i) { if (last.y > ys[i]) { last.Right = new Treap(xs[i], ys[i], parent: last); last = last.Right; } else { Treap cur = last; while (cur.Parent != null && cur.y <= ys[i]) cur = cur.Parent; if (cur.y <= ys[i]) last = new Treap(xs[i], ys[i], cur); else { last = new Treap(xs[i], ys[i], cur.Right, null, cur); cur.Right = last; } } } while (last.Parent != null) last = last.Parent; return last; }
Summary
We have built a tree-like data structure with the following properties:
- possesses almost guaranteed logarithmic height with respect to the number of its vertices;
- allows for logarithmic time to search for any key in the tree, add it and delete it;
- the source code of all its methods does not exceed 20 lines, they are easily understood and it is extremely difficult to make mistakes in them
- contains some overhead from memory, in comparison with truly self-balancing trees, for storing priorities.
In principle, the result is quite powerful. However, it may still be unclear to some whether it was worthwhile to make such a big garden with such a ton of text for it. It was worth it. The trick is that the capabilities of the Cartesian tree and the potential for its application are far from being limited to the functions described in this article. This is just a preface.
In the following parts:
- Multiple operations on a Cartesian tree (looking for O (log 2 N) sum, maximum, etc.)
- Cartesian tree by implicit key (or how to improve a regular array)
- Accelerated implementations of Cartesian tree functions (and their problems)
- Functional implementation of the Cartesian tree in F #.
Sources
I indicate the sources once and for all, they are the same for all planned articles.
First of all, when writing these articles, I am based on a lecture by Vitaliy Goldshtein, given at the Kharkov winter school for programming ACM ICPC in 2010. It can be downloaded from the school’s video gallery (year 2010, day 2), as soon as it starts working again, because in recent days the server is catastrophically junk. Maxim’s e-maxx
website by Ivanov is a rich storehouse of information on various algorithms and data structures used in sports programming. In particular, there is an article on the Cartesian tree on it .
In the famous book by Cormen, Leiserson, Rivest, Stein, “Algorithms: Construction and Analysis,” one can find evidence that the expectation of the height of a random binary search tree is O (log 2 N), although its definition of a random search tree is different from what we used here.
Deramides were first proposed in an article by Seidel, Raimund; Aragon, Cecilia R. (1996), Randomized Search Trees . In principle, there you can find the full amount of information on the topic.
That's all for now. I hope you were interested :)