Python is an assistant in finding cheap flights for those who like to travel
- Transfer
The author of the article, the translation of which we are publishing today, says that her goal is to talk about developing a web scraper in Python using Selenium, which searches for airfare prices. When searching for tickets, flexible dates are used (+ - 3 days relative to the specified dates). Scraper saves the search results in an Excel file and sends to the person who launched it an email with general information about what he managed to find. The objective of this project is to help travelers find the best deals.
If you, when dealing with the material, feel that you are lost - take a look at this article.

You are free to use the system described here the way you want. For example, I used it to search for weekend tours and tickets to my hometown. If you are serious about finding profitable tickets, you can run the script on the server (a simple server , for 130 rubles a month, is quite suitable for this) and make it run once or twice a day. Search results will be emailed to you. In addition, I recommend that you configure everything so that the script saves the Excel file with the search results in the Dropbox folder, which allows you to view such files from anywhere, anytime.

I have not yet found tariffs with errors, but I believe that this is possible.
When searching, as has already been said, a “flexible date” is used, the script finds offers that are within three days from the given dates. Although when starting the script, it searches for offers in only one direction, it is easy to refine it so that it can collect data in several directions of flights. With its help, you can even search for erroneous tariffs, such finds can be very interesting.
When I first started web scraping, to be honest, it was not particularly interesting. I wanted to do more projects in the field of predictive modeling, financial analysis, and, possibly, in the field of analysis of the emotional coloring of texts. But it turned out that it was very interesting - to figure out how to create a program that collects data from websites. As I delved into this topic, I realized that web scraping is the “engine” of the Internet.
You may decide that this is too bold a statement. But think about how Google started with a web scraper that Larry Page created using Java and Python. Googlebots have been researching and exploring the Internet, trying to provide their users with the best answers to their questions. Web scraping has an infinite number of applications, and even if you, in the field of Data Science, are interested in something else, then in order to get data for analysis, you will need some scraping skills.
Some of the tricks used here I found in a wonderful bookabout web scraping recently acquired. In it you can find many simple examples and ideas on the practical application of the studied. In addition, there is a very interesting chapter on reCaptcha test bypass. For me, this was news, since I did not know that there were special tools and even entire services for solving such problems.
To the simple and rather harmless question put in the heading of this section, one can often hear a positive answer, provided with a couple of travel stories of the person to whom he was asked. Most of us will agree that traveling is a great way to dive into new cultural environments and expand our horizons. However, if you ask someone a question about whether he likes to look for air tickets, I’m sure that the answer to it will be far from being so positive. As a matter of fact, here Python comes to the rescue.
The first task that we need to solve on the way of creating a system of searching for information on airline tickets will be the selection of a suitable platform with which we will take information. The solution to this problem was not easy for me, but in the end I chose the Kayak service. I tried the services of Momondo, Skyscanner, Expedia, and some more, but the protection mechanisms against robots on these resources were impenetrable. After several attempts, during which, in trying to convince the systems that I was human, I had to deal with traffic lights, pedestrian crossings and bicycles, I decided that Kayak suits me best, even though here too, if load too many pages in a short time, checks also begin. I managed to make the bot send requests to the site at intervals of 4 to 6 hours, and everything worked fine. Difficulties also arise periodically when working with Kayak, but if you begin to be bothered by checks, then you need to either deal with them manually, then start the bot, or wait a few hours, and the checks should stop. If necessary, you can well adapt the code for another platform, and if you do so, you can report it in the comments.
If you are just starting out with web scraping, and don’t know why some websites are struggling with it, then before you start your first project in this area, do yourself a favor and search Google for words "Web scraping etiquette". Your experiments may end sooner than you think if you are unreasonably engaged in web scraping.
Here is a general overview of what will happen in the code of our web scraper:
It should be noted that every Selenium project starts with a web driver. I use Chromedriver , work with Google Chrome, but there are other options. Also popular are PhantomJS and Firefox. After loading the driver, you need to place it in the appropriate folder, this completes the preparation for its use. The first lines of our script open a new Chrome tab.
Keep in mind that, in my story, I’m not trying to open new horizons for finding profitable offers on airline tickets. There are much more advanced techniques for finding such offers. I just want to offer readers of this material a simple but practical way to solve this problem.
Here is the code we talked about above.
At the beginning of the code, you can see the package import commands that are used throughout our project. So, it
Let's do a little experiment and open the kayak.com website in a separate window. Choose the city from which we are going to fly, and the city we want to get to, as well as the dates of flights. When choosing dates, we’ll verify that the range is + -3 days. I wrote the code taking into account what the site produces in response to such requests. If, for example, you need to search for tickets only for given dates, then it is highly likely that you will have to modify the bot code. Talking about the code, I make appropriate explanations, but if you feel that you are confused - let me know.
Now click on the search start button and look at the link in the address bar. It should look like the link that I use in the example below, where the variable

When I used the command
So, we opened the window and loaded the site. To get pricing and other information, we need to use XPath technology or CSS selectors. I decided to dwell on XPath and did not feel the need to use CSS selectors, but it is quite possible to work like that. Moving around a page using XPath can be a daunting task, and even if you use the methods that I described in this article, which used copying the corresponding identifiers from the page code, I realized that this, in fact, is not the best way to access necessary elements. By the way, in this book you can find an excellent description of the basics of working with pages using XPath and CSS selectors. Here's what the corresponding web driver method looks like.

So, we continue to work on the bot. Take advantage of the program to select the cheapest tickets. In the following image, the XPath selector code is highlighted in red. In order to view the code, you need to right-click on the element of the page you are interested in and select the Inspect command in the menu that appears. This command can be called for different page elements, the code of which will be displayed and highlighted in the code viewing window.
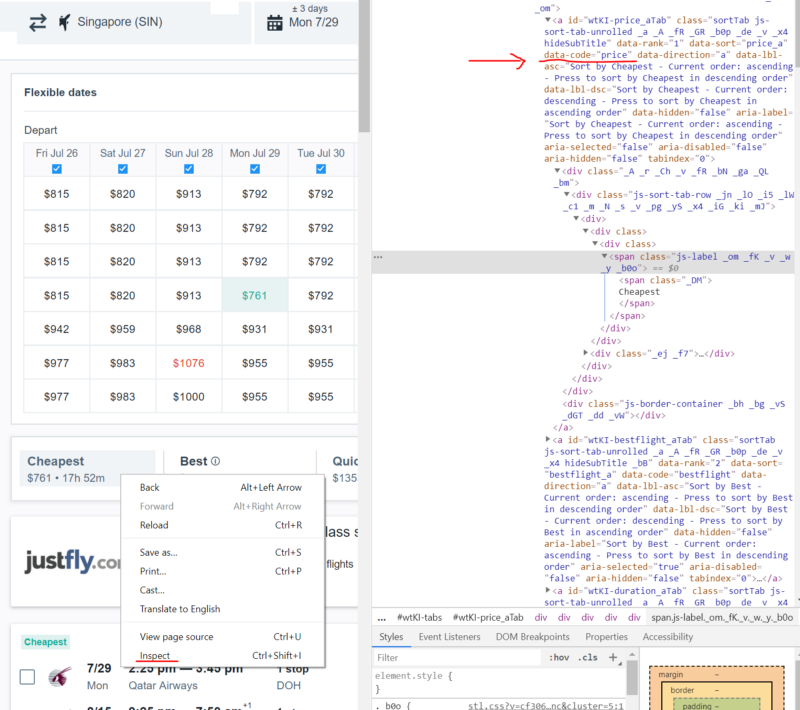
Viewing the page code
In order to find confirmation of my reasoning about the shortcomings of copying selectors from the code, pay attention to the following features.
Here's what you get when copying code:
In order to copy something similar, you need to right-click on the part of the code that interests you and select Copy> Copy XPath from the menu that appears.
Here is what I used to define the Cheapest button:
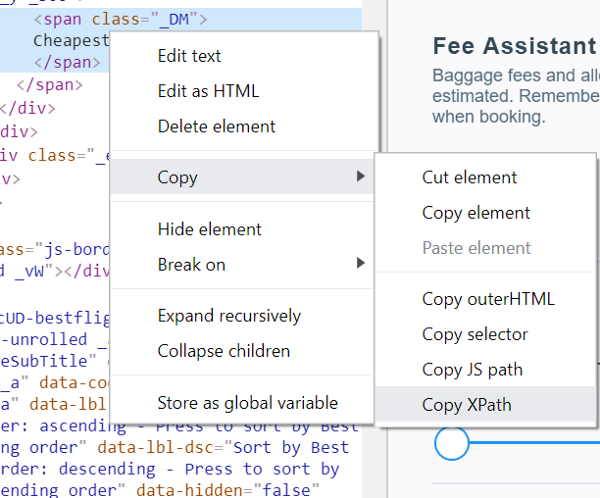
Copy> Copy XPath Command
It is quite obvious that the second option looks much simpler. When using it, it searches for the element a, which has an attribute
However, it should be noted that copying XPath selectors can come in handy when working with fairly simple sites, and if this suits you, there is nothing wrong with that.
Now let's think about what to do if you need to get all the search results in several lines, inside the list. Very simple. Each result is inside an object with a class
It should be noted that if you understand the above, then you should easily understand most of the code that we will parse. In the course of the work of this code, we turn to what we need (in fact, this is the element in which the result is wrapped) using some mechanism to indicate the path (XPath). This is done in order to get the text of the element and place it in an object from which data can be read (first used
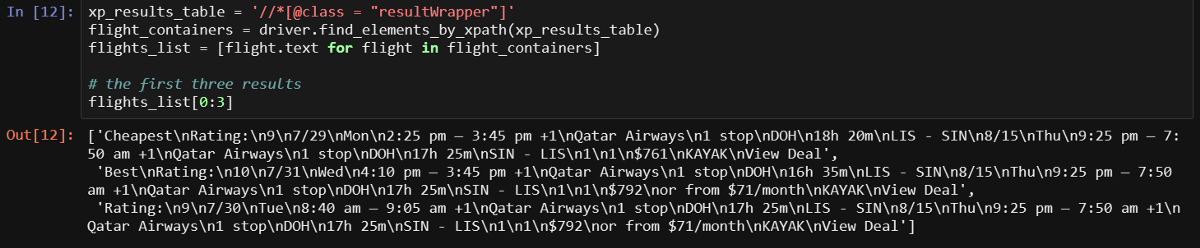
The first three lines are displayed and we can clearly see everything that we need. However, we have more interesting ways of obtaining information. We need to take data from each element separately.
It’s easiest to write a function to load additional results, so let's start with it. I would like to maximize the number of flights that the program receives information about, and at the same time not cause suspicions in the service leading to verification, so I click the Load more results button once every time the page is displayed. In this code, you should pay attention to the block
Now, after a long analysis of this function (sometimes I can get carried away), we are ready to declare a function that will deal with page scraping.
I have already collected most of what is needed in the next function called
I tried to name the variables so that the code would be clear. Remember that variables starting with
Now we have a function that allows you to load additional search results and a function to process these results. This article could be completed on this, since these two functions provide everything necessary for scraping pages that can be opened independently. But we have not yet considered some of the auxiliary mechanisms discussed above. For example, this is code for sending emails and some other things. All this can be found in the function
To use this function, you need information about cities and dates. She, using this information, forms a link in a variable
I tested this script using an Outlook account (hotmail.com). I did not check it for the correct operation of the Gmail account, this mail system is very popular, but there are a lot of possible options. If you use a Hotmail account, then in order for everything to work, you just need to enter your data in the code.
If you want to understand what exactly is performed in separate sections of the code of this function, you can copy them and experiment with them. Code experiments are the only way to understand it.
Now that everything we talked about is done, we can create a simple loop in which our functions are called. The script asks the user for data on cities and dates. When testing with a constant restart of the script, you are unlikely to want to enter this data each time manually, so the corresponding lines, for the time of testing, can be commented out by uncommenting those that go below them in which the data necessary for the script is hardcoded.
Here is the test run of the script.

Test run script
If you get to this point - congratulations! Now you have a working web scraper, although I already see many ways to improve it. For example, it can be integrated with Twilio so that, instead of emails, it sends text messages. You can use a VPN or something else to simultaneously receive results from multiple servers. There is also a recurring problem with checking the site user for whether he is a person, but this problem can also be solved. In any case, now you have a base that you can expand if you wish. For example, to make sure that the Excel file is sent to the user as an attachment to an email.

What are we looking for?
You are free to use the system described here the way you want. For example, I used it to search for weekend tours and tickets to my hometown. If you are serious about finding profitable tickets, you can run the script on the server (a simple server , for 130 rubles a month, is quite suitable for this) and make it run once or twice a day. Search results will be emailed to you. In addition, I recommend that you configure everything so that the script saves the Excel file with the search results in the Dropbox folder, which allows you to view such files from anywhere, anytime.
I have not yet found tariffs with errors, but I believe that this is possible.
When searching, as has already been said, a “flexible date” is used, the script finds offers that are within three days from the given dates. Although when starting the script, it searches for offers in only one direction, it is easy to refine it so that it can collect data in several directions of flights. With its help, you can even search for erroneous tariffs, such finds can be very interesting.
Why do I need another web scraper?
When I first started web scraping, to be honest, it was not particularly interesting. I wanted to do more projects in the field of predictive modeling, financial analysis, and, possibly, in the field of analysis of the emotional coloring of texts. But it turned out that it was very interesting - to figure out how to create a program that collects data from websites. As I delved into this topic, I realized that web scraping is the “engine” of the Internet.
You may decide that this is too bold a statement. But think about how Google started with a web scraper that Larry Page created using Java and Python. Googlebots have been researching and exploring the Internet, trying to provide their users with the best answers to their questions. Web scraping has an infinite number of applications, and even if you, in the field of Data Science, are interested in something else, then in order to get data for analysis, you will need some scraping skills.
Some of the tricks used here I found in a wonderful bookabout web scraping recently acquired. In it you can find many simple examples and ideas on the practical application of the studied. In addition, there is a very interesting chapter on reCaptcha test bypass. For me, this was news, since I did not know that there were special tools and even entire services for solving such problems.
Do you like to travel?!
To the simple and rather harmless question put in the heading of this section, one can often hear a positive answer, provided with a couple of travel stories of the person to whom he was asked. Most of us will agree that traveling is a great way to dive into new cultural environments and expand our horizons. However, if you ask someone a question about whether he likes to look for air tickets, I’m sure that the answer to it will be far from being so positive. As a matter of fact, here Python comes to the rescue.
The first task that we need to solve on the way of creating a system of searching for information on airline tickets will be the selection of a suitable platform with which we will take information. The solution to this problem was not easy for me, but in the end I chose the Kayak service. I tried the services of Momondo, Skyscanner, Expedia, and some more, but the protection mechanisms against robots on these resources were impenetrable. After several attempts, during which, in trying to convince the systems that I was human, I had to deal with traffic lights, pedestrian crossings and bicycles, I decided that Kayak suits me best, even though here too, if load too many pages in a short time, checks also begin. I managed to make the bot send requests to the site at intervals of 4 to 6 hours, and everything worked fine. Difficulties also arise periodically when working with Kayak, but if you begin to be bothered by checks, then you need to either deal with them manually, then start the bot, or wait a few hours, and the checks should stop. If necessary, you can well adapt the code for another platform, and if you do so, you can report it in the comments.
If you are just starting out with web scraping, and don’t know why some websites are struggling with it, then before you start your first project in this area, do yourself a favor and search Google for words "Web scraping etiquette". Your experiments may end sooner than you think if you are unreasonably engaged in web scraping.
Beginning of work
Here is a general overview of what will happen in the code of our web scraper:
- Import required libraries.
- Open the Google Chrome tab.
- Calling the function that launches the bot, passing him the city and date, which will be used when searching for tickets.
- This function receives the first search results, sorted by the criteria of the most attractive (best), and presses the button to load additional results.
- Another function collects data from the entire page and returns a data frame.
- The two previous steps are performed using sorting types by ticket price (cheap) and by flight speed (fastest).
- An email is sent to the script user containing a brief summary of ticket prices (cheapest tickets and average price), and a data frame with information sorted by the three aforementioned indicators is saved as an Excel file.
- All the above actions are performed in a cycle after a specified period of time.
It should be noted that every Selenium project starts with a web driver. I use Chromedriver , work with Google Chrome, but there are other options. Also popular are PhantomJS and Firefox. After loading the driver, you need to place it in the appropriate folder, this completes the preparation for its use. The first lines of our script open a new Chrome tab.
Keep in mind that, in my story, I’m not trying to open new horizons for finding profitable offers on airline tickets. There are much more advanced techniques for finding such offers. I just want to offer readers of this material a simple but practical way to solve this problem.
Here is the code we talked about above.
from time import sleep, strftime
from random import randint
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import smtplib
from email.mime.multipart import MIMEMultipart
# Используйте тут ваш путь к chromedriver!
chromedriver_path = 'C:/{YOUR PATH HERE}/chromedriver_win32/chromedriver.exe'
driver = webdriver.Chrome(executable_path=chromedriver_path) # Этой командой открывается окно Chrome
sleep(2)At the beginning of the code, you can see the package import commands that are used throughout our project. So, it
randintis used so that the bot would "fall asleep" for a random number of seconds before starting a new search operation. Usually not a single bot can do without it. If you run the above code, a Chrome window will open, which the bot will use to work with sites.Let's do a little experiment and open the kayak.com website in a separate window. Choose the city from which we are going to fly, and the city we want to get to, as well as the dates of flights. When choosing dates, we’ll verify that the range is + -3 days. I wrote the code taking into account what the site produces in response to such requests. If, for example, you need to search for tickets only for given dates, then it is highly likely that you will have to modify the bot code. Talking about the code, I make appropriate explanations, but if you feel that you are confused - let me know.
Now click on the search start button and look at the link in the address bar. It should look like the link that I use in the example below, where the variable
kayakthat stores the URL is declared , and the method is usedgetweb drivers. After clicking on the search button, the results should appear on the page.When I used the command
getmore than two to three times in a few minutes, I was asked to pass a test using reCaptcha. You can go through this check manually and continue the experiments until the system decides to arrange a new check. When I tested the script, I had the feeling that the first search session always goes without problems, so if you want to experiment with the code, you only have to manually check it periodically and leave the code to be executed using long intervals between search sessions. Yes, and if you think about it, a person is unlikely to need information on ticket prices received at 10-minute intervals between search operations.Working with a page using XPath
So, we opened the window and loaded the site. To get pricing and other information, we need to use XPath technology or CSS selectors. I decided to dwell on XPath and did not feel the need to use CSS selectors, but it is quite possible to work like that. Moving around a page using XPath can be a daunting task, and even if you use the methods that I described in this article, which used copying the corresponding identifiers from the page code, I realized that this, in fact, is not the best way to access necessary elements. By the way, in this book you can find an excellent description of the basics of working with pages using XPath and CSS selectors. Here's what the corresponding web driver method looks like.
So, we continue to work on the bot. Take advantage of the program to select the cheapest tickets. In the following image, the XPath selector code is highlighted in red. In order to view the code, you need to right-click on the element of the page you are interested in and select the Inspect command in the menu that appears. This command can be called for different page elements, the code of which will be displayed and highlighted in the code viewing window.
Viewing the page code
In order to find confirmation of my reasoning about the shortcomings of copying selectors from the code, pay attention to the following features.
Here's what you get when copying code:
//*[@id="wtKI-price_aTab"]/div[1]/div/div/div[1]/div/span/spanIn order to copy something similar, you need to right-click on the part of the code that interests you and select Copy> Copy XPath from the menu that appears.
Here is what I used to define the Cheapest button:
cheap_results = ‘//a[@data-code = "price"]’Copy> Copy XPath Command
It is quite obvious that the second option looks much simpler. When using it, it searches for the element a, which has an attribute
data-codeequal to price. When using the first option, an element is searched for idwhich is equal wtKI-price_aTab, while the XPath path to the element looks like /div[1]/div/div/div[1]/div/span/span. A similar XPath request to a page will do the trick, but only once. I can say right now what idwill change the next time the page loads. Character sequencewtKIdynamically changes each time the page is loaded, as a result, the code in which it is used will be useless after the next page reload. So take some time to figure out XPath. This knowledge will serve you well. However, it should be noted that copying XPath selectors can come in handy when working with fairly simple sites, and if this suits you, there is nothing wrong with that.
Now let's think about what to do if you need to get all the search results in several lines, inside the list. Very simple. Each result is inside an object with a class
resultWrapper. Downloading all results can be done in a loop that resembles the one shown below.It should be noted that if you understand the above, then you should easily understand most of the code that we will parse. In the course of the work of this code, we turn to what we need (in fact, this is the element in which the result is wrapped) using some mechanism to indicate the path (XPath). This is done in order to get the text of the element and place it in an object from which data can be read (first used
flight_containers, then - flights_list).The first three lines are displayed and we can clearly see everything that we need. However, we have more interesting ways of obtaining information. We need to take data from each element separately.
To work!
It’s easiest to write a function to load additional results, so let's start with it. I would like to maximize the number of flights that the program receives information about, and at the same time not cause suspicions in the service leading to verification, so I click the Load more results button once every time the page is displayed. In this code, you should pay attention to the block
trythat I added due to the fact that sometimes the button does not load normally. If you also encounter this, comment out the calls to this function in the function code start_kayak, which we will discuss below.# Загрузка большего количества результатов для того, чтобы максимизировать объём собираемых данных
def load_more():
try:
more_results = '//a[@class = "moreButton"]'
driver.find_element_by_xpath(more_results).click()
# Вывод этих заметок в ходе работы программы помогает мне быстро выяснить то, чем она занята
print('sleeping.....')
sleep(randint(45,60))
except:
passNow, after a long analysis of this function (sometimes I can get carried away), we are ready to declare a function that will deal with page scraping.
I have already collected most of what is needed in the next function called
page_scrape. Sometimes the returned data about the stages of the path turn out to be combined, for their separation I use a simple method. For example, when I use the variables section_a_list and section_b_list. Our function returns a data frame flights_df, this allows us to separate the results obtained using different data sorting methods, and later combine them.def page_scrape():
"""This function takes care of the scraping part"""
xp_sections = '//*[@class="section duration"]'
sections = driver.find_elements_by_xpath(xp_sections)
sections_list = [value.text for value in sections]
section_a_list = sections_list[::2] # так мы разделяем информацию о двух полётах
section_b_list = sections_list[1::2]
# Если вы наткнулись на reCaptcha, вам может понадобиться что-то предпринять.
# О том, что что-то пошло не так, вы узнаете исходя из того, что вышеприведённые списки пусты
# это выражение if позволяет завершить работу программы или сделать ещё что-нибудь
# тут можно приостановить работу, что позволит вам пройти проверку и продолжить скрапинг
# я использую тут SystemExit так как хочу протестировать всё с самого начала
if section_a_list == []:
raise SystemExit
# Я буду использовать букву A для уходящих рейсов и B для прибывающих
a_duration = []
a_section_names = []
for n in section_a_list:
# Получаем время
a_section_names.append(''.join(n.split()[2:5]))
a_duration.append(''.join(n.split()[0:2]))
b_duration = []
b_section_names = []
for n in section_b_list:
# Получаем время
b_section_names.append(''.join(n.split()[2:5]))
b_duration.append(''.join(n.split()[0:2]))
xp_dates = '//div[@class="section date"]'
dates = driver.find_elements_by_xpath(xp_dates)
dates_list = [value.text for value in dates]
a_date_list = dates_list[::2]
b_date_list = dates_list[1::2]
# Получаем день недели
a_day = [value.split()[0] for value in a_date_list]
a_weekday = [value.split()[1] for value in a_date_list]
b_day = [value.split()[0] for value in b_date_list]
b_weekday = [value.split()[1] for value in b_date_list]
# Получаем цены
xp_prices = '//a[@class="booking-link"]/span[@class="price option-text"]'
prices = driver.find_elements_by_xpath(xp_prices)
prices_list = [price.text.replace('$','') for price in prices if price.text != '']
prices_list = list(map(int, prices_list))
# stops - это большой список, в котором первый фрагмент пути находится по чётному индексу, а второй - по нечётному
xp_stops = '//div[@class="section stops"]/div[1]'
stops = driver.find_elements_by_xpath(xp_stops)
stops_list = [stop.text[0].replace('n','0') for stop in stops]
a_stop_list = stops_list[::2]
b_stop_list = stops_list[1::2]
xp_stops_cities = '//div[@class="section stops"]/div[2]'
stops_cities = driver.find_elements_by_xpath(xp_stops_cities)
stops_cities_list = [stop.text for stop in stops_cities]
a_stop_name_list = stops_cities_list[::2]
b_stop_name_list = stops_cities_list[1::2]
# сведения о компании-перевозчике, время отправления и прибытия для обоих рейсов
xp_schedule = '//div[@class="section times"]'
schedules = driver.find_elements_by_xpath(xp_schedule)
hours_list = []
carrier_list = []
for schedule in schedules:
hours_list.append(schedule.text.split('\n')[0])
carrier_list.append(schedule.text.split('\n')[1])
# разделяем сведения о времени и о перевозчиках между рейсами a и b
a_hours = hours_list[::2]
a_carrier = carrier_list[1::2]
b_hours = hours_list[::2]
b_carrier = carrier_list[1::2]
cols = (['Out Day', 'Out Time', 'Out Weekday', 'Out Airline', 'Out Cities', 'Out Duration', 'Out Stops', 'Out Stop Cities',
'Return Day', 'Return Time', 'Return Weekday', 'Return Airline', 'Return Cities', 'Return Duration', 'Return Stops', 'Return Stop Cities',
'Price'])
flights_df = pd.DataFrame({'Out Day': a_day,
'Out Weekday': a_weekday,
'Out Duration': a_duration,
'Out Cities': a_section_names,
'Return Day': b_day,
'Return Weekday': b_weekday,
'Return Duration': b_duration,
'Return Cities': b_section_names,
'Out Stops': a_stop_list,
'Out Stop Cities': a_stop_name_list,
'Return Stops': b_stop_list,
'Return Stop Cities': b_stop_name_list,
'Out Time': a_hours,
'Out Airline': a_carrier,
'Return Time': b_hours,
'Return Airline': b_carrier,
'Price': prices_list})[cols]
flights_df['timestamp'] = strftime("%Y%m%d-%H%M") # время сбора данных
return flights_dfI tried to name the variables so that the code would be clear. Remember that variables starting with
arefer to the first step of the path, and bto the second. Go to the next function.Auxiliary mechanisms
Now we have a function that allows you to load additional search results and a function to process these results. This article could be completed on this, since these two functions provide everything necessary for scraping pages that can be opened independently. But we have not yet considered some of the auxiliary mechanisms discussed above. For example, this is code for sending emails and some other things. All this can be found in the function
start_kayak, which we now consider. To use this function, you need information about cities and dates. She, using this information, forms a link in a variable
kayak, which is used to go to the page that will contain search results sorted by their best match. After the first scraping session, we will work with the prices in the table at the top of the page. Namely, we find the minimum ticket price and the average price. All this, together with the prediction issued by the site, will be sent by e-mail. On the page, the corresponding table should be in the upper left corner. Working with this table, by the way, can cause an error when searching using exact dates, since in this case the table is not displayed on the page.def start_kayak(city_from, city_to, date_start, date_end):
"""City codes - it's the IATA codes!
Date format - YYYY-MM-DD"""
kayak = ('https://www.kayak.com/flights/' + city_from + '-' + city_to +
'/' + date_start + '-flexible/' + date_end + '-flexible?sort=bestflight_a')
driver.get(kayak)
sleep(randint(8,10))
# иногда появляется всплывающее окно, для проверки на это и его закрытия можно воспользоваться блоком try
try:
xp_popup_close = '//button[contains(@id,"dialog-close") and contains(@class,"Button-No-Standard-Style close ")]'
driver.find_elements_by_xpath(xp_popup_close)[5].click()
except Exception as e:
pass
sleep(randint(60,95))
print('loading more.....')
# load_more()
print('starting first scrape.....')
df_flights_best = page_scrape()
df_flights_best['sort'] = 'best'
sleep(randint(60,80))
# Возьмём самую низкую цену из таблицы, расположенной в верхней части страницы
matrix = driver.find_elements_by_xpath('//*[contains(@id,"FlexMatrixCell")]')
matrix_prices = [price.text.replace('$','') for price in matrix]
matrix_prices = list(map(int, matrix_prices))
matrix_min = min(matrix_prices)
matrix_avg = sum(matrix_prices)/len(matrix_prices)
print('switching to cheapest results.....')
cheap_results = '//a[@data-code = "price"]'
driver.find_element_by_xpath(cheap_results).click()
sleep(randint(60,90))
print('loading more.....')
# load_more()
print('starting second scrape.....')
df_flights_cheap = page_scrape()
df_flights_cheap['sort'] = 'cheap'
sleep(randint(60,80))
print('switching to quickest results.....')
quick_results = '//a[@data-code = "duration"]'
driver.find_element_by_xpath(quick_results).click()
sleep(randint(60,90))
print('loading more.....')
# load_more()
print('starting third scrape.....')
df_flights_fast = page_scrape()
df_flights_fast['sort'] = 'fast'
sleep(randint(60,80))
# Сохранение нового фрейма в Excel-файл, имя которого отражает города и даты
final_df = df_flights_cheap.append(df_flights_best).append(df_flights_fast)
final_df.to_excel('search_backups//{}_flights_{}-{}_from_{}_to_{}.xlsx'.format(strftime("%Y%m%d-%H%M"),
city_from, city_to,
date_start, date_end), index=False)
print('saved df.....')
# Можно следить за тем, как прогноз, выдаваемый сайтом, соотносится с реальностью
xp_loading = '//div[contains(@id,"advice")]'
loading = driver.find_element_by_xpath(xp_loading).text
xp_prediction = '//span[@class="info-text"]'
prediction = driver.find_element_by_xpath(xp_prediction).text
print(loading+'\n'+prediction)
# иногда в переменной loading оказывается эта строка, которая, позже, вызывает проблемы с отправкой письма
# если это прозошло - меняем её на "Not Sure"
weird = '¯\\_(ツ)_/¯'
if loading == weird:
loading = 'Not sure'
username = 'YOUREMAIL@hotmail.com'
password = 'YOUR PASSWORD'
server = smtplib.SMTP('smtp.outlook.com', 587)
server.ehlo()
server.starttls()
server.login(username, password)
msg = ('Subject: Flight Scraper\n\n\
Cheapest Flight: {}\nAverage Price: {}\n\nRecommendation: {}\n\nEnd of message'.format(matrix_min, matrix_avg, (loading+'\n'+prediction)))
message = MIMEMultipart()
message['From'] = 'YOUREMAIL@hotmail.com'
message['to'] = 'YOUROTHEREMAIL@domain.com'
server.sendmail('YOUREMAIL@hotmail.com', 'YOUROTHEREMAIL@domain.com', msg)
print('sent email.....')I tested this script using an Outlook account (hotmail.com). I did not check it for the correct operation of the Gmail account, this mail system is very popular, but there are a lot of possible options. If you use a Hotmail account, then in order for everything to work, you just need to enter your data in the code.
If you want to understand what exactly is performed in separate sections of the code of this function, you can copy them and experiment with them. Code experiments are the only way to understand it.
Ready system
Now that everything we talked about is done, we can create a simple loop in which our functions are called. The script asks the user for data on cities and dates. When testing with a constant restart of the script, you are unlikely to want to enter this data each time manually, so the corresponding lines, for the time of testing, can be commented out by uncommenting those that go below them in which the data necessary for the script is hardcoded.
city_from = input('From which city? ')
city_to = input('Where to? ')
date_start = input('Search around which departure date? Please use YYYY-MM-DD format only ')
date_end = input('Return when? Please use YYYY-MM-DD format only ')
# city_from = 'LIS'
# city_to = 'SIN'
# date_start = '2019-08-21'
# date_end = '2019-09-07'
for n in range(0,5):
start_kayak(city_from, city_to, date_start, date_end)
print('iteration {} was complete @ {}'.format(n, strftime("%Y%m%d-%H%M")))
# Ждём 4 часа
sleep(60*60*4)
print('sleep finished.....')Here is the test run of the script.
Test run script
Summary
If you get to this point - congratulations! Now you have a working web scraper, although I already see many ways to improve it. For example, it can be integrated with Twilio so that, instead of emails, it sends text messages. You can use a VPN or something else to simultaneously receive results from multiple servers. There is also a recurring problem with checking the site user for whether he is a person, but this problem can also be solved. In any case, now you have a base that you can expand if you wish. For example, to make sure that the Excel file is sent to the user as an attachment to an email.
Only registered users can participate in the survey. Please come in.
Do you use web scraping technology?
- 57.7% Yes 41
- 42.2% No 30