With a beard, in dark glasses and in profile: difficult situations for computer vision

Technologies and models for our future computer vision system were created and improved gradually in various projects of our company - in the Mail, Cloud, and Search. Ripened like good cheese or cognac. Once we realized that our neural networks showed excellent recognition results, and decided to bring them together into a single b2b-product - Vision - which we now use ourselves and offer to use you.
Today, our computer vision technology on the Mail.Ru Cloud Solutions platform works successfully and solves very complex practical problems. It is based on a number of neural networks that are trained on our data sets and specialize in solving applied problems. All services are spinning on our server capacities. You can integrate the public Vision API into your applications, through which all the features of the service are available. The API is fast - thanks to server GPUs, the average response time within our network is 100 ms.
Come under the cut, there is a detailed story and many examples of Vision.
An example of a service in which we ourselves use the aforementioned face recognition technologies is Events. One of its components is the Vision photo stands, which we install at various conferences. If you go up to such a photo stand, take a photo with the built-in camera and enter your mail, the system will immediately find among the array of photos those of which the regular conference photographers have captured you, and if desired, send the photos found to you by mail. And it's not about staged portrait shots - Vision recognizes you even in the background in the crowd of visitors. Of course, they are not recognized by the photo stands themselves, they are only tablets in beautiful coasters that simply photograph guests on their built-in cameras and transmit information to servers, where all the magic of recognition takes place. And we have repeatedly observed how surprising the effectiveness of the technology is even among specialists in image recognition.
1. Our Face Recognition Model
1.1. Neural network and processing speed
For recognition, we use a modification of the ResNet 101 neural network model. Average Pooling at the end is replaced by a fully connected layer, similar to how it was done in ArcFace. However, the size of vector representations is 128, not 512. Our training set contains about 10 million photos of 273,593 people.
The model works very fast thanks to a carefully selected server configuration architecture and GPU computing. It takes 100 ms to get a response from the API in our internal networks - this includes face detection (face detection in the photo), recognition and returning the PersonID in the API response. With large volumes of incoming data - photos and videos - it will take much more time to transfer data to the service and to receive a response.
1.2. Assessment of the effectiveness of the model
But determining the efficiency of neural networks is a very mixed task. The quality of their work depends on which data sets the models were trained on and whether they were optimized for working with specific data.
We began to evaluate the accuracy of our model with the popular LFW verification test, but it is too small and simple. After reaching 99.8% accuracy, it is no longer useful. There is a good competition for evaluating recognition models - Megaface on it we gradually reached 82% rank 1. Megaface test consists of a million photos - distractors - and the model should be able to distinguish well several thousand photos of celebrities from the Facescrub dataset from distractors. However, having cleared the Megaface test of errors, we found out that on the cleaned version we achieve an accuracy of 98% rank 1 (celebrity photos are generally quite specific). Therefore, they created a separate identification test, similar to Megaface, but with photos of “ordinary” people. Further improved the recognition accuracy on their datasets and went far ahead. Moreover, we use the clustering quality test, which consists of several thousand photographs; It simulates the markup of faces in the user's cloud. In this case, clusters are groups of similar individuals, a group for each recognizable person. We checked the quality of work on real groups (true).
Of course, any model has recognition errors. But such situations are often resolved by fine-tuning the thresholds for specific conditions (for all conferences we use the same thresholds, and, for example, for ACSs we have to significantly increase the thresholds so that there are fewer false positives). The vast majority of conference attendees were recognized by our Vision photo stands correctly. Sometimes someone looked at the cropped preview and said: "Your system was wrong, it's not me." Then we opened the whole photograph, and it turned out that this visitor really was in the photograph, only they didn’t take it, but someone else, just a man accidentally appeared in the background in the blur zone. Moreover, the neural network often correctly recognizes even when a part of the face is not visible, or a person is standing in profile, or even half-turn. The system can recognize a person, even if the person fell into the field of optical distortion, say, when shooting with a wide-angle lens.
1.3. Testing examples in difficult situations
Below are examples of the operation of our neural network. At the entrance, photos are submitted, which she must mark using PersonID - a unique identifier for the person. If two or more images have the same identifier, then, according to the models, these photos show one person.
Immediately, we note that during testing we have access to various parameters and thresholds of models that we can configure to achieve a particular result. The public API is optimized for maximum accuracy on common cases.
Let's start with the simplest, with face recognition in the face.

Well, that was too easy. We complicate the task, add a beard and a handful of years.

Someone will say that this was not too difficult, because in both cases the face is visible in its entirety, the algorithm has a lot of information about the face. Okay, turn Tom Hardy in profile. This task is much more complicated, and we spent a lot of effort on its successful solution while maintaining a low level of errors: we selected a training sample, thought over the architecture of the neural network, honed the loss functions, and improved the preliminary processing of photos.
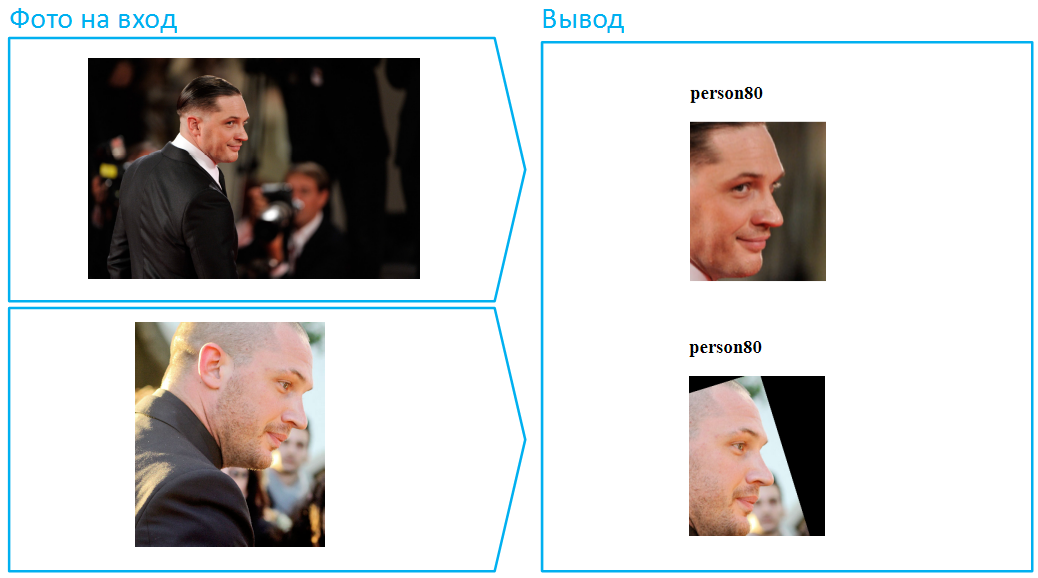
We put a hat on him:

By the way, this is an example of a particularly difficult situation, because here the face is very covered, and in the lower picture there is also a deep shadow that hides the eyes. In real life, people very often change their appearance with the help of dark glasses. Do the same with Tom.

Well, let's try to upload photos from different ages, and this time we will put experience on another actor. Let’s take a much more complex example when age-related changes are especially pronounced. The situation is not far-fetched, it happens all the time when you need to compare a photograph in your passport with the face of the bearer. After all, the first photo is stuck in the passport when the owner is 20 years old, and by 45 people can change very much:

Do you think that the main special on impossible missions has not changed much with age? I think that even a few people would combine the upper and lower photos, the boy has changed so much over the years.

Neural networks are faced with changes in appearance much more often. For example, sometimes women can greatly change their image with the help of cosmetics:

Now let's complicate the task even more: let different parts of the face be covered in different photos. In such cases, the algorithm cannot compare the entire samples. However, Vision handles such situations well.
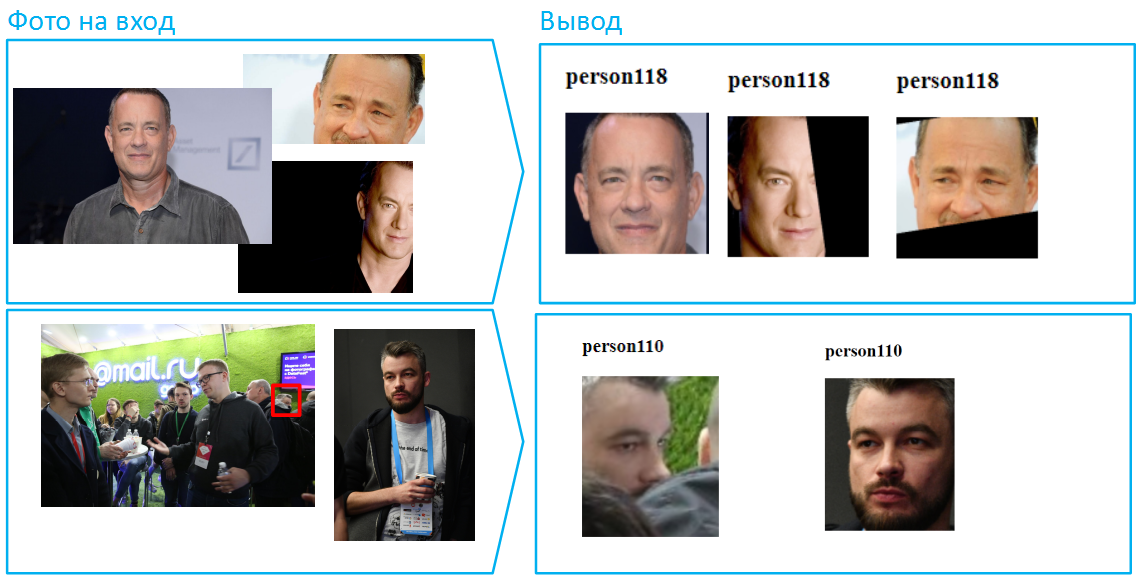
By the way, there are a lot of faces in photographs, for example, more than 100 people can fit in a common picture of the hall. This is a difficult situation for neural networks, since many faces can be differently illuminated, someone outside the zone of sharpness. However, if the photo was taken with sufficient resolution and quality (at least 75 pixels per square covering the face), Vision will be able to identify and recognize it.

The peculiarity of reporting photographs and images from surveillance cameras is that people are often blurry because they were out of the field of sharpness or were moving at that moment:

Also, the intensity of illumination can vary greatly from image to image. This also often turns into a stumbling block, many algorithms have great difficulty in correctly processing images that are too dark and too light, not to mention the exact comparison. Let me remind you that in order to achieve such a result, you need to set thresholds in a certain way, this possibility is not yet publicly available. For all clients, we use the same neural network, it has thresholds that are suitable for most practical tasks.

Recently, we rolled out a new version of the model that recognizes Asian faces with high accuracy. Previously, this was a big problem, which was even called "machine learning racism" (or "neural networks"). European and American neural networks recognized Europeoid faces well, and things were much worse with Mongoloid and Negroid ones. Probably in the same China, the situation was exactly the opposite. It's all about training data sets that reflect the dominant types of people in a particular country. However, the situation is changing, today this problem is far from so acute. Vision does not have any difficulties with representatives of different races.

Face recognition is just one of many applications of our technology, Vision can be taught to recognize anything. For example, car numbers, including in difficult conditions for algorithms: at sharp angles, dirty and hard to read numbers.

2. Practical use cases
2.1. Physical access control: when two go on the same pass
With the help of Vision, it is possible to implement accounting systems for employee arrival and departure. A traditional system based on electronic passes has obvious drawbacks, for example, you can go through two badges together. If the access control system (ACS) is supplemented with Vision, it will honestly record who came and went when.
2.2. Time tracking
This use case for Vision is closely related to the previous one. If we complement the access control system with our face recognition service, it will be able to not only notice violations of the access control, but also record the actual stay of employees in the building or at the facility. In other words, Vision will help to honestly consider who and how much came to work and left with her, and who even skipped, even if his colleagues covered him in front of his superiors.
2.3. Video analytics: people tracking and security
By tracking people using Vision, you can accurately assess the actual patency of shopping areas, train stations, crossings, streets, and many other public places. Our tracking can also be of great help in controlling access, for example, to a warehouse or other important office premises. And of course, tracking people and faces helps solve security problems. Caught someone stealing from your store? Add it to the PersonID, which returned Vision, in the black list of your video analytics software, and the next time the system will immediately alert the security if this type appears again.
2.4. In trade
Retail and various service businesses are interested in queue recognition. Using Vision, you can recognize that this is not a random crowd of people, but rather a queue, and determine its length. And then the system informs the responsible people about the queue in order to understand the situation: either this is an influx of visitors and additional employees need to be called, or someone is hacking with their work responsibilities.
Another interesting task is the separation of company employees in the hall from visitors. Typically, the system learns to separate objects in certain clothes (dress code) or with some distinctive feature (signature scarf, badge on the chest, and so on). This helps to more accurately assess attendance (so that employees alone do not “wind up” the statistics of people in the hall).
Using face recognition, you can evaluate your audience: what is the loyalty of visitors, that is, how many people return to your institution and with what frequency. Calculate how many unique visitors come to you in a month. To optimize the costs of attracting and retaining, you can find out and the change in attendance depending on the day of the week and even time of day.
Franchisors and network companies can order an assessment of the quality of branding of various retail outlets from photographs: the presence of logos, signs, posters, banners and so on.
2.5. On transport
Another example of security through video analytics is identifying items left in airport or train station halls. Vision can be trained to recognize objects of hundreds of classes: furniture, bags, suitcases, umbrellas, various types of clothing, bottles and so on. If your video analytics system detects an ownerless object and recognizes it using Vision, it sends a signal to the security service. A similar task is related to the automatic detection of non-standard situations in public places: someone became ill, or someone smoked in the wrong place, or the person fell on the rails, and so on - all these patterns of the video analytics system can recognize through the API Vision.
2.6. Workflow
Another interesting future application of Vision that we are currently developing is the recognition of documents and their automatic parsing into databases. Instead of manually driving in (or even worse, entering) endless series, numbers, issue dates, account numbers, bank details, dates and places of birth and many other formalized data, you can scan documents and automatically send them via a secure channel through the API in the cloud, where the system will be on the fly, these documents will be recognized, parsed and will return a response with data in the desired format for automatic entry into the database. Today Vision already knows how to classify documents (including in PDF) - it distinguishes passports, SNILS, TIN, birth certificates, marriage certificates and others.
Of course, all these situations the neural network is not able to handle out of the box. In each case, a new model is built for a particular customer, many factors, nuances and requirements are taken into account, data sets are selected, training-testing-settings are iterated.
3. API working scheme
Vision's “entrance gate” for users is the REST API. At the entrance, he can take photos, video files and broadcasts from network cameras (RTSP streams).
To use Vision, you need to register in Mail.ru Cloud Solutions and get access tokens (client_id + client_secret). User authentication is performed using the OAuth protocol. The source data in the bodies of POST requests is sent to the API. And in response, the client receives the recognition result from the API in JSON format, and the response is structured: it contains information about the objects found and their coordinates.

Response example
{
"status":200,
"body":{
"objects":[
{
"status":0,
"name":"file_0"
},
{
"status":0,
"name":"file_2",
"persons":[
{
"tag":"person9"
"coord":[149,60,234,181],
"confidence":0.9999,
"awesomeness":0.45
},
{
"tag":"person10"
"coord":[159,70,224,171],
"confidence":0.9998,
"awesomeness":0.32
}
]
}
{
"status":0,
"name":"file_3",
"persons":[
{
"tag":"person11",
"coord":[157,60,232,111],
"aliases":["person12", "person13"]
"confidence":0.9998,
"awesomeness":0.32
}
]
},
{
"status":0,
"name":"file_4",
"persons":[
{
"tag":"undefined"
"coord":[147,50,222,121],
"confidence":0.9997,
"awesomeness":0.26
}
]
}
],
"aliases_changed":false
},
"htmlencoded":false,
"last_modified":0
}The answer has an interesting parameter awesomeness - this is the conditional “coolness” of the face in the photo, with it we select the best face shot from the sequence. We trained the neural network to predict the likelihood that the picture will be like on social networks. The better the picture and the smoother the face, the greater the awesomness.
The Vision API uses a concept such as space. This is a tool for creating different sets of faces. Examples of spaces are black and white lists, lists of visitors, employees, customers, etc. For each token in Vision, you can create up to 10 spaces, in each space there can be up to 50 thousand PersonID, that is, up to 500 thousand for one token . Moreover, the number of tokens per account is not limited.
Today, the API supports the following detection and recognition methods:
- Recognize / Set - definition and recognition of faces. Automatically assigns a PersonID to each unique face, returns the PersonID and coordinates of the found faces.
- Delete - delete a specific PersonID from the person database.
- Truncate - clearing the entire space from PersonID, useful if it was used as a test and you need to reset the base for production.
- Detect - definition of objects, scenes, license plates, attractions, queues, etc. Returns the class of found objects and their coordinates
- Detect for documents - detects specific types of documents of the Russian Federation (distinguishes passport, snls, inn, etc.).
Also, we will soon finish work on methods for OCR, determining sex, age and emotions, as well as solving merchandising tasks, that is, to automatically control the display of goods in stores. You can find the full API documentation here: https://mcs.mail.ru/help/vision-api
4. Conclusion
Now through the public API you can access face recognition in photos and videos, it supports the definition of various objects, car numbers, attractions, documents and entire scenes. Application Scenarios - Sea. Come, test our service, set the most tricky tasks for it. The first 5,000 transactions are free. It may be the “missing ingredient” for your projects.
Access to the API can be instantly obtained when registering and connecting Vision . All Habra users - a promotional code for additional transactions. Write in a personal email address to which the account was registered!