JavaScript engine basics: general forms and inline caching. Part 1
Hello friends. At the end of April, we are launching a new course “Information Systems Security” . And now we want to share with you a translation of the article, which will certainly be very useful for the course. The original article can be found here .
The article describes the key foundations, they are common to all JavaScript engines, and not just to V8 , which the authors of the engine ( Benedict and Matias ) are working on . As a JavaScript developer, I can say that a deeper understanding of how the JavaScript engine works will help you figure out how to write efficient code.

It all starts with the fact that you write code in JavaScript. After that, the JavaScript engine processes the source code and presents it as an abstract syntax tree (AST). Based on the constructed AST, the interpreter can finally get down to work and start generating bytecode. Excellent! This is the moment the engine executes JavaScript code.

To make it run faster, you can send bytecode to the optimizing compiler along with profiling data. The optimizing compiler makes certain assumptions based on profiling data, then it generates highly optimized machine code.
If at some point the assumptions turn out to be incorrect, the optimizing compiler will de-optimize the code and return to the interpreter stage.
Interpreter pipelines / compiler in JavaScript engines
Now let's take a closer look at the parts of the pipeline that execute your JavaScript code, namely where the code is interpreted and optimized, as well as a few differences between the main JavaScript engines.
At the heart of everything is a pipeline that contains an interpreter and an optimizing compiler. The interpreter quickly generates non-optimized bytecode, the optimizing compiler, in turn, works longer, but the output has highly optimized machine code.
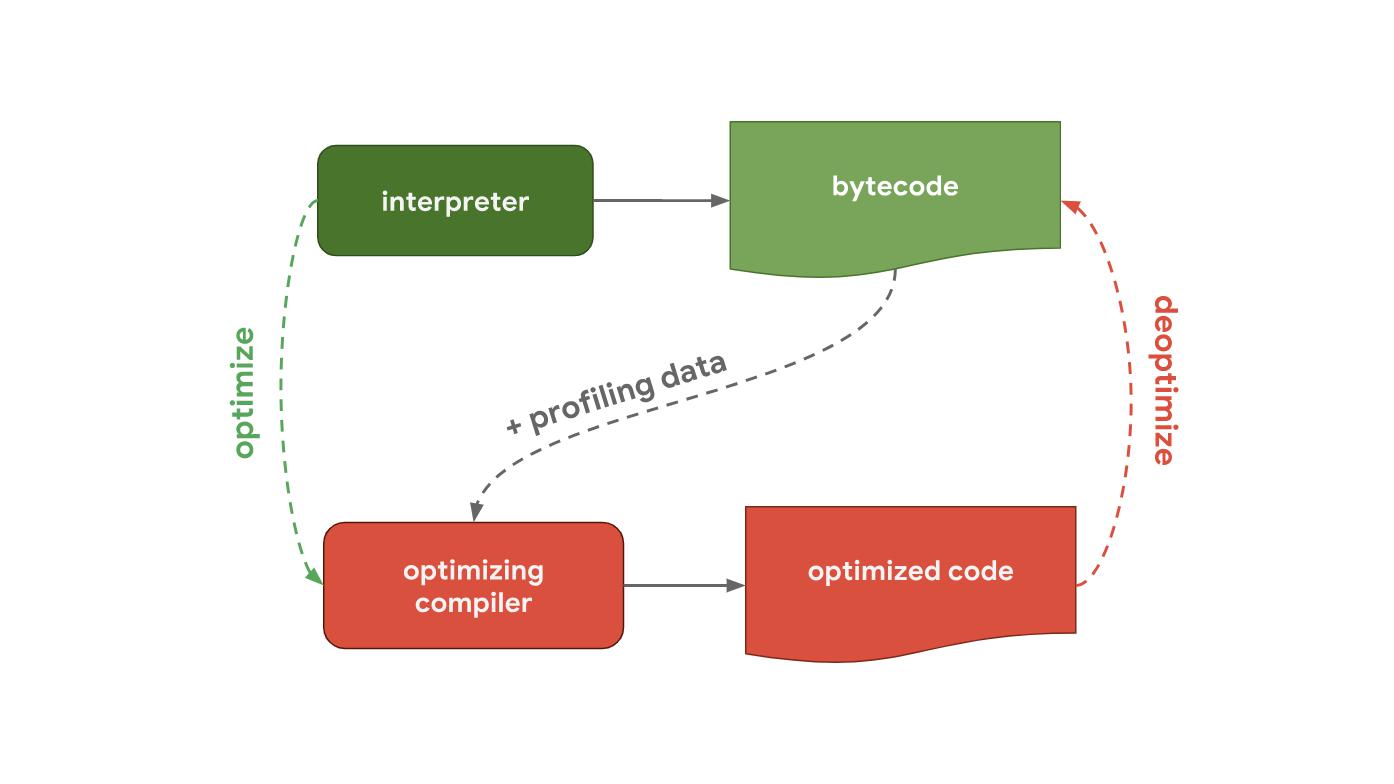
Next up is a pipeline that shows how V8 works, the JavaScript engine used by Chrome and Node.js.

The interpreter in V8 is called Ignition, which is responsible for generating and executing bytecode. It collects profiling data that can be used to speed up execution in the next step while the bytecode is being processed. When a function becomes hot , for example, if it starts frequently, the generated bytecode and profiling data are transferred to the TurboFan, that is, to the optimizing compiler to generate highly optimized machine code based on the profiling data.

For example, Mozilla's SpiderMonkey JavaScript engine, which is used in Firefox and SpiderNode, works a little differently. It has not one, but two optimizing compilers. The interpreter is optimized into a basic compiler (Baseline compiler), which produces some optimized code. Together with profiling data collected during code execution, the IonMonkey compiler can generate heavily-optimized code. If speculative optimization fails, IonMonkey returns to the Baseline code.

Chakra - Microsoft's JavaScript engine, used by Edge and Node-ChakraCore, has a very similar structure and uses two optimizing compilers. The interpreter is optimized in SimpleJIT (where JIT stands for "Just-In-Time compiler", which produces optimized code to some extent. Together with the profiling data, FullJIT can create even more highly optimized code.
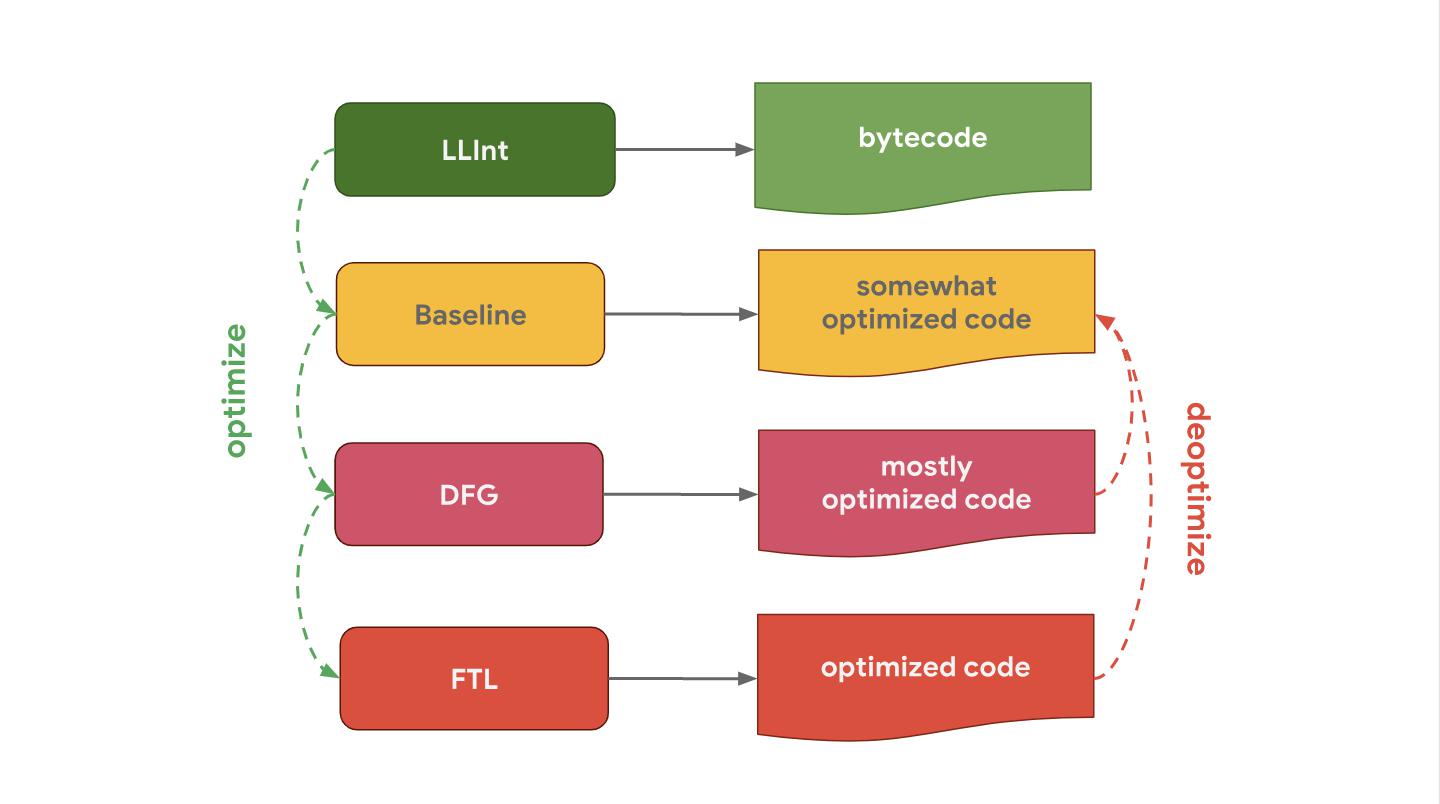
JavaScriptCore (short for JSC), JavaScript engine from Apple, which is used in Safari and React Native, generally has three different optimizing compilers: LLInt is a low-level interpreter that is optimized into the base compiler, which in turn is optimized in the DFG (Data Flow Graph) compiler, and it is already optimized in FTL (Faster Than Light) compiler.
Why do some engines have more optimizing compilers than others? It is all about compromises. The interpreter can process bytecode quickly, but bytecode alone is not particularly efficient. The optimizing compiler, on the other hand, works a little longer, but produces more efficient machine code. This is a compromise between quickly getting the code (interpreter) or some waiting and running the code with maximum performance (optimizing compiler). Some engines choose to add several optimizing compilers with different characteristics of time and efficiency, which allows you to provide the best control over this compromise solution and understand the cost of additional complication of the internal device. Another tradeoff is memory usage; take a look at thisarticle to better understand this.
We have just examined the main differences between interpreter and optimizer compiler pipelines for various JavaScript engines. Despite these high-level differences, all JavaScript engines have the same architecture: they all have a parser and some kind of interpreter / compiler pipeline.
JavaScript Object Model
Let's see what else JavaScript engines have in common and what techniques they use to speed up access to the properties of JavaScript objects? It turns out that all the main engines do this in a similar way.
The ECMAScript specification defines all objects as dictionaries with string keys matching property attributes .

In addition to
The notation
Ok, so JavaScript defines objects. What about arrays?
You can imagine arrays as special objects. The only difference is that arrays have special index processing. Here, an array index is a special term in the ECMAScript specification. JavaScript has limits on the number of elements in an array - up to 2³² − 1. An array index is any available index from this range, that is, any integer value from 0 to 2³² − 2.
Another difference is that arrays have a magical property
In this example, the array has a length of 2 at the time of creation. Then we assign another element to index 2 and the length automatically increases.
JavaScript defines arrays as well as objects. For example, all keys, including array indices, are represented explicitly as strings. The first element of the array is stored under the key '0'.

A property
As soon as an element is added to the array, JavaScript automatically updates the property attribute of the

In general, we can say that arrays behave similarly to objects.
Optimization of access to properties
Now that we know how objects are defined in JavaScript, let's take a look at how JavaScript engines allow you to work with objects efficiently.
In everyday life, access to properties is the most common operation. It is extremely important for the engine to do this quickly.
Forms
In JavaScript programs, it is quite common practice to assign the same property keys to many objects. They say that such objects have the same shape .
Also common mechanics is access to the property of objects of the same form:
Knowing this, JavaScript engines can optimize access to the property of an object based on its shape. See how it works.
Suppose we have an object with properties x and y, it uses the dictionary data structure, which we talked about earlier; it contains key strings that point to their respective attributes.
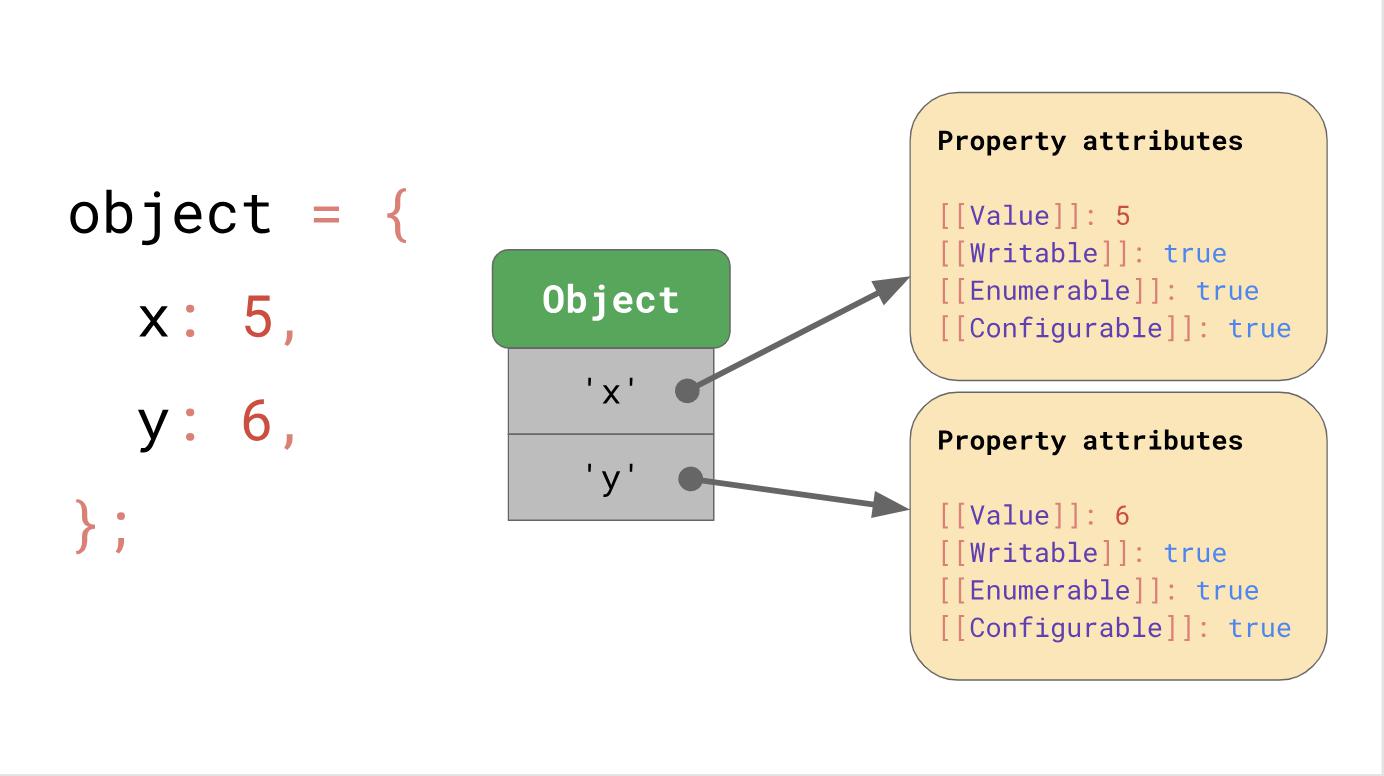
If you are accessing a property, for example,
But where are these property attributes stored in memory? Should we store them as part of a JSObject? If we do this, we will see more objects of this form later, in which case, it is a waste of space to store a complete dictionary containing the names of properties and attributes in JSObject itself, since property names are repeated for all objects of the same form. This causes a lot of duplication and leads to misallocation of memory. For optimization, the engines store the shape of the object separately.

This form (
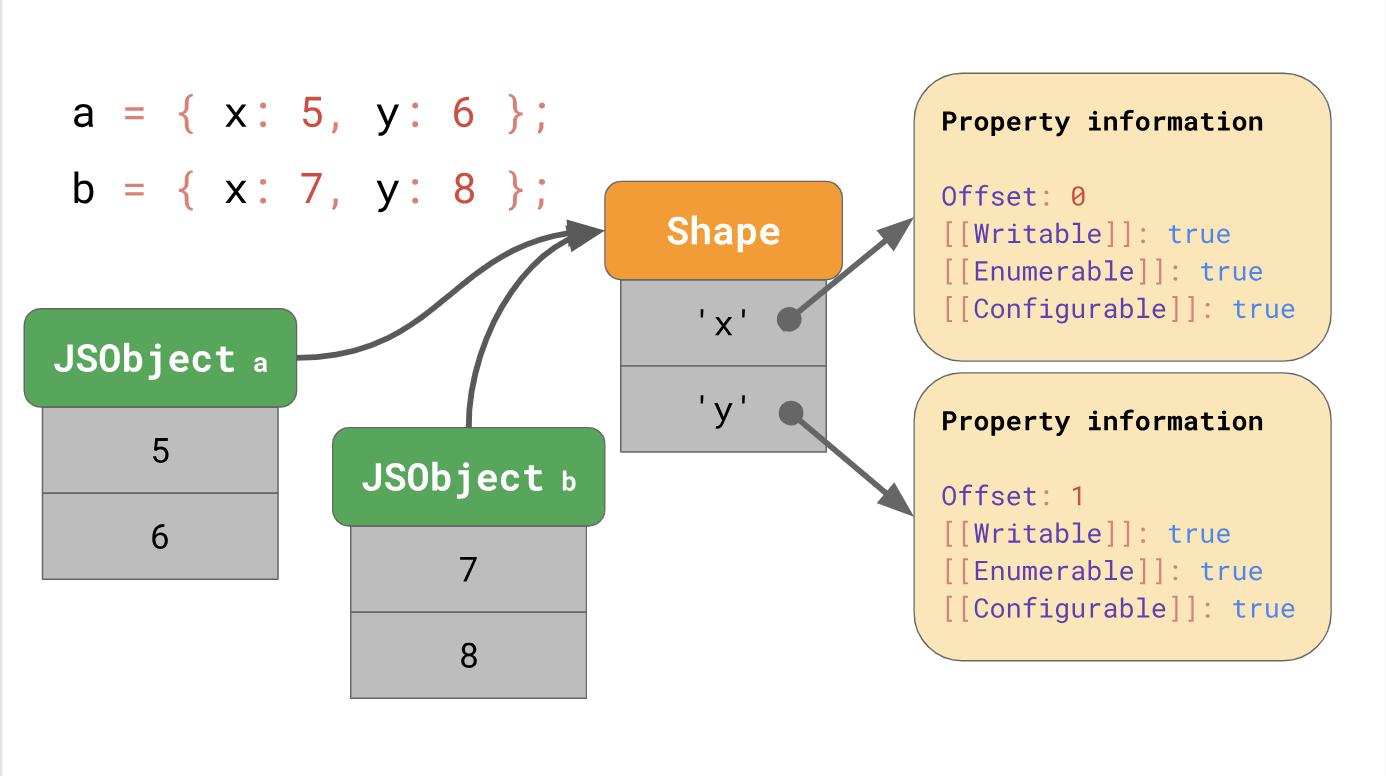
The advantage becomes obvious as soon as we have a lot of objects. Their number does not matter, because if they have one form, we save information about the form and property only once.
All JavaScript engines use forms as a means of optimization, but they do not directly call them forms (
In this article, we continue to call them forms (
Transition chains and trees
What happens if you have an object of a certain shape, but you add a new property to it? How does the JavaScript engine define a new form?
Forms create what are called transition chains in the JavaScript engine. Here is an example: An
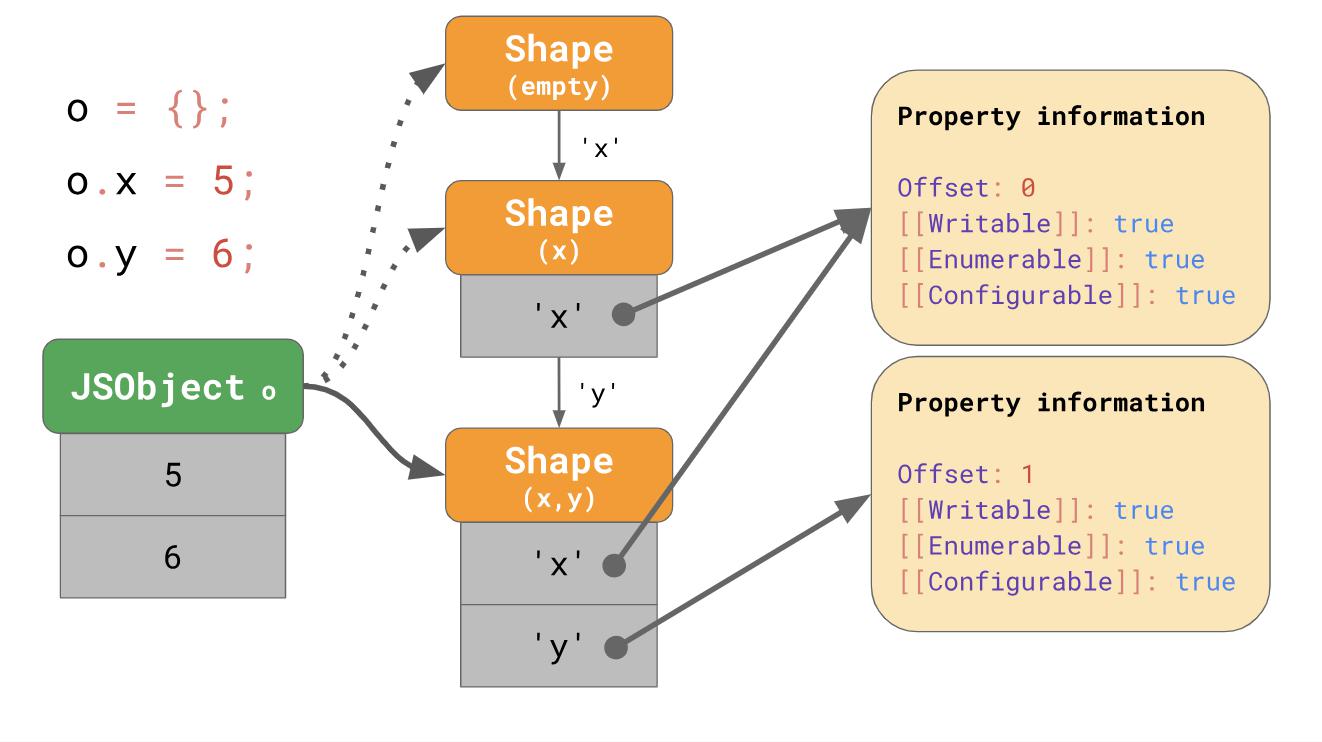
object initially has no properties; it corresponds to an empty form. The following expression adds a property
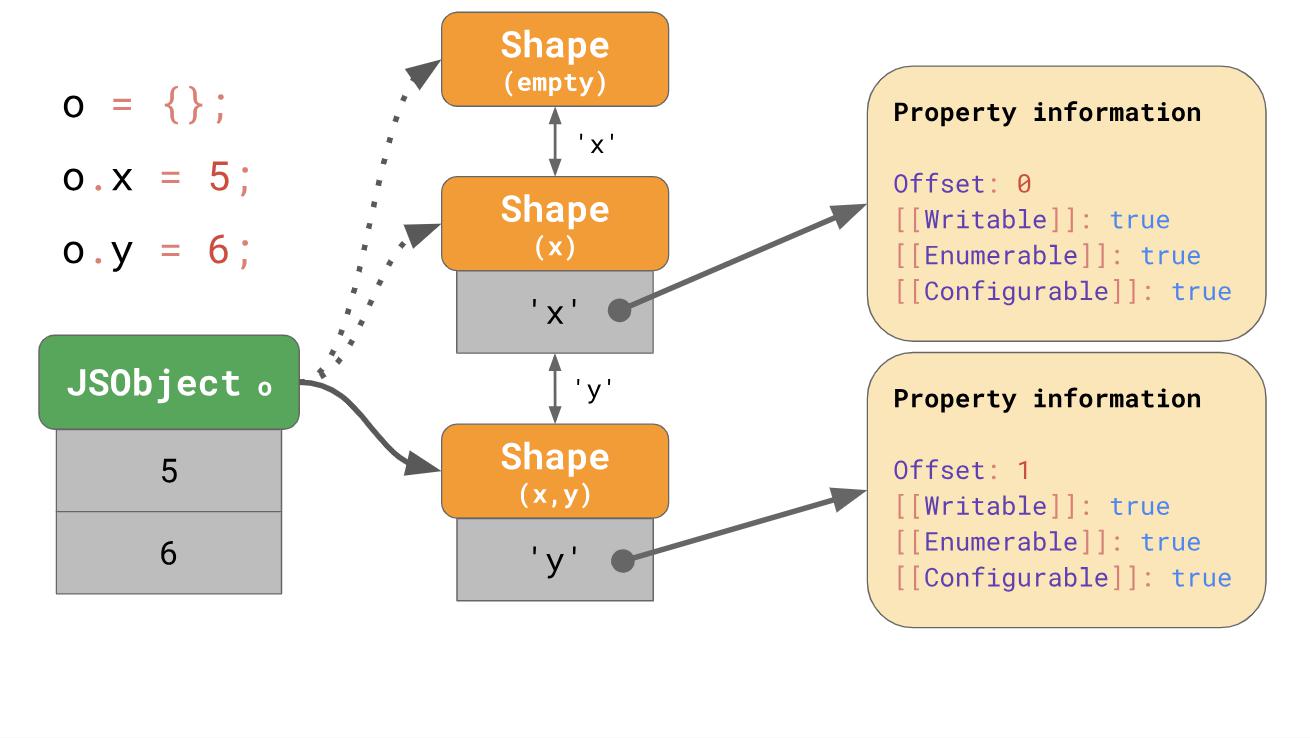
If you write
But what happens if it is impossible to create a transition chain? For example, what happens if you have two empty objects and you add different properties to them?
In this case, a branch appears, and instead of a transition chain we get a transition tree:
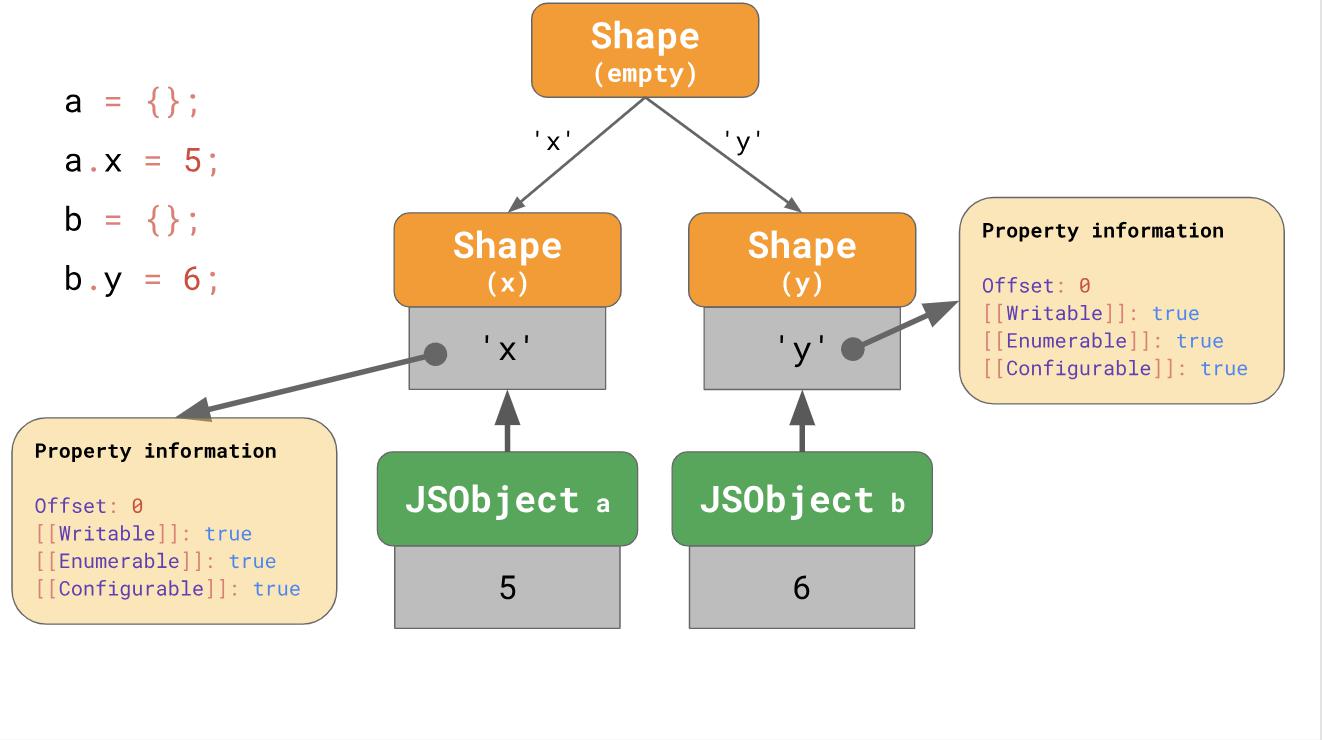
We create an empty object
The second example starts with the fact that we have an empty object
Does this mean that we always start with an empty form? Not necessary. The engines use some optimization of object literals (
In the first example, we start with an empty form and go to the chain, which also contains
In the case of c,
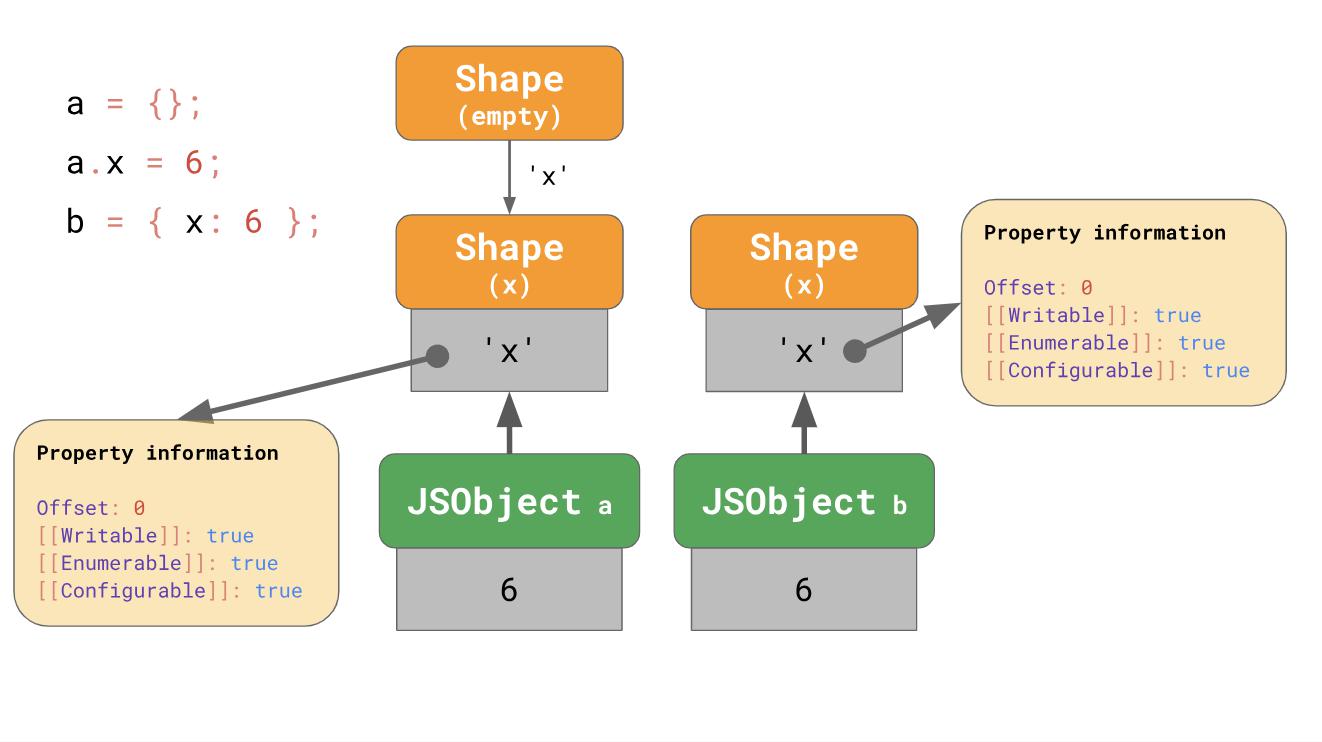
The literal of the object that contains the property
Benedict's blog post on the amazing polymorphism of applications on React talks about how such subtleties can affect performance.
You'll see an example of a three-dimensional object points to the properties
As you understood earlier, we create an object with three forms in memory (not counting the empty form). To access the property of
It turns out very slowly, especially if you do it often and with a lot of properties of the object. The residence time of a property is equal
Wait a second, now we return to the dictionary search ... This is exactly what we started with when we put forms in the first place! So why do we even care about forms?
The fact is that forms contribute to another optimization called Inline Caches.
We'll talk about the concept of inline caches or ICs in the second part of the article, and now we want to invite you to a free open webinar , which will be held by the famous virus analyst and part-time teacher, Alexander Kolesnikov , on April 9th .
The article describes the key foundations, they are common to all JavaScript engines, and not just to V8 , which the authors of the engine ( Benedict and Matias ) are working on . As a JavaScript developer, I can say that a deeper understanding of how the JavaScript engine works will help you figure out how to write efficient code.
Note : if you prefer to watch presentations than read articles, then watch this video . If not, then skip it and read on.Pipeline (pipeline) JavaScript engine
It all starts with the fact that you write code in JavaScript. After that, the JavaScript engine processes the source code and presents it as an abstract syntax tree (AST). Based on the constructed AST, the interpreter can finally get down to work and start generating bytecode. Excellent! This is the moment the engine executes JavaScript code.
To make it run faster, you can send bytecode to the optimizing compiler along with profiling data. The optimizing compiler makes certain assumptions based on profiling data, then it generates highly optimized machine code.
If at some point the assumptions turn out to be incorrect, the optimizing compiler will de-optimize the code and return to the interpreter stage.
Interpreter pipelines / compiler in JavaScript engines
Now let's take a closer look at the parts of the pipeline that execute your JavaScript code, namely where the code is interpreted and optimized, as well as a few differences between the main JavaScript engines.
At the heart of everything is a pipeline that contains an interpreter and an optimizing compiler. The interpreter quickly generates non-optimized bytecode, the optimizing compiler, in turn, works longer, but the output has highly optimized machine code.
Next up is a pipeline that shows how V8 works, the JavaScript engine used by Chrome and Node.js.
The interpreter in V8 is called Ignition, which is responsible for generating and executing bytecode. It collects profiling data that can be used to speed up execution in the next step while the bytecode is being processed. When a function becomes hot , for example, if it starts frequently, the generated bytecode and profiling data are transferred to the TurboFan, that is, to the optimizing compiler to generate highly optimized machine code based on the profiling data.
For example, Mozilla's SpiderMonkey JavaScript engine, which is used in Firefox and SpiderNode, works a little differently. It has not one, but two optimizing compilers. The interpreter is optimized into a basic compiler (Baseline compiler), which produces some optimized code. Together with profiling data collected during code execution, the IonMonkey compiler can generate heavily-optimized code. If speculative optimization fails, IonMonkey returns to the Baseline code.
Chakra - Microsoft's JavaScript engine, used by Edge and Node-ChakraCore, has a very similar structure and uses two optimizing compilers. The interpreter is optimized in SimpleJIT (where JIT stands for "Just-In-Time compiler", which produces optimized code to some extent. Together with the profiling data, FullJIT can create even more highly optimized code.
JavaScriptCore (short for JSC), JavaScript engine from Apple, which is used in Safari and React Native, generally has three different optimizing compilers: LLInt is a low-level interpreter that is optimized into the base compiler, which in turn is optimized in the DFG (Data Flow Graph) compiler, and it is already optimized in FTL (Faster Than Light) compiler.
Why do some engines have more optimizing compilers than others? It is all about compromises. The interpreter can process bytecode quickly, but bytecode alone is not particularly efficient. The optimizing compiler, on the other hand, works a little longer, but produces more efficient machine code. This is a compromise between quickly getting the code (interpreter) or some waiting and running the code with maximum performance (optimizing compiler). Some engines choose to add several optimizing compilers with different characteristics of time and efficiency, which allows you to provide the best control over this compromise solution and understand the cost of additional complication of the internal device. Another tradeoff is memory usage; take a look at thisarticle to better understand this.
We have just examined the main differences between interpreter and optimizer compiler pipelines for various JavaScript engines. Despite these high-level differences, all JavaScript engines have the same architecture: they all have a parser and some kind of interpreter / compiler pipeline.
JavaScript Object Model
Let's see what else JavaScript engines have in common and what techniques they use to speed up access to the properties of JavaScript objects? It turns out that all the main engines do this in a similar way.
The ECMAScript specification defines all objects as dictionaries with string keys matching property attributes .
In addition to
[[Value]], the specification defines the following properties:[[Writable]]determines whether a property can be reassigned;[[Enumerable]]determines whether the property is displayed in for-in loops;[[Configurable]]determines whether a property can be deleted.
The notation
[[двойные квадратные скобки]]looks strange, but that is how the specification describes properties in JavaScript. You can still get these property attributes for any given object and property in JavaScript using the Object.getOwnPropertyDescriptorAPI:const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, 'foo');
// → { value: 42, writable: true, enumerable: true, configurable: true }Ok, so JavaScript defines objects. What about arrays?
You can imagine arrays as special objects. The only difference is that arrays have special index processing. Here, an array index is a special term in the ECMAScript specification. JavaScript has limits on the number of elements in an array - up to 2³² − 1. An array index is any available index from this range, that is, any integer value from 0 to 2³² − 2.
Another difference is that arrays have a magical property
length.const array = ['a', 'b'];
array.length; // → 2
array[2] = 'c';
array.length; // → 3In this example, the array has a length of 2 at the time of creation. Then we assign another element to index 2 and the length automatically increases.
JavaScript defines arrays as well as objects. For example, all keys, including array indices, are represented explicitly as strings. The first element of the array is stored under the key '0'.
A property
lengthis just another property that turns out to be non-enumerable and non-configurable. As soon as an element is added to the array, JavaScript automatically updates the property attribute of the
[[Value]]property length. In general, we can say that arrays behave similarly to objects.
Optimization of access to properties
Now that we know how objects are defined in JavaScript, let's take a look at how JavaScript engines allow you to work with objects efficiently.
In everyday life, access to properties is the most common operation. It is extremely important for the engine to do this quickly.
const object = {
foo: 'bar',
baz: 'qux',
};
// Here, we’re accessing the property `foo` on `object`:
doSomething(object.foo);
// ^^^^^^^^^^Forms
In JavaScript programs, it is quite common practice to assign the same property keys to many objects. They say that such objects have the same shape .
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
// `object1` and `object2` have the same shape. Also common mechanics is access to the property of objects of the same form:
function logX(object) {
console.log(object.x);
// ^^^^^^^^
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);Knowing this, JavaScript engines can optimize access to the property of an object based on its shape. See how it works.
Suppose we have an object with properties x and y, it uses the dictionary data structure, which we talked about earlier; it contains key strings that point to their respective attributes.
If you are accessing a property, for example,
object.y,the JavaScript engine searches for a JSObject by key ‘y’, then it loads the property attributes that match this request and finally returns [[Value]].But where are these property attributes stored in memory? Should we store them as part of a JSObject? If we do this, we will see more objects of this form later, in which case, it is a waste of space to store a complete dictionary containing the names of properties and attributes in JSObject itself, since property names are repeated for all objects of the same form. This causes a lot of duplication and leads to misallocation of memory. For optimization, the engines store the shape of the object separately.
This form (
Shape) contains all property names and attributes except [[Value]]. Instead, the form contains an offset (offset) values inside a JSObject, so the JavaScript engine knows where to look for values. Each JSObject with a common form indicates a specific instance of the form. Now each JSObject has to store only values that are unique to the object. The advantage becomes obvious as soon as we have a lot of objects. Their number does not matter, because if they have one form, we save information about the form and property only once.
All JavaScript engines use forms as a means of optimization, but they do not directly call them forms (
shapes):- The Academic documentation calls them Hidden Classes (similar to JavaScript classes);
- V8 calls them Maps;
- Chakra calls them Types;
- JavaScriptCore calls them Structures;
- SpiderMonkey calls them Shapes.
In this article, we continue to call them forms (
shapes). Transition chains and trees
What happens if you have an object of a certain shape, but you add a new property to it? How does the JavaScript engine define a new form?
const object = {};
object.x = 5;
object.y = 6;Forms create what are called transition chains in the JavaScript engine. Here is an example: An
object initially has no properties; it corresponds to an empty form. The following expression adds a property
‘x’with a value of 5 to this object, then the engine goes to the form that contains the property ‘x’and the value 5 is added to the JSObject at the first offset 0. The next line adds the property ‘y’, then the engine goes to the next form that already contains both ‘x’and ‘y’, and also adds the value 6 to the JSObject at offset 1.Note : The sequence in which properties are added affects the form. For example, {x: 4, y: 5} will result in a different form than {y: 5, x: 4}.We do not even need to store the entire property table for each form. Instead, each form needs to know only a new property that they are trying to include in it. For example, in this case, we do not need to store information about 'x' in the latter form, since it can be found earlier in the chain. For this to work, the form merges with its previous form.
If you write
o.xJavaScript in your code, JavaScript will search for the property ‘x’along the transition chain until it detects a form that already has a property in it ‘x’. But what happens if it is impossible to create a transition chain? For example, what happens if you have two empty objects and you add different properties to them?
const object1 = {};
object1.x = 5;
const object2 = {};
object2.y = 6;In this case, a branch appears, and instead of a transition chain we get a transition tree:
We create an empty object
aand add a property to it ‘x’. As a result, we have JSObject, containing a single value and two forms: empty and a form with a single property ‘x’. The second example starts with the fact that we have an empty object
b, but then we add another property ‘y’. As a result, here we get two chains of forms, but in the end we get three chains. Does this mean that we always start with an empty form? Not necessary. The engines use some optimization of object literals (
object literal) that already contain properties. Say we add x, starting with an empty object literal, or we have an object literal that already contains x:const object1 = {};
object1.x = 5;
const object2 = { x: 6 };In the first example, we start with an empty form and go to the chain, which also contains
x, just as we observed earlier. In the case of c,
object2it makes sense to directly create objects that already have x from the very beginning, rather than starting with an empty object and a transition. The literal of the object that contains the property
‘x’begins with a form that contains ‘x’an empty form from the very beginning. This is (at least) what V8 and SpiderMonkey do. Optimization shortens the transition chain and makes it more convenient to assemble objects from literals. Benedict's blog post on the amazing polymorphism of applications on React talks about how such subtleties can affect performance.
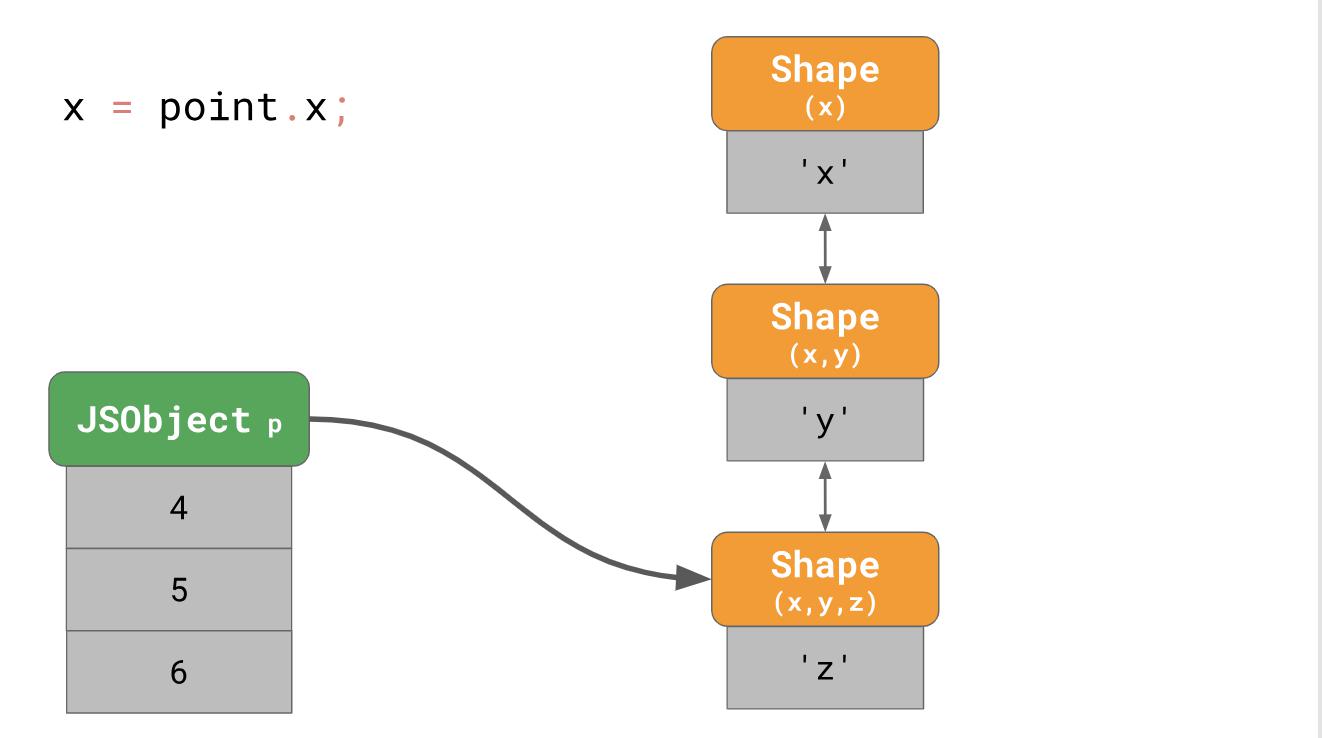
You'll see an example of a three-dimensional object points to the properties
‘x’, ‘y’, ‘z’.const point = {};
point.x = 4;
point.y = 5;
point.z = 6;As you understood earlier, we create an object with three forms in memory (not counting the empty form). To access the property of
‘x’this object, for example, if you write point.xin your program, the JavaScript engine must follow a linked list: starting from the form at the very bottom, and then gradually moving up to the form that has ‘x’at the very top. It turns out very slowly, especially if you do it often and with a lot of properties of the object. The residence time of a property is equal
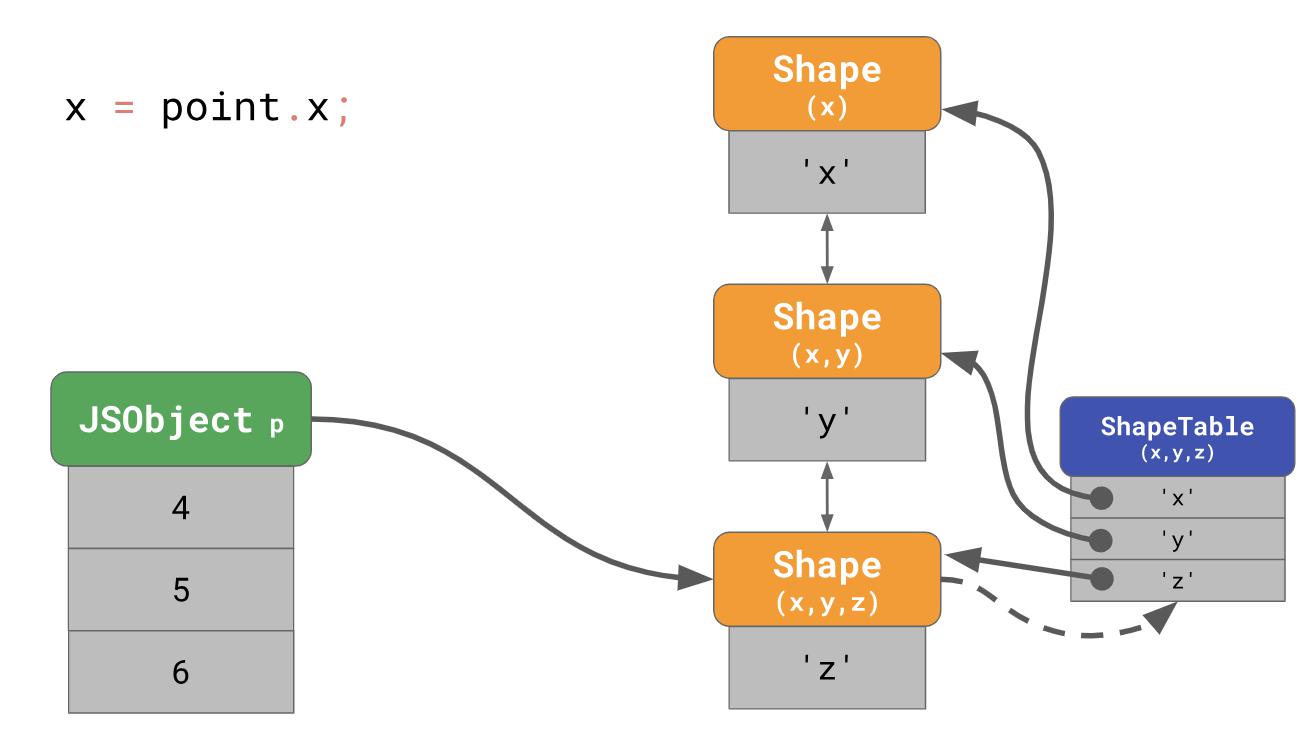
O(n), that is , it is a linear function that correlates with the number of properties of the object. To speed up property searches, JavaScript engines add a ShapeTable data structure. ShapeTable is a dictionary where the keys are mapped in a certain way with the forms and produce the desired property.Wait a second, now we return to the dictionary search ... This is exactly what we started with when we put forms in the first place! So why do we even care about forms?
The fact is that forms contribute to another optimization called Inline Caches.
We'll talk about the concept of inline caches or ICs in the second part of the article, and now we want to invite you to a free open webinar , which will be held by the famous virus analyst and part-time teacher, Alexander Kolesnikov , on April 9th .