Professional Postgres
We continue to publish videos and transcripts of the best reports from the PGConf.Russia 2019 conference . A report by Oleg Bartunov on the topic “Professional Postgres” opened the plenary part of the conference. It reveals the history of Postgres DBMS, the Russian contribution to the development, architecture features.
Previous materials in this series: “Typical Mistakes When Working With PostgreSQL” by Ivan Frolkov, parts 1 and 2 .

I will talk about professional Postgres. Please do not confuse with the company that I represent now - Postgres Professional.

I really will talk about how Postgres, which began as an amateur academic development, became professional - the way we see it now. I will only express my personal opinion, it does not reflect the opinion of either our company or any groups.

It so happened that I use and do not do Postgres snippets, but continuously from 1995 to the present. His whole story passed before my eyes, I am a participant in the main events.
On this slide, I briefly outlined the projects in which I took part. Many of them are familiar to you. And I’ll start the history of Postgres right away with a picture that I painted many, many years ago and then I just drew it up - the number of versions is increasing and increasing. It reflects the evolution of relational databases. On the left, if anyone does not know, this is Michael Stonebreaker , who is called the father of Postgres. Below are our first "nuclear" developers. The person sitting to the right is Vadim Mikheev from Krasnoyarsk, he was one of the first core developers.
I will begin the story of the relational model with IBM, which has made a huge contribution to the industry. It was IBM who worked for Edgar Codd , the first white paper on IBM System R came from its bowels.- This was the first relational base. Mike Stonebreaker worked at that time in Burkeley. He read this article and caught fire with his guys: we need to create a database.

In those years - at the beginning of the 70s - as you suspect, there were not many computers. There was one PDP-11 for the entire Computer science department at Berkeley, and all students and faculty fought for machine time. This machine was mainly used for calculations. I myself worked like this when I was young: you give the operator a task, he starts it. But students and developers wanted interactive work. It was our dream - to sit at the remote control, enter programs, debug them. And when Mike Stonebreaker and his friends made the first base, they called it Ingres- INteractive Grafic REtrieval System. People did not understand: why interactive? And it was just the dream of its developers that came true. They had a console client with which they could work with Ingres. He gave a lot of our industry. Do you see how many arrows there are from Ingres? These are the databases that he influenced, which fumbled his code. Michael Stonebreaker had a lot of development students who left and then developed Sybase and MS SQL , NonStop SQL , Illustra , Informix .
When Ingres developed so much that it became interesting from a commercial point of view, Illustra (it was 1992) was formed, and the Illustra DBMS codewas purchased by Informix , which was later eaten by IBM , and thus this code went into DB2 . But what interested IBM in Ingres? First of all, extensibility - those revolutionary ideas that Michael Stonebreaker laid down from the very beginning, thinking that the database should be ready to solve any business problems. And for this it is necessary that you can add your data types, access-methods and functions to the database. Now, to us postgresists, this seems natural. In those years, it was a revolution. Since the time of Ingres and Postgres, these features, this functionality have become the de facto standard for all relational databases. Now all databases have user functions, and when Stonebreaker wrote that user functions are needed, Oraclefor example, she screamed that it was dangerous, and that this could not be done because users could harm the data. Now we see that user-defined functions exist in all databases, that you can make your own aggregates and data types.

Postgres developed as an academic development, which means: there is a professor, he has a grant for development, students and graduate students who work with him. A serious base, ready for production, cannot be done like that. However , SQL has already been added to the latest release from Berkeley - Postgres95. Student developers at that time already began to work at Illustra, made Informix and lost interest in the project. They said: we have Postgres95, take it whoever needs it! I remember all this very well because I myself was one of those who received this letter: there was a mailing list, and there were less than 400 subscribers in it. The Postgres95 community began with these 400 people. We all voted together to take this project. We found an enthusiast who picked up the CVS server, and we dragged everything to Panama, since the servers were there.
The history of PostgreSQL [simply Postgres hereafter] begins with version 6.0, since versions 1, 4, 5 were still Postgres95. On April 3, 1997, our logo appeared - an elephant. Before that, we had different animals. On my page, for example,For a long time there was a cheetah , hinting that Postgres is very fast. Then a question was raised in the mailing list: our large database needs a serious animal. And someone wrote: let it be an elephant. Everyone voted together, then our guys from St. Petersburg drew this logo. Initially, it was an elephant in a diamond - if you dig deeper into a time machine, you will see it. The elephant was chosen because elephants have a very good memory. Even Agatha Christie has a story “Elephants can remember”: the elephant is very vengeful, he remembered the offense for about fifty years, and then crushed the offender. The diamond was then split off, the vectorized pattern, and the result was this elephant. So this is one of the first Russian contributions to Postgres.
 Cheetah replaced Elephant in the diamond:
Cheetah replaced Elephant in the diamond:
The first task was to stabilize his work. The community has adopted the source code for academic developers. What was not there! They started shoveling all this to compile decently. On this slide, I highlighted the year 1997, version 6.1 - internationalization appeared in it. I highlighted it not because I did it myself (it really was my first patch), but because it was an important stage. You are already used to the fact that Postgres works with any language, in any locales - all over the world. And then he understood only ASCII, that is, no 8 bits, no European languages, no Russian. Having discovered this, following the principles of open-source, I just took and made support for locales. And thanks to this work, Postgres went into the world. After me, Japanese Tatsuo Ishii[Tatsuo Ishii] made support for multibyte encodings, and Postgres became truly worldwide.
In 2005, Windows support was introduced . I remember these heated debates when they were discussing this in the mailing list. All developers were normal people, they worked under Unix . You are clapping right now, and in the same way the people reacted then. And voted against. It lasted for years. Moreover, SRA Computers released their Powergres several years earlier .- native port on Windows. But it was a purely Japanese product. When in 2005 in the 8th version we got support for Windows, it turned out that this was a strong step: the community was swollen. There were a lot of people and a lot of stupid questions, but the community became big, we grabbed vinduzovye users.
In 2010, we had built-in replication. It is a pain. I remember how many years people struggled for replication to be in Postgres. At first everyone said: we do not need replication, this is not a database matter, this is a matter of external utilities. If anyone remembers, Slony did Ian Wieck[Jan Wieck]. By the way, “elephants” also came from the Russian language: Jan asked me how “many elephants” would be in Russian, and I replied: “elephants”. So he made Slony. These elephants worked like logical replication on triggers, configuring them was a nightmare - veterans remember. Moreover, everyone listened for a long time to Tom Lane , who, I remember, desperately shouted: why should we complicate the code with replication if it can be done outside the base? But as a result, inline replication still appeared. This immediately yielded a huge number of enterprise users, because before that, such users said: how can we even live without replication? It's impossible!
In 2014, jsonb appeared. This is my work, Fedor Sigaev and Alexander Korotkov. And also the people shouted: why do we need this? In general, we already had the hstore, which we made in 2003, and in 2006 he entered Postgres. People used it beautifully around the world, loved it, and if you type hstore on google , a huge amount of documents appeared. Very popular extension. And we strongly promoted the idea of unstructured data in Postgres. From the very beginning of my work, I was just interested in this, and when we did jsonb , I received a lot of letters of thanks and questions. And the community has got NoSQL users! Before jsonb, people zombified by hype went to the key-value of the database. However, they were forced to sacrifice integrity, ACID-nost. And we gave them the opportunity, without sacrificing anything, to work with their beautiful json. The community has grown sharply again.
In 2016, we got parallel query execution. If anyone does not know, this, of course, is not for OLTP. If you have a loaded machine, then all the kernels are already busy. Concurrent query execution is valuable for OLAP users. And they appreciated it, that is, a certain number of OLAP users began to arrive in the community .
Next came the cumulative processes. In 2017, we received logical replication and declarative partitioning - it was also a big and serious step because logical replication made it possible to make very, very interesting systems, people got unlimited freedom for their imagination and started making clusters. Using declarative partitioning, it became possible not to create partitions manually, but using SQL.
In 2018, in the 11th version, we got JIT . Who doesn’t know, this is Just In Time compiler: you compile requests, and it can really speed up execution very much. This is important for speeding up slow queries because fast queries are already fast, and overhead for compilation is still significant.
In 2019, the most basic thing we expect ispluggable storage, an API so that developers can create their own repositories, one example of which is zheap - a repository developed by EnterpriseDB .
And here is our development: SQL / JSON. I really hoped that Sasha Korotkov would commit him before the conference, but there were some problems there, and now we hope that all the same we will get SQL / JSON this year . People have been waiting for it for two years [a significant part of the SQL / JSON: jsonpath patch has been commited now, this is described in detail here ].

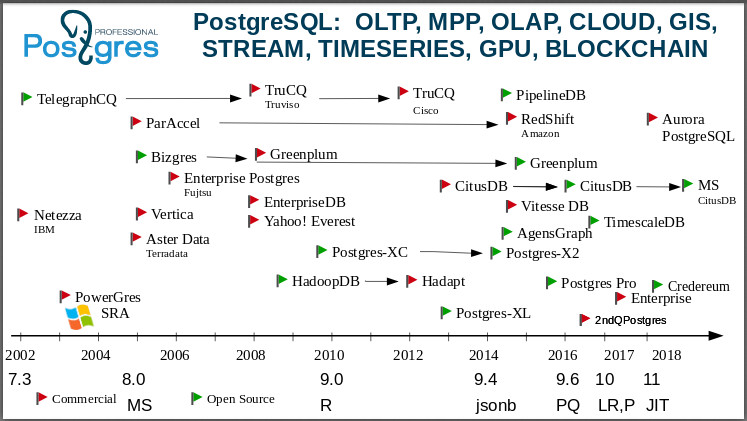
Next, I move on to a slide that shows: Postgres is a universal database. You can study this picture for hours, tell a bunch of stories about the emergence of companies, the takeover, the death of companies. I will start in the year 2000. One of the first forks of Postgres is the IBM Netezza . Just imagine: the “Blue Giant” took the Postgres code and built a base for OLAP to support its BI!
Here is a fork of TelegraphCQ: Already in 2000, people made a streaming database based on Postgres in Berkeley. If anyone does not know, this is a database that is not interested in the data itself, but interested in their aggregates. Now there are a lot of tasks where you do not need to know each value, for example, the temperature at some point, but you need an average value in this region. And in TelegraphCQ they took this idea (also arising in Berkeley), one of the most advanced ideas of that time, and developed a base based on Postgres. It further evolved, and in 2008, on its basis, a commercial product was released - the TruCQ base , now its owner is Cisco .
I forgot to say that not all forks are on this page, there are twice as many of them. I chose the most important and interesting, so as not to clutter up the picture. On theThe postgresql wiki page lists all the forks. Who knows an open source database that would have so many forks? There are no such bases.
Postgres differs from other databases not only in its functionality, but also in that it
a very interesting community, it normally accepts forks. In the world of open source, it is generally accepted: I made a fork because I was offended - you did not support me, so I decided to conduct my own development. In the post-Greek world, the appearance of a fork means: some people or some company decided to make some prototype and test the functionality they invented, to experiment. And if you're lucky, then make a commercial base that can be sold to customers, provide them with service, and so on. At the same time, as a rule, the developers of all these forks return their achievements and patches to the community. The product of our company is also fork, and it is clear that we returned a bunch of patches back to the community. In the latest, 11th version, we returned more than 100 patches to the community. If you look at her release notes, then there will be 25 names of our employees. This is normal community behavior. We use the community version and make our fork in order to test our ideas or give customers functionality before the community ripens for its adoption. Forks in the Postgres community are very welcome.
The famous Vertica came from the C-Store - also grew from Postgres. Some people claim that Vertica did not have Postgres source code at all, but only support for the postgres protocol. Nevertheless, it is customary to classify it as a post-Greek forks.
Greenplum . Now you can download it and use it as a cluster. He arose from Bizgres- massively parallel database. Then it was bought by Greenplum, became and for a long time remained commercial. But you see that around 2015, they realized that the world has changed: the world is moving towards open protocols, open communities, open databases. And they opened the Greenplum codes. Now they are actively catching up with Postgres because they have lagged behind, of course, very much. They have budged at 8.2, and now they say that they caught up with 9.6.
We all love and dislike Amazon . You know how it came about. It happened before my eyes. There was a company, there was ParAccel with vector processing, also on Postgres - a community product, open. In 2012, the cunning Amazon bought the source code and literally six months later announced that we now have RDS in Amazon. We then asked them, they hesitated for a long time, but then it turned out that it was Postgres. RDS still lives, and this is one of Amazon’s most popular services, they have about 7,000 bases spinning there. But they did not calm down on this, and in 2010 Amazon Aurora appeared - Postgres 10 with a rewritten story that is sewn directly into Amazon's infrastructure, in their distributed storage.
Take a look now at Teradata . A large, good old analytics company, OLAP . After the G8 [PostgreSQL 8.0], Aster Data arose .
Hadoop : we have Postgres on Hadoop - HadoopDB . After a while, it became a closed Hadapt base owned byTeradata . If you see Hadapt, know what Postgres is inside.
A very interesting fate with Citus . Everyone knows that this is Postgres distributed for online analytics. It does not support transactions. Citus Data was a startup, and Citus was closed source, a separate database. After some time, people realized that it was better to live with the community, to open up. And they did a lot to become just an extension of Postgres. Plus, they began to do business already on the provision of their cloud services. You all already know: MS Citus is written here because Microsoft bought them, literally two weeks ago. Probably in order to support Postgres on its Azurethat is, Microsoft also plays these games. They have Postgres running on Azure, and the Citus development team has joined the MS developers.
In general, recently the processes of buying post-gres companies have gone intensively. Just after Microsoft bought Citus, another postgres company, credativ , bought OmniTI to strengthen its market presence. These are two well-known, solid companies. And Amazon bought OpenSCG . The postgres world is changing now, and I'll show you why there is so much interest in Postgres.
The acclaimed TimescaleDBit was also a separate database, but it is now an extension: you take Postgres and set timescaledb as an extension and get a database that breaks all kinds of specialized databases.
There is also Postgres XL, there are clusters that are developing.
Here in 2015, I set our fork: Postgres Pro . We have Postgres Pro Enterprise , there is a certified version, we support 1C out of the box and we are recognized by 1C . If anyone wants to try Postgres Pro Enterprise, then you can take the distribution kit for free, and if you need it for work, you can buy it.
We made Credereum- a prototype database with blockchain support. Now we are waiting for the people to mature in order to start using it.
See how big and interesting the picture is. I'm not even talking about Yahoo! Everest with column storage, with petabytes of data in Yahoo! - it was the 2008th year. They even sponsored our conference in Canada, came there, somewhere I even have a shirt from there :)
There is also PipelineDB. It also began as a closed source database, but now it is also just an extension. We see that Citus, TimescaleDB and PipelineDB are like separate databases, but at the same time they exist as extensions, that is, you take the standard Postgres and compile the extension. PipelineDB is a continuation of the idea of stream databases. Want to work with streams? Take Postgres, take PipelineDB and you can work.
In addition, there are extensions that allow you to work with the GPU . See the headline? I have shown that there is an ecosystem that spans a large number of different types of data and loads. Therefore, we say that Postgres is a universal database.

The next slide has big names. All the most famous clouds in the world support Postgres. In Russia, Postgres is supported by large state-owned companies. They use it, and we serve them as our customers.

There are already many extensions and many applications, so Postgres is good as the database from which the project starts. I always say to startups: guys, you don’t need to take NoSQL database. I understand that you really want to, but start with Postgres. If you don’t have enough, you can always unhook a service and give it to a specialized database. In addition to universality, Postgres has one more advantage: a very liberal BSD license, which allows you to do anything with your database.
Everything that you see on this slide is accessible due to the fact that Postgres is an extensible database, and this extensibility is built right into the database architecture. When Michael Stonebreaker wrote about Postgres in his first article about him (it was written by him in 1984, here I quote an article from 1987), he already talked about extensibility as the most important component of database functionality. And this, as they say, has already been tested by time. You can add your own functions, your data types, operators, index accesses (that is, optimized access-methods), you can write your procedures in a very large number of languages. We have a Foreign Data Wrapper ( FDW ), that is, interfaces for working with different repositories, files, you can connect to Oracle , MySQLand other bases.
I want to give an example from my own personal experience. I worked with Postgres and when something was missing in Postgres, my colleagues and I simply added this functionality. We needed to work, for example, with the Russian language, and we made an 8-bit locale. It was a Rambler project . By the way, he was then in the top 5. Ramblerwas the first major global project to launch on Postgres. Arrays in Postgres were from the very beginning, but they were such that nothing could be done with them, it was just a text line in which the arrays were stored. We added operators, made indexes, and now arrays are an integral part of the Postgres functionality, and many of you use them without worrying about how fast they work - and that's fine. They used to say that arrays is no longer a traditional relational model, it does not satisfy the classical normal forms. Now people are already used to using arrays.

When we needed a full-text search, we did it. When we needed to store data of different nature, we made the hstore extension, and many people began to use it: it made it possible to build flexible database schemas so that it could be faster and faster. We made a GIN index to make full-text search work fast. We made trigrams ( pg_trgm ). Made NoSQL. And all this is in my memory, all of my own needs.

Extensibility makes Postgres a unique database, a universal database with which you can start working and not be afraid that you will be left without support. Look how many people here we have - this is already a market! Despite the fact that now hype - graph databases, document databases, time series and so on - look: most still use relational databases. They dominate, this is 75% of the database market, and the rest are exotic databases, a trifle compared to relational ones.

If you look at the ratio of open source to commercial databases, then, according
to DB-Engines, we will see that the number of open source databases is almost equal to the number of commercial databases. And we see that open source databases (blue line) are growing, and commercial (red) are falling. This is the direction of the development of the entire IT community, the direction of openness. Now, of course, it is indecent to refer to Gartner , but I’ll say it anyway: they predict that by 2022 70% will use open databases and up to 50% of existing systems will migrate to open source.
Look at this pomosomer: we see that Postgres is called the database of 2018. Last year, she was also the first independent expert estimate of DB-Engines. The ranking shows that Postgres is really ahead of the rest. It is in absolute terms in 4th place, but look how it grows. Sure, good. On the slide, this is a blue line. The rest - MySQL, Oracle, MS SQL - either balances at its level, or begins to bend.

Hacker news - you all probably read it or Y Combinator- polls are periodically conducted there, companies publish their vacancies there, and for some time they have been conducting statistics. You see that starting around 2014, Postgres is ahead of everyone. It was the 1st MySQL, but Postgres has slowly grown, and now among the entire hacker community (in the good sense of the word) it also prevails and grows further.

The Stack Overflow , too, each year conduct surveys. By most used, our Postgres is in a good, third place. By most loved - on the second. This is a favorite database. Redis is not a relational database, but relational Postgres is a favorite. I did not give here the most dreaded picture- the most terrible database, but you probably guess who comes first. "Base X," as they like to call it in Russia.

There is a review in Russia, a survey at all of us at the respected HighLoad ++ conference . It was not conducted by us, it was made by Oleg Bunin . It turned out: in Russia Postgres database No. 1.

We are asking HH.ru for the second time to share Postgres job statistics with us. 9 years ago Postgres was 10 times behind Oracle, everyone shouted: give us oracleists. And we see that last year we caught up, and then in 2018 there was growth. And if you are worried about where to find a job, then see: 2 thousand vacancies on HH.ru is Postgres. Do not worry, enough work.

In order to make it easier to see, I took a picture where I showed Postgres vacancies regarding Oracle vacancies. There were fewer ones, starting from 2018 they are already on par, and now Postgres has already become a little more. So far it is a little depressing that the absolute number of Oracle vacancies is also growing, which in principle should not be. But, as they say, we are sitting near the riverbank and watching: when will the enemy’s corpse float by. We are just doing our job.

This is the most organized community in Russia, I have never met such people. A lot of resources, chats, where we all communicate on business. We hold conferences - two large conferences: in St. Petersburg and Moscow, apartment houses, we participate in all major international conferences, conduct courses.

In fact, these are community courses. They were prepared by our company, but they are freely available to any of you, look at our channel on youtube or go to the Education section on our website, there are DBA1 , DBA2 , DBA3 courses, and development courses for free download .
And now we are launching certification - this is what companies are asking for, they want to have certified specialists. And the employer will know: you are a certified specialist.

They often ask: how much Russian Postgres? The question is a little misplaced: Postgres is international. But I’ll say a little about the Russian flag. You see on the slide what Vadim Mikheev did . Those who know Postgres understand that MVCC , WAL , VACUUM and so on mean for this base . This is all the Russian contribution. Now there are three leading developers of Postgres, of which two are committers. On the slide you see that quite a lot has been done. If you look at major features from release notes, then you will see our contribution. The Russian contribution is substantial enough. We worked from the very beginning and continue to work with the community - already at the campaign level.

And the company's contribution is books. We have 2 Postgres university courses. You can go to the store and buy these books, you can teach at these courses, take exams and so on. We have books for beginners that are distributed, including here. Very useful good book. We even translated it into English.
Let's move on to the main one. Academic Postgres, when it started, was designed for several dozen users. The Postgres95 community had less than 400 people. The community consisted mainly of developers and few more users. At the same time - an interesting detail - the developers were mainly both customers and contractors. For example, when I needed it, I developed for myself and, at the same time, shared with everyone. That is, the community was developing for the community.
Starting from the year 2000, a little earlier, the first post-Grace companies began to appear: GreatBridge , 2ndQuadrant , EDB. They already hired full-time developers who worked for the community. The first enterprise forks and the first enterprise customisers appeared. This led to the fact that by 2015 the main number - and almost all the leading developers - were already organized in some companies. In 2015, our company was formed: we were the last free freelance developers. Now there are practically no such people. The postgres community has changed, it has become an enterprise, and now these companies are driving development. This is good because these companies carry out what the enterprise needs. The community is a brake in a good way: it tests features, condemns or accepts new features, it unites all of us. And Postgres became enterprise readyHe is used with pleasure by large companies, he has become a professional.

This slide is about the future, as I see it. With the advent of pluggable storage , new storages will appear: append-only , read-only , column storage - whatever you want (for example, I dream about parquet). There will be support for vector operations. Today, by the way, there will be a report about them. Blockchain will be supported. There is no getting away from this, since we are moving to the digital economy, to paperless technologies. You will need to use electronic signatures and you will need to be able to authenticate your database, make sure that no one has changed anything, and the blockchain is very suitable for this.


Next: Responsive Postgres. This is a little sad topic for you, but it is still quite far from you. The fact is that DBA, generally speaking, is an expensive resource, and soon databases will not need them. The bases will be smart enough and will configure and adjust themselves. But it will be in another ten years, probably. We still have a lot of time.

And it is clear that in Postgres there will be native support for clouds, cloud storage - without this, we simply can not survive. And, of course, here it is, the last slide:
EVERYTHING YOU NEED IS POSTGRES!

Thanks for attention.
Previous materials in this series: “Typical Mistakes When Working With PostgreSQL” by Ivan Frolkov, parts 1 and 2 .
I will talk about professional Postgres. Please do not confuse with the company that I represent now - Postgres Professional.
I really will talk about how Postgres, which began as an amateur academic development, became professional - the way we see it now. I will only express my personal opinion, it does not reflect the opinion of either our company or any groups.
It so happened that I use and do not do Postgres snippets, but continuously from 1995 to the present. His whole story passed before my eyes, I am a participant in the main events.
History
On this slide, I briefly outlined the projects in which I took part. Many of them are familiar to you. And I’ll start the history of Postgres right away with a picture that I painted many, many years ago and then I just drew it up - the number of versions is increasing and increasing. It reflects the evolution of relational databases. On the left, if anyone does not know, this is Michael Stonebreaker , who is called the father of Postgres. Below are our first "nuclear" developers. The person sitting to the right is Vadim Mikheev from Krasnoyarsk, he was one of the first core developers.
I will begin the story of the relational model with IBM, which has made a huge contribution to the industry. It was IBM who worked for Edgar Codd , the first white paper on IBM System R came from its bowels.- This was the first relational base. Mike Stonebreaker worked at that time in Burkeley. He read this article and caught fire with his guys: we need to create a database.
In those years - at the beginning of the 70s - as you suspect, there were not many computers. There was one PDP-11 for the entire Computer science department at Berkeley, and all students and faculty fought for machine time. This machine was mainly used for calculations. I myself worked like this when I was young: you give the operator a task, he starts it. But students and developers wanted interactive work. It was our dream - to sit at the remote control, enter programs, debug them. And when Mike Stonebreaker and his friends made the first base, they called it Ingres- INteractive Grafic REtrieval System. People did not understand: why interactive? And it was just the dream of its developers that came true. They had a console client with which they could work with Ingres. He gave a lot of our industry. Do you see how many arrows there are from Ingres? These are the databases that he influenced, which fumbled his code. Michael Stonebreaker had a lot of development students who left and then developed Sybase and MS SQL , NonStop SQL , Illustra , Informix .
When Ingres developed so much that it became interesting from a commercial point of view, Illustra (it was 1992) was formed, and the Illustra DBMS codewas purchased by Informix , which was later eaten by IBM , and thus this code went into DB2 . But what interested IBM in Ingres? First of all, extensibility - those revolutionary ideas that Michael Stonebreaker laid down from the very beginning, thinking that the database should be ready to solve any business problems. And for this it is necessary that you can add your data types, access-methods and functions to the database. Now, to us postgresists, this seems natural. In those years, it was a revolution. Since the time of Ingres and Postgres, these features, this functionality have become the de facto standard for all relational databases. Now all databases have user functions, and when Stonebreaker wrote that user functions are needed, Oraclefor example, she screamed that it was dangerous, and that this could not be done because users could harm the data. Now we see that user-defined functions exist in all databases, that you can make your own aggregates and data types.
Postgres developed as an academic development, which means: there is a professor, he has a grant for development, students and graduate students who work with him. A serious base, ready for production, cannot be done like that. However , SQL has already been added to the latest release from Berkeley - Postgres95. Student developers at that time already began to work at Illustra, made Informix and lost interest in the project. They said: we have Postgres95, take it whoever needs it! I remember all this very well because I myself was one of those who received this letter: there was a mailing list, and there were less than 400 subscribers in it. The Postgres95 community began with these 400 people. We all voted together to take this project. We found an enthusiast who picked up the CVS server, and we dragged everything to Panama, since the servers were there.
The history of PostgreSQL [simply Postgres hereafter] begins with version 6.0, since versions 1, 4, 5 were still Postgres95. On April 3, 1997, our logo appeared - an elephant. Before that, we had different animals. On my page, for example,For a long time there was a cheetah , hinting that Postgres is very fast. Then a question was raised in the mailing list: our large database needs a serious animal. And someone wrote: let it be an elephant. Everyone voted together, then our guys from St. Petersburg drew this logo. Initially, it was an elephant in a diamond - if you dig deeper into a time machine, you will see it. The elephant was chosen because elephants have a very good memory. Even Agatha Christie has a story “Elephants can remember”: the elephant is very vengeful, he remembered the offense for about fifty years, and then crushed the offender. The diamond was then split off, the vectorized pattern, and the result was this elephant. So this is one of the first Russian contributions to Postgres.
Cheetah replaced Elephant in the diamond:Postgres Development Stages
The first task was to stabilize his work. The community has adopted the source code for academic developers. What was not there! They started shoveling all this to compile decently. On this slide, I highlighted the year 1997, version 6.1 - internationalization appeared in it. I highlighted it not because I did it myself (it really was my first patch), but because it was an important stage. You are already used to the fact that Postgres works with any language, in any locales - all over the world. And then he understood only ASCII, that is, no 8 bits, no European languages, no Russian. Having discovered this, following the principles of open-source, I just took and made support for locales. And thanks to this work, Postgres went into the world. After me, Japanese Tatsuo Ishii[Tatsuo Ishii] made support for multibyte encodings, and Postgres became truly worldwide.
In 2005, Windows support was introduced . I remember these heated debates when they were discussing this in the mailing list. All developers were normal people, they worked under Unix . You are clapping right now, and in the same way the people reacted then. And voted against. It lasted for years. Moreover, SRA Computers released their Powergres several years earlier .- native port on Windows. But it was a purely Japanese product. When in 2005 in the 8th version we got support for Windows, it turned out that this was a strong step: the community was swollen. There were a lot of people and a lot of stupid questions, but the community became big, we grabbed vinduzovye users.
In 2010, we had built-in replication. It is a pain. I remember how many years people struggled for replication to be in Postgres. At first everyone said: we do not need replication, this is not a database matter, this is a matter of external utilities. If anyone remembers, Slony did Ian Wieck[Jan Wieck]. By the way, “elephants” also came from the Russian language: Jan asked me how “many elephants” would be in Russian, and I replied: “elephants”. So he made Slony. These elephants worked like logical replication on triggers, configuring them was a nightmare - veterans remember. Moreover, everyone listened for a long time to Tom Lane , who, I remember, desperately shouted: why should we complicate the code with replication if it can be done outside the base? But as a result, inline replication still appeared. This immediately yielded a huge number of enterprise users, because before that, such users said: how can we even live without replication? It's impossible!
In 2014, jsonb appeared. This is my work, Fedor Sigaev and Alexander Korotkov. And also the people shouted: why do we need this? In general, we already had the hstore, which we made in 2003, and in 2006 he entered Postgres. People used it beautifully around the world, loved it, and if you type hstore on google , a huge amount of documents appeared. Very popular extension. And we strongly promoted the idea of unstructured data in Postgres. From the very beginning of my work, I was just interested in this, and when we did jsonb , I received a lot of letters of thanks and questions. And the community has got NoSQL users! Before jsonb, people zombified by hype went to the key-value of the database. However, they were forced to sacrifice integrity, ACID-nost. And we gave them the opportunity, without sacrificing anything, to work with their beautiful json. The community has grown sharply again.
In 2016, we got parallel query execution. If anyone does not know, this, of course, is not for OLTP. If you have a loaded machine, then all the kernels are already busy. Concurrent query execution is valuable for OLAP users. And they appreciated it, that is, a certain number of OLAP users began to arrive in the community .
Next came the cumulative processes. In 2017, we received logical replication and declarative partitioning - it was also a big and serious step because logical replication made it possible to make very, very interesting systems, people got unlimited freedom for their imagination and started making clusters. Using declarative partitioning, it became possible not to create partitions manually, but using SQL.
In 2018, in the 11th version, we got JIT . Who doesn’t know, this is Just In Time compiler: you compile requests, and it can really speed up execution very much. This is important for speeding up slow queries because fast queries are already fast, and overhead for compilation is still significant.
In 2019, the most basic thing we expect ispluggable storage, an API so that developers can create their own repositories, one example of which is zheap - a repository developed by EnterpriseDB .
And here is our development: SQL / JSON. I really hoped that Sasha Korotkov would commit him before the conference, but there were some problems there, and now we hope that all the same we will get SQL / JSON this year . People have been waiting for it for two years [a significant part of the SQL / JSON: jsonpath patch has been commited now, this is described in detail here ].
Next, I move on to a slide that shows: Postgres is a universal database. You can study this picture for hours, tell a bunch of stories about the emergence of companies, the takeover, the death of companies. I will start in the year 2000. One of the first forks of Postgres is the IBM Netezza . Just imagine: the “Blue Giant” took the Postgres code and built a base for OLAP to support its BI!
Here is a fork of TelegraphCQ: Already in 2000, people made a streaming database based on Postgres in Berkeley. If anyone does not know, this is a database that is not interested in the data itself, but interested in their aggregates. Now there are a lot of tasks where you do not need to know each value, for example, the temperature at some point, but you need an average value in this region. And in TelegraphCQ they took this idea (also arising in Berkeley), one of the most advanced ideas of that time, and developed a base based on Postgres. It further evolved, and in 2008, on its basis, a commercial product was released - the TruCQ base , now its owner is Cisco .
I forgot to say that not all forks are on this page, there are twice as many of them. I chose the most important and interesting, so as not to clutter up the picture. On theThe postgresql wiki page lists all the forks. Who knows an open source database that would have so many forks? There are no such bases.
Postgres differs from other databases not only in its functionality, but also in that it
a very interesting community, it normally accepts forks. In the world of open source, it is generally accepted: I made a fork because I was offended - you did not support me, so I decided to conduct my own development. In the post-Greek world, the appearance of a fork means: some people or some company decided to make some prototype and test the functionality they invented, to experiment. And if you're lucky, then make a commercial base that can be sold to customers, provide them with service, and so on. At the same time, as a rule, the developers of all these forks return their achievements and patches to the community. The product of our company is also fork, and it is clear that we returned a bunch of patches back to the community. In the latest, 11th version, we returned more than 100 patches to the community. If you look at her release notes, then there will be 25 names of our employees. This is normal community behavior. We use the community version and make our fork in order to test our ideas or give customers functionality before the community ripens for its adoption. Forks in the Postgres community are very welcome.
The famous Vertica came from the C-Store - also grew from Postgres. Some people claim that Vertica did not have Postgres source code at all, but only support for the postgres protocol. Nevertheless, it is customary to classify it as a post-Greek forks.
Greenplum . Now you can download it and use it as a cluster. He arose from Bizgres- massively parallel database. Then it was bought by Greenplum, became and for a long time remained commercial. But you see that around 2015, they realized that the world has changed: the world is moving towards open protocols, open communities, open databases. And they opened the Greenplum codes. Now they are actively catching up with Postgres because they have lagged behind, of course, very much. They have budged at 8.2, and now they say that they caught up with 9.6.
We all love and dislike Amazon . You know how it came about. It happened before my eyes. There was a company, there was ParAccel with vector processing, also on Postgres - a community product, open. In 2012, the cunning Amazon bought the source code and literally six months later announced that we now have RDS in Amazon. We then asked them, they hesitated for a long time, but then it turned out that it was Postgres. RDS still lives, and this is one of Amazon’s most popular services, they have about 7,000 bases spinning there. But they did not calm down on this, and in 2010 Amazon Aurora appeared - Postgres 10 with a rewritten story that is sewn directly into Amazon's infrastructure, in their distributed storage.
Take a look now at Teradata . A large, good old analytics company, OLAP . After the G8 [PostgreSQL 8.0], Aster Data arose .
Hadoop : we have Postgres on Hadoop - HadoopDB . After a while, it became a closed Hadapt base owned byTeradata . If you see Hadapt, know what Postgres is inside.
A very interesting fate with Citus . Everyone knows that this is Postgres distributed for online analytics. It does not support transactions. Citus Data was a startup, and Citus was closed source, a separate database. After some time, people realized that it was better to live with the community, to open up. And they did a lot to become just an extension of Postgres. Plus, they began to do business already on the provision of their cloud services. You all already know: MS Citus is written here because Microsoft bought them, literally two weeks ago. Probably in order to support Postgres on its Azurethat is, Microsoft also plays these games. They have Postgres running on Azure, and the Citus development team has joined the MS developers.
In general, recently the processes of buying post-gres companies have gone intensively. Just after Microsoft bought Citus, another postgres company, credativ , bought OmniTI to strengthen its market presence. These are two well-known, solid companies. And Amazon bought OpenSCG . The postgres world is changing now, and I'll show you why there is so much interest in Postgres.
The acclaimed TimescaleDBit was also a separate database, but it is now an extension: you take Postgres and set timescaledb as an extension and get a database that breaks all kinds of specialized databases.
There is also Postgres XL, there are clusters that are developing.
Here in 2015, I set our fork: Postgres Pro . We have Postgres Pro Enterprise , there is a certified version, we support 1C out of the box and we are recognized by 1C . If anyone wants to try Postgres Pro Enterprise, then you can take the distribution kit for free, and if you need it for work, you can buy it.
We made Credereum- a prototype database with blockchain support. Now we are waiting for the people to mature in order to start using it.
See how big and interesting the picture is. I'm not even talking about Yahoo! Everest with column storage, with petabytes of data in Yahoo! - it was the 2008th year. They even sponsored our conference in Canada, came there, somewhere I even have a shirt from there :)
There is also PipelineDB. It also began as a closed source database, but now it is also just an extension. We see that Citus, TimescaleDB and PipelineDB are like separate databases, but at the same time they exist as extensions, that is, you take the standard Postgres and compile the extension. PipelineDB is a continuation of the idea of stream databases. Want to work with streams? Take Postgres, take PipelineDB and you can work.
In addition, there are extensions that allow you to work with the GPU . See the headline? I have shown that there is an ecosystem that spans a large number of different types of data and loads. Therefore, we say that Postgres is a universal database.
Favorite people base
The next slide has big names. All the most famous clouds in the world support Postgres. In Russia, Postgres is supported by large state-owned companies. They use it, and we serve them as our customers.
There are already many extensions and many applications, so Postgres is good as the database from which the project starts. I always say to startups: guys, you don’t need to take NoSQL database. I understand that you really want to, but start with Postgres. If you don’t have enough, you can always unhook a service and give it to a specialized database. In addition to universality, Postgres has one more advantage: a very liberal BSD license, which allows you to do anything with your database.
Everything that you see on this slide is accessible due to the fact that Postgres is an extensible database, and this extensibility is built right into the database architecture. When Michael Stonebreaker wrote about Postgres in his first article about him (it was written by him in 1984, here I quote an article from 1987), he already talked about extensibility as the most important component of database functionality. And this, as they say, has already been tested by time. You can add your own functions, your data types, operators, index accesses (that is, optimized access-methods), you can write your procedures in a very large number of languages. We have a Foreign Data Wrapper ( FDW ), that is, interfaces for working with different repositories, files, you can connect to Oracle , MySQLand other bases.
I want to give an example from my own personal experience. I worked with Postgres and when something was missing in Postgres, my colleagues and I simply added this functionality. We needed to work, for example, with the Russian language, and we made an 8-bit locale. It was a Rambler project . By the way, he was then in the top 5. Ramblerwas the first major global project to launch on Postgres. Arrays in Postgres were from the very beginning, but they were such that nothing could be done with them, it was just a text line in which the arrays were stored. We added operators, made indexes, and now arrays are an integral part of the Postgres functionality, and many of you use them without worrying about how fast they work - and that's fine. They used to say that arrays is no longer a traditional relational model, it does not satisfy the classical normal forms. Now people are already used to using arrays.
When we needed a full-text search, we did it. When we needed to store data of different nature, we made the hstore extension, and many people began to use it: it made it possible to build flexible database schemas so that it could be faster and faster. We made a GIN index to make full-text search work fast. We made trigrams ( pg_trgm ). Made NoSQL. And all this is in my memory, all of my own needs.
Extensibility makes Postgres a unique database, a universal database with which you can start working and not be afraid that you will be left without support. Look how many people here we have - this is already a market! Despite the fact that now hype - graph databases, document databases, time series and so on - look: most still use relational databases. They dominate, this is 75% of the database market, and the rest are exotic databases, a trifle compared to relational ones.
If you look at the ratio of open source to commercial databases, then, according
to DB-Engines, we will see that the number of open source databases is almost equal to the number of commercial databases. And we see that open source databases (blue line) are growing, and commercial (red) are falling. This is the direction of the development of the entire IT community, the direction of openness. Now, of course, it is indecent to refer to Gartner , but I’ll say it anyway: they predict that by 2022 70% will use open databases and up to 50% of existing systems will migrate to open source.
Look at this pomosomer: we see that Postgres is called the database of 2018. Last year, she was also the first independent expert estimate of DB-Engines. The ranking shows that Postgres is really ahead of the rest. It is in absolute terms in 4th place, but look how it grows. Sure, good. On the slide, this is a blue line. The rest - MySQL, Oracle, MS SQL - either balances at its level, or begins to bend.
Hacker news - you all probably read it or Y Combinator- polls are periodically conducted there, companies publish their vacancies there, and for some time they have been conducting statistics. You see that starting around 2014, Postgres is ahead of everyone. It was the 1st MySQL, but Postgres has slowly grown, and now among the entire hacker community (in the good sense of the word) it also prevails and grows further.
The Stack Overflow , too, each year conduct surveys. By most used, our Postgres is in a good, third place. By most loved - on the second. This is a favorite database. Redis is not a relational database, but relational Postgres is a favorite. I did not give here the most dreaded picture- the most terrible database, but you probably guess who comes first. "Base X," as they like to call it in Russia.
There is a review in Russia, a survey at all of us at the respected HighLoad ++ conference . It was not conducted by us, it was made by Oleg Bunin . It turned out: in Russia Postgres database No. 1.
We are asking HH.ru for the second time to share Postgres job statistics with us. 9 years ago Postgres was 10 times behind Oracle, everyone shouted: give us oracleists. And we see that last year we caught up, and then in 2018 there was growth. And if you are worried about where to find a job, then see: 2 thousand vacancies on HH.ru is Postgres. Do not worry, enough work.
In order to make it easier to see, I took a picture where I showed Postgres vacancies regarding Oracle vacancies. There were fewer ones, starting from 2018 they are already on par, and now Postgres has already become a little more. So far it is a little depressing that the absolute number of Oracle vacancies is also growing, which in principle should not be. But, as they say, we are sitting near the riverbank and watching: when will the enemy’s corpse float by. We are just doing our job.
Russian Postgres community
This is the most organized community in Russia, I have never met such people. A lot of resources, chats, where we all communicate on business. We hold conferences - two large conferences: in St. Petersburg and Moscow, apartment houses, we participate in all major international conferences, conduct courses.
In fact, these are community courses. They were prepared by our company, but they are freely available to any of you, look at our channel on youtube or go to the Education section on our website, there are DBA1 , DBA2 , DBA3 courses, and development courses for free download .
And now we are launching certification - this is what companies are asking for, they want to have certified specialists. And the employer will know: you are a certified specialist.
They often ask: how much Russian Postgres? The question is a little misplaced: Postgres is international. But I’ll say a little about the Russian flag. You see on the slide what Vadim Mikheev did . Those who know Postgres understand that MVCC , WAL , VACUUM and so on mean for this base . This is all the Russian contribution. Now there are three leading developers of Postgres, of which two are committers. On the slide you see that quite a lot has been done. If you look at major features from release notes, then you will see our contribution. The Russian contribution is substantial enough. We worked from the very beginning and continue to work with the community - already at the campaign level.
And the company's contribution is books. We have 2 Postgres university courses. You can go to the store and buy these books, you can teach at these courses, take exams and so on. We have books for beginners that are distributed, including here. Very useful good book. We even translated it into English.
Professional Postgres
Let's move on to the main one. Academic Postgres, when it started, was designed for several dozen users. The Postgres95 community had less than 400 people. The community consisted mainly of developers and few more users. At the same time - an interesting detail - the developers were mainly both customers and contractors. For example, when I needed it, I developed for myself and, at the same time, shared with everyone. That is, the community was developing for the community.
Starting from the year 2000, a little earlier, the first post-Grace companies began to appear: GreatBridge , 2ndQuadrant , EDB. They already hired full-time developers who worked for the community. The first enterprise forks and the first enterprise customisers appeared. This led to the fact that by 2015 the main number - and almost all the leading developers - were already organized in some companies. In 2015, our company was formed: we were the last free freelance developers. Now there are practically no such people. The postgres community has changed, it has become an enterprise, and now these companies are driving development. This is good because these companies carry out what the enterprise needs. The community is a brake in a good way: it tests features, condemns or accepts new features, it unites all of us. And Postgres became enterprise readyHe is used with pleasure by large companies, he has become a professional.
This slide is about the future, as I see it. With the advent of pluggable storage , new storages will appear: append-only , read-only , column storage - whatever you want (for example, I dream about parquet). There will be support for vector operations. Today, by the way, there will be a report about them. Blockchain will be supported. There is no getting away from this, since we are moving to the digital economy, to paperless technologies. You will need to use electronic signatures and you will need to be able to authenticate your database, make sure that no one has changed anything, and the blockchain is very suitable for this.
Next: Responsive Postgres. This is a little sad topic for you, but it is still quite far from you. The fact is that DBA, generally speaking, is an expensive resource, and soon databases will not need them. The bases will be smart enough and will configure and adjust themselves. But it will be in another ten years, probably. We still have a lot of time.
And it is clear that in Postgres there will be native support for clouds, cloud storage - without this, we simply can not survive. And, of course, here it is, the last slide:
EVERYTHING YOU NEED IS POSTGRES!
Thanks for attention.