Autocoding Blade Runner
- Transfer
Reconstruction of films using artificial neural networks
I bring to your attention a translation of the author’s description of the auto-encoder algorithm used to create the reconstruction of the film “Blade Runner”, about which I already wrote an article . It described the general story of the film and how Warner filed and then withdrew the lawsuit about copyright infringement . Here you will find a more detailed technical description of the algorithm and even its code.
In this blog I will describe the work that I did all last year - the reconstruction of films using artificial neural networks. First, their ability to reconstruct individual frames from films is trained, and then each frame in the film is reconstructed and the sequence of frames is created anew.
The type of neural network used is called an auto-encoder. Auto-encoder is a type of neural network with a very small size of the hidden layer. It encodes a chunk of data into a much shorter representation (in this case, a set of 200 numbers), and then reconstructs the data in the best possible way. The reconstruction is not perfect, but the project was for the most part a creative study of the possibilities and limitations of this approach.
The work was done as part of a dissertation at the Faculty of Creative Computing at the Goldsmith Institute.
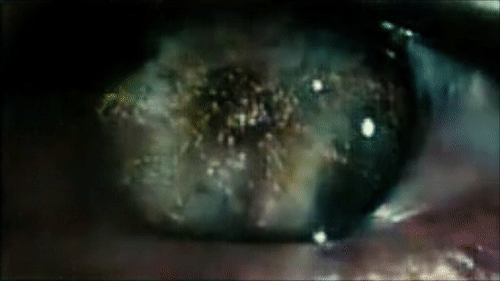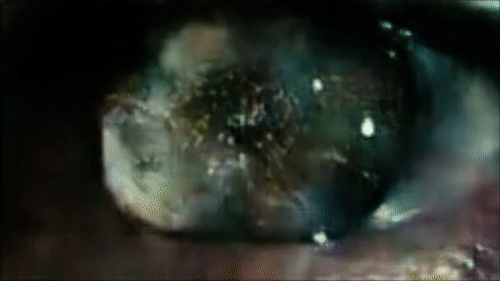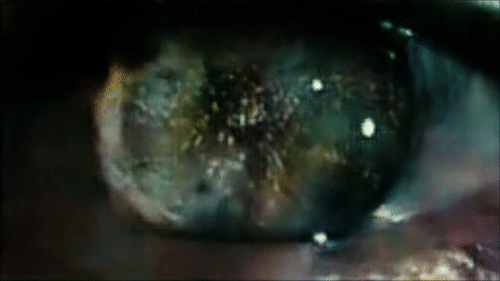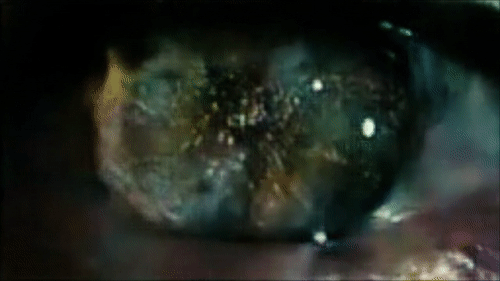
Reconstructing the eyes of Roy Batti looking at Los Angeles in the first scene
Comparison of the original Blade Runner trailer with reconstruction
The first 10 minutes of film reconstruction
Technical description
In the past 12 months, the interest and efforts of developers in using neural networks to generate text, pictures and sounds have risen sharply. In particular, in recent months, methods for generating pictures have advanced dramatically.

DCGAN bedroom images
In November 2015, Radford et al.they were extremely surprised by the community interested in this topic, using neural networks to create realistic images of bedrooms and faces, using the competitive method of training neural networks. The network creates random examples, and the comparing network (discriminator) tries to distinguish the generated pictures from real images. Over time, the generator begins to produce increasingly realistic images that the discriminator is no longer able to distinguish. The adversarial method was first proposed by Goodfellowet al. in 2013, but before Radford’s work, it was not possible to create realistic images using neural networks. An important breakthrough that made this possible was the use of a convolutional autoencoder to create images. Prior to this, it was assumed that such neural networks could not effectively create images, since the use of accumulating layers leads to the loss of information between layers. Radford brushed off the use of cumulative layers and simply used strided backwards convolutions. (For those unfamiliar with the concept of "convolutional auto-encoder" I prepared a visualization ).

I studied creating models before the work of Redford, but after its publication it became obvious that this was the right approach. However, creating competitive networks do not know how to reconstruct pictures, but only create examples from random noise. Therefore, I began to study the possibilities of training a variational auto - encoder - which can recover images - with a discriminatory network used for a competitive approach, or even with a network that assesses the similarity between the reconstructed image and the real example. But I didn’t even have time to do this, and Larsen et al.already published in 2015, a work combining both of these approaches in a very elegant way - comparing the difference in responses to real and reconstructed images in the upper layers of the discriminatory network. They were able to produce a learned similarity metric, a radically superior pixel-by-pixel comparison of recovery errors (otherwise, the procedure will lead to blurry reconstruction - see the picture above).
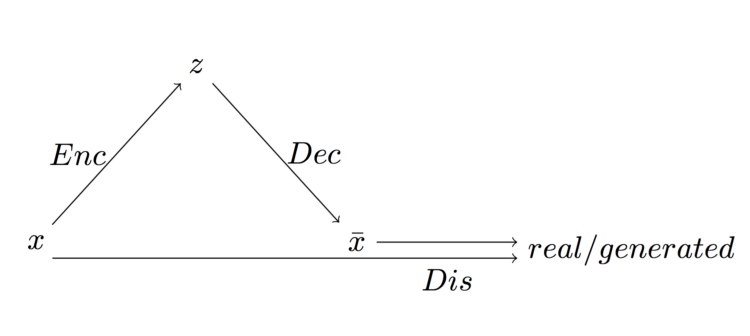
General scheme of a variational autocoder combined with a discriminating network
Larsen’s model consists of three separate networks — an encoder, a decoder, and a discriminator. The encoder encodes the data set x into a hidden representation z. The decoder is trying to recreate a dataset from a hidden view. The discriminator has both original and reconstructed sets, and determines whether they are real or fake. The response to them in the upper layers of the network is compared to determine how close the reconstruction has come to the original.
I made this model based on the TensorFlow library , intending to expand it with LSTMto create video predictions. Due to time constraints, I could not do this. But that led me to create a model for generating large non-square images. Previous models described 64x64 resolution images, with 64 images for batch processing. I expanded the network to pictures with a resolution of 256x144 with packets of 12 pictures each (my NVIDIA GTX 960 GPU simply could not cope with a lot). The hidden view had 200 variables, which means that the model encoded a 256x144 picture with three color channels (110,592 variables) into a view of 200 numbers before reconstructing the image. The network trained on a set of data from all Blade Runner frames, cropped and scaled to 256x144. The network trained in 6 eras, which took me 2 weeks.
Artistic motivation
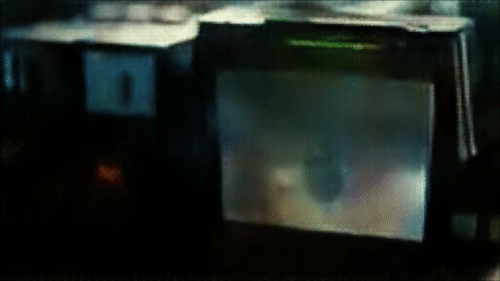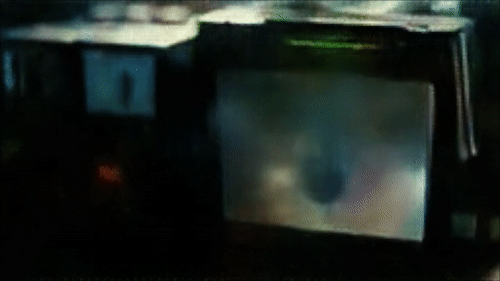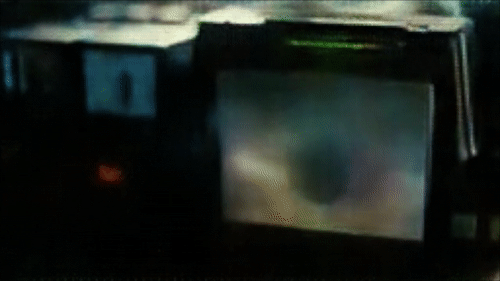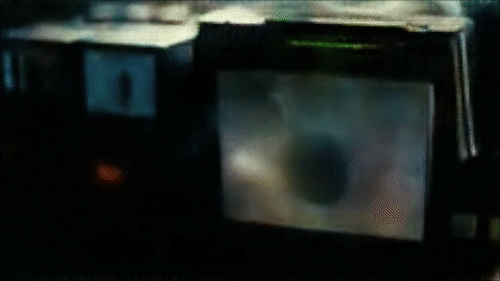
Reconstruction of the second Voight-Kampf test
The 1982 film “Blade Runner” by Ridley Scott is an adaptation of the classic science fiction work “Do Androids Dream of Electric Sheep?” By Philip Dick (1968). In the film, Rick Deckard (Harrison Ford) is a bounty hunter who makes money by hunting and killing replicants - androids that are so well made that they can not be distinguished from people. Deckard needs Voight-Kampf tests to distinguish between androids and people, asking increasingly complex questions from the field of morality and studying pupils of experimental subjects, with the intention of provoking an empathic reaction in people, but not in androids.
One of the main questions of history is the task of determining what is human and what is not, it becomes more and more complex as the complexity of technological developments increases. The new Nexus-6 androids created by Tyrell Corporation over time generate emotional reactions, and Rachel’s new prototype contains memory implants, because of which she considers herself a human being. The method of separating people from non-people is undoubtedly borrowed from the methodological skepticism of the great French philosopher Rene Descartes. Even the name Deckard is very similar to Descartes . Over the course of the film, Deckard tries to determine who is the person and who is not, while the assumption remains that Deckard himself doubts whether he is a person.
I will not delve into the philosophical problems discussed in the film ( there are two good articles on this subject ), I will only say the following. The success of deep learning systems is manifested in the fact that systems are becoming more involved in their environment . At the same time, a virtual system that recognizes images but is not involved in the environment represented by these images is a model whose characteristics are similar to Cartesian dualism, in which the body and spirit are separated.
A neural network is a relatively simple mathematical model (if compared with the brain), and excessive anthropomorphization of these systems can lead to problems. Despite this, advances in deep learning mean that the subject of inclusion of models in their environment and their relationship with theories about the nature of the mind should be considered in the context of technical, philosophical and artistic consequences.



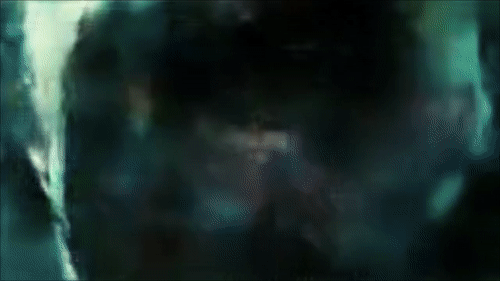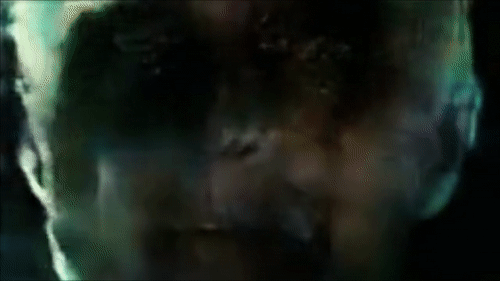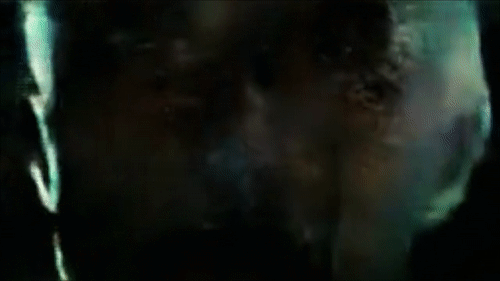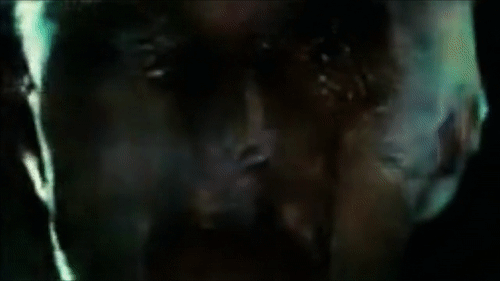
Reconstruction of Blade Runner
The reconstructed film turned out to be unexpectedly connected. This is not an ideal reconstruction, but given that the model was designed to emulate a set of images of one entity from the same perspective, it does a good job, given how much the individual frames vary.
Static and high-contrast scenes that change little over time are very well reconstructed. This is because, in fact, the model “saw” the same frame much more often than just 6 training eras. This can be seen as an excess of data, but since the training data set is intentionally distorted, there is no need to worry about this.
The model has a predisposition to compress many similar frames with minimal differences into one (when, for example, the actor speaks in a static scene). Since the model represents separate images, it is not clear that there are small deviations from frame to frame, and that they are quite important.
Also, the models hardly manage to make a distinguishable reconstruction of scenes with low contrast, especially with the presence of faces. She also hardly reconstructs faces when there are a lot of changes - with movement or rotation of the head. This is not surprising given the limitations of the model and the sensitivity of people to face recognition. Recently, there have been successes in development by combining creating models and networks with a change in spatial transformer networks that can help with these issues, but describing them is beyond the scope of this article.

Reconstruction of scenes of the film “Koyaaniskatsi” using a network trained on “Blade Runner”
Reconstruction of other films
An example of the reconstruction of the film “Koyaaniskatsi” using a network trained on “Blade Runner”
In addition to the reconstruction of the film on which the network trained, you can make it reconstruct any video. I experimented with different films, but it worked best with one of my favorites - Koyaaniskatsi (1982). It consists mainly of scenes with time dilation and acceleration, and the scenes are very different, which makes it an ideal candidate for testing the performance of the Blade Runner model.
It is not surprising that the model recreates the film on which she trained much better, in comparison with the video, which she never “saw”. You can improve the results by training the network on a large number of heterogeneous video material, for example, hundreds of hours of random videos. But the model will lose in the aesthetic quality that stems from the only finished film. And although most often individual frames by themselves are difficult to make out, in the movement of the image they become more connected and at the same time quite unpredictable.
Reconstruction of Apple's 1984 advertising using Blade Runner-trained network
Reconstruction of John Whitney's Matrix III using a network trained on Blade Runner
In addition to Koyaaniskatsi, I tested the network for the reconstruction of two more films. This is the famous 1984 Apple Macintosh ad made by Ridley Scott. Steve Jobs hired him when he watched Blade Runner in a movie. Advertising has a lot in common with Blade Runner in a visual sense, so the choice of this video was justified.
Another film is John Whitney's "Matrix III" animation. He was a pioneer in computer animation and IBM's first full-time artist from 1966 to 1969. Matrix III (1972) was one of a series of films that demonstrated the principles of harmonic progression. He was chosen to test how the model handles the reconstruction of abstract, unnatural images.



Autocoding "Turbidity"
After Blade Runner, I wanted to see how the model behaves if you train it on another movie. I chose the 2006 film, “Clouding” [A Scanner Darkly]. This is another adaptation of Philip Dick's novel, and stylistically it is very different from Blade Runner. “Turbidity” was shot using the rotoscoping method - it was shot on camera, and then each frame was drawn by the artist.
The model caught the film style well enough (although not as well as in the work of transferring the art style ), but it was even more difficult for her to reconstruct her faces. Apparently, this is due to the fact that the film has contrasting contours and there are difficulties with recognizing facial features, as well as there are unnatural and amplified changes in chiaroscuro from frame to frame.
Blade Runner trailer remodeled using Blurred Network
Fragment “Koyaaniskatsi” reconstructed using a network trained on “Blurred”
Again, the reconstruction of some films by models trained on others is practically not recognizable. The results are not as coherent as those with the Blade Runner model, possibly due to the much larger number of colors in Blur, and the fact that modeling natural images for this model is more complicated. On the other hand, the images are unusual and complex, which leads to the appearance of an unpredictable video sequence.
Conclusion
Honestly, I was very surprised at how the model behaved when I started training her on Blade Runner. The reconstruction of the film came out better than I could have imagined, and I am surprised at what happened during the reconstruction of other films. I will definitely do more experimentation with training on more films to see the result. I would like to adapt the training procedure so that it takes into account the sequence of frames, so that the network better distinguishes between long sequences of similar frames.
Project code is available on GitHub . Details are also on my website .