How Netflix Evacuates AWS in Seven Minutes
- Transfer
Netflix reduces failover time from 45 to 7 minutes at no cost

Image: Florida Memory . Modified by Opensource.com. CC BY-SA 4.0
In the winter of 2012, Netflix experienced a long failure , turning off for seven hours due to problems with the AWS Elastic Load Balancer service in the US-East region (Netflix runs on AWS - we do not have our own data centers. Everything is yours interaction with Netflix takes place via AWS, except for streaming video itself. As soon as you click Play , the video stream from our own CDN network starts to load). During the crash, not a single package from the US-East region reached our servers.
To prevent this from happening again, we decided to create a failover system that is resistant to failures of the basic service providers. Failover is a fail-safe system where redundant equipment is automatically activated in the event of a main system failure.
Change of region reduces risk
We expanded to three AWS regions: two in the USA (US-East and US-West) and one in the European Union (EU). Have reserved enough resources to switch if one region fails.
A typical failover is as follows:
- Understand that one of the regions is experiencing problems.
- Scale two rescue regions.
- Proxy traffic to rescuers from a problem region.
- Change DNS from problem region to rescuers.
We will study every step.
1. Identify a problem
We need metrics, but rather one metric that talks about the health of the system. Netflix uses the business metric “stream starts per second” (abbreviated SPS). This is the number of clients who successfully started streaming.
Data is segmented by region. At any time, you can build an SPS chart for each region - and compare the current value with the value for the last day or week. When we notice a drop in SPS, we know that clients are not able to start streaming - therefore, we have a problem.
The problem is not necessarily related to the cloud infrastructure. This may be bad code in one of the hundreds of microservices that make up the Netflix ecosystem, a broken submarine cable, etc. We may not know the reason: we just know something is wrong.
If SPS dropped only in one region, then this is a great candidate for failover. If in several regions, then no luck, because we can evacuate only one region at a time. That is why we deploy microservices in the regions in turn. If you have a deployment problem, you can immediately evacuate and fix the problem later. In exactly the same way, we want to avoid a failure if the problem persists after traffic is redirected (as happens in the case of a DDoS attack).
2. Scale Rescuers
After we have identified the affected region, we need to prepare other regions (“rescuers”) to transfer traffic. Prior to the evacuation, it is necessary to scale the infrastructure in the rescue regions accordingly.
What does scaling mean in this context? Netflix traffic pattern changes throughout the day. There are peak hours, usually around 6-9 p.m., but in different parts of the world this time comes at different times. Traffic peaks in the US-East region three hours earlier than in the US-West region, which is eight hours behind the EU region.
In the event of a US-East emergency shutdown, we direct traffic from the East Coast to the EU region, and traffic from South America to US-West. This is necessary to reduce the delay and the best quality of service.
Taking this into account, you can use linear regression to predict traffic that will be sent to the rescue regions at this time of day (and day of the week) using the historical scaling data of each microservice.
After we have determined the appropriate size for each microservice, we start scaling for them, set the desired size of each cluster - and let AWS do its magic.
3. Proxies for traffic
Now that the microservice clusters are scaled, we begin to proxy traffic from the affected region to the rescue regions. Netflix has developed a high-performance inter-regional border proxy server called Zuul, which we have posted open source .
These proxies are designed to authenticate requests, load shedding, retry failed requests, etc. The Zuul proxy server can also perform proxying between regions. We use this function to redirect traffic from the affected region, and then gradually increase the amount of redirected traffic until it reaches 100%.
Such progressive proxying allows services to use their scaling rules to respond to incoming traffic. This is necessary to compensate for any traffic change between the moment when the scaling forecast is made and the time needed to scale each cluster.
Zuul does the hard work by redirecting incoming traffic from the victim to healthy regions. But there comes a time when you need to completely abandon the use of the affected region. This is where DNS comes into play.
4. DNS change
The final step in emergency evacuation is updating the DNS records pointing to the affected region and redirecting them to the working regions. This will completely transfer traffic there. Clients who do not update the DNS cache will continue to be redirected by Zuul in the affected region.
This is a general description of the process of how to evacuate Netflix from the region. The process used to take a lot of time - about 45 minutes (if you're lucky).
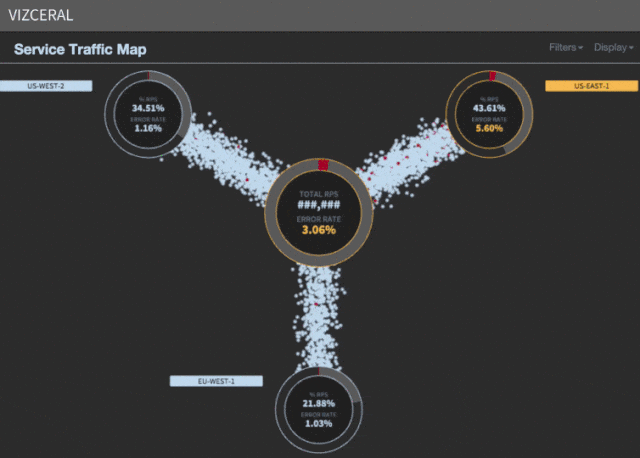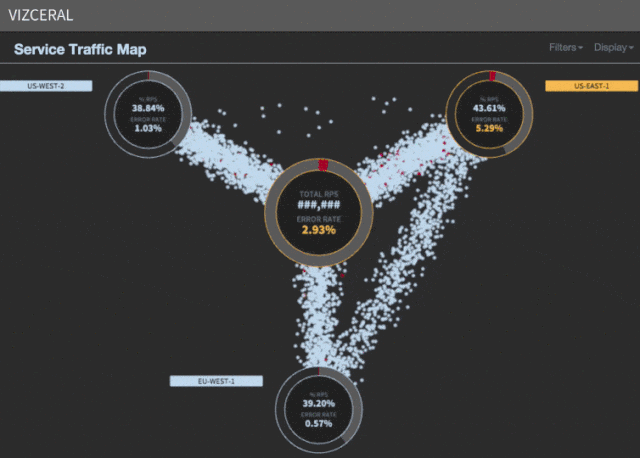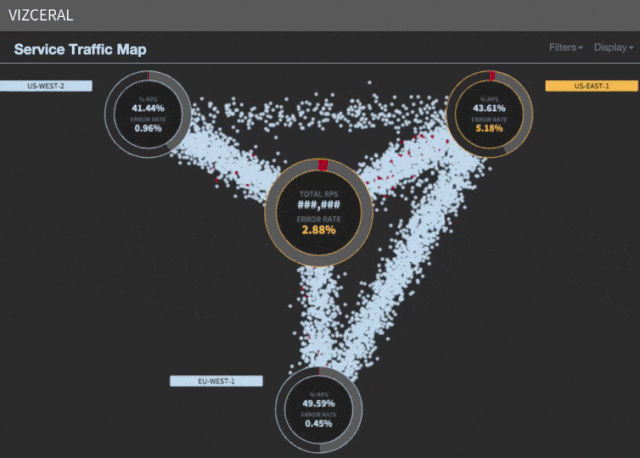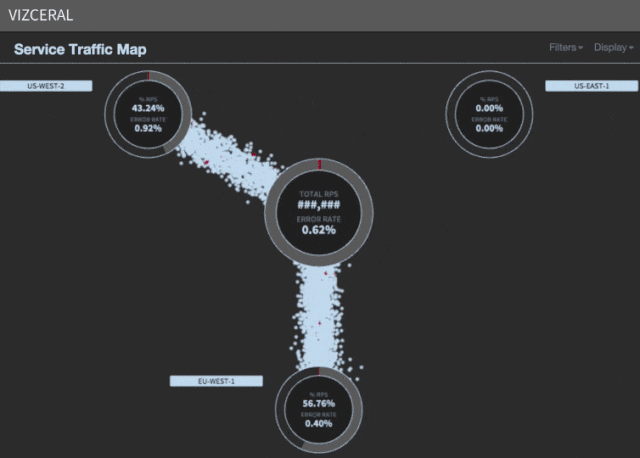
Speed up evacuation
We noticed that most of the time (about 35 minutes) is spent waiting for the rescue regions to scale. Although AWS can provide new instances within minutes, the scaling process takes the lion's share of the time to launch services, warm up, and process other necessary tasks before UP is registered in discovery .
We decided it was too long. I wish that the evacuation took less than ten minutes. And I would like to optimize the process without additional operating load. It is also undesirable to increase financial costs.
We reserve capacity in all three regions in case of failure of one. If we already pay for these capacities, why not use them? So started Project Nimble (project "Shustrik").
The idea was to maintain a hot pool of instance pool for each microservice. When we are ready for migration, we simply implement a “hot” reserve in the clusters to accept the current traffic.
An unused reserved capacity is called a trough. Some Netflix development teams sometimes use part of the “feeder” for their batch jobs, so we just can’t take it all to a hot reserve. But it is possible to maintain a shadow cluster for each microservice, so that there are enough instances for evacuating traffic at each time of the day, if such a need arises. The remaining instances are available for batch jobs.
During evacuation, instead of traditional AWS scaling, we deploy instances from the shadow cluster to the working cluster. The process takes about four minutes, unlike the previous 35.
Since such an injection is quick, there is no need to carefully move it with a proxy so that the scaling rules can respond. We can simply switch the DNS - and open the gateways, thereby saving a few more precious minutes during downtime.
We added filters to the shadow cluster so that these instances do not fall into the metric reports. Otherwise, they will pollute the metrics and bring down normal working behavior.
We also removed UP registration for instances from shadow clusters by changing our discovery client. Instances will remain in the shade until evacuation begins.
Now we perform a failover of the region in just seven minutes. Since existing reserved capacities are used, we do not bear any additional infrastructure costs. The failover software is written in Python by a team of three engineers.