Introducing reactive streams - for Java developers
- Transfer
Hello, Habr!
Today we will return to one of the topics covered in our wonderful book " Reactive Design Patterns ." We will talk about Akka Streams and streaming data in general - in the book of Roland Kuhn, chapters 10 and 15-17 are devoted to these issues.
Jet streams are a standard way to stream data asynchronously. They were included in Java 9 as interfaces.
Context
A typical stream processing pipeline consists of several steps, at each of which information is transmitted to the next step (i.e., in descending order). So, if you take two adjacent steps and consider the parent as the supplier, and the next one as the data consumer, it turns out that the supplier can work either slower than the consumer or faster than him. When the supplier works more slowly, everything is fine, but the situation is complicated if the consumer does not keep pace with the supplier. In this case, the consumer can overflow with data that he has to (to the best of his ability) to carefully process.
The easiest way to deal with excess data is to take and discard everything that cannot be processed. This is exactly what they do, for example, when working with network equipment. But what if we don't want to drop anything at all? Then backpressure will come in handy.
The idea of back pressure is very important in the context of Reactive Streams and it comes down to the fact that we limit the amount of data transferred between adjacent links of the conveyor, so no link is overflowed. Since the most important aspect of the reactive approach is to prevent blocking unless absolutely necessary, the implementation of the back pressure in the reactive stream must also be non-blocking.
How it's done
The Reactive Streams standard defines a number of interfaces, but not an implementation as such. This means that by simply adding a dependency to org.reactivestreams: reactive-streams, we just stomp on the spot - we still need a specific implementation. There are many implementations of Reactive Streams, and in this article we will use Akka Streams and the corresponding Java-based DSL . Other implementations include RxJava 2.x or Reactor and others.
Example usage
Suppose we have a directory in which we want to track new CSV files, then process each file on a streaming basis, perform some aggregation on the fly, and send the results thus collected to a web socket (in real time). In addition, we want to set a certain threshold for the accumulation of aggregated data, upon reaching which an email notification will be triggered.
In our example, the CSV lines will contain pairs (
We want to calculate the average value for two lines with a common id and send it to the web socket only if it exceeds 0.9. Moreover, we want to send an e-mail notification after every fifth value arriving on a web socket. Finally, we want to read and display data received from the web socket, and this will be done through a trivial frontend written in JavaScript.
Architecture
We are going to use a number of tools from the Akka ecosystem (see Figure 1). Naturally, Akka Streams will be at the center of the entire system, which allows you to process data in real time on a streaming basis. For reading CSV files we will use Alpakka, is a set of connectors for integrating Akka Streams with various technologies, protocols, or libraries. It is interesting that, since Akka Streams are jet streams, the entire Alpakka ecosystem is also available for any other RS implementation - it is RS interfaces that are designed to achieve such interoperability gains. Finally, we will use Akka HTTP, which will provide the endpoint of the web socket. The best part in this case is that Akka HTTP seamlessly integrates with Akka Streams (which, in fact, it uses "under the hood"), so providing a stream as a web socket is not difficult.
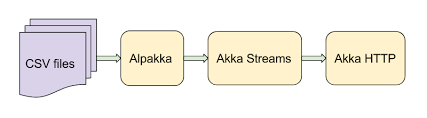
Fig. 1. Architecture Overview
If you compare this scheme with the classic Java EE architecture, it is probably noticeable that everything is much simpler here. No containers and beans, but just a simple standalone application. Moreover, the Java EE stack does not support the streaming approach at all.
Akka Streams Basics
In Akka Streams, the processing pipeline (graph) consists of three types of elements
Based on these components, we define our graph, which, in essence, is just a recipe for data processing. No calculations are made there. In order for the pipeline to work, we need to materialize the graph, that is, bring it into a runable form. To do this, you will need the so-called materializer, which optimizes the definition of the graph and, ultimately, runs it. However, the built-in ActorMaterializer is virtually uncontested, so you are unlikely to use any other implementation.
If you look closely at the parameters of the types of components, it is noticeable that each component (except the corresponding types of input / output) has a mysterious type Mat. It refers to the so-called “materialized value” - this is the value accessible from outside the graph (as opposed to the types of input / output available only for internal communication between the steps of the graph - see Fig. 2). If you prefer to ignore materialized value (as is often the case, if we are interested in only the data transmission between the count steps), then to refer to such an option is a special type parameter:
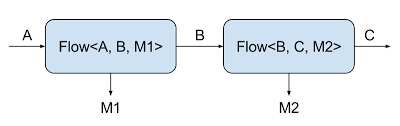
Fig. 2. Description of flow type parameters.
Application
Now let's move on to a specific implementation of the CSV handler. First, let's define the Akka Streams graph, and then, using the Akka HTTP protocol, we connect the stream to the web socket.
Components of a stream pipeline
At the input point of our stream pipeline, we want to monitor whether new CSV files have appeared in the directory of interest to us. I would like to use for this
So we get a source that gives us type elements . We are going to filter them so that we select only new CSV files and then transfer them “down”. For this data conversion, as well as for all subsequent ones, we will use small elements called Flow, which will then form a full-fledged processing pipeline:
You can create
Now we are going to convert the Paths into strings, selected by stream from each file. To turn a source into another source, you can use one of the methods
This time we will use the method
Shown above
Pay attention to the combinator used here
To convert as such, we use the method
At the next stage, we must add the readings in pairs, calculate the average value for each group
Having defined the above components, we are ready to add an integral conveyor out of them (using the combinator you already know
Note
When combining components as shown above, the compiler protects us by not accidentally connecting two blocks containing incompatible data types.
Stream as a web socket
Now we will use Akka HTTP to create a simple web server that will play such roles:
It costs nothing to create a web server using Akka HTTP: you just need to inherit
Two routes are defined here:
To start the server, you just need to run the method
Frontend
To receive data from a web socket and display it, we use a completely simple JavaScript code that simply attaches the received values to textarea. This code uses ES6 syntax, which should work fine in any modern browser.
The method
Launching
To launch and test the application, you need:
Adding a mail trigger
The final touch in our application is a side channel in which we will simulate mail notifications sent after every fifth element arrives on the web socket. It should work "sideways" so as not to disrupt the transmission of basic elements.
To implement this behavior, we will use the more advanced feature of Akka Streams - the Graph DSL language - in which we will write our own graph step, in which the stream branches into two parts. The first simply submits the values to the web socket, and the second monitors when the next 5 seconds expire, and sends a notification by e-mail - see fig. 3.
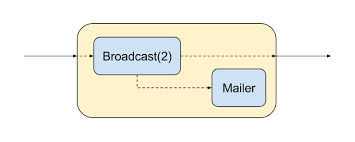
Fig. 3. Our own graph step for sending emails
We will use the built-in step
We begin to create our own graph step with the method
Next, we define our own trap, where it is used
Having defined our own trap, we can use an instance
Next, you need to specify the connection between the graph elements - one of the outputs of the step
Note 1:
The compiler cannot determine if all parts of the graph are connected correctly. However, this point is checked by the materializer at run time, so there will be no hanging elements at the input or output.
Note 2
In this case, you can notice that all the steps we wrote are of the form Graph, where S is the form defining the number and types of inputs and outputs, and M is the materialized value (if any). Here we are dealing with the Flow form, that is, we have one input and one output.
At the last stage, we connect the notifier as an additional step in the pipeline
Running the updated code, you will see how the messages about email notifications appear in the log. A notification is sent whenever another five values manage to pass through the web socket.
Summary
In this article we studied the general concepts of streaming data processing, learned how to use Akka Streams to build a lightweight data processing pipeline. This is an alternative to the traditional approach used in Java EE.
We looked at how to use some processing steps built into Akka Streams, how to write our own step in Graph DSL. It was also shown how to use Alpakka to stream data from the file system and the Akka HTTP protocol, which allows you to create a simple web server with a web socket on the endpoint, seamlessly integrated with Akka Streams.
A full working example with the code in this article is on GitHub . It has several additional
Today we will return to one of the topics covered in our wonderful book " Reactive Design Patterns ." We will talk about Akka Streams and streaming data in general - in the book of Roland Kuhn, chapters 10 and 15-17 are devoted to these issues.
Jet streams are a standard way to stream data asynchronously. They were included in Java 9 as interfaces.
java.util.concurrent.Flow, and now they are becoming a real lifesaver for creating streaming components in various applications - and this arrangement will continue over the coming years. It should be noted that reactive flows are a “simple” standard, and by themselves are worthless. In practice, one or another specific implementation of this standard is used, and today we will talk about Akka Streams - one of the leading implementations of jet streams since their inception. Context
A typical stream processing pipeline consists of several steps, at each of which information is transmitted to the next step (i.e., in descending order). So, if you take two adjacent steps and consider the parent as the supplier, and the next one as the data consumer, it turns out that the supplier can work either slower than the consumer or faster than him. When the supplier works more slowly, everything is fine, but the situation is complicated if the consumer does not keep pace with the supplier. In this case, the consumer can overflow with data that he has to (to the best of his ability) to carefully process.
The easiest way to deal with excess data is to take and discard everything that cannot be processed. This is exactly what they do, for example, when working with network equipment. But what if we don't want to drop anything at all? Then backpressure will come in handy.
The idea of back pressure is very important in the context of Reactive Streams and it comes down to the fact that we limit the amount of data transferred between adjacent links of the conveyor, so no link is overflowed. Since the most important aspect of the reactive approach is to prevent blocking unless absolutely necessary, the implementation of the back pressure in the reactive stream must also be non-blocking.
How it's done
The Reactive Streams standard defines a number of interfaces, but not an implementation as such. This means that by simply adding a dependency to org.reactivestreams: reactive-streams, we just stomp on the spot - we still need a specific implementation. There are many implementations of Reactive Streams, and in this article we will use Akka Streams and the corresponding Java-based DSL . Other implementations include RxJava 2.x or Reactor and others.
Example usage
Suppose we have a directory in which we want to track new CSV files, then process each file on a streaming basis, perform some aggregation on the fly, and send the results thus collected to a web socket (in real time). In addition, we want to set a certain threshold for the accumulation of aggregated data, upon reaching which an email notification will be triggered.
In our example, the CSV lines will contain pairs (
id, value), and, idwill be changed every two lines, for example:370582,0.17870700247256666
370582,0.5262255382633264
441876,0.30998025265909457
441876,0.3141591265785087
722246,0.7334219632071504
722246,0.5310146239777006We want to calculate the average value for two lines with a common id and send it to the web socket only if it exceeds 0.9. Moreover, we want to send an e-mail notification after every fifth value arriving on a web socket. Finally, we want to read and display data received from the web socket, and this will be done through a trivial frontend written in JavaScript.
Architecture
We are going to use a number of tools from the Akka ecosystem (see Figure 1). Naturally, Akka Streams will be at the center of the entire system, which allows you to process data in real time on a streaming basis. For reading CSV files we will use Alpakka, is a set of connectors for integrating Akka Streams with various technologies, protocols, or libraries. It is interesting that, since Akka Streams are jet streams, the entire Alpakka ecosystem is also available for any other RS implementation - it is RS interfaces that are designed to achieve such interoperability gains. Finally, we will use Akka HTTP, which will provide the endpoint of the web socket. The best part in this case is that Akka HTTP seamlessly integrates with Akka Streams (which, in fact, it uses "under the hood"), so providing a stream as a web socket is not difficult.
Fig. 1. Architecture Overview
If you compare this scheme with the classic Java EE architecture, it is probably noticeable that everything is much simpler here. No containers and beans, but just a simple standalone application. Moreover, the Java EE stack does not support the streaming approach at all.
Akka Streams Basics
In Akka Streams, the processing pipeline (graph) consists of three types of elements
Source(source), Sink(trap) and Flows (processing steps).Based on these components, we define our graph, which, in essence, is just a recipe for data processing. No calculations are made there. In order for the pipeline to work, we need to materialize the graph, that is, bring it into a runable form. To do this, you will need the so-called materializer, which optimizes the definition of the graph and, ultimately, runs it. However, the built-in ActorMaterializer is virtually uncontested, so you are unlikely to use any other implementation.
If you look closely at the parameters of the types of components, it is noticeable that each component (except the corresponding types of input / output) has a mysterious type Mat. It refers to the so-called “materialized value” - this is the value accessible from outside the graph (as opposed to the types of input / output available only for internal communication between the steps of the graph - see Fig. 2). If you prefer to ignore materialized value (as is often the case, if we are interested in only the data transmission between the count steps), then to refer to such an option is a special type parameter:
NotUsed. It can be compared with Voidfrom Java, however, it is slightly more semantically loaded: in the sense of “we do not use this value” is more informativeVoid. I also note that some APIs use a similar type of Done, signaling that a particular task is completed. Perhaps, other Java libraries in both of these cases would be used Void, but in Akka Streams all types try to fill the maximum with useful semantics. Fig. 2. Description of flow type parameters.
Application
Now let's move on to a specific implementation of the CSV handler. First, let's define the Akka Streams graph, and then, using the Akka HTTP protocol, we connect the stream to the web socket.
Components of a stream pipeline
At the input point of our stream pipeline, we want to monitor whether new CSV files have appeared in the directory of interest to us. I would like to use for this
java.nio.file.WatchService, but since we have a streaming application, we need to get the event source ( Source) and work with it, and not organize everything through callbacks. Fortunately, such a Source is already available in Alpakka in the form of one of the connectors DirectoryChangesSource, it is part of alpakka-filewhere “under the hood” is used WatchService:private final Source, NotUsed> newFiles =
DirectoryChangesSource.create(DATA_DIR, DATA_DIR_POLL_INTERVAL, 128); So we get a source that gives us type elements . We are going to filter them so that we select only new CSV files and then transfer them “down”. For this data conversion, as well as for all subsequent ones, we will use small elements called Flow, which will then form a full-fledged processing pipeline:
Pairprivate final Flow, Path, NotUsed> csvPaths =
Flow.>create()
.filter(this::isCsvFileCreationEvent)
.map(Pair::first);
private boolean isCsvFileCreationEvent(Pair p) {
return p.first().toString().endsWith(".csv") && p.second().equals(DirectoryChange.Creation);
} You can create
Flow, for example, using the generalized method create()- it is useful when the input type itself is generalized. Here, the resulting stream will spawn (in the form Path) every new CSV file that appears in DATA_DIR. Now we are going to convert the Paths into strings, selected by stream from each file. To turn a source into another source, you can use one of the methods
flatMap*. In both cases, we create Sourcefrom each input element and somehow combine several of the resulting sources into a new, solid, linking or merging source sources. In this case, we will focus on flatMapConcat, because we want to preserve the order of the lines, so that the lines with the same idremain next to each other. To convertPathinto the byte stream, use the built-in utility FileIO:private final Flow fileBytes =
Flow.of(Path.class).flatMapConcat(FileIO::fromPath); This time we will use the method
of()to create a new stream - it is convenient when the input type is not generalized. Shown above
ByteStringis a byte sequence representation adopted by Akka Streams. In this case, we want to parse the byte stream as a CSV file - and for this we will again use one of the Alpakka modules, this time alpakka-csv:private final Flow, NotUsed> csvFields =
Flow.of(ByteString.class).via(CsvParsing.lineScanner()); Pay attention to the combinator used here
via, which allows you to attach an arbitrary Flowto the output obtained at another step of the graph ( Sourceor another Flow). The result is a stream of elements, each of which corresponds to a field in a single line in a CSV file. Then they can be transformed into a model of our subject area:class Reading {
private final int id;
private final double value;
private Reading(int id, double value) {
this.id = id;
this.value = value;
}
double getValue() {
return value;
}
@Override
public String toString() {
return String.format("Reading(%d, %f)", id, value);
}
static Reading create(Collection fields) {
List fieldList = fields.stream().map(ByteString::utf8String).collect(toList());
int id = Integer.parseInt(fieldList.get(0));
double value = Double.parseDouble(fieldList.get(1));
return new Reading(id, value);
}
} To convert as such, we use the method
mapand pass the link to the method Reading.create:private final Flow, Reading, NotUsed> readings =
Flow.>create().map(Reading::create);
At the next stage, we must add the readings in pairs, calculate the average value for each group
valueand transmit information only when a certain threshold is reached. Since we need the average to be calculated asynchronously, we will use a method mapAsyncUnorderedthat performs an asynchronous operation with a given level of parallelism:private final Flow averageReadings =
Flow.of(Reading.class)
.grouped(2)
.mapAsyncUnordered(10, readings ->
CompletableFuture.supplyAsync(() ->
readings.stream()
.map(Reading::getValue)
.collect(averagingDouble(v -> v)))
)
.filter(v -> v > AVERAGE_THRESHOLD); Having defined the above components, we are ready to add an integral conveyor out of them (using the combinator you already know
via). It is not at all complicated:private final Source liveReadings =
newFiles
.via(csvPaths)
.via(fileBytes)
.via(csvFields)
.via(readings)
.via(averageReadings); Note
When combining components as shown above, the compiler protects us by not accidentally connecting two blocks containing incompatible data types.
Stream as a web socket
Now we will use Akka HTTP to create a simple web server that will play such roles:
- Provide a reading source as a web socket,
- Issue a trivial web page that connects to the web socket and displays the received data.
It costs nothing to create a web server using Akka HTTP: you just need to inherit
HttpAppand provide the required mappings via the DSL route:class Server extends HttpApp {
private final Source readings;
Server(Source readings) {
this.readings = readings;
}
@Override
protected Route routes() {
return route(
path("data", () -> {
Source messages = readings.map(String::valueOf).map(TextMessage::create);
return handleWebSocketMessages(Flow.fromSinkAndSourceCoupled(Sink.ignore(), messages));
}
),
get(() ->
pathSingleSlash(() ->
getFromResource("index.html")
)
)
);
}
} Two routes are defined here:
/datathat is, the end point of the web socket, and /along which a trivial frontend is issued. It’s already clear how simple it is to provide Sourcea web socket from Akka Streams as an endpoint: we take the handleWebSocketMessagestask of which is to improve the HTTP connection to connect to the web socket and organize a stream there in which incoming and outgoing data will be processed. WebSocketIt is modeled as a stream, that is, outgoing and incoming messages are sent to the client. In this case, we want to ignore the incoming data and create a stream whose "incoming" side is wound up in Sink.ignore(). The upstream side of the web socket handler stream is simply connected to our source from which the averages come. All you have to do with numbersdouble, in the form of which the averages are presented - to convert each of them into TextMessage, this is a wrapper used in Akka HTTP for web socket data. Everything is elementarily done using a method already familiar to us map. To start the server, you just need to run the method
startServer, specifying the host name and port:Server server = new Server(csvProcessor.liveReadings);
server.startServer(config.getString("server.host"), config.getInt("server.port"));Frontend
To receive data from a web socket and display it, we use a completely simple JavaScript code that simply attaches the received values to textarea. This code uses ES6 syntax, which should work fine in any modern browser.
let ws = new WebSocket("ws://localhost:8080/data");
ws.onopen = () => log("WS connection opened");
ws.onclose = event => log("WS connection closed with code: " + event.code);
ws.onmessage = event => log("WS received: " + event.data);The method
logattaches the message to textarea, and also puts a time stamp. Launching
To launch and test the application, you need:
- start server (
sbt run), - go to localhost : 8080 in the browser (or to the host / port of your choice if you changed the default),
- copy one or more files from
src/main/resources/sample-datato the directorydatain the root of the project (if you have not changedcsv-processor.data-dirin the configuration), - watch how the data is displayed in the server logs and in the browser.
Adding a mail trigger
The final touch in our application is a side channel in which we will simulate mail notifications sent after every fifth element arrives on the web socket. It should work "sideways" so as not to disrupt the transmission of basic elements.
To implement this behavior, we will use the more advanced feature of Akka Streams - the Graph DSL language - in which we will write our own graph step, in which the stream branches into two parts. The first simply submits the values to the web socket, and the second monitors when the next 5 seconds expire, and sends a notification by e-mail - see fig. 3.
Fig. 3. Our own graph step for sending emails
We will use the built-in step
Broadcaston which our input is sent to a set of announced conclusions. We will also write our own trap - Mailer:private final Graph, NotUsed> notifier = GraphDSL.create(builder -> {
Sink mailerSink = Flow.of(Double.class)
.grouped(EMAIL_THRESHOLD)
.to(Sink.foreach(ds ->
logger.info("Sending e-mail")
));
UniformFanOutShape broadcast = builder.add(Broadcast.create(2));
SinkShape mailer = builder.add(mailerSink);
builder.from(broadcast.out(1)).toInlet(mailer.in());
return FlowShape.of(broadcast.in(), broadcast.out(0));
}); We begin to create our own graph step with the method
GraphDSL.create()where an instance of the graph builder is provided Builder— it is used to manipulate the graph structure. Next, we define our own trap, where it is used
groupedto combine incoming elements into groups of arbitrary size (5 by default), after which these groups are sent down. For each such group, we will simulate a side effect: an email notification. Having defined our own trap, we can use an instance
builderto add it to the graph. We also add a step Broadcastwith two outputs. Next, you need to specify the connection between the graph elements - one of the outputs of the step
Broadcastwe want to connect with an email trap, and the other - to make an output for the step of the graph we wrote. The input of the step we wrote will be directly connected to the step output Broadcast. Note 1:
The compiler cannot determine if all parts of the graph are connected correctly. However, this point is checked by the materializer at run time, so there will be no hanging elements at the input or output.
Note 2
In this case, you can notice that all the steps we wrote are of the form Graph
At the last stage, we connect the notifier as an additional step in the pipeline
liveReadings, which now takes the following form:private final Source liveReadings =
newFiles
.via(csvPaths)
.via(fileBytes)
.via(csvFields)
.via(readings)
.via(averageReadings)
.via(notifier); Running the updated code, you will see how the messages about email notifications appear in the log. A notification is sent whenever another five values manage to pass through the web socket.
Summary
In this article we studied the general concepts of streaming data processing, learned how to use Akka Streams to build a lightweight data processing pipeline. This is an alternative to the traditional approach used in Java EE.
We looked at how to use some processing steps built into Akka Streams, how to write our own step in Graph DSL. It was also shown how to use Alpakka to stream data from the file system and the Akka HTTP protocol, which allows you to create a simple web server with a web socket on the endpoint, seamlessly integrated with Akka Streams.
A full working example with the code in this article is on GitHub . It has several additional
logsteps, placed at different points. They help to more accurately imagine what is happening inside the conveyor. In the article, I specifically omitted them to make it shorter.