Data Analysis - Basics and Terminology
- Tutorial
- Recovery mode
In this article, I would like to discuss the basic principles of building a practical project for (so-called “intellectual”) data analysis, as well as fix the necessary terminology, including Russian-language.
According to wikipedia,
The described problem of digit recognition can be solved by trying to independently select a function that implements the corresponding display. It will turn out, most likely, not very fast and not very good. On the other hand, you can resort to machine learning methods , that is, use manually labeled samples (or, in other cases, certain historical data) to automatically select the decisive function. Thus, hereinafter , I will call a (generalized) machine learning algorithm an algorithm that somehow or other based on data forms a non-deterministic algorithm that solves a particular problem. (The nondeterministic nature of the obtained algorithm is necessary so that a directory that uses pre-loaded data or an external API does not fall under the definition).
Thus, machine learning is the most common and powerful (but, nevertheless, not the only) method of data analysis. Unfortunately, people have not yet invented machine learning algorithms that process data of a more or less arbitrary nature well, and therefore a specialist has to pre-process the data independently to bring it into a form suitable for applying the algorithm. In most cases, this pre- processing is called feature selection (English feature selection ) or preprocessing . The fact is that most machine learning algorithms accept sets of fixed-length numbers as input (for mathematicians, points in ) However, now various algorithms based on neural networks are also widely used , which can accept not only sets of numbers, but also objects that have some additional, mainly geometric, properties, such as images (the algorithm takes into account not only pixel values, but also their relative position), audio, video and texts. Nevertheless, some pre-processing usually occurs in these cases, so we can assume that for them the feature select is replaced by the selection of successful preprocessing.
) However, now various algorithms based on neural networks are also widely used , which can accept not only sets of numbers, but also objects that have some additional, mainly geometric, properties, such as images (the algorithm takes into account not only pixel values, but also their relative position), audio, video and texts. Nevertheless, some pre-processing usually occurs in these cases, so we can assume that for them the feature select is replaced by the selection of successful preprocessing.
An algorithm of machine learning with a teacher (in the narrow sense of the word) can be called an algorithm (for mathematicians, a mapping), which takes a set of points (also called examples or samples)  and labels (the values we are trying to predict)
and labels (the values we are trying to predict)  , and the output gives an algorithm (= function)
, and the output gives an algorithm (= function)  already matching a specific value
already matching a specific value  any input
any input  belonging to the space of examples. For example, in the case of the aforementioned neural network that recognizes numbers, using a special procedure based on the training set, values corresponding to the connections between neurons are established, and with their help, a prediction for each new example is calculated at the application stage. By the way, a collection of examples and labels is called a training set .
belonging to the space of examples. For example, in the case of the aforementioned neural network that recognizes numbers, using a special procedure based on the training set, values corresponding to the connections between neurons are established, and with their help, a prediction for each new example is calculated at the application stage. By the way, a collection of examples and labels is called a training set .
The list of effective machine learning algorithms with a teacher (in the narrow sense) is strictly limited and hardly replenished despite intensive research in this area. However, the proper application of these algorithms requires experience and training. The issues of effectively reducing a practical task to the task of analyzing data, selecting a list of features or preprocessing, a model and its parameters, as well as competent implementation are not easy in themselves, not to mention working on them together.
The general scheme for solving the problem of data analysis using the machine learning method looks like this:
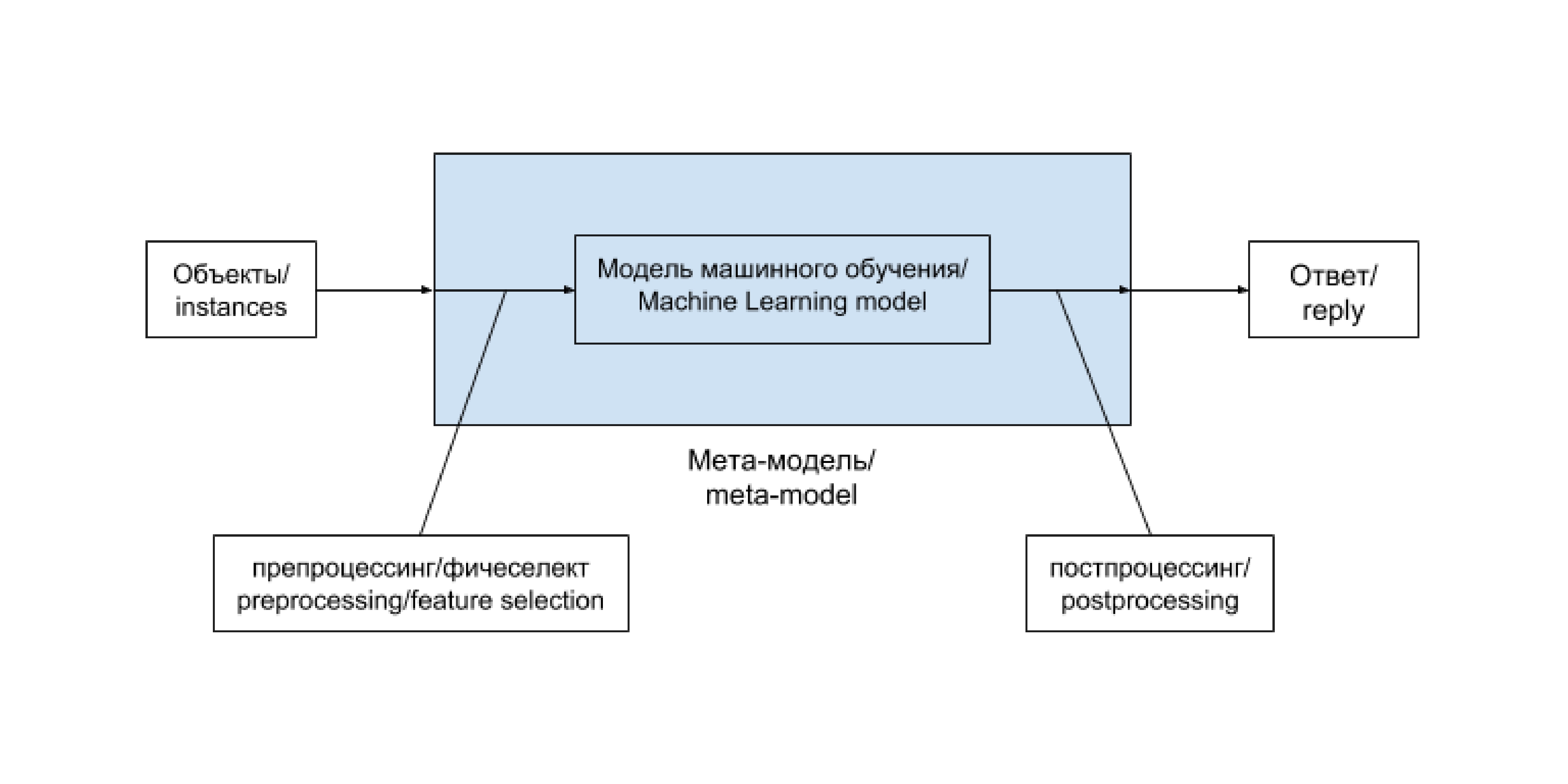
The chain “preprocessing - machine learning model - postprocessing” is conveniently distinguished into a single entity. Often such a chain remains unchanged and only regularly retrains on newly arrived data. In some cases, especially in the early stages of project development, its contents are replaced by a more or less complex heuristic that does not depend directly on the data. There are more tricky cases. We will start a separate term for such a chain (and its possible variants) and will call it a meta-model . In the case of heuristics, it is reduced to the following scheme:
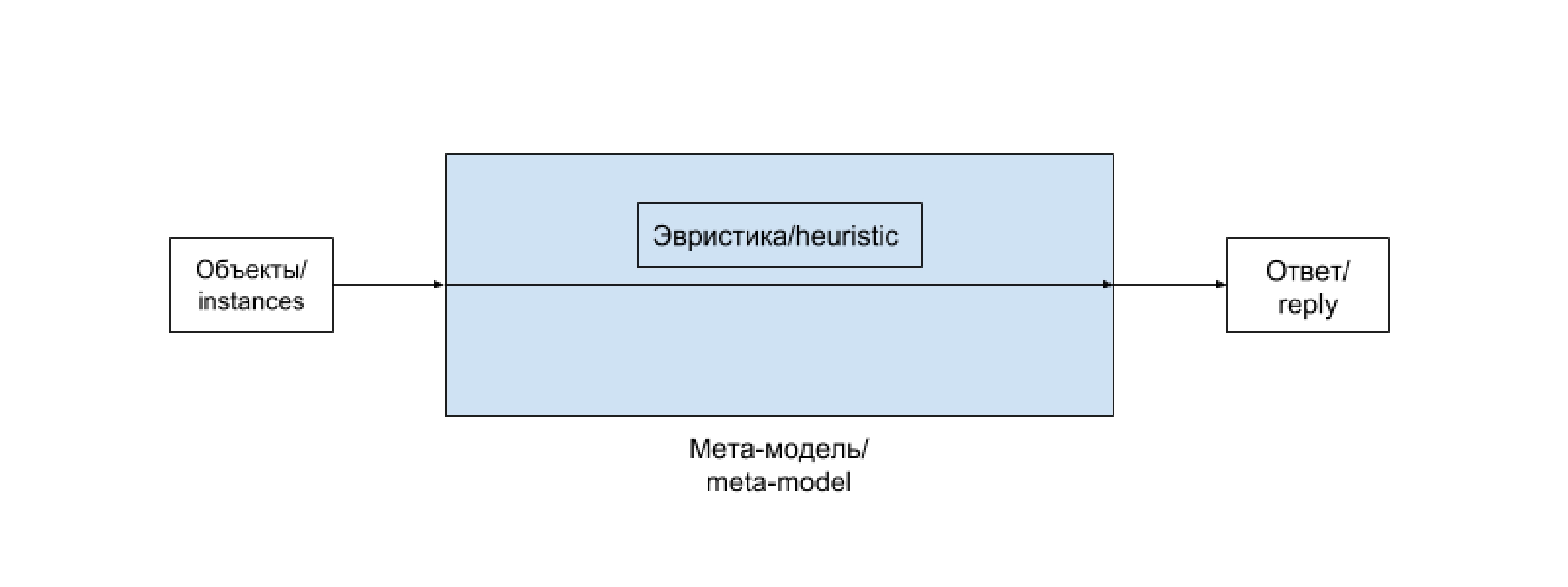
Heuristics is simply a manually selected function that does not use advanced methods, and, as a rule, does not give a good result, but is acceptable in certain cases, for example, in the early stages of a project.
Depending on the setting, the tasks of machine learning are divided into tasks of classification, regression and logistic regression.
Classification is a statement of the problem in which it is required to determine which class of an clearly defined list an incoming object belongs to. A typical and popular example is the recognition of numbers already mentioned above, in it each image needs to be matched with one of 10 classes corresponding to the displayed figure.
Regression is a statement of the problem in which it is required to predict some quantitative characteristic of an object, for example, price or age.
Logistic regression combines the properties of the above two problem statements. It sets the events that have taken place at the objects, and it is required to predict their probabilities at new objects. A typical example of such a task is the task of predicting the likelihood of a user clicking on a reference link or advertisement.
The metric of the quality of the prediction of the (fuzzy) algorithm is a way to evaluate the quality of its work, to compare the result of its application with a valid answer. More mathematically, this is a function that takes a prediction list as an input and a list of answers that happened
and a list of answers that happened  , and the returning number corresponding to the quality of the prediction. For example, in the case of a classification problem, the simplest and most popular option is the number of mismatches
, and the returning number corresponding to the quality of the prediction. For example, in the case of a classification problem, the simplest and most popular option is the number of mismatches , and in the case of the regression problem, the standard deviation
, and in the case of the regression problem, the standard deviation  . However, in some cases, for practical reasons, it is necessary to use less standard quality metrics.
. However, in some cases, for practical reasons, it is necessary to use less standard quality metrics.
Before introducing an algorithm into a product that works and interacts with real users (or passes it to the customer), it would be nice to evaluate how well this algorithm works. For this, the following mechanism is used, called the validation procedure.. The available labeled sample is divided into two parts - training and validation. The algorithm is trained on the training sample, and its quality assessment (or validation) is performed on the validation one. In the event that we do not use the machine learning algorithm yet, but select the heuristic, we can assume that the whole labeled sample on which we evaluate the quality of the algorithm is validated, and the training sample is empty - consists of 0 elements.
In its most general terms, the data analysis project development cycle is as follows.
That's all for now, next time we will discuss what specific algorithms are used to solve classification, regression and logistic regression problems, and how to do a basic study of the problem and prepare its result for use by an applied programmer can already be read here .
PS In the next topic, I argued a little with people who adhere to a more academic point of view on machine learning issues than mine. Which somewhat negatively affected my habrokarm. So if you would like to accelerate the appearance of the next article and have the appropriate authority - try me on a little, this will help me write and lay out the sequel more quickly. Thanks.
According to wikipedia,
Data analysis is a field of mathematics and computer science that is engaged in the construction and study of the most common mathematical methods and computational algorithms for extracting knowledge from experimental (in the broad sense) data; the process of researching, filtering, transforming and modeling data in order to extract useful information and make decisions.Speaking in a slightly simpler language, I would suggest to understand by data analysis the totality of methods and applications related to data processing algorithms and not having a clearly recorded response to each incoming object. This will distinguish them from classical algorithms, for example, implementing sorting or a dictionary. The time of its execution and the amount of occupied memory depends on the specific implementation of the classical algorithm, but the expected result of its application is strictly fixed. In contrast, we expect a neural network that recognizes numbers to answer 8 with an incoming picture depicting a handwritten figure of eight, but we cannot demandof this result. Moreover, any (in the rational sense of the word) neural network will sometimes be mistaken on one or another version of the correct input data. We will call such a statement of the problem and the methods and algorithms used in its solution non-deterministic (or fuzzy ), in contrast to the classical ( deterministic , clear ) ones.
Algorithms and Heuristics
The described problem of digit recognition can be solved by trying to independently select a function that implements the corresponding display. It will turn out, most likely, not very fast and not very good. On the other hand, you can resort to machine learning methods , that is, use manually labeled samples (or, in other cases, certain historical data) to automatically select the decisive function. Thus, hereinafter , I will call a (generalized) machine learning algorithm an algorithm that somehow or other based on data forms a non-deterministic algorithm that solves a particular problem. (The nondeterministic nature of the obtained algorithm is necessary so that a directory that uses pre-loaded data or an external API does not fall under the definition).
Thus, machine learning is the most common and powerful (but, nevertheless, not the only) method of data analysis. Unfortunately, people have not yet invented machine learning algorithms that process data of a more or less arbitrary nature well, and therefore a specialist has to pre-process the data independently to bring it into a form suitable for applying the algorithm. In most cases, this pre- processing is called feature selection (English feature selection ) or preprocessing . The fact is that most machine learning algorithms accept sets of fixed-length numbers as input (for mathematicians, points in
) However, now various algorithms based on neural networks are also widely used , which can accept not only sets of numbers, but also objects that have some additional, mainly geometric, properties, such as images (the algorithm takes into account not only pixel values, but also their relative position), audio, video and texts. Nevertheless, some pre-processing usually occurs in these cases, so we can assume that for them the feature select is replaced by the selection of successful preprocessing. An algorithm of machine learning with a teacher (in the narrow sense of the word) can be called an algorithm (for mathematicians, a mapping), which takes a set of points
(also called examples or samples) and labels (the values we are trying to predict) , and the output gives an algorithm (= function) already matching a specific value any input belonging to the space of examples. For example, in the case of the aforementioned neural network that recognizes numbers, using a special procedure based on the training set, values corresponding to the connections between neurons are established, and with their help, a prediction for each new example is calculated at the application stage. By the way, a collection of examples and labels is called a training set .The list of effective machine learning algorithms with a teacher (in the narrow sense) is strictly limited and hardly replenished despite intensive research in this area. However, the proper application of these algorithms requires experience and training. The issues of effectively reducing a practical task to the task of analyzing data, selecting a list of features or preprocessing, a model and its parameters, as well as competent implementation are not easy in themselves, not to mention working on them together.
The general scheme for solving the problem of data analysis using the machine learning method looks like this:
The chain “preprocessing - machine learning model - postprocessing” is conveniently distinguished into a single entity. Often such a chain remains unchanged and only regularly retrains on newly arrived data. In some cases, especially in the early stages of project development, its contents are replaced by a more or less complex heuristic that does not depend directly on the data. There are more tricky cases. We will start a separate term for such a chain (and its possible variants) and will call it a meta-model . In the case of heuristics, it is reduced to the following scheme:
Heuristics is simply a manually selected function that does not use advanced methods, and, as a rule, does not give a good result, but is acceptable in certain cases, for example, in the early stages of a project.
Machine Learning Tasks with a Teacher
Depending on the setting, the tasks of machine learning are divided into tasks of classification, regression and logistic regression.
Classification is a statement of the problem in which it is required to determine which class of an clearly defined list an incoming object belongs to. A typical and popular example is the recognition of numbers already mentioned above, in it each image needs to be matched with one of 10 classes corresponding to the displayed figure.
Regression is a statement of the problem in which it is required to predict some quantitative characteristic of an object, for example, price or age.
Logistic regression combines the properties of the above two problem statements. It sets the events that have taken place at the objects, and it is required to predict their probabilities at new objects. A typical example of such a task is the task of predicting the likelihood of a user clicking on a reference link or advertisement.
Metric selection and validation procedure
The metric of the quality of the prediction of the (fuzzy) algorithm is a way to evaluate the quality of its work, to compare the result of its application with a valid answer. More mathematically, this is a function that takes a prediction list as an input
and a list of answers that happened , and the returning number corresponding to the quality of the prediction. For example, in the case of a classification problem, the simplest and most popular option is the number of mismatches, and in the case of the regression problem, the standard deviation . However, in some cases, for practical reasons, it is necessary to use less standard quality metrics. Before introducing an algorithm into a product that works and interacts with real users (or passes it to the customer), it would be nice to evaluate how well this algorithm works. For this, the following mechanism is used, called the validation procedure.. The available labeled sample is divided into two parts - training and validation. The algorithm is trained on the training sample, and its quality assessment (or validation) is performed on the validation one. In the event that we do not use the machine learning algorithm yet, but select the heuristic, we can assume that the whole labeled sample on which we evaluate the quality of the algorithm is validated, and the training sample is empty - consists of 0 elements.
Typical project development cycle
In its most general terms, the data analysis project development cycle is as follows.
- The study of the problem statement, possible data sources.
- Reformulation in mathematical language, the choice of metrics for the quality of prediction.
- Writing a pipeline for training and (at least test) use in a real environment.
- Writing a heuristic that solves the problem or a simple machine learning algorithm.
- If necessary, improving the quality of the algorithm, it is possible to refine the metrics, attract additional data.
Conclusion
That's all for now, next time we will discuss what specific algorithms are used to solve classification, regression and logistic regression problems, and how to do a basic study of the problem and prepare its result for use by an applied programmer can already be read here .
PS In the next topic, I argued a little with people who adhere to a more academic point of view on machine learning issues than mine. Which somewhat negatively affected my habrokarm. So if you would like to accelerate the appearance of the next article and have the appropriate authority - try me on a little, this will help me write and lay out the sequel more quickly. Thanks.