Microservice testing: a smart approach
- Transfer
The driving force of microservices
The ability to develop, deploy and scale various business functions independently of one another is one of the most publicized benefits of switching to a microservice architecture.
While the masters of thoughts still cannot decide whether this statement is true or not, microservices have already become fashionable - and to such an extent that for most startups they have de facto become the default architecture.
However, when it comes to testing (or, worse, developing ) microservices, it turns out that most companies are still attached to the antediluvian way of testing all components together. The creation of a complex infrastructure is considered a prerequisite for conducting end-to-end testing, in which a set of tests for each service must be performed - this is done in order to make sure that the services do not have regressions or incompatible changes.
From translators. INCindy Sridharan’s original article uses a lot of terminology for which there are no established Russian counterparts. In some cases, the used Englishisms are used, it seems reasonable to us to write them in Russian, and in controversial cases, in order to avoid an incorrect interpretation, we will write the original term.
Today, the world does not lack books and articles on best software testing practices. However, in our article today, we will focus exclusively on the topic of testing backend services and will not touch upon testing desktop applications, systems with special technical security requirements, GUI tools, and other types of software.
It is worth noting that different experts put different meanings in the concept of “distributed system”.
As part of our article today, “distributed system” refers to a system consisting of many moving parts, each of which has different guarantees and types of failures, these parts work together in unison in order to implement a specific business function. My description may be very vaguely similar to the classical definition of distributed systems, but it applies to those systems that I regularly encounter - and I bet that the vast majority of us develop and support such systems . Further in the article, we are talking about distributed systems, which today are called "microservice architecture."
“Full Stack in a Box”: A Cautionary Story
I often have to deal with companies that are trying to fully reproduce the service topology locally on the laptops of developers. I had to face this error personally at the last place of work, where we tried to deploy our entire stack in Vagrant-box. The Vagrant repository was called the "full stack in the box"; As you might have guessed, the idea was that one simple vagrant up team should allow any engineer in our company (even front-end and mobile developers) to deploy absolutely the entire stack on their work laptops.
As a matter of fact, it was not a full-fledged microservice architecture of the scale of Amazon , containing thousands of services. We had two services on the backend: an API server based on gevent , and asynchronous Python workers running in the background, which had a whole bunch of native dependencies that included boost in C ++ - and, if memory serves me right, it compiled from scratch every time a new box on Vagrant was launched.
My first work week at this company was entirely spent only locally raising a virtual machine and defeating a great many errors. Finally, by Friday evening, I managed to get Vagrant to work, and all the tests worked successfully on my PC. In the end, I decided to document all the problems that I had to face, so that other developers had fewer such problems.
And what do you think, when a newcomer developer started to configure Vagrant, then he faced completely different errors - and I did not even manage to reproduce them on my machine. In truth, this whole fragile design was on the palm of my hand - I was afraid to even update the library for Python, because once done pip install managed to break Vagrant settings and stopped running tests when it started locally.
In the process of flight debriefing, it turned out that Vagrant had a similar situation with programmers from the mobile and web development teams; troubleshooting Vagrant has become a frequent source of requests for the support team, where I worked then. Of course, someone can say that we just had to spend more time once and for all “fixing” Vagrant settings so that everything “just worked”, in my defense I will say that the described story took place in a startup, where time and engineering cycles forever missing out on anything.
Fred Eber wrote a wonderful review of this article, and made a remark that accurately describes my feelings:
... the request to launch the cloud on the developer's machine is equivalent to the need to support a new cloud provider, and the worst of all that you have ever encountered.
Even provided that you follow the most modern operating methods - “infrastructure as code”, unchanged infrastructure - an attempt to deploy a cloud environment locally will not bring you benefits commensurate with the efforts that will take you to raise it and provide long-term support.
After talking with my friends, I found out that the described problem is poisoning life not only for those who work in startups, but also for those who work in large organizations. Over the past few years, I have heard a lot of jokes about how easily this design falls apart and how expensive it costs to operate and maintain it. Now I am firmly convinced that the idea of deploying the entire stack on developer laptops is vicious, no matter what size your company is.
In fact, a similar approach to microservices is equivalent to creating a distributed monolith.
Prediction for 2020: monolithic applications are back in fashion after people become familiar with the disadvantages of distributed monoliths.
As blogger Tyler Trith notes :
He laughed heartily at the discussion of microservices at Hacker News . "Developers should be able to deploy the environment locally; everything else is a sign of bad tools." Well, yes, of course, smart guy, try running 20 pieces of microservices with different databases and dependencies on your MacBook. Oh yes, I forgot that docker compose will solve all your problems.
Everywhere the same thing. People begin to create microservices, without changing their “monolithic” mentality, and this always ends with a real theater of absurdity. “I need to run all this on my machine with the selected service configuration in order to test one single change.” What happened to us ...
If someone, God forbid, accidentally sneezes, then my code will immediately become non-testable. Well, good luck with this approach. Even though large-scale integration tests involving a significant number of services are an anti-pattern, it’s still hard to convince others. Switching to microservices means using the right tools and techniques. Stop using old approaches in a new context.
Throughout the industry, we are still attached to the testing methodologies invented in the era far from us, which was very different from the reality in which we are today. People are still passionate about ideas such as full test coverage (so much so that in some companies merge will be blocked if a patch or brunch with a new feature will reduce the code base coverage by more than a certain percentage), development through testing and full end-to-end testing at the system level.
In turn, such beliefs lead to the fact that large engineering resources are invested in the construction of complex CI pipelines and intricate local development environments. Quickly enough, support for such an expanded system turns into the need to contain a team that will create, maintain, troubleshoot and develop infrastructure. And if large companies can afford such a deep level of sophistication, then everyone else should just take testing as it is: this is the best possible system verification. If we take a smart approach to assessing the value of our choice and make compromises, then this will be the best option.
Test Range
It is generally accepted that testing is done before release. Some companies have - and still exist - separate testers (QA), whose main responsibility is to perform manual or automated tests for software created by development teams. As soon as the software component passes the QA, it is transferred to the operating team for launch (in the case of services), or released as a product (in the case of desktop applications and games).
This model is slowly but surely a thing of the past - at least in terms of services; how much I can judge from startups in San Francisco. Now the development teams are responsible for both testing and operating the services they create. This new approach to creating services I find incrediblepowerful - it truly allows development teams to think about the scope, goals, trade-offs and compensations across the full spectrum of testing methods - and in a realistic manner. In order to fully understand how our services function and make sure their work is correct, we obviously need to be able to choose the right subset of testing methods and tools, taking into account the required parameters of availability, reliability and correct operation of the service.
Just like a tongue removed. Testing before the deployment is a partial preparation for testing in production. To paraphrase your statement: pre-deployment testing can teach, help rehearse and strengthen biased mental models of the system, and actually works against you in the product, making you immune to reality.
By and large, the concept of “testing” can cover several types of activities that are traditionally referred to as “release engineering”, operation, or QA. Some of the methods listed in the table below, strictly speaking, are not considered test forms - for example, chaos engineering is classified as an experiment form in the official definition; in addition, the above list is by no means exhaustive - it does not include vulnerability testing , penetration testing , threat modeling ( threat modeling ) and other testing methods. However, the table includes all the most popular testing methods that we encounter daily.

Of course, the taxonomy of testing methods in the table does not fully reflect reality: as practice shows, some testing methods may fall into both categories at once. So, for example, “profiling” in it is referred to testing in production - however, it is often used during development, so it can be attributed to testing in pre-production. Similarly, shadowing - a method in which a small amount of traffic from a production is run over a small number of test instances - can be considered as testing in production (because we use real traffic) and testing in pre-production (because it does not affect real users).
Different programming languages have varying degrees of support for application testing in production. If you write in Erlang, then it is quite possible that you are familiar with the guidance of Fred Eber on the use of virtual machine primitives for debugging systems in production while they continue to work. Languages like Go come with built-in support for profiling heaps, locks, CPUs and goroutines for any of the running processes (testing in production) or when running unit tests (this can be qualified as testing in pre-production).
Testing in production - replacing testing in pre-production?
In my last article, I paid a lot of attention to testing in "post-production", mainly from the point of view of observability. Such forms of testing include monitoring, alerts, research, and dynamic instrumentation (inserting analyzing procedures into executable code). Perhaps testing in production may include such techniques as gating and the use of function flags ( feature flags , with which you can enable / disable functionality in the code using the configuration). User interaction and user experience assessment - for example, A / B testing and real user monitoring also apply to production testing.
In narrow circles, there is a discussion that such testing methods can replace traditional testing in pre-production. Recently, a similar provocative discussion launched on Twitter Sarah May . Of course, she immediately raises a few difficult topics in her, and I don’t agree with her on everything, but many of her remarks exactly correspond to my feelings. Sarah states the following:
Popular wisdom states the following: before releasing the code, a complete set of regression tests should become “green”. You need to be sure that the changes will not break anything else in the application. But there are ways to verify this without resorting to a set of regression tests. Especially now, with the heyday of complex monitoring systems and understanding of the error rate on the operating side.
With sufficiently advanced monitoring and a large-scale realistic strategy, it becomes writing code, pushing it into the prod and observing the number of errors. If as a result something in another part of the application breaks, it will become very quickly clear from the increased number of errors. You can fix the problem or roll back. Simply put, you allow your monitoring system to perform the same role as regression tests and continuous integration in other teams.
Many people took it as if it was worth removing testing before production altogether as unclaimed, but I think that was not the idea. Behind these words is a fact that many software developers and professional testers can’t put up with in any way - manual or automated testing alone can often be insufficient measures, to the extent that sometimes they do not help us at all .
In the book “ Lessons Learned in Software Testing ” (there is no official translation into Russian, but there is an amateur one) there is a chapter entitled “ Automated testing ”, in which the authors claim that only a minority of bugs find automatic regression tests.
According to unofficial polls, the percentage of bugs that are detected by automated tests is surprisingly low. Projects with a significant number of well-designed automated tests report that regression tests are capable of detecting 15 percent of the total number of bugs.
Automated regression tests usually help detect more bugs during the development of the tests themselves than during the execution of tests in subsequent stages. However, if you take your regression tests and find a way to reuse them in different environments (for example, on a different platform or with different drivers), then your tests are more likely to detect problems. In fact, in this case they are no longer regression tests, since they are used to test configurations that have not been tested before. Testers report that this kind of automated test is able to find 30 to 80 percent of errors.
The book, of course, managed to get a little outdated, and I could not find a single recent study about the effectiveness of regression tests, but the fact that we are so used to the fact that the best testing practices and disciplines are based on the absolute superiority of automated testing is important here, and any attempt to doubt leads to the fact that you are considered a heretic. If I learned something from several years of monitoring how services are being denied, then this is this: testing before production is the best possible verification of some small set of system guarantees, but at the same time, it alone will not be enough for checks of systems that will work for a long time and with a frequently changing load.
Returning to what Sarah wrote about:
This strategy builds on many assumptions; it is based on the fact that the team has a complex operation system that most development teams do not have. And that's not it. It is assumed that we can segment users, display changes-in-process of each developer on a different segment, and also determine the error rate for each segment. In addition, such a strategy involves a product organization that feels comfortable when experimenting with live traffic.Again, if the team is already doing A / B testing for changes in the product on live traffic, it simply extends the idea itself to the changes made by the developers. If you manage to do all this and receive feedback on changes in real time - it will be just wonderful.
The selection is mine, it seems to me to be the biggest block on the path to gaining greater confidence in the systems being created. For the most part, the biggest obstacle to moving to a more comprehensive testing approach is the necessary shift in thinking. The idea of habitual testing in pre-production has been instilled into programmers from the very beginning of their career, while the idea of experimenting with live traffic is seen by them either as the prerogative of operational engineers, or as encountering something terrible like an alarm.
Since childhood, we have all been accustomed to the sacred sanctity of production, with which we are not supposed to play, even if this deprives us of the opportunity to check our services, and all that remains on our lot are other environments that are only pale shadows of production. Testing services in environments that are “as similar as possible” to production is akin to a dress rehearsal - it seems to be some good, but there is a huge difference between speaking in a full room and an empty room.
It is not surprising that many of Sarah's interlocutors shared this opinion. Her answer to them was as follows:
They write to me here: “but your users will see more errors!” This statement directly consists of non-obvious misconceptions - I don’t even know where to start ...
The transfer of responsibility for finding regressions from monitoring tests in production will result in users most likely to generate more errors in your system. This means that you cannot afford to use this approach without changing your code base accordingly - everything should work in such a way that errors are less noticeable (and produce less effect) on your users. In fact, this is such a beneficial pressure that can help make your user experience much better. Some write to me that “users will generate more errors” -> “users will see more errors” -> “you do not care about your users!” No, this is absolutely not so, you just think wrong.
Here it hits the nail on the head. If we transfer regression testing to monitoring after production, then such a change will require not just a change in mindset, but also a willingness to take risks. More importantly, it will require a complete redesign of the system design, as well as serious investments in advanced release engineering practices and tools. In other words, this is not just about architecture with failures in mind - in fact, there is programming with failures in mind . Whereas the gold standard has always been software programming that runs smoothly. And here, the vast majority of developers will definitely feel uncomfortable.
What to test in production, and what in pre-production?
Since the testing of services is represented by a whole spectrum, both forms of testing should be taken into account during the design of the system (both architecture and code are implied here). This will make it possible to understand which functionality of the system will need to be tested before production, and which of its characteristics, more reminiscent of the long tail of the features , are best studied already in production using the appropriate tools and tools.
How to determine where these boundaries lie, and which testing method is suitable for a particular system functionality? This should be decided together by development and operation, and, again, it should bedone at the stage of system design. The top-down approach as applied to testing and monitoring after this stage managed to prove its failure.
Hiring a “SRE team” will not provide additional reliability to your services. The top-down approach to reliability and stability does not work - here we need a bottom-up approach. To achieve these goals, you must believe in SWE instead of continuing to flirt with exploitation.
Charity Majors made a presentation last year at Strangeloop , where she talked about how the difference between observability and monitoring comes down to “known unknowns” and “unknown unknowns”.
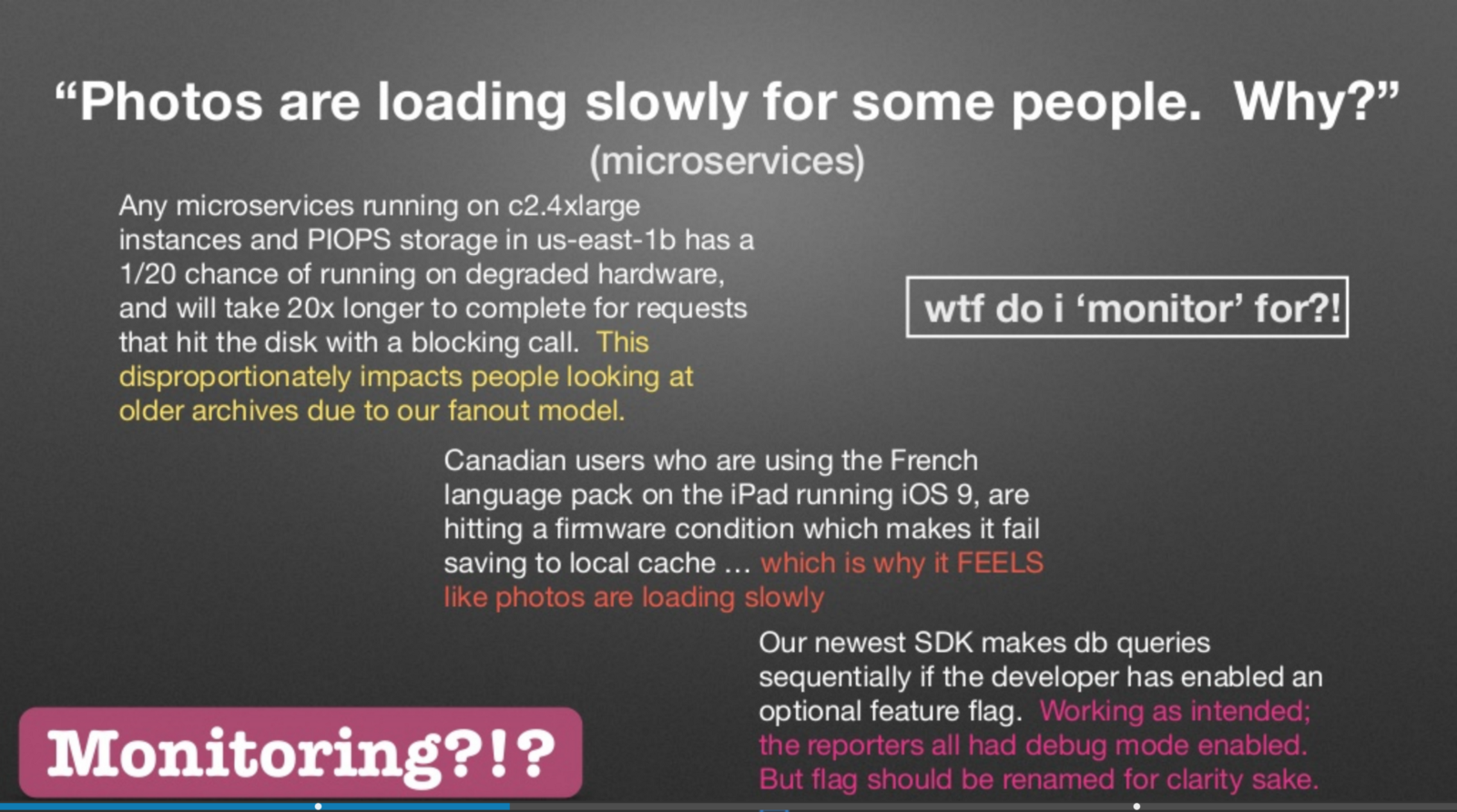
Slide from Charity Major's report on Strangeloop in 2017
Charity rights - the problems listed on the slide are not what you would ideally want to monitor. Similarly, these are not the problems that you would like to test in pre-production. Distributed systems are pathologically unpredictable, and it is impossible to foresee all the possible bogs of that swamp, in which various services and subsystems may appear. The sooner we come to terms with the fact that the attempt to predict in advance every way that a service can be performed, followed by writing a regression test case is a stupid undertaking, the sooner we will begin to engage in less dysfunctional testing.
As Fred Eber noted in his review of this article:
... as a large service using many machines grows, so do the chances that the system will never be 100% operational. A partial failure will always occur somewhere in it. If the tests require 100% performance, then keep in mind that your problem is brewing.
In the past, I argued that “monitoring everything” is an anti-pattern. Now it seems to me that a similar statement applies to testing. You cannot, and therefore should not try, test absolutely everything . The SRE book claims that:
It turns out that after a certain point, an increase in reliability negatively affects the service (and its users), instead of making life better! Extreme reliability comes at a price: maximizing stability limits the speed of developing new functions and the speed of delivering them to users, and significantly increases their cost, which in turn reduces the number of functions that a team can implement and offer users.
Our goal is to find clear boundaries between the risk that the service will take and the risk that the business is ready to bear. We strive to make the service reliable enough, but no more than what is required of us.
If you replace “reliability” with “testing” in the quote above, this advice will not cease to be less useful.
However, it is time to ask the following question: what is better for testing before production, and what after?
Exploratory testing is not intended for pre-production testing.
Research testing is a testing approach that has been used since the 80s. It is mainly practiced by professional testers; This approach requires less training from the tester, allows you to find critical bugs, and has proven to be "more stimulating on an intellectual level than performing script tests . " I have never been a professional tester and have not worked in an organization that has a separate testing team, and therefore I only recently learned about this type of testing.
In the already mentioned book, Lessons Learned in Software Testing , in the chapter “ Think like a tester, ” there is one very sensible piece of advice that sounds like this: to test, you have to research .
To test something properly, you have to work with it. You have to figure it out. This is a research process, even if you have the perfect product description on hand. Until you research this specification by scrolling through it in your head or by working with the product itself, the tests you decide to write will be superficial. Even after you study the product at a fairly deep level, you still have to continue research for the sake of finding problems. Since all testing is sample analysis, and your sample will never be complete, this way of thinking allows you to maximize the benefits of testing the project.
By research, we mean deliberate wandering - navigation through space with a specific mission, but without a designated path. Research includes training and experimentation; it implies backtracking, repetition and other processes that may seem like a waste of time to an outside observer.
If in the above quote you replace each word “product” with the word “service”, then, according to my ideas, this will be the maximum of what we can achieve by testing microservices before production - given that for the most part the tests are pre- Production is extremely superficial .
Moreover, even though I absolutely agree with the significance of the opportunity to explore the service, I do not think that this technique should be applied only in the release phase before production. The book has additional details on how to incorporate research into your testing:
Research is the work of a detective. This is a free search. Think of exploration as moving through space. It implies direct, reverse and lateral thinking. You move forward by building better product models. These models subsequently allow you to design more effective tests.
Direct thinking : Move from what you know well to what you don’t know.
Reverse Thinking : Start with what you suspect or have some idea of, and move on to what you know, trying to confirm or refute your hypotheses.
Lateral thinking: Let's distract ourselves from work on ideas that go into your head, exploring tasks related to the main “tangent”, then return to the main topic.
Perhaps this kind of testing really needs to be done before release when building systems that are critical in terms of security, financial-related systems, and maybe even mobile applications. However, when creating infrastructural services, the research method is much better suited for debugging problems or conducting experiments in production; but the application of research at the stage of service development can be compared with an attempt to run ahead of the engine.
This is due to the fact that understanding of the performance characteristics of a service often comes after observing it in production, and the study becomes muchmore productive when we conduct it based on any evidence, rather than pure hypotheses. It is also important to note that in the absence of exclusively experienced and well-versed developers who can be trusted to carry out such a study in production, such experiments will require you not only to have modern tools that will provide you with security, but also a good understanding between the product and infrastructure / operational teams.
This is one of the reasons developers and operations must work closely together within an organization. The rivalry between them kills the whole idea. You cannot even begin to apply it if the responsibility for the so-called "quality" is hung on one of the parties. Hybrid approaches are definitely possible, in which small, fast test suites run through the critical code, and everything else is monitored in the prod.
Sara May
Developers should get used to the idea of testing and developing their systems based on the kind of accurate feedback that they can get only by observing the behavior of the system in production. If they rely solely on testing prior to production, this can serve them poorly - not only in the future, but even in the present, gaining distributed momentum - at the moment when they have to face a slightly less trivial architecture.
I do not think that each of us is an operating engineer . But what I am sure of is that exploitation is a shared responsibility. Understanding the basics of how hardware works allows a developer to advance further in their development - as well as understanding how services work in production.
I give 1000% that sooner or later a failure will happen. Damn it, it’s even possible that you will not have anything to do with it (I’m talking about you, S3zure). And the reason for this is not the deployment - the reason is on the Internet. If your software does not work in the “box”, then you now also work in Ops. Write your code accordingly.
Developers must learn to write (and test!) The code accordingly. However, such a statement can be considered superficial; let's finally decide what it is hidden under the sentence "write code accordingly."
In my opinion, it all comes down to three basic principles:
- understanding the operational semantics of the application;
- understanding the operational characteristics of dependencies;
- writing debugged code.
Application operational semantics
This concept involves writing code, during which you are puzzled by the following questions:
- how is the service deployed, with what tools;
- Is the service banned on port 0 or on a standard port?
- How does the application process signals?
- how the process starts on the selected host;
- How is a service registered with service discovery ?
- How does the service detect upstream?
- how the service is disconnected when it is about to end;
- whether graceful restart should be performed or not;
- how configs - static and dynamic - are fed to the process;
- application competitiveness model (multithreaded, or purely single-threaded, event driven , or on actors, or a hybrid model);
- how the reverse proxy at the front of the application holds connections (pre-fork or threads or processes).
Many companies believe that these issues need to be removed from the shoulders of developers and transferred to platforms or standard tools. Personally, I believe that at least a basic understanding of these issues can really help developers with work on services.
Dependency Performance
We build our services on top of more and more leaky abstractions (which are sometimes also fragile) with poorly understood types of failures. Examples of such characteristics that have become established for me over the past three years were:
- the default read consistency mode in the Consul client library (the default is usually “strict consistency”, but this is not quite what we would like to use to detect services);
- caching guarantees offered by the RPC client or standard TTL;
- Confluent Python Kafka official client streaming model and consequences of its use in the event server in Python;
- the default connection pool size for pgbouncer , reuse connections (default is LIFO), and find out if the default settings are suitable for the Postgres installation topology.
Debugging Code
Writing debugged code includes the ability to ask questions in the future, which in turn implies:
- a good degree of code instrumentation ;
- understanding of the chosen observability format - metrics, logs, error trackers, traces and their combination - as well as its pros and cons;
- the ability to choose the best observability format, taking into account the requirements of a particular service, the operational nuances of dependence and good engineering intuition.
If all of the above sounds intimidating, then the desire to "write the code accordingly" (and, critically important, " test accordingly") implies your willingness to accept this challenge.
Testing in pre-production
Now that we have discussed the hybrid approach to testing, let's look at the essence of the second half of our article - testing microservices before production.
Writing and running tests is NEVER an end in itself. We do this for the sake of our team or for the sake of business. If you can find a way to get the same benefits that tests give you, you should go this way - as your competitors most likely have already chosen it.
Sara May
We often get to the point that any type of testing becomes a fetish (be it traditional testing, monitoring, research, or whatever is used there); instead of working towards a goal, testing turns into a religion. No matter how unusual it may sound, testing is not an absolute, there is no standardized set of metrics that could be used as a universal criterion for a well-tested system.
However, the four axes — purpose, scale, concessions, benefits — can in practice serve as a good way to determine how effective one form or another of testing can be.
The purpose of testing before production
As stated earlier, for me testing before production is the best possible verification of the correctness of the system, and at the same time is the best possible simulation of known types of failures. The purpose of testing in pre-production, as you can see, is not to prove that there are no bugs (with the exception, probably, bugs in parsers and any applications related to money and security), but to make sure that "known-famous" are well covered by tests, but for "known-unknowns" there is a corresponding instrumentation.
Test coverage before production
The scope of testing before production can be wide only as good as our ability to find with the help of heuristics that which may turn out to be a precursor of errors in production. This includes the ability to approximate or intuitively understand the boundaries of the system, successful execution paths, as well as erroneous execution paths, plus continuous improvement of the heuristics used.
Usually at work I always write code and tests for it. Even when someone else does a review of my code, it still turns out to be a person from the same team. Thus, the coverage of tests is greatly reduced due to the prejudices that the engineers in the team may have, as well as any unexpressed assumptions based on which the system was created.
Given these goals and scope, let's evaluate the various types of testing before production in terms of these goals and scope, and also consider their advantages and disadvantages.
Unit testing
Microservices are based on the concept of dividing business logic units into autonomous services, while maintaining the principle of sole responsibility, where each individual service is responsible for the autonomous part of the business or infrastructure functionality. These services interact with each other over the network, either in some form of synchronous RPC mechanism, or communicate using asynchronous messaging.
Some proponents of microservices are calling for the use of standardized patterns for the interservice organization of components so that all services look structurally similar and consist of many components that could be layered together to help test each layer in isolation.
In other words, this approach (deservedly) wins in terms of decomposition at the code level for each individual service in order to separate different domains, as a result of which the network logic is separate from the protocol parsing logic, business logic and data storage logic. Traditionally, libraries were used to achieve these goals (you have a JSON parsing library, another library for accessing the data warehouse, and so on), and one of the often used advantages of this type of decomposition is that each of the layers can be tested with a unit test separately from the rest. Unit testing is widely regarded as a cheap and fast way to test the smallest possible functional unit.
No discussion of testing can be considered complete without mentioning the test automation pyramid proposed by Mike Cohn in his book Succeeding with Agile (not a Russian translation of Scrum. Flexible Software Development), which again became popular after Sam Newman mentioned in his book “ Building Microservices: Designing Fine-Grained Systems . " At the lower level of the pyramid are unit tests, which we consider to be a quick and cheap way to test, above them are service tests (or integration tests), and then tests using the UI (or end-to-end tests). As you climb up the pyramid, the speed of the tests decreases, and the cost of the test grows.
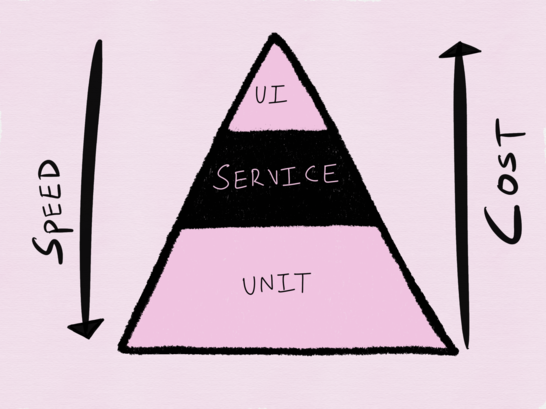
The test automation pyramid of Mike Cohn
The test pyramid was conceived in the era of monoliths, and with respect to testing such applications it makes a lot of sense. As a test of distributed systems, I find this approach not only obsolete, but also insufficient.
From my experience, an individual microservice (with the possible exception of network proxies) is almost always a front-end program (with a business logic spoon) that interacts with some kind of stateful backend like a database or cache. In such systems, most - if not all - rudimentary units of functionality often include some form of I / O (I want to believe that it is non-blocking ), whether it is receiving bytes from the network or reading data from disk.
Not all I / O are equal
At PyCon 2016, Corey Bandfield presented a wonderful report where he argued that most libraries make the mistake of not separating protocol parsing from I / O - which ultimately makes testing and code reuse difficult. This is really an extremely important idea, with which I absolutely agree.
However, I believe that not all types of I / O can be considered equal. Libraries for protocol parsing, RPC clients, database drivers, AMQP clients and others all perform I / O, but they all use different forms of I / O with different rates , which are determined by the limited context of the microservice.
For example, take the microservice testing, which is responsible for user management. In this case, it will be more important for us to be able to check whether users have been successfully created in the database, and not to test whether HTTP parsing works as it should. Of course, a bug in the HTTP parsing library can be a single point of failure for this service, but at the same time, HTTP parsing plays only a supporting role in the general scheme, and it is secondary to the main responsibility of the service. In addition, the library for working with HTTP is the part that will be reused by all services (and therefore fuzzing can be of great use in this case ), it should become a general abstraction. As you know, the best way to find a balance when working with abstractions (even the most "leaky") is, albeit unwillingly, to trust the promised service contract. Even if such a solution can hardly be called an ideal solution, as for me, this compromise has every right to exist if we are going to unleash at least something.
However, when it comes to the microservice itself, the abstraction that it is with respect to the rest of the system includes state transitions that are directly mapped to a specific part of the business or infrastructure logic, and therefore this functionality should be tested at the level of a sealed unit.
Similarly, suppose we have a network proxy server that uses Zookeper and service discovery to balance requests to dynamic backends; in this case, it is much more important to be able to test whether the proxy can correctly respond to the watch value trigger and, if possible, set a new control value. This is precisely what is the unit to be tested here.
The meaning of all of the above is that the most important unit of microservice functionality is the abstraction underlying I / O, which is used to interact with the backend, and therefore should become the very tight unit of basic functionality that we will test.
The most interesting thing is that, despite all the above, the vast majority of "best practices" for testing such systems do not refer to the underlying I / O microservice as its inseparable part, which also needs to be tested, but as interference that needs to be eliminated with the help of mocks . Up to the point that all unit testing these days has become synonymous with the active use of mokas.
Unit testing of such a critical for an I / O service with mokami is essentially a “block” for testing the service, since it sacrifices speed and accustoms us to think about the systems that we create, the opposite of how they actually work . Here I would go further and say that unit testing with the help of moki (we can denote it by the term“Wet testing” ) is for the most part a test of our incomplete, and most likely erroneous, mental model of the critical business components of the system we are working on, as a result of which we become hostages to one of the most insidious forms of bias.
I like the idea that moking affects our thinking. Mocks behave predictably, but networks and databases do not.
The biggest drawback of mokas as a testing tool is that when simulating successful execution, as well as crashing, mokas remain a programmer’s mirage, never reflecting even an approximate picture of the real world of production.
Here, some will say that it is better to deal with this problem in another way: to track all possible failures at the network level and, accordingly, add them to the test suite with additional moks that will cover all these test casesthat we previously ignored. Well, in addition to taking into account all possible problems, it seems poorly possible, this approach will most likely lead to an overblown set of tests with a large number of different mocks that perform similar functions. And in the end, all this, in turn, will lay a heavy burden on the shoulders of those who in the future will have to deal with supporting this good.
Once it came to supporting the tests, then another drawback of mocks is actively manifesting itself here: they make the test code unnecessarily detailed and difficult to understand. From my experience, this is especially true when whole classes are turned into mokas, and the implementation of mokas is introduced into the test as a dependency only so that the mok can confirm that a particular class method has been called an nth number of times or with certain parameters. A similar form of mok is now actively used when writing tests to test the behavior of services.
Мой синопсис использования объектов-моков в тестах: все закончится тем, что вы будете тестировать имплементацию, а не поведение, почти во всех тестовых кейсах. Это глупо: первое правило клуба тавтологии — это первое правило клуба тавтологии.
К тому же, вы увеличиваете размер своей кодовой базы в разы. В итоге, вам будет гораздо тяжелее производить изменения.
Примиряемся с мокингом
From the Google blog about testing, a post about
Mocky double objects , stubs and fakes - these are all kinds of so-called “ test doubles ”. Almost everything that I wrote before about mokee applies to other forms of test doubles. However, let's not go to extremes and say that mokas (and their variants) do not contain any advantages; likewise, not every unit test should always include I / O testing. In unit tests, it makes sense to include I / O only when the test includes a single I / O operation without any further side effects that we should prepare for (this is the main reason why I don’t see much point in testing subscription- publications in a similar way).
Consider the following topology of a highly plausible example of microservice architecture.
The interaction of service A with service B involves the communication of service B with Redis and service C. However, the smallest unit tested is the interaction of service A with service B , and the easiest way to test this interaction is to deploy a fake for service B and test the interaction of service A with fake . Testing contracts can be especially useful for testing such integrations. Soundcloud is known for using contract tests to test all of its 300+ microservices.
Service A also communicates with Riak. The minimum unit tested in this case includesthe real message between service A and Riak , so it makes sense to deploy a local Riak instance for testing.
When it comes to integration with third-party services such as GCP, AWS, Dropbox or Twilio, ideally, the binders or SDKs provided by the vendors already have ready-made good fakes that we can use in our test suite. Even better, if the vendors provide the ability to make real API calls, but in test mode or in the sandbox, as this allows developers to test services in a more realistic manner. These services include Stripe, which provides test tokens.
So, we have found out that the test "doubles" deserve their place in our testing spectrum, but do not get hung up on them as the only means of conducting unit tests or overdo it with their use.
The inconspicuous advantages of unit tests
Unit testing is not limited to the methods that we managed to discuss. It would be an omission to start discussing unit tests and not talk about property-based testing and fuzzing. It has become popular thanks to the QuickCheck library for Haskell (which was later ported to Scala and other languages) and the Hypothesis library for Python, property-based testing allows you to run the same test several times with different inputs without the need for the programmer to generate a fixed set of input data for test case. An excellent report on this topic was made by Jessica Kerr , and Fred Eber evenwrote a whole book on this subject . In his review of this article, Fred mentions various types of approaches to various tools for property-based testing:
Относительно property-based тестировани я скажу следующее: большая часть инструментов приближает его к фаззингу, но если немного поднапрячься, то вы сможете провести его на манер white-box тестирования с более тонким подходом. Другими словами, если фаззинг заключается в выяснении того, «падает» ли данная часть системы или нет, то property-based тестирование помогает проверить, всегда ли в системе соблюдается определенный набор правил или свойств. Существует 3 больших семейства property-тестов:
— Семейство Haskell QuickCheck. Эта разновидность основана на использовании информации о типе для генерирования данных, на которых будет выполнен тест. Основное преимущество: тесты становятся меньше, а их покрытие и полезность — выше. Недостаток: тяжело масштабировать.
— Семейство Erlang QuickCheck. Эта разновидность основана на динамических генераторах данных, которые представляют собой составные функции. Вдобавок к функциональности предыдущего типа, в таких фреймворках доступны stateful-примитивы моделирования. Больше напоминают model checking, поскольку вместо поиска перебором выполняют вероятностный поиск. Соответственно, здесь мы уходим от фаззинга в зону «проверки моделей», которая является совершенно другим семейством методов тестирования. Мне доводилось слушать доклады, авторы которых прогоняли такие тесты по разным облачным провайдерам и использовали их для обнаружения «железных» ошибок.
— Hypothesis: уникальный подход к делу. Основывается на механизме, схожем с фазз ингом, в котором генерация данных производится на основе потока байтов, который может становиться легче/тяжелее по шкале сложности. Имеет уникальное устройство и является самым применимым инструментом из перечисленных. Я не слишком хорошо знакома с тем, как Hypothesis работает «под капотом», но этот инструмент умеет делать гораздо больше, чем его аналоги на Haskell.
Fuzzing, on the other hand, allows you to feed in advance invalid and junk input to the application in order to ensure that the application completes the failure as planned.
For fuzzing, there are a large number of different tools: there are fuzzers that are based on coverage, such as afl , as well as address sanitizer , thread sanitizer , memory sanitizer , undefined behavior sanitizer and leak sanitizer tools and others.
Unit testing can provide other benefits besides the usual verification that something works as intended for a specific input data set. Tests can act as excellent documentation for the API exposed by the application. Languages like Go allow you to create example tests , in which functions starting with Example instead of Test live next to regular tests in the _test.go file in any of the selected packages. These example functions are compiled (and optionally executed) as part of the test suite of the package, after which they are displayed as part of the package documentation and allow you to run them as tests. The meaning of this, according to the documentation , is as follows:
This approach ensures that when you change the API, the documentation for the package does not expire.
Another advantage of unit tests is that they put some pressure on programmers and designers to structure the API, which would be easy to work with third-party services. A wonderful post “ Discomfort as a means of motivating changes ” was published on the Google blog about testing , which sheds light on the fact that the requirement from the authors of the API to provide its implementation in the form of fakes allows them to better understand who will work with this API and reduce the number of pain in this world.
In 2016, she was involved in organizing Python Twisted mitaps in San Francisco. One popular topic of discussion was that it was a mistake to make the event loop in Twisted global (which Python 3 would subsequently reproduce in the asyncio implementation , which would horrify the Twisted community) and how much easier it would be to test and use if Reactor ( which provides basic interfaces for all types of services, including networking, streaming, event scheduling, and so on) passed to consumers as an explicit dependency.
However, a reservation is required here. As a rule, good API design and good testing are two goals that are completely independent of each other, and in reality (however, to do thisnot recommended ) it’s easy to design an incredibly convenient and intuitive API that lacks testing. However, much more often people design an API that tries to achieve 100% test coverage (it doesn’t matter how you measure it there, by lines of code or otherwise), but in the end it turns out to be prematurely abstracted for a redundant artifact of insolvency. Although mocha-based unit testing is the path to a good API design, it does not guarantee that your code will execute properly.
VCR - cache or repeat test responses
Excessive use of moxes / fakes / test twins / stubs is not the most reliable choice of testing techniques (although sometimes you can’t get away with this), but when it comes to VCR-style caching, debugging failed tests becomes even more difficult.
Given the general unreliability of moki, I find it absolutely absurd for individuals to go even further down to write down answers as test fixtures . I find this method ineffective, both as a way to accelerate integration tests (although what kind of integration they are if they use such testing methods), and in terms of accelerating unit tests. Excessive overload of your brain during debugging of failed tests with a pile of extra layers is not worth the time spent on it.
Integration testing
If unit testing with mokas is so unreliable and implausible, does this mean that integration testing rushes to our aid and saves us?
Here is what I wrote on this issue in the past:
This may sound too radical, but good (and fast) integration testing (local and remote) coupled with good instrumentation often works better than the desire to achieve 100% test coverage.
At the same time, large integration tests for each available service that interacts with ours does not scale very well. It will be slow by default, and integration tests bring maximum benefit only if feedback from them can be obtained quickly.
We need the best distributed system testing patterns.
Some readers of my Twitter have pointed out to me that these two statements of mine conflict with each other; on the one hand, I urge you to write more integration tests instead of unit tests, on the other hand, I argue that integration tests do not scale well in the case of distributed systems. These points of view are not mutually exclusive, and perhaps my first statement really requires detailed explanations.
The point here is not that the replaced unit testing in this case come through end-to-end tests; the bottom line is that the ability to correctly identify a “unit”, or the unit that we must test, often means moving from traditional unit testing to what we usually call “integration testing”, because it involves communication over the network.
In the most trivial scenarios, a service communicates with a single database. In such cases, the inseparable unit that we are testing clearly includes the I / O they use. In cases where transactions are distributed, the definition of this unit itself becomes a non-trivial task. The only company I know that is trying to solve this problem is Uber, but, alas, when I asked my friend who worked there, the question of how they test, all he could answer me was: “it's still complicated task". Hypothetically, if I wanted to implement this pattern in a new service, the prospect of using mobs or fakes in order to check whether a distributed transaction was correctly canceled or a compensating transaction was applied does not seem to me a reliable option. The unit we are testing becomes a long-lived transaction.
Event sourcing Is a pattern that has gained popularity due to the growing popularity of Kafka. The pattern of the division of responsibilities commands and queries ( the Command and the Query Responsibility Segregation ) and anti-patterns associated with it is alive and well for more than 10 years. It is based on the idea of separating state changes ( writes ) from receiving states ( reads ). What I usually never hear in reports about these rather non-trivial architectural patterns is what methods should be used to test such architectures, with the exception of mocks at the code level and end-to-end testing at the system level.
Usually, the transfer of such verification to full-scale integration testing not only slows down the feedback cycle, but also causes the complexity of integration tests to grow to such a scale that they can exceed the system we are testing and require an inadequate amount of working time to support it (and, quite possibly the attention of the whole team).
Integration testing is not just ineffective for complex distributed systems; it is a black hole for your working time, which will not bring the corresponding benefit to the project.
Another disadvantage of using integration tests in complex systems is the requirement to support several different environments for development, testing and / or staging. Many companies try to maintain these environments in an identical state and “synchronize” them with the production, this usually involves repeating all the “live” traffic (at least the records) on the test cluster so that the data stores in the test environment match the production. Anyway, this approach requires significant investments in automation and its further support and monitoring.
Now that we have come to know all of these limitations and pitfalls, we can move on to the best compromise that exists. I call it the "Rule of Step Up."
Step Up Rule
Its main idea is that testing should begin one level higher than is usually recommended. According to this model, unit tests are more likely to look like integration tests (since they take I / O into account as part of the unit being tested within a limited context ), integration testing will look like testing in real production, but testing in production will be like monitoring and research. The familiar test pyramid for distributed systems is as follows:
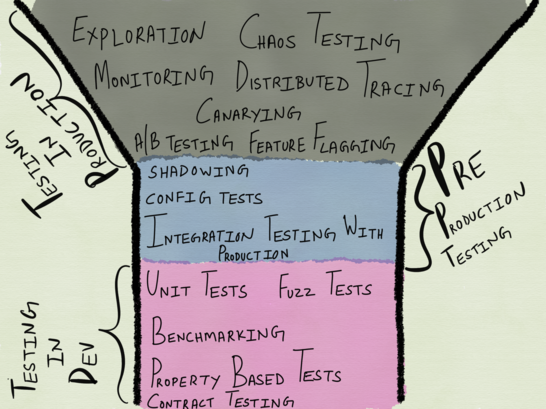
Test pyramid for distributed systems
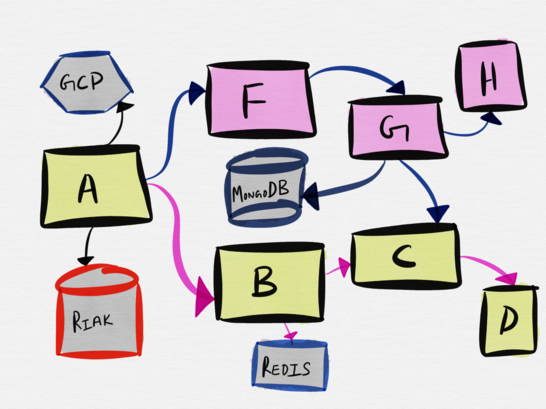
To understand how this idea can be applied in the real world, let's look at the simplified architecture of services that I have been working on as a developer for the last couple of years (we will omit all backup data warehousing, observability tools, and other integrations with third-party components) . What is described below is just a small part of the entire infrastructure; Moreover, it is important to note right away that the boundaries of the given system are extremely conservative - we break it only when this cannot be avoided in order to take into account the requirements . Say, since a load balancer can never perform the functions of a distributed file system or a distributed multilevel caching system, these will be different systems.

It does not matter for us what this or that service does, we just need to know that they are scattered, written in different languages and receive different amounts of traffic. They all use Consul to discover services. All services have their own deployment schedule - a central API server (with versioned endpoints) is deployed several times a day, while service G is deployed about a couple of times a year .
The idea that everythingthese services can be deployed locally on my Macbook during the development of the API service, it can be called ridiculous (and no, I do not). Similarly ridiculous, the idea of deploying all these services in a test environment and launching integration tests for each build can be considered ridiculous. Instead, you need to decide how best to test each individual service, based on the benefits and rates, given the functionality of each service, its guarantees and access patterns.
Unit tests are more like integration tests
Over 80% of the functionality of the central server API includes interaction with MongoDB, so most of the unit tests contain a real connection to the local MongoDB instance. Service E is an LuaJIT authorization proxy that balances traffic arising from three different sources to three different central API instances. One of the critical parts of the functionality of the E service is to check whether a suitable handler is called for each watch value in Consul , and therefore some of the unit tests actually unwind the Consul child process to interact with it, and then “kill” it when the test is completed. Both of the above services examples would be better to test with this type of unit tests, which purists call integration tests.
Integration testing is more like testing in production
Let's look at the services G, H, I, and K (not in the diagram above).
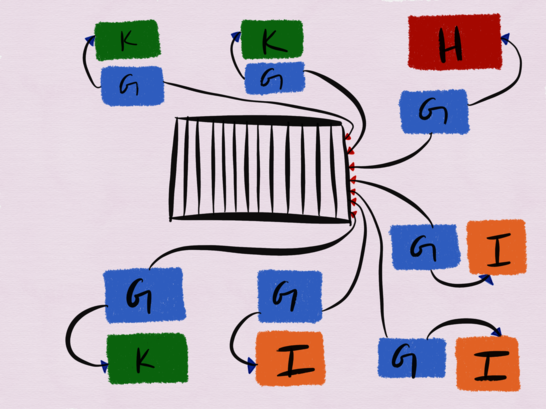
Service G is a Python single-threaded process that subscribes to the Kafka broker topic to read updates received from the user and periodically reloads the service H, I, and K configs. Service G is shared on each of the hosts where H, I, and K are deployed. and at any given time, about 15-20 G service instances are working (only 7 are displayed on the diagram). The main responsibility of the G service is to make sure that the messages it reads from the Kafka topic are transferred to the services H, K and I.
H, K and I are independent services. Service H is the nginx frontend (more specifically, Openresty) to a large distributed system (it is not shown in the diagram), in the heart of which there is a distributed file system, in addition to LevelDB in write through cache mode (recording is done in the main memory and is duplicated in the cache) , MySQL metadata storage, metadata trackers , fetch and crop files on Go. Service K is HAProxy, and Service I is the LuaJIT HTTP server. It also requires that services H, I, and K converge in Kafka configuration updates. Fortunately, at least we do not need guarantees of strict consistency .
Which brings us to the next question: how is it best to test the eventual consistency of these systems?
The way that these services are tested is not to start all these services and conduct end-to-end testing to check if any message sent to the Kafka topic by the G service is used correctly, and if the H, I and K on a specific configuration. A similar procedure, when performed in a "test environment", will not guarantee the correct operation of this design in production, especially if we take into account that:
- K service is HAProxy ( and until very recently, it was impossible to use HAProxy with zero downtime during a restart )
- сервис H в продакшне держит сотни (иногда тысячи) запросов в секунду на процесс, что не так-то просто воспроизвести в тестовом окружении без серьезных вложений в инструменты и автоматизацию загрузки. Кроме того, это потребует от нас тестирования того, приводит ли перезапуск мастер-процесса nginx сервиса H к корректному запуску нескольких свежих рабочих процессов. Постоянной проблемой с сервисом H в продакшне является то, что перезапуск мастер-процесса nginx не всегда приводит к «убийству» старых рабочих процессов, из-за чего старые рабочие процессы продолжают висеть в памяти и отъедать трафик, хотя пост в официальном блоге такую ситуацию называет «крайне редкой»:
In rare cases, problems can arise when too many generations of NGINX workflows are waiting for connections to close, but they are quickly resolved.
In practice, at least for HTTP2, this is the most “rare” until very recently it happened quite often, and, based on my experience, the easiest way to solve this problem was to monitor old nginx workflows and manually kill them. Again, the delay in convergence for the three services H, I and K is what needs to be monitored and what the alert should hang on.
I gave just one example of a system in which integration testing does not bring noticeable benefits, while monitoring could make life much easier. Despite the fact that we could accurately simulate everything types of failures in the environment of integration testing, we still need monitoring, therefore, as a result, all the advantages of using integration testing cannot compensate for the overhead costs of its use and maintenance.
Shaping traffic with Service Meshes
One of the reasons why I really like the service meshes paradigm , which is gaining popularity , is that the proxy allows shaping traffic in such a way that it’s incredibly good for testing. Using a small amount of logic in the proxy to route staging traffic to a staging instance (this can be achieved in such an elementary way as setting a special HTTP header in all requests not from production, or based on the IP address of the incoming request), you can actually use the stack with production for all services except that servicewhich you are testing. This approach allows real integration testing with production services without unnecessary overhead from the support of an overcomplicated test environment.
I believe that integration testing in "test" clusters is practically useless and should disappear - the future is with live traffic. Today I found out that Facebook has been practicing this approach for quite some time. https://t.co/zMrt1YXaB1
The Service Meshes paradigm allows us to unlock the true potential of testing.
Of course, here you need to pay attention to maintaining safety, data integrity, etc., however, I sincerely believe that testing on live traffic with good observability as a result of the tests carried out is the road to the future in the field of microservice testing.
The choice of this testing model will bring another advantage, expressed in stimulating improved isolation between services and designing more advanced systems. Engineers will have to think hard about interservice dependencies and about their possible impact on data integrity, and this will make architecture designers think again. In addition, the ability to test one service with all the others in production will require that the service under test does not have any side effects that could affect any of the dependencies in the upstream or downstream, which I see as quite a reasonable goal when designing the system.
Conclusion
In the framework of this article, I did not set myself the goal of proving the advantage of a particular testing method. I can’t be called an expert on this topic, because my way of thinking was formed under the influence of the types of systems that I worked with, and the limitations that we were in left their mark on it (mainly, it was an extremely limited time and resources), as well as the organizational structure of the companies themselves. It is quite possible that in other scenarios and circumstances the ideas voiced in my article will not carry any meaning.
Listen to the so-called "experts", but also turn on your head more often. “Experts” often provide overly generalized advice. Therefore, think with your own head and do not be lazy!
Given how wide the spectrum of testing is, it becomes clear that there is no single “truly true" way to test in the right way. Any approach implies the need to compromise and sacrifice.
Ultimately, each team is an expert in its own circumstances and needs, and your thinking is not something that should be outsourced.
We love such large-scale conceptual discussions, especially seasoned with our own examples, because not only individual developers, but almost all project teams are involved in solving such issues. We invite specialists whose experience already allows us to discuss philosophical issues of software development, to speak at RIT ++ 2018 .