Application Evolution or Where We Go
It would be too academic to call the article "The Evolution of Applied Information Systems and the Prospects for the Development of Their Architecture", and after all there will be a very brief squeeze out of real practical experience, possible options for the development of technologies that have caused their needs and solutions. I hope that the article will help to generalize and rethink a wide range of tasks related to applied IP, and I want to immediately clarify what I mean by these terms. IP - a system that provides processing, transmission and storage of data. This is far from all programming, but nowadays IPs are most often associated with web and mobile applications, although they do not completely coincide with them, the equal sign between the UI and IPs cannot be put all the more. I beg everyone to look at the question as broadly as possible and join the discussion in the comments. And further,
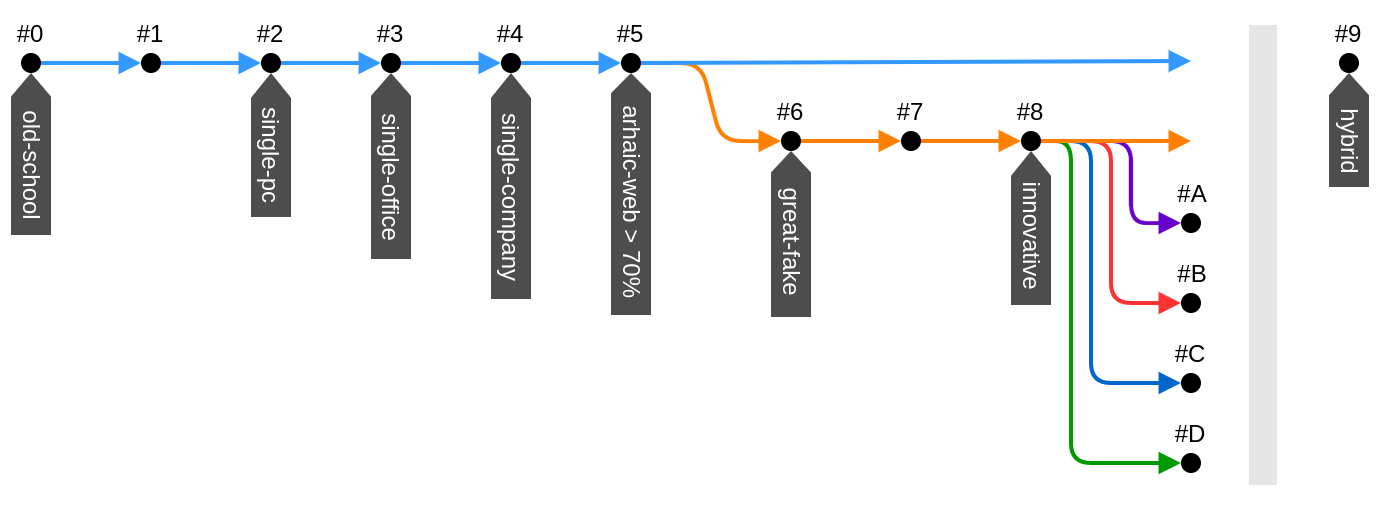
Branches in technology have happened many times in history, but a period of uncertainty always follows a stage of sustainable development, when non-essential branches go into the shadows, and relevant features are combined into the most viable hybrid. To begin with, we will briefly follow how IP has evolved since its inception. For the memories to flood, we need only 9 lines and a picture.
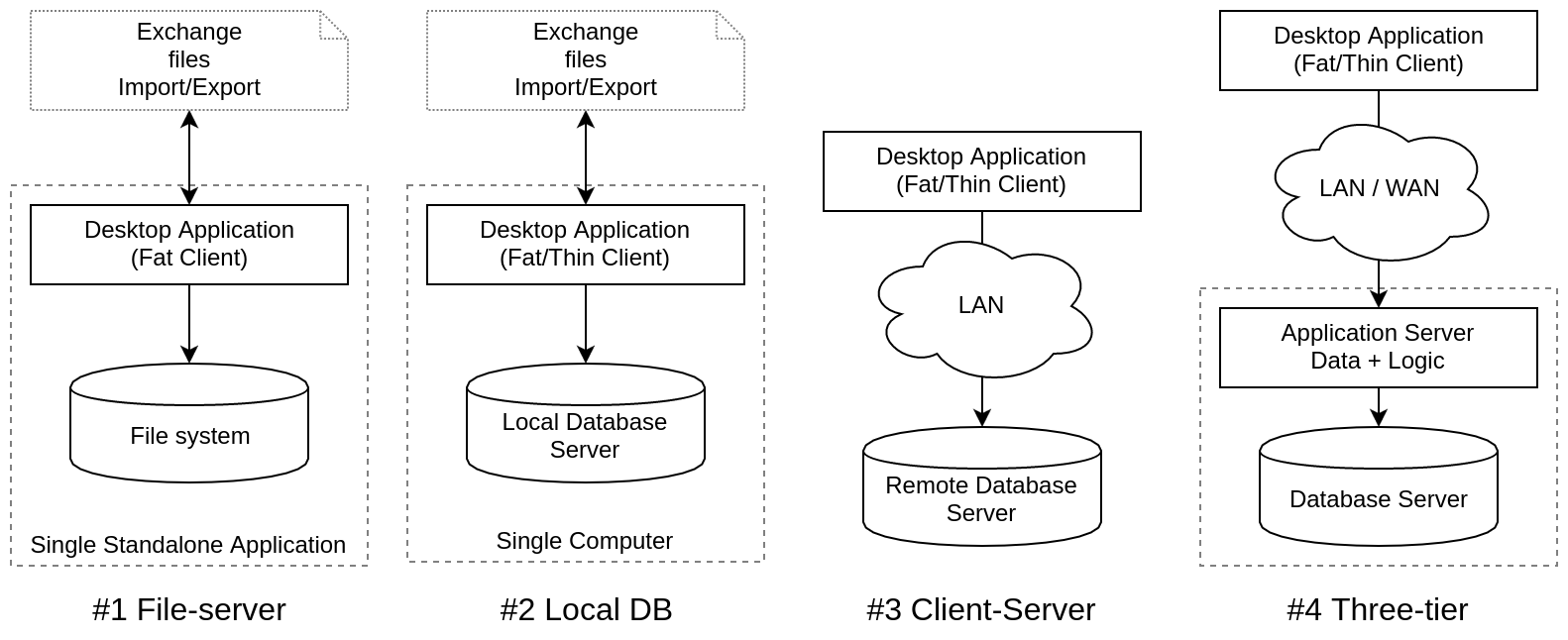
| Architecture | Key Features | Exchange |
|---|---|---|
| # 0 Data files | Everyone stored their data in files of various unknown formats | files |
| # 1 File-server | Database engines working in the same process as the application | files |
| # 2 Local DB | DBMSs stand out in separate processes - DBMS servers | IPC |
| # 3 Client-Server | DBMSs are available on LAN for different types of workstations (client workstations) | Rpc |
| # 4 Three-tier | The application server layer, 3-tier, work from remote offices stood out | Rpc |
| # 5 Web-client | Thin clients appeared to access data from a web browser | HTTP |
| # 6 Web 2.0 | Partial interactive reloading of elements through AJAX, Comet, SSE | Ajax |
| # 7 SPA / WebApp | Full-featured browser applications without page reloading | Ajax |
| # 8 PWA & Mobile | Progressive Web Application and Mobile Applications | Https |
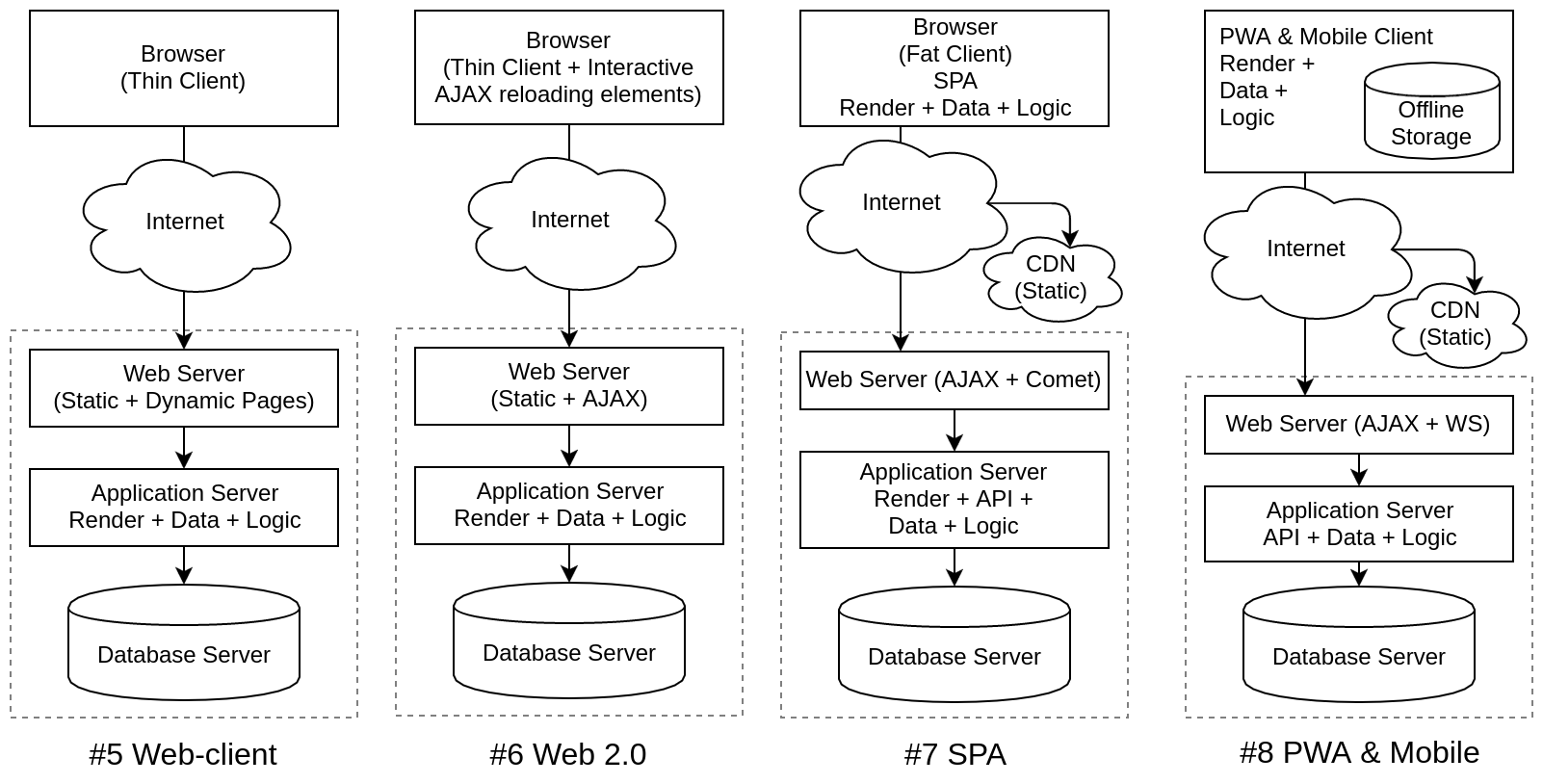
I did not indicate the existence time for architectures, because even now almost all of the listed solutions exist in their niches in parallel. For modern IPs, the prevailing technology is still # 5, i.e. regular web pages with reloading by links (thin client) and all the logic on the server. For many tasks, more is not needed. At the forefront of # 8, here web applications and mobile applications have merged architecturally, although they have many differences in technology and implementation. What next? Trends have already been outlined: the server is an API, databases on the client, rendering on the client, rich GUI, work offline, high loads and many users. But technologically, these needs are met by so many different platforms that branching has occurred. This is equally true for the web and mobile applications. Need to say,
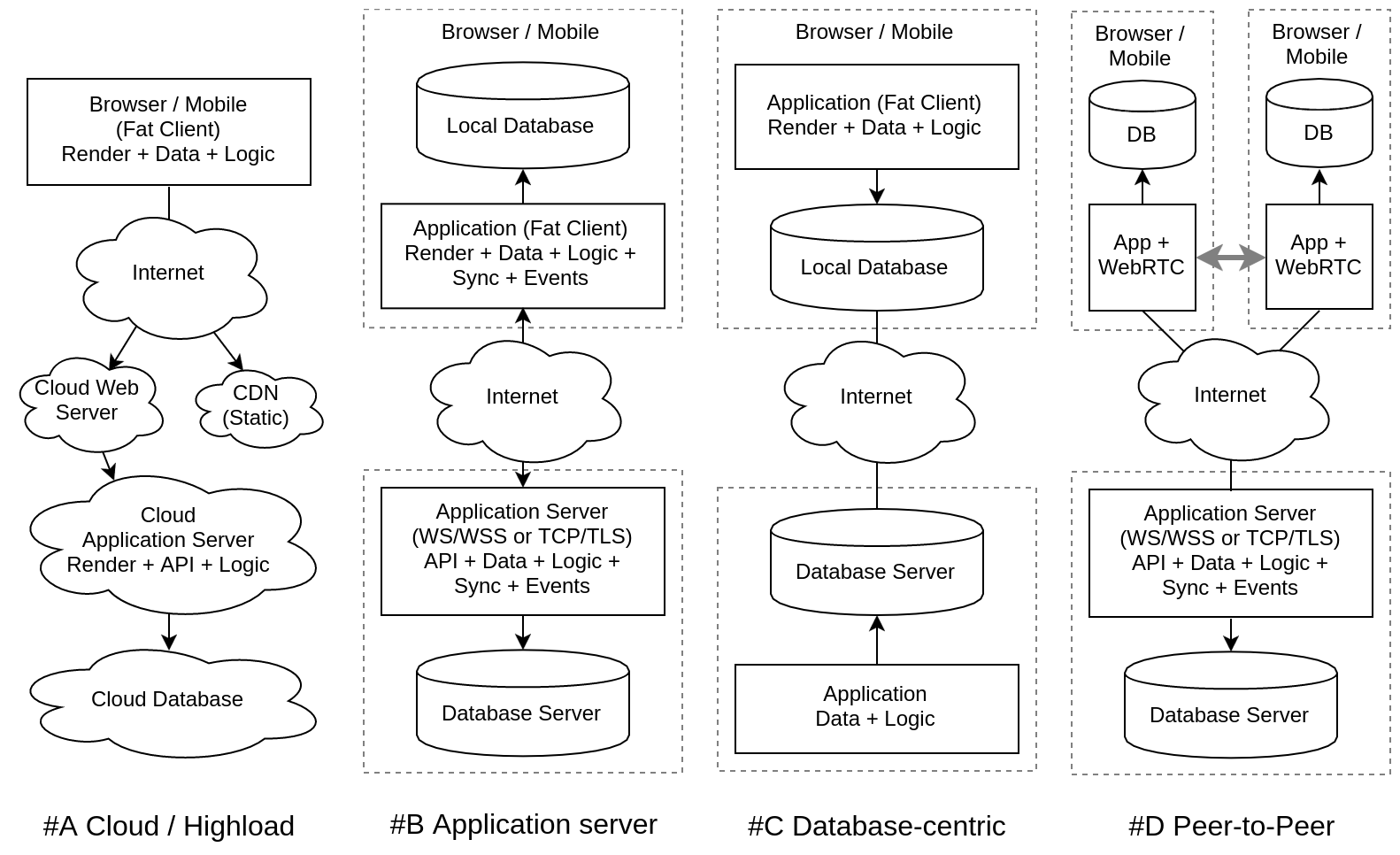
Serving High Cloud Loads (#A Cloud Highload)
Advantages : Clouds do a great job of scaling, using the REST principle, applications can serve tens of millions of subscribers if they abandon the state, i.e. server processes do not store state in memory, all network calls are independent and do not transfer the session to any state.
Disadvantages : In real applications, they often move away from REST precisely because a state is needed to solve the problem. It turns out a pseudo-REST , not scalable, but with a bunch of restrictions. And most importantly, completely unsuitable for applications that interact interactively with the user or provide interaction between users.
Conclusion : In many cases, this is the optimal solution: publishing content, information resources, media can be effectively built in the cloud, but for complex applications with databases and interactivity, this is a step back from architecture # 8.
Application Servers (#B Application servers)
Advantages : The web server takes the place of the application server, i.e. it is not the application that runs under the control of the web server, but the web server is embedded in the application or application server. Moreover, to increase efficiency, HTTP / HTTPS can be replaced by specialized TCP / TLS protocols. This is especially true for mobile and desktop applications, which makes it possible to build RPC, event bus, database synchronization.
Disadvantages : Such applications do not yet have universal cloud solutions, but everything goes to the point that they will appear soon. Before that, you need to invent your own technology stack and build a private cloud yourself. It is difficult to maintain and maintain. In addition, the synchronization of the database on the server and client is done manually, through the application, usually by the super efforts of the developers, and it is usually not possible to reuse such solutions.
Conclusion : This direction is now available only to large companies that need to serve millions of users , create interactive applications or R&D laboratories preparing similar solutions for the mass user.
DB-centric approach (#C Database-centric)
Advantages : It is very attractive to put the database ahead of the application and set up synchronization (partial replication) between the databases. Thus, we have DBMSs built into applications and work not with the server, but with the local database. Many methods have already been invented for this: optimistic replication, operational transformation, conflict-free replicated data type, because DBMSs have existed for a long time and have learned to scale.
Disadvantages : Communication between applications only through data clearly limits our capabilities. This is a reduction of everything to work with the base. But what about event passing, integration at the API level, calling remote procedures? All this must be forgotten with the DB-centric approach.
Conclusion : For a certain class of tasks, this is a smart solution, and together with the introspection and scaffolding of UI, such an architecture will automatically “roll out” the very wide range of applications of more complex competitors that integrate using the API and require all the time to write the interaction programmatically.
Peer-to-peer or peer-to-peer interaction (#D Peer-to-Peer)
Advantages : This will offload servers that will only perform the binding / broker function. Local interaction between users is often more effective than through a remote server, especially with large data streams. It gives hope for the anonymity of the exchange of private data.
Disadvantages : The issue of “trust” in peer-to-peer networks is still not completely overcome. It will not work to build distributed IPs only on P2P, the servers will still be in this scheme. So far, there are no widespread protocols, libraries, frameworks, and other software tools for implementation to the extent necessary for building applied information systems.
Conclusion : Elements of peer-to-peer networks will be embedded in a centralized IP.
Summary of Trends
What hybrid will come out as a result of the merger of these areas is not yet clear, but it is already possible to build several assumptions and, at a minimum, highlight trends.
It is already obvious that the branching of architectures at this stage will occur, first of all, due to the integration of system components into the application itself:
- Embedded communication server application: HTTP / WS, HTTPS / WSS, TCP / TLS, etc.
- Built-in DBMS with automatic synchronization.
- By analogy, one can recall another IP function, this is data processing or computing. So, built-in applications of distributed computing systems will happen sooner or later. After all, user devices in our time have great computing power and not use them for distributed data processing, this is an inadmissible architectural omission.
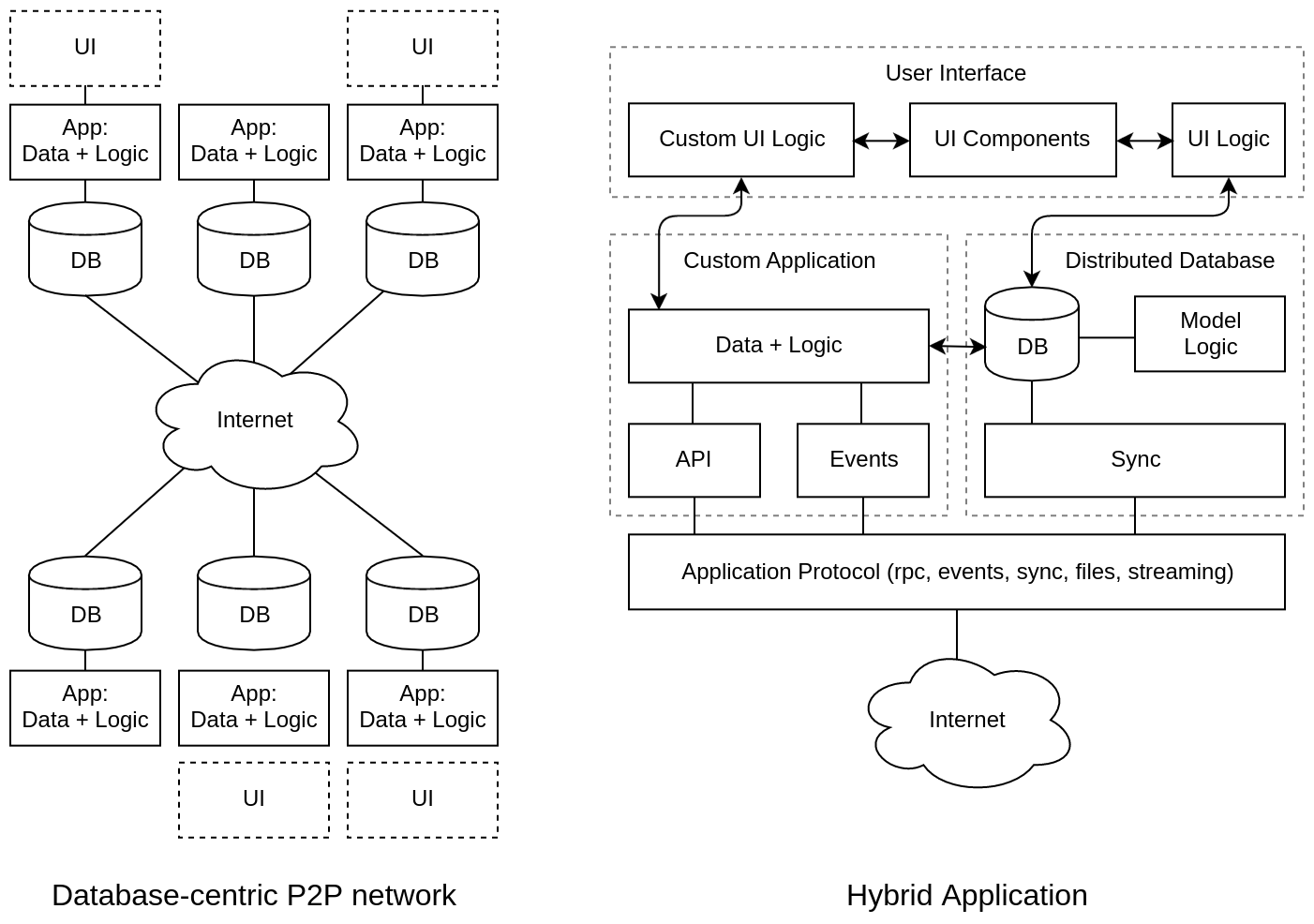
Personally, I want to combine the Data-centric architecture (which, according to the Pareto principle, will cover 80% of the needs with full automation) with the application server (which will make it possible to integrate at the API or event bus level for the remaining 20% of cases). For this, the IP interaction protocol must simultaneously support 5 types of interaction : RPC, REST, Event BUS, DB Sync, Binary streaming. Our team is working on such a comprehensive solution now.
In addition to four large architectures, you can build hybrids from a combination of individual features:
- Synchronization - synchronization of data structures between applications in distributed systems in a time mode close to real;
- Offline - the ability to work with part of the data stored in local storage in a browser or mobile application, and when going online, synchronize;
- Interactivity - the possibility of two-way exchange of events with the server and the construction of reactive components: UI, database cursors, application logic, network exchange, etc .;
- Low latency (or High availability) - the characteristic of readiness for processing requests and optimizing the response time of the server (not to be confused with bandwidth);
- Highload - processing an intensive stream of requests (request per second), which includes their frequency, size, priority, waiting time in the queue, lifetime and resources for servicing;
- High connectivity - a large number of competitive (simultaneous and long-lived) client connections to the server with the possibility of two-way data exchange at the initiative of either side;
- High interconnection - a characteristic of the intensity of interaction between competitive compounds, as well as the size of the interacting groups of compounds;
- Scalability - a group of characteristics of horizontal and vertical scaling, providing transparency of scaling for software and hardware (without rewriting the code);
- Big data - the ability to process large amounts of data, for example, streaming data processing or building queries to distributed storages;
- Big memory and in-memory DB - high utilization of memory or transferring databases completely to RAM with additional indexes for quick query execution;
- Integration flexibility - a characteristic of the flexibility and ease of integration of solutions based on introspection, automatic interface binding, scaffolding and dynamic interpretation of metamodels .
In order that we all understand the trends, I propose to answer questions, and I will also be grateful for constructive criticism and comments.
Only registered users can participate in the survey. Please come in.
What are the most promising scenarios for the evolution of IP?
- 22% Old Web 11
- 4% Easy scaling in the cloud of passive applications without interactivity 2
- 24% Private Cloud Application Server for large projects and companies 12
- 30% A new type of cloud that supports interactive two-way communication 15
- 32% Interactive application servers will be available for small projects 16
- 16% DB-centric approach will be available to small projects 8
- 34% A new type of cloud with database-centric applications as a service 17
- 38% Applied IPs will be implemented on the basis of peer-to-peer P2P interaction 19
What are the most popular technological stack features?
- 57.5% Data Sync 42
- 49.3% Work offline 36
- 42.4% Interactivity 31
- 32.8% Low Latency and Availability 24
- 41% High Load 30
- 20.5% A large number of compounds 15
- 17.8% High intensity of interaction of compounds 13
- 54.7% Easy scalability 40
- 32.8% Big Data 24
- 15% Big memory and in-memory DB 11
- 52% Easy to integrate solutions 38
What is your personal attitude to the emergence of new architectures and technologies?
- 23.5% Everything suits, does not interest the new 20
- 60% I look forward to all the new and try 51
- 16.4% Participate in OpenSource projects, contribute to the future 14