Python program for statistical text analysis
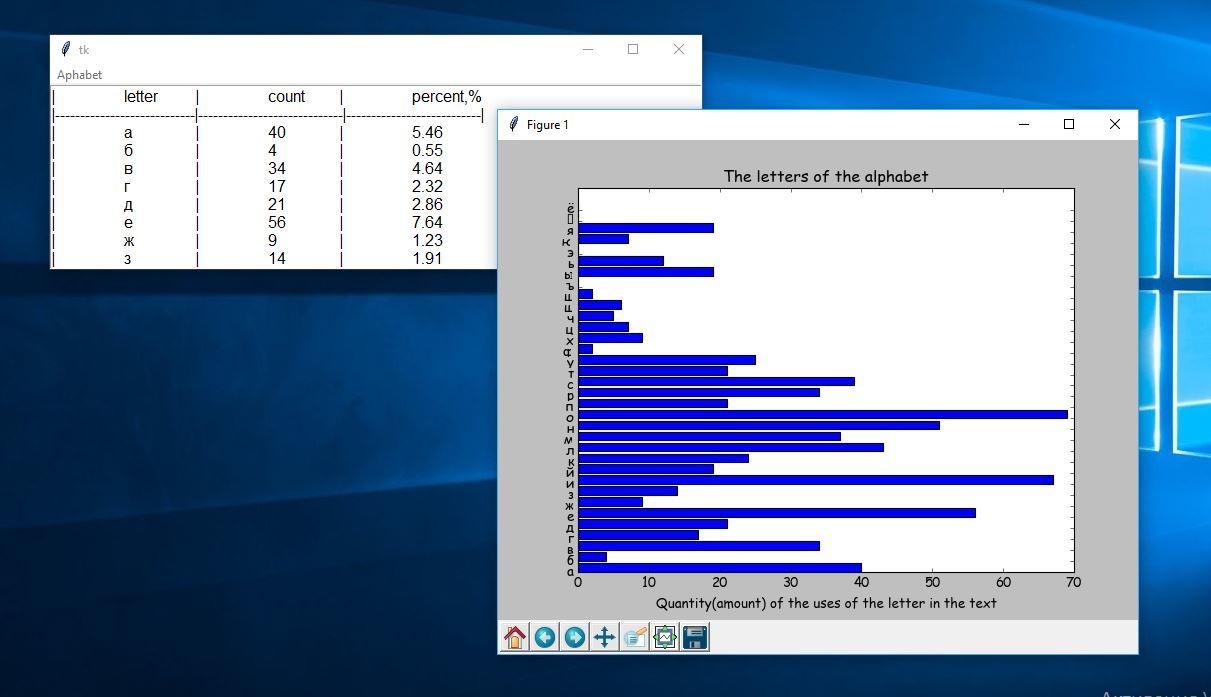
The task of calculating the frequency of use of certain letters in English and Russian texts is one of the stages of linguistic-statistical analysis. There is no Python program in the Catalog of Linguistic Programs and Resources in the Network for solving this problem.
On the Python forums, there are separate parts of such a program, but they focus on one language, mainly English. Given this circumstance, I developed a program for statistical processing, for both Russian and English texts.
Import and initial variables
import matplotlib.pyplot as plt; plt.rcdefaults()
import numpy as np
import matplotlib.pyplot as plt
from tkinter import *
from tkinter.filedialog import *
from tkinter.messagebox import *
import fileinput
import matplotlib as mpl
mpl.rcParams['font.family'] = 'fantasy'
mpl.rcParams['font.fantasy'] = 'Comic Sans MS, Arial'
Opening a file with English text
def w_open_ing():
aa=ord('a')
bb=ord('z')
op = askopenfilename()
main(op,aa,bb)
Opening a file with Russian text
def w_open_rus():
aa=ord('а')
bb=ord('ё')
op = askopenfilename()
main(op,aa,bb)
Universal data processing for both languages
def main(op,aa,bb):
alpha = [chr(w) for w in range(aa,bb+1)] #обратное преобразование кода в символы
f = open(op , 'r')
text = f.read()
f.close()
alpha_text = [w.lower() for w in text if w.isalpha()] #выбор только букв и привидение их к нижнему регистру
k={} #создание словаря для подсчета каждой буквы
for i in alpha: #заполнение словаря
alpha_count =0
for item in alpha_text:
if item==i:
alpha_count = alpha_count + 1
k[i]= alpha_count
z=0
for i in alpha: #графическая визуализация данных в поле формы
z=z+k[i]
a_a=[]
b_b=[]
t= ('|\tletter\t|\tcount\t|\tpercent,%\t\n')
txt.insert(END,t)
t=('|----------------------------|-----------------------------|---------------------------|\n')
txt.insert(END,t)
for i in alpha: #графическая визуализация данных в поле формы
persent = round(k[i] * 100.0 / z,2)
t=( '|\t%s\t|\t%d\t|\t%s\t\n' % (i, k[i], persent))
txt.insert(END,t)
a_a.append(i)
b_b.append(k[i])
t=('|----------------------------|-----------------------------|---------------------------|\n' )
txt.insert(END,t)
t=('Total letters: %d\n' % z)
txt.insert(END,t)
people=a_a #подготовка данных для построения диаграммы
y_pos = np.arange(len(people))
performance =b_b #подготовка данных для построения диаграммы
plt.barh(y_pos, performance)
plt.yticks(y_pos, people)
plt.xlabel('Quantity(amount) of the uses of the letter in the text')
plt.title('The letters of the alphabet')
plt.show() #визуализация диаграммы
Field cleaning
def clear_text():
txt.delete(1.0, END)
Writing data from a field to a file
def save_file():
save_as = asksaveasfilename()
try:
x =txt.get(1.0, END)
f = open(save_as, "w")
f.writelines(x.encode('utf8'))
f.close()
except:
pass
Program closing
def close_win():
if askyesno("Exit", "Do you want to quit?"):
tk.destroy()
Tkinter standard interface
tk= Tk()
main_menu = Menu(tk)
tk.config(menu=main_menu)
file_menu = Menu(main_menu)
main_menu.add_cascade(label="Aphabet", menu=file_menu)
file_menu.add_command(label="English text", command= w_open_ing)
file_menu.add_command(label="Russian text", command= w_open_rus)
file_menu.add_command(label="Save file", command=save_file)
file_menu.add_command(label="Cleaning", command=clear_text)
file_menu.add_command(label="Exit", command=close_win)
txt = Text(tk, width=72,height=10,font="Arial 12",wrap=WORD)
txt.pack()
tk.mainloop()
Benefits
- The program is written in Python, which simplifies its use in BigARTM and Gensim.
- It takes into account the difference between the Russian letters "e" and "e".
- It has a graphical interface and at the same time "freely distributes".