Data Oriented Design in practice
Recently, more and more often you can find a discussion of an interesting, but not very popular paradigm - the so-called Data Oriented Design ( DOD ). If you are looking for a job related to high-performance computing, be prepared for related issues. But I was very very surprised to learn that some of my colleagues did not hear about this approach and after a short discussion they were skeptical. In this article I will try to compare the traditional OOP approach with DOD .
This article was conceived as an attempt to compare different approaches without trying to explain their essence. On Habré there are some articles on a subject, for example this . You should also watch the video from the CppCon conference . But in a nutshell, DOD is a way to handle data in a cache friendly manner. It sounds incomprehensible, an example will explain better.
The second test runs 30% faster (in VS2017 and gcc7.0.1). But why?
The size of the structure
The example above demonstrates the advantages of using SoA (Struct of Arrays) instead of AoS (Array of Structs), but this example is from the category
To understand the reality of applying the approach, I decided to write a more or less complex code using both techniques and compare the results. Let it be a 2d simulation of solids - we will create N convex polygons, set parameters - mass, speed, etc. and see how many objects we can simulate staying at around 30 fps.
The source code for the first version of the program can be taken from this commit . Now we will briefly go over the code.
For simplicity, the program is written for Windows and uses DirectX11 for rendering. The purpose of this article is to compare performance on the processor, so we will not discuss graphics. The class
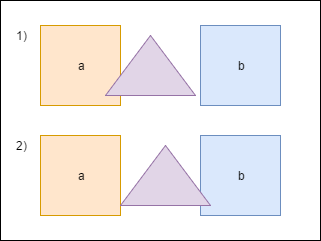
When the triangle intersects the figure a , we must move it a little to avoid overlapping figures. Also we have to recount
The heart of our program is the method
Each frame, we call a
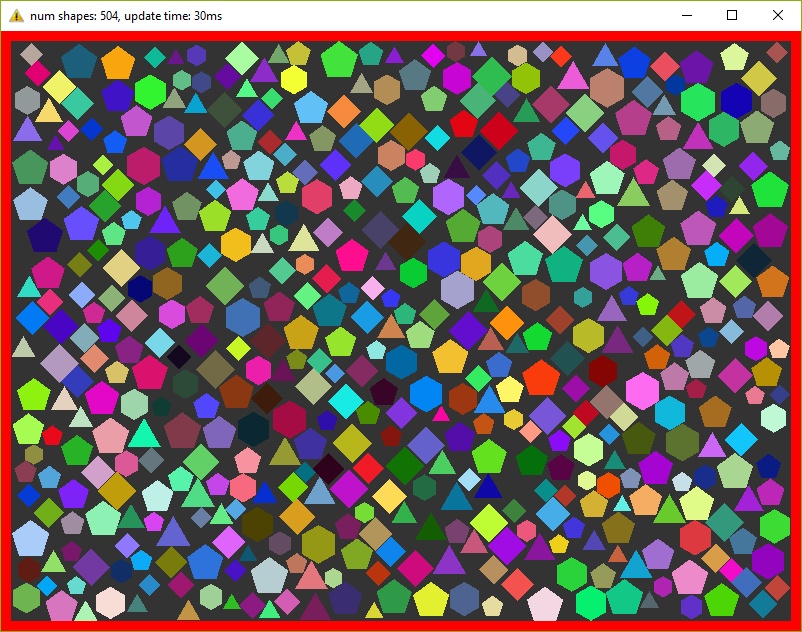
On my old laptop, this program calculates 500 pieces maximum, before fps starts to fall below 30. Fuuuu, only 500 ???! I agree, a little, but do not forget that every frame we repeat the calculations 20 times.
I think it’s worth diluting the article with screenshots, so here:
I mentioned that I want to conduct tests on a program as close to reality as possible. What we wrote above is not used in reality - to check each figure with each sooo slowly. To speed up calculations, a special structure is usually used. I suggest using an ordinary 2d grid - I called it
The commit of the second version of the program can be seen here . A new class has appeared
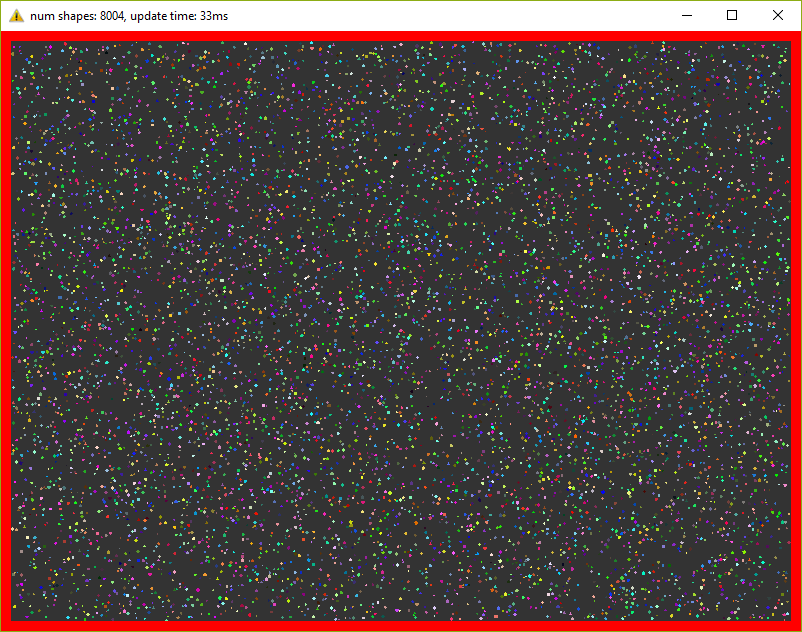
This version already holds 8000 figures at 30 fps (do not forget about 20 iterations in each frame)! I had to reduce the figures by 10 times so that they fit in the window.
Today, when even processors with four cores are installed on phones, it is simply silly to ignore multithreading. In this last optimization, we will add a pool of threads and divide the main tasks into equal tasks. So, for example, a method
Separation of the main tasks added a little headache. So, for example, if a figure crosses the border of a cell in the grid, then it will be in several cells at the same time:
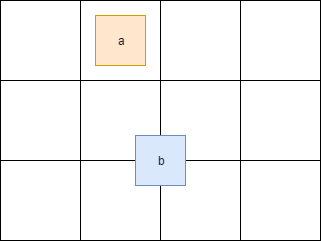
Here the figure a is in one cell, while b is in four at once. Therefore, access to these cells must be synchronized. You also need to synchronize access to some fields of the class
By running this version, I can observe 13,000 figures at 30 fps. For so many objects I had to enlarge the window! And again - in each frame, we repeat the simulation 20 times.

What I wrote above I call the traditional approach - I have been writing this code for many years and I read mostly similar code. But now we will kill the structure
And we pass this structure like this:
Those. instead of specific figures, their indices are transferred and in the method the necessary data is taken from the necessary vectors.
This version of the program produces 500 figures at 30 fps, i.e. no different from the very first version. This is due to the fact that measurements are carried out on a small amount of data and, moreover, the heaviest method uses almost all fields of the structure.
Further without pictures, as they are exactly the same as before.
Everything is as before, we change only AoS to SoA . The code is here . The result is better than it was before - 9,500 figures (there were 8,000), i.e. the difference in performance is about 15%.
Again, take the old code, change the structure and get 15,000 figures at 30 fps. Those. performance increase of about 15%. The source code for the final version is here .
Initially, the code was written for myself in order to test various approaches, their performance and convenience. As the results showed, a small change in the code can give a rather tangible increase. Or it may not, it may even be the other way around - productivity will be worse. So for example, if we need only one instance, then using the standard approach we will read it from memory only once and will have access to all fields. Using the same vector structure, we will be forced to query each field individually, with cache-miss on each request. Plus, readability worsens a bit and the code gets complicated.
Therefore, it is impossible to answer unequivocally whether it is worth moving to a new paradigm for everyone and everyone. When I worked in a game dev on a game engine, a 10% increase in productivity is an impressive figure. When I wrote user utilities such as a launcher, then applying the DOD approach would only cause bewilderment of colleagues. In general, profile, measure and draw conclusions yourself :).
What is a DOD?
This article was conceived as an attempt to compare different approaches without trying to explain their essence. On Habré there are some articles on a subject, for example this . You should also watch the video from the CppCon conference . But in a nutshell, DOD is a way to handle data in a cache friendly manner. It sounds incomprehensible, an example will explain better.
Example
#include
#include
#include
using namespace std;
using namespace std::chrono;
struct S
{
uint64_t u;
double d;
int i;
float f;
};
struct Data
{
vector vu;
vector vd;
vector vi;
vector vf;
};
int test1(S const & s1, S const & s2)
{
return s1.i + s2.i;
}
int test2(Data const & data, size_t const ind1, size_t const ind2)
{
return data.vi[ind1] + data.vi[ind2];
}
int main()
{
size_t const N{ 30000 };
size_t const R{ 10 };
vector v(N);
Data data;
data.vu.resize(N);
data.vd.resize(N);
data.vi.resize(N);
data.vf.resize(N);
int result{ 0 };
cout << "test #1" << endl;
for (uint32_t i{ 0 }; i < R; ++i)
{
auto const start{ high_resolution_clock::now() };
for (size_t a{ 0 }; a < v.size() - 1; ++a)
{
for (size_t b{ a + 1 }; b < v.size(); ++b)
{
result += test1(v[a], v[b]);
}
}
cout << duration{ high_resolution_clock::now() - start }.count() << endl;
}
cout << "test #2" << endl;
for (uint32_t i{ 0 }; i < R; ++i)
{
auto const start{ high_resolution_clock::now() };
for (size_t a{ 0 }; a < v.size() - 1; ++a)
{
for (size_t b{ a + 1 }; b < v.size(); ++b)
{
result += test2(data, a, b);
}
}
cout << duration{ high_resolution_clock::now() - start }.count() << endl;
}
return result;
} The second test runs 30% faster (in VS2017 and gcc7.0.1). But why?
The size of the structure
Sis 24 bytes. My processor (Intel Core i7) has a 32KB cache per core with a 64B cache line. This means that when requesting data from memory, only two structures will completely fit in one cache line S. In the first test, I read only one intfield, i.e. with one memory access, in one cache line there will be only 2 (sometimes 3) of the fields we need. In the second test, I read the same intvalue, but from a vector. std::vectorguarantees data consistency. This means that when accessing memory in one cache line there will be 16 (64B / sizeof(int) = 16) the values we need. It turns out that in the second test we access memory less often. A memory access, as you know, is a weak link in modern processors.How are things in practice?
The example above demonstrates the advantages of using SoA (Struct of Arrays) instead of AoS (Array of Structs), but this example is from the category
Hello World, i.e. far from real life. In real code, there are a lot of dependencies and specific data, which, probably, will not give a performance gain. In addition, if in tests we refer to all fields of the structure, there will be no difference in performance. To understand the reality of applying the approach, I decided to write a more or less complex code using both techniques and compare the results. Let it be a 2d simulation of solids - we will create N convex polygons, set parameters - mass, speed, etc. and see how many objects we can simulate staying at around 30 fps.
1. Array of Structures
1.1. The first version of the program
The source code for the first version of the program can be taken from this commit . Now we will briefly go over the code.
For simplicity, the program is written for Windows and uses DirectX11 for rendering. The purpose of this article is to compare performance on the processor, so we will not discuss graphics. The class
Shapethat represents the physical body looks like this:Shape.h
class Shape
{
public:
Shape(uint32_t const numVertices, float radius, math::Vec2 const pos, math::Vec2 const vel, float m, math::Color const col);
static Shape createWall(float const w, float const h, math::Vec2 const pos);
public:
math::Vec2 position{ 0.0f, 0.0f };
math::Vec2 velocity{ 0.0f, 0.0f };
math::Vec2 overlapResolveAccumulator{ 0.0f, 0.0f };
float massInverse;
math::Color color;
std::vector vertices;
math::Bounds bounds;
}; - The purpose
positionandvelocity, I think, is obvious.vertices- the vertices of the figure given randomly. bounds- This is a bounding box that fully contains a shape - used to pre-check intersections.massInverse- unit divided by mass - we will use only this value, therefore we will store it, instead of mass.color- color - is used only during rendering, but is stored in an instance of the shape, is set randomly.overlapResolveAccumulatorsee explanation below.
When the triangle intersects the figure a , we must move it a little to avoid overlapping figures. Also we have to recount
bounds. But after moving the triangle intersects another figure - b , and again we need to move it and recount again bounds. Notice that after the second move, the triangle will again be above the figure a . To avoid repeated calculations, we will store the value by which you need to move the triangle in a special battery - overlapResolveAccumulator- and later we will move the figure to this value, but only once. The heart of our program is the method
ShapesApp::update(). Here is a simplified version of it:ShapesApp.cpp
void ShapesApp::update(float const dt)
{
float const dtStep{ dt / NUM_PHYSICS_STEPS };
for (uint32_t s{ 0 }; s < NUM_PHYSICS_STEPS; ++s)
{
updatePositions(dtStep);
for (size_t i{ 0 }; i < _shapes.size() - 1; ++i)
{
for (size_t j{ i + 1 }; j < _shapes.size(); ++j)
{
CollisionSolver::solveCollision(_shapes[i].get(), _shapes[j].get());
}
}
}
}Each frame, we call a
ShapesApp::updatePositions()method that changes the position of each figure and calculates a new one Shape::bounds. Then we check each figure with each other at the intersection - CollisionSolver::solveCollision(). I used Separating Axis Theorem (SAT) . We do all these checks NUM_PHYSICS_STEPSonce. This variable serves several purposes - firstly, the physics is more stable, and secondly, it limits the number of objects on the screen. C ++ is fast, very fast, and without this variable we will have tens of thousands of shapes, which will slow down the rendering. I used NUM_PHYSICS_STEPS = 20On my old laptop, this program calculates 500 pieces maximum, before fps starts to fall below 30. Fuuuu, only 500 ???! I agree, a little, but do not forget that every frame we repeat the calculations 20 times.
I think it’s worth diluting the article with screenshots, so here:
1.2. Optimization Number 1. Spatial Grid
I mentioned that I want to conduct tests on a program as close to reality as possible. What we wrote above is not used in reality - to check each figure with each sooo slowly. To speed up calculations, a special structure is usually used. I suggest using an ordinary 2d grid - I called it
Grid- which consists of NxM cells - Cell. At the beginning of calculations, we will record in each cell the objects that are in it. Then we just need to go over all the cells and check the intersection of several pairs of objects. I have repeatedly used this approach in releases and it has proven itself - it is written very quickly, is easily debugged, and is easy to understand. The commit of the second version of the program can be seen here . A new class has appeared
Gridand the method has changed a bit ShapesApp::update()- now it calls grid methods to check for intersections. This version already holds 8000 figures at 30 fps (do not forget about 20 iterations in each frame)! I had to reduce the figures by 10 times so that they fit in the window.
1.3. Optimization number 2. Multithreading.
Today, when even processors with four cores are installed on phones, it is simply silly to ignore multithreading. In this last optimization, we will add a pool of threads and divide the main tasks into equal tasks. So, for example, a method
ShapesApp::updatePositionsthat previously ran through all the figures, establishing a new position and recounting bounds, now runs only along part of the figures, thereby reducing the load on one core. The pool class was honestly copy-paste from here . In tests, I use four threads (counting the main one). The finished version can be found here . Separation of the main tasks added a little headache. So, for example, if a figure crosses the border of a cell in the grid, then it will be in several cells at the same time:
Here the figure a is in one cell, while b is in four at once. Therefore, access to these cells must be synchronized. You also need to synchronize access to some fields of the class
Shape. To do this, we added std::mutexin Shapeand Cell. By running this version, I can observe 13,000 figures at 30 fps. For so many objects I had to enlarge the window! And again - in each frame, we repeat the simulation 20 times.
2. Structure of Arrays
2.1. The first version of the program
What I wrote above I call the traditional approach - I have been writing this code for many years and I read mostly similar code. But now we will kill the structure
Shapeand see if this small modification can affect performance. To everyone's joy, refactoring was not complicated, even trivial. Instead, Shapewe will use a structure with vectors:Shape.h
struct ShapesData
{
std::vector positions;
std::vector velocities;
std::vector overlapAccumulators;
std::vector massesInverses;
std::vector colors;
std::vector> vertices;
std::vector bounds;
}; And we pass this structure like this:
solveCollision(struct ShapesData & data, std::size_t const indA, std::size_t const indB);Those. instead of specific figures, their indices are transferred and in the method the necessary data is taken from the necessary vectors.
This version of the program produces 500 figures at 30 fps, i.e. no different from the very first version. This is due to the fact that measurements are carried out on a small amount of data and, moreover, the heaviest method uses almost all fields of the structure.
Further without pictures, as they are exactly the same as before.
2.2. Optimization Number 1. Spatial Grid
Everything is as before, we change only AoS to SoA . The code is here . The result is better than it was before - 9,500 figures (there were 8,000), i.e. the difference in performance is about 15%.
2.3. Optimization Number 2. Multithreading
Again, take the old code, change the structure and get 15,000 figures at 30 fps. Those. performance increase of about 15%. The source code for the final version is here .
3. Conclusion
Initially, the code was written for myself in order to test various approaches, their performance and convenience. As the results showed, a small change in the code can give a rather tangible increase. Or it may not, it may even be the other way around - productivity will be worse. So for example, if we need only one instance, then using the standard approach we will read it from memory only once and will have access to all fields. Using the same vector structure, we will be forced to query each field individually, with cache-miss on each request. Plus, readability worsens a bit and the code gets complicated.
Therefore, it is impossible to answer unequivocally whether it is worth moving to a new paradigm for everyone and everyone. When I worked in a game dev on a game engine, a 10% increase in productivity is an impressive figure. When I wrote user utilities such as a launcher, then applying the DOD approach would only cause bewilderment of colleagues. In general, profile, measure and draw conclusions yourself :).