Verification of photos in retail using Computer vision
Introduction
As part of the loan program, the bank cooperates with many retail stores.
One of the key elements of the loan application is a photograph of the borrower - the agent of the partner store takes a photograph of the buyer; Such a photo gets into the client’s “personal business” and is used further as one of the ways to confirm his presence at the point at the time of applying for a loan.
Unfortunately, there is always a risk of unfair behavior of an agent who can transfer unreliable photos to the bank - for example, pictures of clients from social networks or a passport.
Usually, banks solve this problem by verifying the photographs — office workers look at the photographs and try to identify unreliable images.
We wanted to try to automate the process and solve the problem using neural networks.
Task formalization
We investigated only photos in which there are people. To cut out extraneous images without faces, you can use the open library Dlib .
For clarity, we give examples of photographs (bank employees in the pictures):

Figure 1. Photos from the point of sale

Figure 2. Photos from social networks

Figure 3. Passport photos
So, we needed to write a model analyzing the background of the photo. The result of her work was to determine the likelihood that a photo was taken at one of the points of sale of our partners. We identified three ways to solve this problem: segmentation, comparison with other photos at the same point of sale, classification. Consider each of them in more detail.
A) Segmentation
The first thing that came to mind was to solve this problem by segmentation of the image, identifying areas with the background of partner stores.
Minuses:
- Training sample preparation takes too much time.
- A service built on such a model will not work quickly.
It was decided to return to this method only in case of rejection of alternatives. Spoiler: not returned.
B) Comparison with other photos at the same point of sale.
Together with the photo, we receive information about which retail store it was made at. That is, we have groups of shots taken at the same points of sale. The total number of photographs in each group varies from a few to a few thousand.
Another idea appeared: to build a model that will compare two photos and predict the likelihood that they were taken at one point of sale. Then we will be able to compare the new photo obtained with the existing photos in the same store. If it turns out to be similar to them, then the picture is exactly reliable. If the picture is knocked out of the overall picture, we additionally send it for manual verification.
Minuses:
- Unbalanced sample.
- The service will work for a long time if there are a lot of photos at the point of sale.
- When a new point of sale appears, you need to retrain the model.
Despite the drawbacks, we implemented the model from the article , using the blocks of the VGG-16 and ResNet-50 neural networks. And ... received a percentage of correct answers not much higher than 50% in both cases: (
B) Classification!
The most tempting idea was to make a simple classifier that would divide the photos into 3 groups: photos from points of sale, from passports and from social networks. It remains only to check whether this approach will work. Well, still spend some time preparing data for training.
Data preparation
In the dataset of images from social networks using the Dlib library, only those photos in which there are people were selected.
Passport shots needed to be cropped in different ways, leaving only the face. Then Dlib came to the rescue. The principle of operation turned out to be this: found with the help of this library, the coordinates of the face -> cut off the passport photo, leaving the face.
In each of the 3 classes left 40,000 photos. Do not forget about the augmentation of data
Model
Used ResNet-50. Solved the problem as a multi-class classification problem with non-intersecting classes. That is, it was believed that the photo can belong to only one class.
model = keras.applications.resnet50.ResNet50()
model.layers.pop()
for layer in model.layers:
layer.trainable=True
last = model.layers[-1].output
x = Dense(3, activation="softmax")(last)
resnet50_1 = Model(model.input, x)
resnet50_1.compile(optimizer=Adam(lr=0.00001), loss='categorical_crossentropy', metrics=[ 'accuracy'])
results
In the test sample left 24,000 images, that is, 20%. The error matrix was as follows:
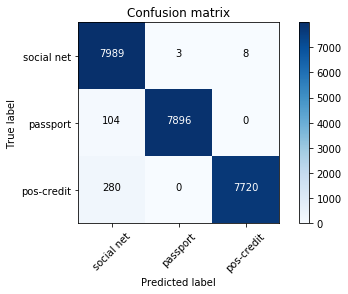
social net - social network;
passport - passports;
pos-credit - points of sale partners who provide loans.
The total error rate is 1.6%, for photos from points of sale - 1.2%. Most of the mistakenly identified images are similar to two classes at the same time. For example, almost all incorrectly defined photographs from the pos-credit class were taken in unsuccessful angles (against a white wall, only a face is visible). Therefore, they were also similar to the photo from the social net class. Such photos had a low maximum likelihood.
We have added a threshold for maximum likelihood. If the final value is higher - we trust the classifier, below - send the image for manual verification.
As a result, the result of the work of the service for photography is

as follows:
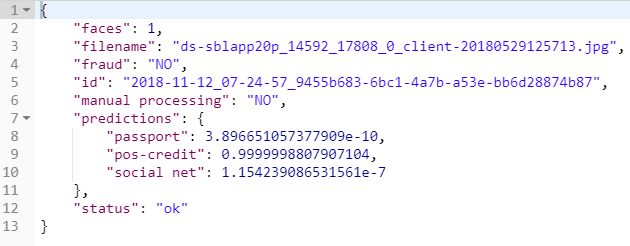
Results
So, with the help of a simple model, we learned how to automatically determine that the photo was taken at one of the points of sale of our partners. This allowed us to automate part of a large process for approving a loan application.