Classifiers: analysis of site visitors activity
1. Introduction
This note talks about some aspects of the practical application of classifiers in systems for analyzing the activity of site visitors. Code examples for machine learning tasks are shown, which are actively used both for global analysis of statistics on the Internet and for local problems of classifying behavioral factors on large portals.
2. Some methods of probability theory
The main problem is the fact that with stochastic processes (activity of site visitors) it is impossible to determine the value of a random variable in advance. However, we can estimate the probability of each of the values. Moreover, using the methods of machine learning, we will be able to understand the reasons why this or that random variable has taken its meaning.
There are stochastic processes with a very sharply expressed regularity, for example, an observer recorded several thousand trials. Suppose that over the entire long period of observations it was revealed that the random variable took only four possible values with an equal distribution. It is logical to assume that the amount of one of these values will be approximately four times less than the number of all. And vice versa: multiplying the number of values from one group by four we get an approximate number of all objects.
By analogy, you can identify (according to the Monte Carlo method) the approximate area of complex figures, if you know the number of hits on it points, the total number of random points and the area of space into which the complex figure is inscribed. It will be intuitively felt that if we divide the number of hits in a complex figure by the total number of points, then this will be the approximate part occupied by the figure in space. Moreover, it will also be the likelihood of a point falling into this complex figure.
Consider a simplified example. Let there be four main topics on the huge news portal. Some users go to the site and look strictly at only one of the topics. The distribution between them is equal, i.e. Equal probability that the topic of one of the clusters will be viewed. But the exact position of the new point is not known in advance, and it is only known that it will appear in one of these clusters (centroids are shown as large green dots):

It is impossible for a non-existent topic to be viewed (how can I see it if it does not exist?), I.e. its probability is zero. Any point belongs only to this space. The probability of getting into a particular cluster is 1/4. The probability of falling into at least one of the clusters will be equal to 1 (the sum of the probabilities of all events), since the point necessarily falls into one of them. The probability that points will fall into one cluster several times in a row is equal to the product of the probabilities of these events. This can be seen experimentally and formally written as:

But for the normal distribution, a slightly different forecast tactic is used. It is necessary to identify the average value. That it will be the most likely. The following are two visual displays of the equiprobable distribution and the normal distribution.
To understand the strength of the spread, it is necessary to identify the variance (or the square root of it, which is called the standard deviation and is denoted by the Greek letter sigma). To predict the value of a discrete random variable, this is a very important indicator, since most of the values (if this is a normal distribution) are within sigma.
In other words: if under normal distribution we will expect the arithmetic mean (it is equal to the mathematical expectation), and the permissible error (inaccuracy or error) will be at least about one sigma, then in most cases (about 68%) we will successfully guess. We will visually display a random variable with a different level of dispersion: at first, the variance is small, and then it clearly increases. For the convenience of visual perception, the mathematical expectation is also increased.
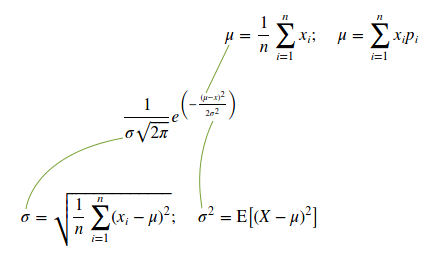
Since we are talking about discrete random variables, it is permissible to use the formula of the arithmetic mean value instead of the mathematical expectation formula. For the reason mentioned, you can use the formula shown below to the left so as not to calculate the sum of the squared value multiplied by their probability, and then subtract the squared mathematical expectation from the sum of these products. I give the normal distribution function and the variables necessary for it (formulas for their calculation):
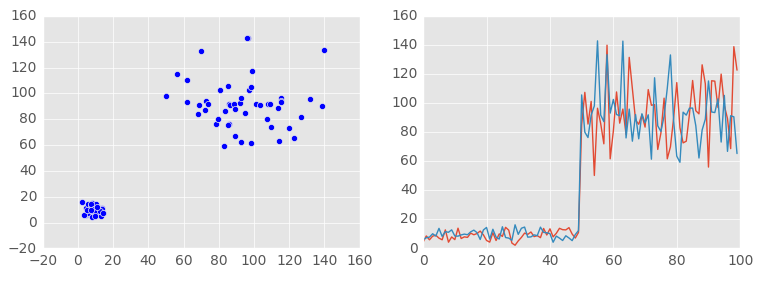
But everything is not always so predictable. Naturally, the probability of a random variable can vary. Not all processes will have a Gaussian distribution or an equiprobable distribution. It is often possible to record changes in probability over time, i.e. some metrics can change their values in an unpredictable way, which will obviously affect the probability. An example of a change in values in which two metrics grow unevenly, and one after growth returns to its original value:
Consequently, in a number of processes the results (the appearance of a point) may not be distributed evenly. Obviously, in the following example, the cloud cannot be called uniformly distributed in space. For clarity, I also cite its contours:

In the analysis of a large amount of data with different distributions, machine learning will help us. Each observation will have a large feature vector. For example, in the diagnosis of acute respiratory viral infections, an indicator such as body temperature is often used. It is very easy to objectively measure with a suitable instrument. Obviously, if you look at descriptive statistics of the body temperature of two groups of people (healthy and with acute respiratory viral infections), it will be quite easy to understand the differences in this indicator. Of course, a metric alone will not be enough, since a symptom of fever can occur (or be absent) in many other diseases. Therefore, we need to objectively measure a huge list of indicators (vector of predictors). Each vector must have a label: healthy or sick. This is a general principle of data preparation for those machine learning methods,
3. Preliminary research
The preliminary stage of analysis does not always require the involvement of servers in the data center, therefore, it is performed on local computers. One of the most popular data analysis tools is the R and Python programming languages (combined with Jupyter, Pandas, NumPy, and SciPy). They have rich sets of already implemented mathematical functions and tools for visualizing information.
At the stage of preliminary research, it is necessary to collect the information necessary for classification. It is always a feature vector, i.e. numbers (usually a Double data type). At this stage, the methods of collection and action are selected if it is impossible to obtain a value (sometimes it is permissible to replace the missing values with an arithmetic mean or median).
The metric (predictor) should be a number that objectively reflects the essence of this part of the phenomenon. Such a metric is measurable, and the measurements themselves are reproducible (anyone with a working measuring device can repeat the experiment and get about the same indicators). It is intuitively expected that the stronger the difference between the values of the metric in different groups, the easier it will be to classify. In the most ideal case, they do not intersect (the maximum of one is clearly less than the minimum of the other).
Additional checks may also be required at this point. They are implemented using a very large number of third-party libraries and software products. Sometimes it’s fun to watch the number of imported modules, especially the different destination at first glance (like Mystem and Selenium). It is logical that various experiments can be performed that confirm or refute the hypothesis. Divide into groups and carefully monitor the conditions and expect the metrics to change accordingly.
If we talk about the specifics of systems for analyzing behavioral factors, the logic of their work implies that the collected data has already been cleaned and validated. Ideally, the application itself should be responsible for the quality of data collection. It remains only to mark (for each vector mark the class to which it belongs). It is possible that the application has already marked up the data (for example, there is already a record in the database that will become the label: bought or not bought the product). Of course, this is necessary in order to further predict the likelihood of this event or to identify the most important predictors.
Quite often, data is stored in ordinary text files in CSV or libsvm format. This allows you to conveniently handle them using R and Python (Pandas, NumPy). In some cases, you need to put them in a database. And in some cases, distributed computing may be required. On huge portals and in global statistical systems, a very large matrix is obtained. This raises the question of choosing a system for storing a huge number of observations in a very wide table (a lot of tuples with a large number of attributes).
Most likely, it makes sense to pay attention to specialized analytical solutions that have tremendous processing speed. The use of technologies such as ClickHouse (an analytical database management system) allows you to pre-analyze some important indicators and prepare the data itself. And now we are talking not just about high performance, but also about a number of useful functions for working with statistics, as well as additional features, for example, the ability to select the data export format (including JSON and XML) or the response directly in the browser after the get-request ( http: // localhost: 8123 /? query = Q ), where instead of Q is the following SQL statement:
SELECT page, COUNT() AS views, uniqCombined(uuid) AS users
FROM example.page_views
GROUP BY page
FORMAT CSVWithNames;The preparation and verification of data is a very serious process, they pay great attention to it. After several research queries, the choice of machine learning algorithms and a more detailed analysis of the selection of the tools mentioned above begin. Even at the stage of selecting the most suitable classification algorithms, the verification of the initial data and the attempt to find new predictors continue. In any case, many “classification wonders” are easily explained by a couple of missed or noisy predictors. In some cases, you can even create an array of classifiers and analyze the correct operation of each of them with the corresponding parameters:
import pylab
import pandas as pd
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from mpl_toolkits.mplot3d import Axes3D
from sklearn.linear_model import SGDClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from IPython.core.display import display, HTML
#
# Список классификаторов
#
classifiers = [
LogisticRegression(max_iter=200, penalty="l2"),
SGDClassifier(loss="hinge", penalty="l2"),
MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(3, 4)),
RandomForestClassifier(n_estimators=60, max_depth=5),
GradientBoostingClassifier(n_estimators=180, learning_rate=1.0, max_depth=4),
DecisionTreeClassifier(),
SVC(),
]
#
# Тренировка и оценка точности
#
result = []
for classifier in classifiers:
classifier.fit(features, classes)
report = accuracy_score(testClasses, classifier.predict(testFeatures))
result.append({'class' : classifier.__class__.__name__, 'accuracy' : report})
display(HTML('Result
'))
display(pd.DataFrame(result))
#
# Исследуем уровень важности предикторов
#
model = xgb.XGBClassifier()
model.fit(features, classes)
pylab.rcParams['figure.figsize'] = 3, 3
plt.style.use('ggplot')
pd.Series(model.feature_importances_).plot(kind='bar')
plt.title('Feature Importances')
plt.show()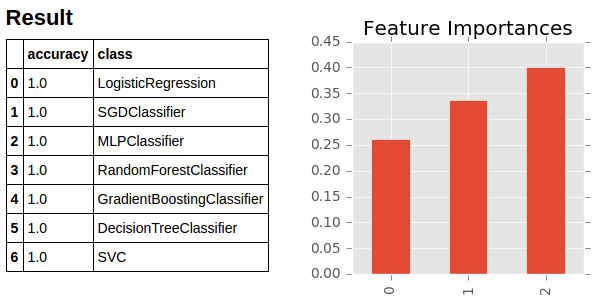
As you can see, the basic classification algorithms are already implemented in popular libraries, which makes it possible to use them in just a few lines of code very simply and quickly. In addition, it is very useful for some models to look at the chart of the significance level of predictors using appropriate classifiers (such as: RandomForestClassifier, GradientBoostingClassifier, XGBClassifier). It is very convenient to perform other types of data analysis and visualization, for example, cluster analysis:
import pylab
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from mpl_toolkits.mplot3d import Axes3D
centroids = KMeans(n_clusters=4, random_state=0).fit(features).cluster_centers_
ax = Axes3D(pylab.figure())
ax.scatter(features[:, 0], features[:, 1], features[:, 2], c='blue', marker='p', s=8)
ax.scatter(centroids[:, 0], centroids[:, 1], centroids[:, 2], c='g', marker='o', s=80)
plt.show()4. Creating a finished model
After the appropriate algorithm with the necessary parameters has been selected on the local system, the preparation of distributed computing begins, the task of which is to predict the class of the event in advance. This can be not just a binary classification (an event will happen or not), but also a multiclass classification. Apache Spark is often used for such distributed computing tasks (examples are shown on Scala for version 2.0.2). Of course, the first test runs also require a very thorough check of the selected solution on new data:
import org.apache.spark.ml.classification.MultilayerPerceptronClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val train = spark.read.format("libsvm").load(file)
val test = spark.read.format("libsvm").load(fileTest)
val trainer = new MultilayerPerceptronClassifier().setLayers(Array[Int](3, 5, 4, 4)).setBlockSize(128).setSeed(1234L).setMaxIter(100)
val result = trainer.fit(train).transform(test)
val predictionAndLabels = result.select("prediction", "label")
val evaluator = new MulticlassClassificationEvaluator()
evaluator.setMetricName("accuracy").evaluate(predictionAndLabels)At the end of the verification and tuning process, the final version of the machine learning algorithm starts its work. It marks out huge amounts of data, and the results are displayed in a user-friendly interface. A separate application is responsible for the visualization (often this is a web application or part of a portal). As a rule, the application does not know anything about the analysis system, and is connected with it only by import into the database or through the API. In my personal experience, a well-known technology stack (PHP7, Yii 2, Laravel, MySQL, Redis, Memcached, RabbitMQ) for the backend and a set of libraries for visual presentation (for example, Chart.js and many others) are usually used for a separate displaying application.
Thus, we looked at the basic steps of creating a system of analysis of behavioral factors. Systems for classifying other data sets work on a similar principle. The most basic steps can be called collecting the right metrics in a suitable format (as they say, “deploy to a vector”) and choosing the right algorithm with the right parameters. Of course, it is critical to verify the correct operation of the classifier.
Taking this opportunity (given today's date) I congratulate dear readers on the upcoming New Year in advance and sincerely wish you happiness and success in all areas of life.