Databases and Kubernetes (review and video report)
On November 8, the report “Databases and Kubernetes” was presented in the main conference room of HighLoad ++ 2018 , within the DevOps and Operation section. It tells about high availability of databases and approaches to fault tolerance up to Kubernetes and with it, as well as practical options for deploying DBMS in Kubernetes clusters and existing for this solution (including Stolon for PostgreSQL).

By tradition, we are glad to present a video with a report (about an hour, much more informative than an article) and the main squeeze in text form. Go!
This report appeared as an answer to one of the most popular questions that over the past years we have been tirelessly asked in different places: comments on Habré or YouTube, social networks, etc. It sounds simple: “Is it possible to launch a base in Kubernetes?”, And if we usually answered it “in general, yes, but ...”, then the explanations for these “in general” and “but” clearly did not suffice, but to accommodate them in a short message could not succeed.
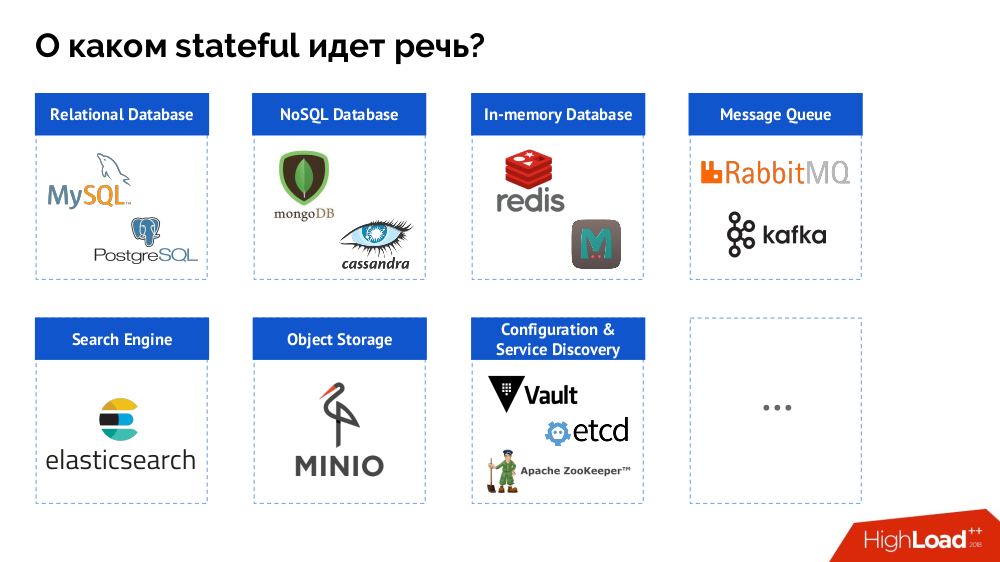
However, to begin with, I will generalize the question from the “[database]” to the stateful as a whole. A DBMS is only a special case of stateful solutions, a more complete list of which can be represented as follows:
Before looking at specific cases, I’ll tell you about three important features of the work / use of Kubernetes.
Everyone knows the analogy “pets vs cattle ” and understand that if Kubernetes is a story from the world of the herd, then the classic DBMS is just pets.
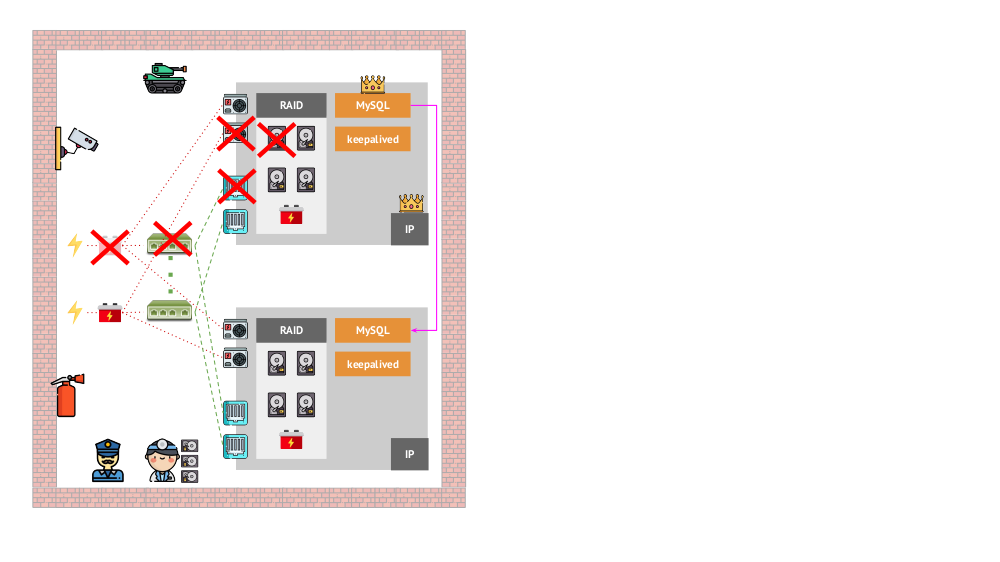
And how did the architecture of the “pets” look in the “traditional” version? The classic MySQL installation example is replication on two iron servers with backup power, disk, network ... and everything else (including an engineer and various support tools), which will help us to be sure that the MySQL process will not fall, and if there is a problem with any of the critical ones. for it components, fault tolerance will be respected:
How will the same look in Kubernetes? There are usually much more iron servers, they are simpler and they do not have redundant power and network (in the sense that dropping one machine doesn’t affect anything) - all of this is clustered together. Its fault tolerance is ensured by software: if something happens to a node, Kubernetes detects it and runs the necessary instances on another node.
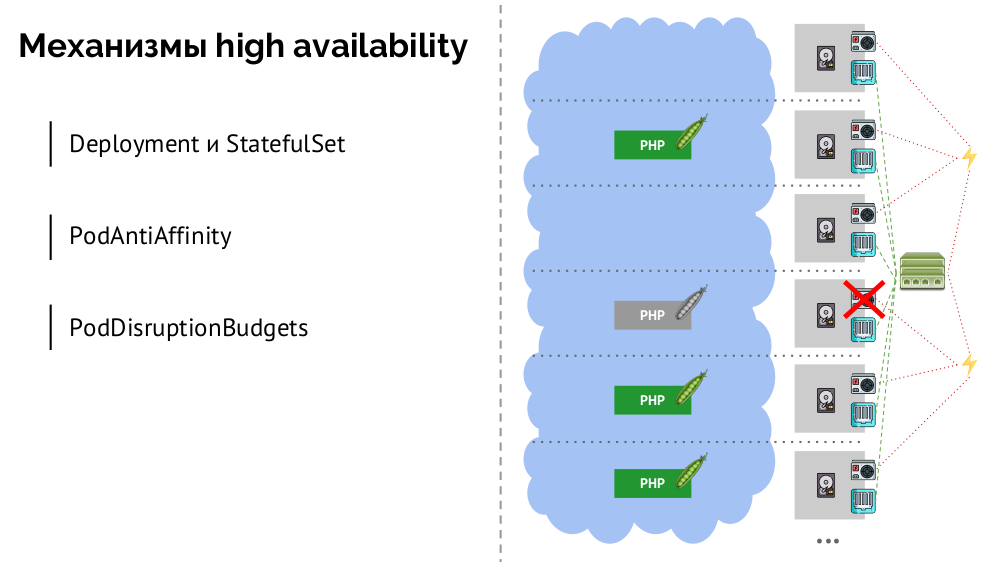
What are the mechanisms for high availability in K8s?
How does the familiar one-master failover scheme work? Two servers (master and standby), one of which is constantly accessed by the application, which in turn is used through the load balancer. What happens in case of a network problem?
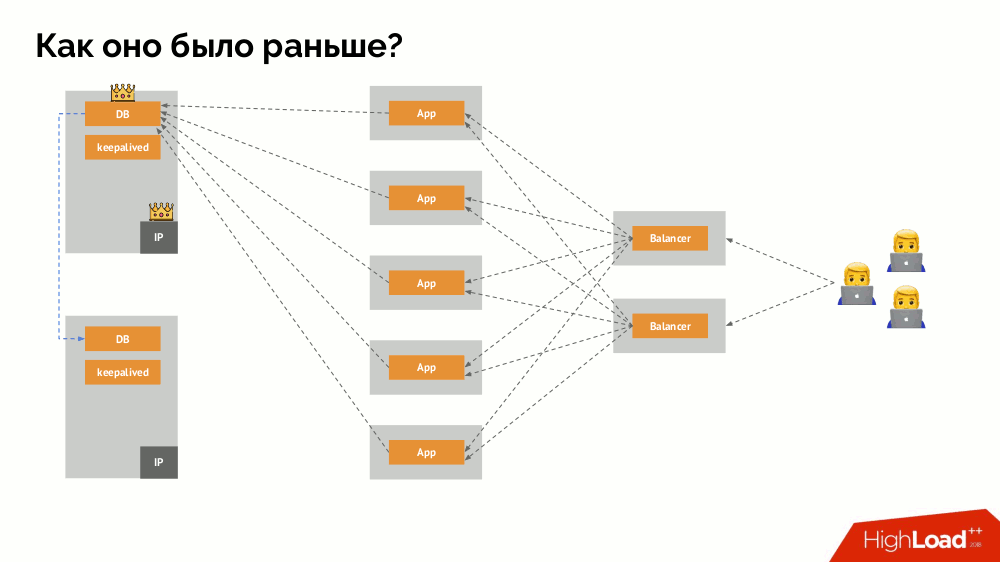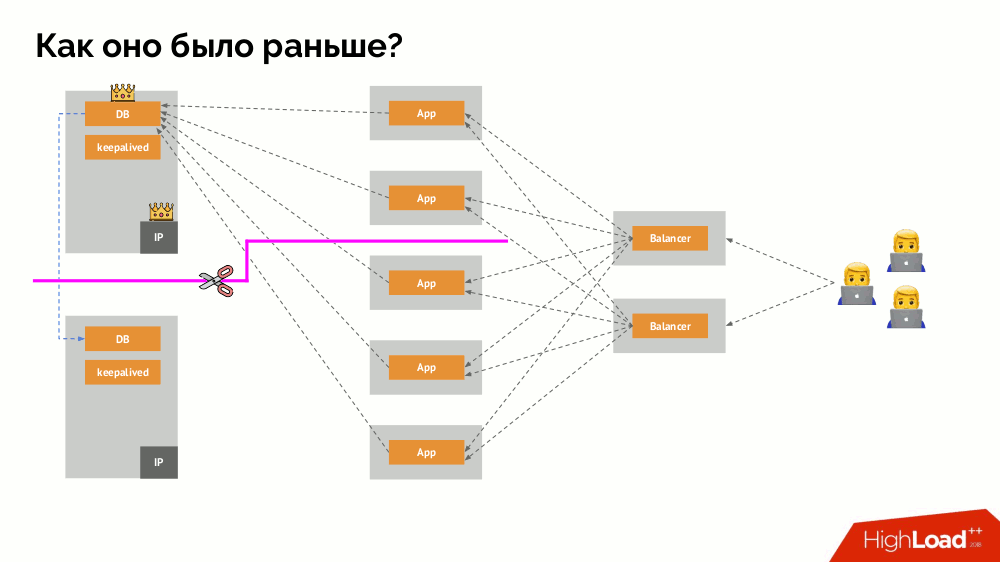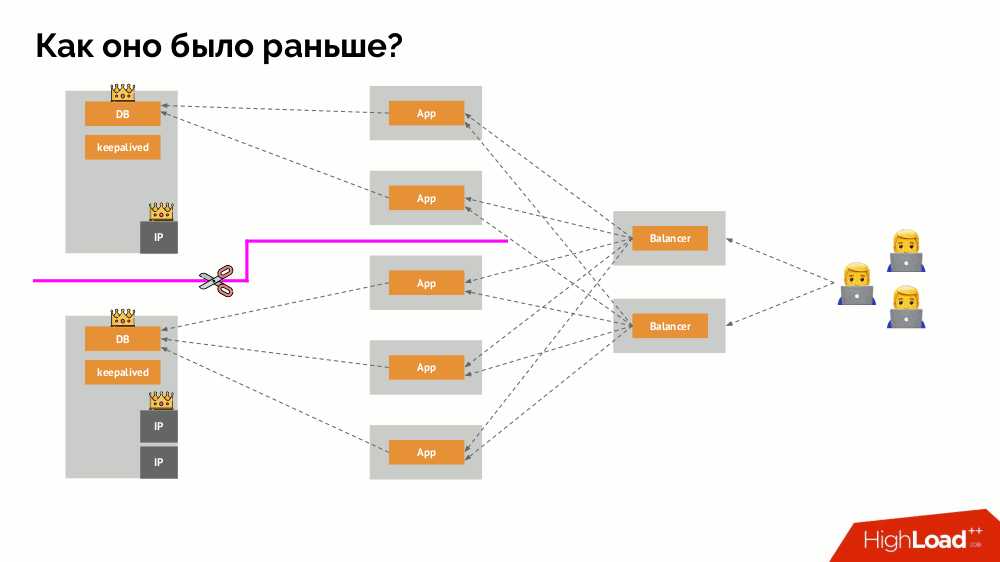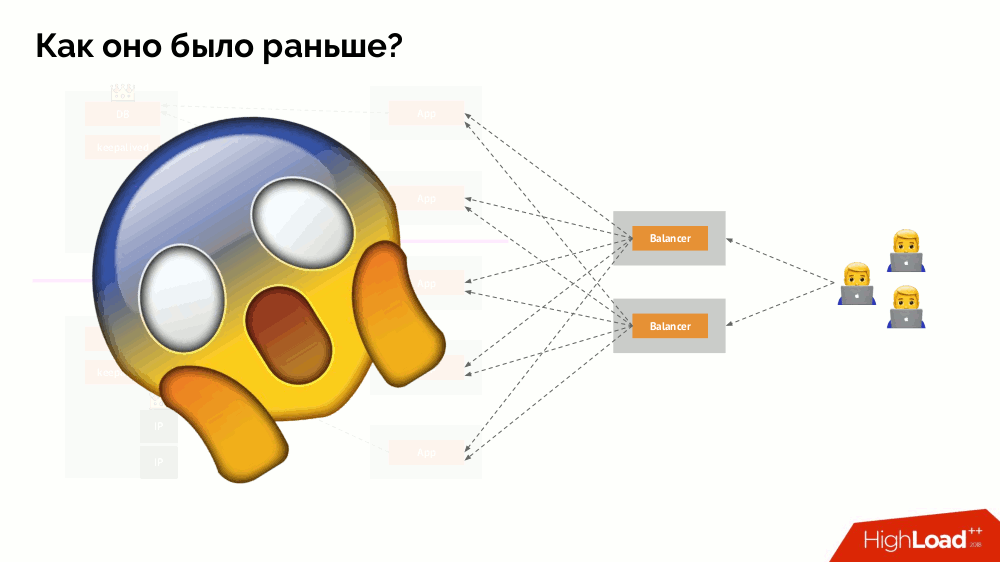
Classic split-brain: The application starts to access both instances of the DBMS, each of which considers itself to be the main. To avoid this, keepalived was replaced with corosync already with three copies of it to achieve a quorum when voting for the master. However, even in this case, there are problems: if a failed copy of the DBMS tries in every way to “suicide” (remove the IP address, transfer the database to read-only ...), then another part of the cluster does not know what happened to the master — indeed, it can happen that the node actually still works and requests get to it, which means that we cannot yet switch masters.
To solve this situation, there is a node isolation mechanism in order to protect the entire cluster from incorrect operation - this process is called fencing.. The practical essence comes down to the fact that we are trying by some external means to “kill” the fallen off car. Approaches can be different: from shutting down the machine via IPMI and blocking the port on the switch to accessing the cloud provider's API, etc. And only after this operation, you can switch the wizard. This achieves a guarantee AT-will most-once recording , which gives us consistency ( consistency ) .
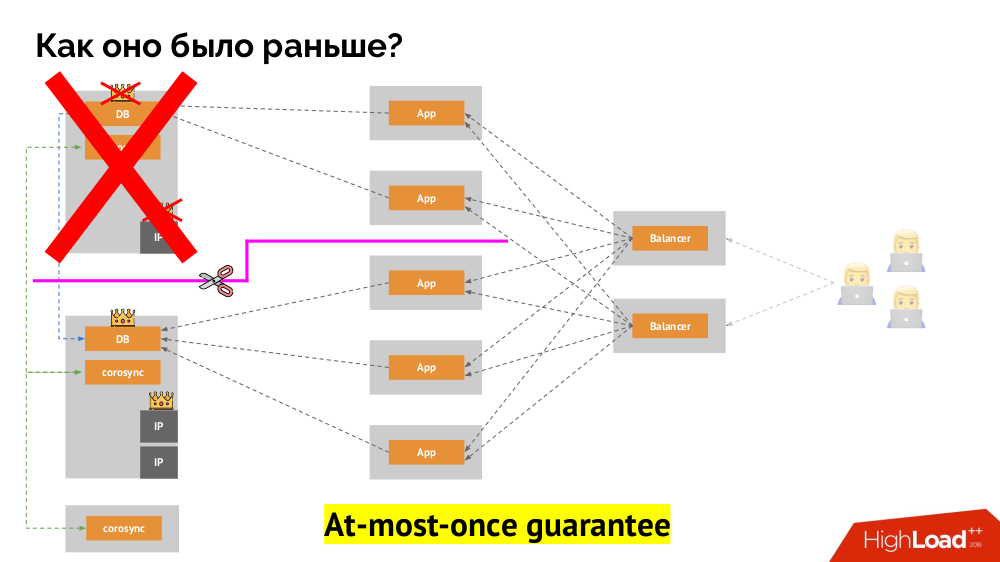
How to achieve the same in Kubernetes? To do this, there are already mentioned controllers, whose behavior in the case of node unavailability is different:
However, here, in the latter case, fencing is required: a mechanism is needed that will confirm that this node is definitely no more. First of all, it is very difficult to make it automatic (many implementations are required), and secondly, even worse, it usually kills nodes slowly (accessing IPMI can take seconds or tens of seconds, or even minutes). Few people will wait per minute to switch the base to the new master. But there is another approach that does not require a fencing mechanism ...
I will begin his description outside of Kubernetes. It uses a special load balancer (load balancer), through which backends address the DBMS. Its specificity lies in the fact that it has the property of consistency, i.e. protection from network failures and split-brain, because it allows you to remove all connections to the current master, wait for synchronization (replica) on another node and switch to it. I did not find an established term for this approach and called it Consistent Switchover .
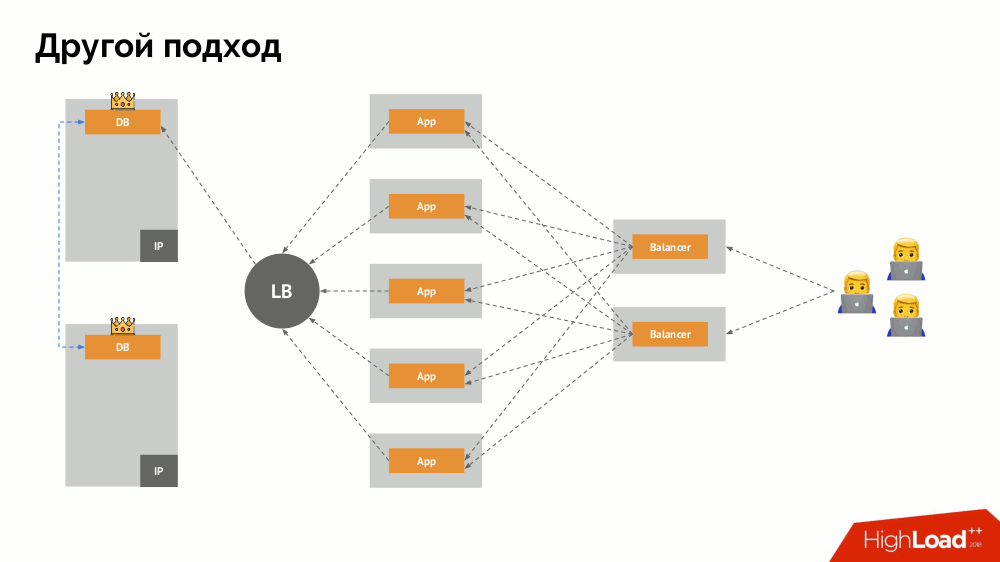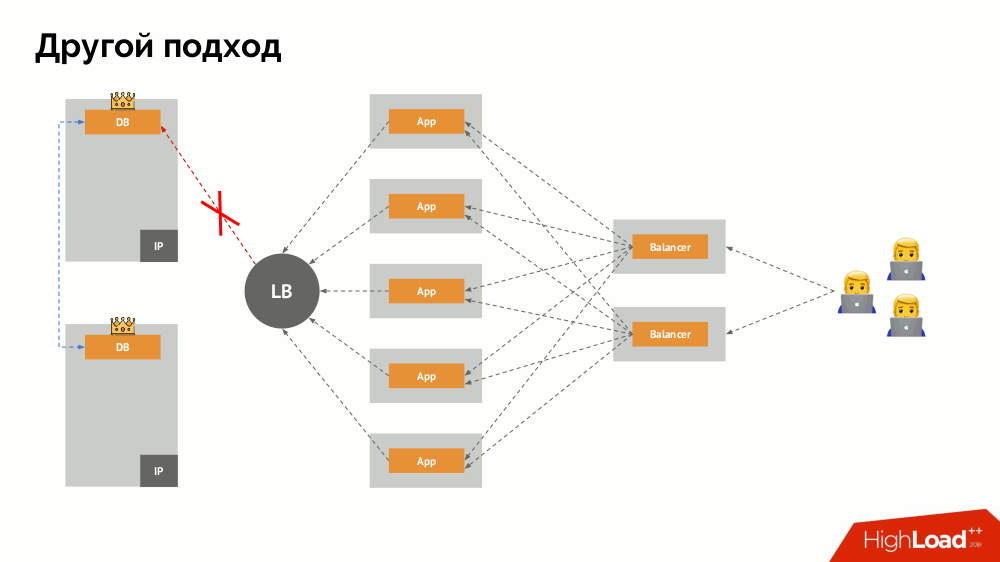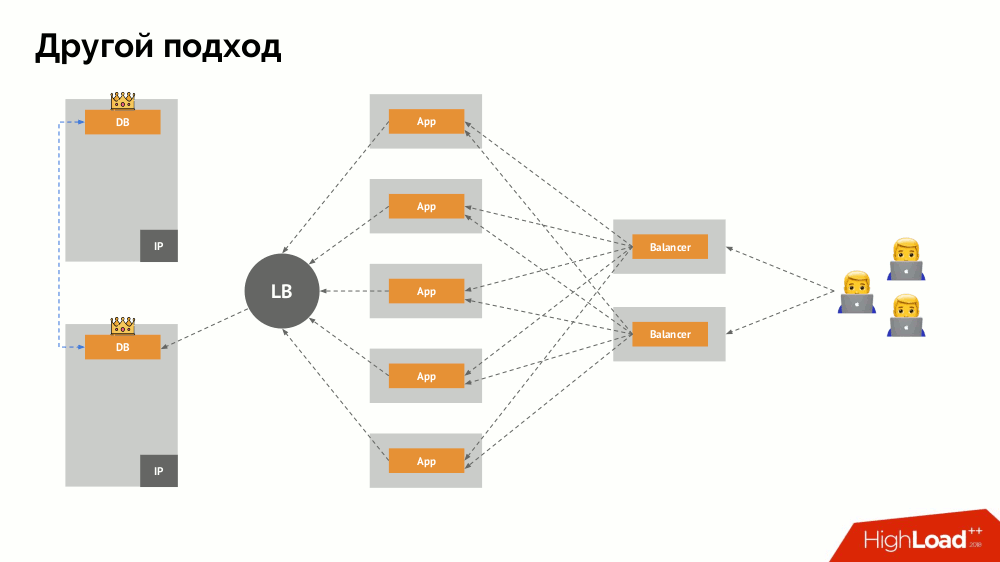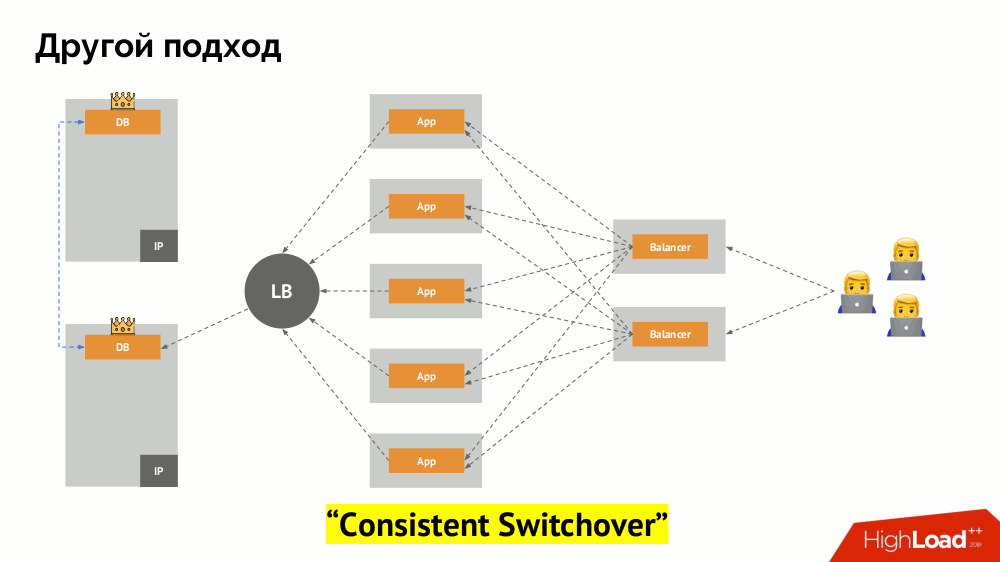
The main question with him is how to make it universal, providing support to both cloud providers and private installations. To do this, proxy servers are added to the applications. Each of them will receive requests from its application (and send them to the DBMS), and quorum will be collected from all together. As soon as a part of the cluster fails, those proxies that have lost their quorum immediately remove their connections to the DBMS.
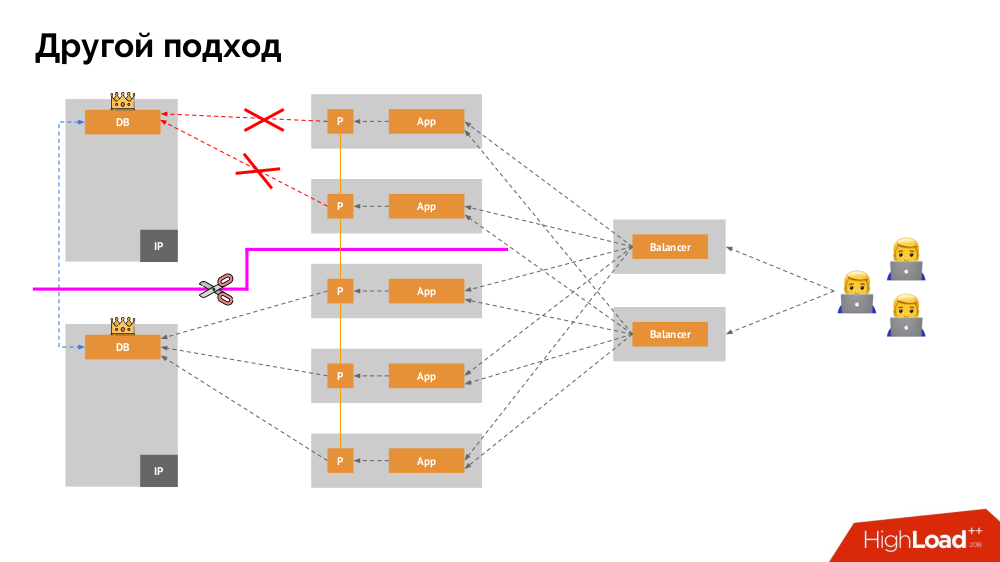
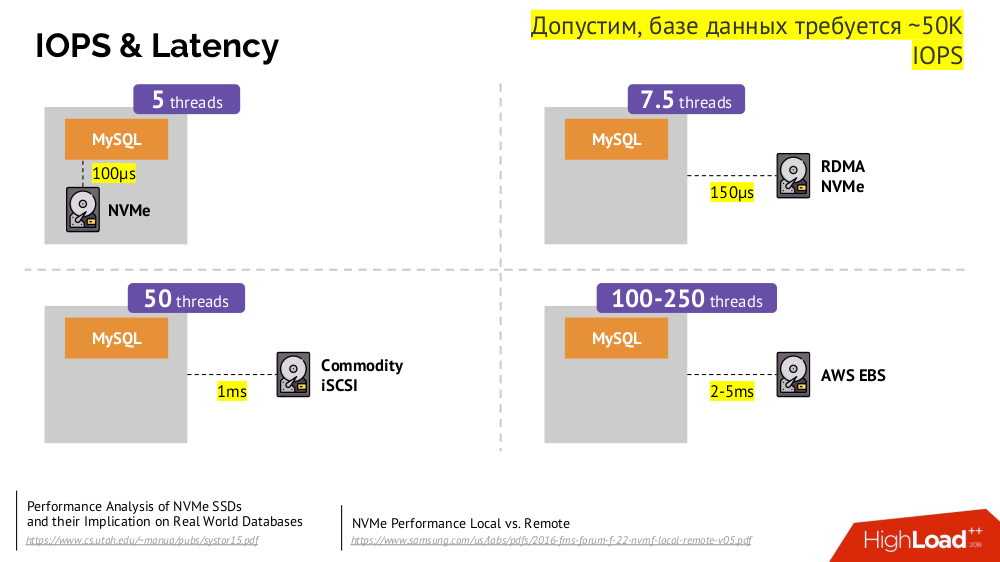
The main mechanism is the Network Block Device network disk (aka SAN) in different implementations for the desired cloud options or bare metal. However, putting a loaded database (for example, MySQL, which requires 50,000 IOPS) to the cloud (AWS EBS ) is not possible due to the latency .
In Kubernetes for such cases it is possible to connect a local hard disk - Local Storage . If a failure occurs (the disk ceases to be available in the pod), then we are forced to repair this machine - by analogy with the classical scheme in case of failure of one reliable server.
Both options ( Network Block Device and Local Storage ) are in the ReadWriteOnce category.: the storage cannot be mounted in two places (pod'a) - for such scaling you need to create a new disk and connect it to the new pod (for this there is a built-in K8s mechanism), and then fill it with the necessary data (already done by our own forces).
If we need the ReadWriteMany mode , then the Network File System (or NAS) implementations are available : for a public cloud, this is

This option is about the case when nothing prevents to launch the DBMS in the mode of a separate server with local storage. This is not about high availability ... although it may be to some extent (i.e., sufficient for a given application) implemented at the iron level. There are many cases for this use. First of all, these are various staging- and dev-environments, but not only: secondary services also fall here, and disabling them for 15 minutes is not critical. In Kubernetes, this is implemented
In general, this is a viable option, which, from my point of view, has no disadvantages compared to installing a DBMS on a separate virtual machine.
It is used again
If one of the nodes (
If you are currently using the classic version with two servers (master + standby) without failover , this solution is equivalent to Kubernetes. Suitable for MySQL, PostgreSQL, Redis and other products.
In fact, this case is not stateful, because we are talking only about reading. Here, the main DBMS server is outside the considered scheme, and within the Kubernetes framework, a “farm of slave servers” is created that are available only for reading. The general mechanism — the use of init containers to fill the database with data on each new pod of this farm (using a hot dump or the usual one with additional actions, etc. — depends on the database used). To be sure that each instance is not too far behind the master, you can use liveness samples.

If you make
You don’t have to go far for an example: storage of sessions in PHP works out of the box. For each session request, requests are made simultaneously to all servers, after which the most relevant answer is selected from them (similarly to recording).
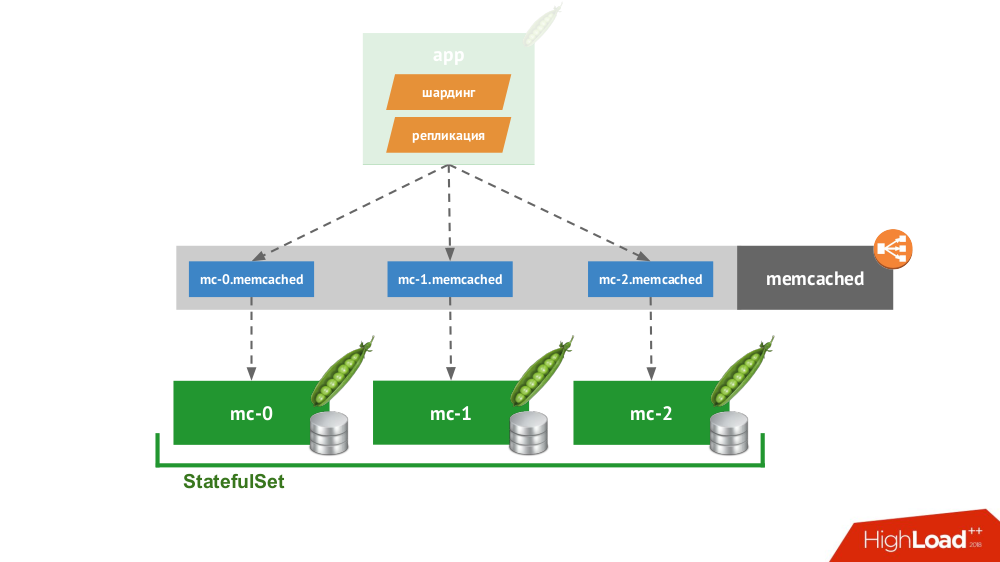
There are many solutions that are initially focused on node failure, i.e. they are able to do failover (failover) and recovery units (recovery) , provide a guarantee of consistency (consistency) . This is not a complete list of them, but only some of the popular examples:

All of them are simply put in
Regardless of the chosen solutions to these issues, all such products work well with Kubernetes, because they were originally created as a “herd” (cattle) .
Stolon actually allows you to turn PostgreSQL DBMS, created as a pet , into a cattle . How is this achieved?
So is it possible to base in Kubernetes? Yes, of course, it is possible, in some cases ... And if it is appropriate, then it is done like this (see the work scheme of Stolon) ...
Everyone knows that technologies are developing in waves. Initially, any new device can be very difficult to use, but over time, everything changes: the technology becomes available. Where are we going? Yes, it will remain like this inside, but how it will work, we will not know. In Kubernetes, operators are actively developing . So far there are not so many of them and they are not so good, but there is a movement in this direction.
Video from the performance (about an hour):
Presentation of the report:
PS We also found a very (!) Short text message from this report on the web - thanks for her Nikolai Volynkin.
Other reports on our blog:
You may also be interested in the following publications:
By tradition, we are glad to present a video with a report (about an hour, much more informative than an article) and the main squeeze in text form. Go!
Theory
This report appeared as an answer to one of the most popular questions that over the past years we have been tirelessly asked in different places: comments on Habré or YouTube, social networks, etc. It sounds simple: “Is it possible to launch a base in Kubernetes?”, And if we usually answered it “in general, yes, but ...”, then the explanations for these “in general” and “but” clearly did not suffice, but to accommodate them in a short message could not succeed.
However, to begin with, I will generalize the question from the “[database]” to the stateful as a whole. A DBMS is only a special case of stateful solutions, a more complete list of which can be represented as follows:
Before looking at specific cases, I’ll tell you about three important features of the work / use of Kubernetes.
1. The philosophy of high availability in Kubernetes
Everyone knows the analogy “pets vs cattle ” and understand that if Kubernetes is a story from the world of the herd, then the classic DBMS is just pets.
And how did the architecture of the “pets” look in the “traditional” version? The classic MySQL installation example is replication on two iron servers with backup power, disk, network ... and everything else (including an engineer and various support tools), which will help us to be sure that the MySQL process will not fall, and if there is a problem with any of the critical ones. for it components, fault tolerance will be respected:
How will the same look in Kubernetes? There are usually much more iron servers, they are simpler and they do not have redundant power and network (in the sense that dropping one machine doesn’t affect anything) - all of this is clustered together. Its fault tolerance is ensured by software: if something happens to a node, Kubernetes detects it and runs the necessary instances on another node.
What are the mechanisms for high availability in K8s?
- Controllers. There are many of them, but there are two main ones:
Deployment(for stateless applications) andStatefulSet(for stateful applications). They contain all the logic of actions taken in the event of a node fall (inaccessibility of the pod). PodAntiAffinity- the ability to specify certain pods so that they are not on the same node.PodDisruptionBudgets- limit on the number of copies of pods that can be simultaneously turned off in case of planned work.
2. Assurance of consistency in Kubernetes
How does the familiar one-master failover scheme work? Two servers (master and standby), one of which is constantly accessed by the application, which in turn is used through the load balancer. What happens in case of a network problem?
Classic split-brain: The application starts to access both instances of the DBMS, each of which considers itself to be the main. To avoid this, keepalived was replaced with corosync already with three copies of it to achieve a quorum when voting for the master. However, even in this case, there are problems: if a failed copy of the DBMS tries in every way to “suicide” (remove the IP address, transfer the database to read-only ...), then another part of the cluster does not know what happened to the master — indeed, it can happen that the node actually still works and requests get to it, which means that we cannot yet switch masters.
To solve this situation, there is a node isolation mechanism in order to protect the entire cluster from incorrect operation - this process is called fencing.. The practical essence comes down to the fact that we are trying by some external means to “kill” the fallen off car. Approaches can be different: from shutting down the machine via IPMI and blocking the port on the switch to accessing the cloud provider's API, etc. And only after this operation, you can switch the wizard. This achieves a guarantee AT-will most-once recording , which gives us consistency ( consistency ) .
How to achieve the same in Kubernetes? To do this, there are already mentioned controllers, whose behavior in the case of node unavailability is different:
Deployment: “I was told that there should be 3 pods, and now there are only 2 of them - I will create a new one”;StatefulSet: “Pod'a gone? I will wait: either this node will return, or they will tell us to kill him ”, i.e. containers themselves (without operator actions) are not re-created. This is the way the same at-most-once warranty is achieved.
However, here, in the latter case, fencing is required: a mechanism is needed that will confirm that this node is definitely no more. First of all, it is very difficult to make it automatic (many implementations are required), and secondly, even worse, it usually kills nodes slowly (accessing IPMI can take seconds or tens of seconds, or even minutes). Few people will wait per minute to switch the base to the new master. But there is another approach that does not require a fencing mechanism ...
I will begin his description outside of Kubernetes. It uses a special load balancer (load balancer), through which backends address the DBMS. Its specificity lies in the fact that it has the property of consistency, i.e. protection from network failures and split-brain, because it allows you to remove all connections to the current master, wait for synchronization (replica) on another node and switch to it. I did not find an established term for this approach and called it Consistent Switchover .
The main question with him is how to make it universal, providing support to both cloud providers and private installations. To do this, proxy servers are added to the applications. Each of them will receive requests from its application (and send them to the DBMS), and quorum will be collected from all together. As soon as a part of the cluster fails, those proxies that have lost their quorum immediately remove their connections to the DBMS.
3. Data Storage and Kubernetes
The main mechanism is the Network Block Device network disk (aka SAN) in different implementations for the desired cloud options or bare metal. However, putting a loaded database (for example, MySQL, which requires 50,000 IOPS) to the cloud (AWS EBS ) is not possible due to the latency .
In Kubernetes for such cases it is possible to connect a local hard disk - Local Storage . If a failure occurs (the disk ceases to be available in the pod), then we are forced to repair this machine - by analogy with the classical scheme in case of failure of one reliable server.
Both options ( Network Block Device and Local Storage ) are in the ReadWriteOnce category.: the storage cannot be mounted in two places (pod'a) - for such scaling you need to create a new disk and connect it to the new pod (for this there is a built-in K8s mechanism), and then fill it with the necessary data (already done by our own forces).
If we need the ReadWriteMany mode , then the Network File System (or NAS) implementations are available : for a public cloud, this is
AzureFileand AWSElasticFileSystem, and for its installations, CephFS and Glusterfs for fans of distributed systems, as well as NFS.Practice
1. Standalone
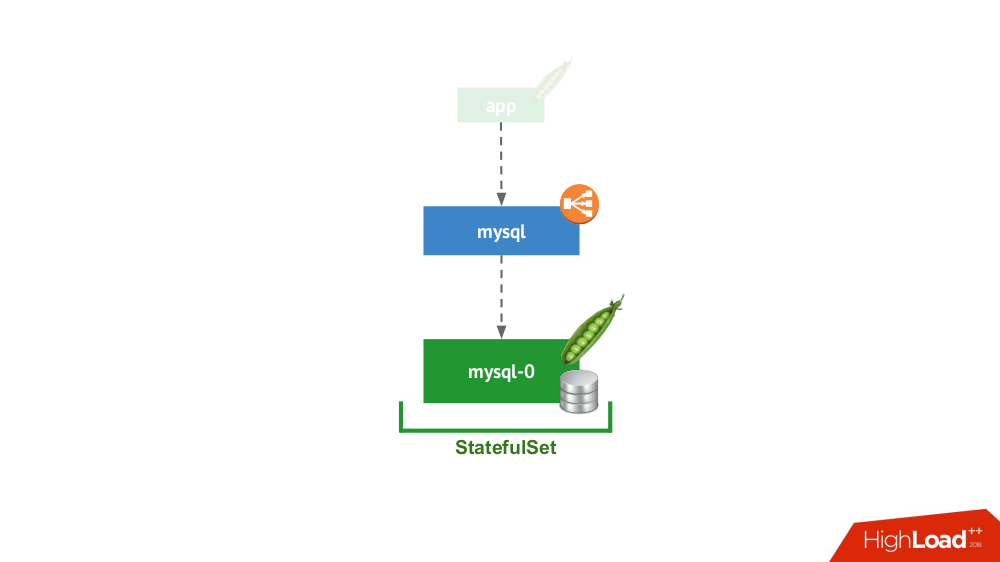
This option is about the case when nothing prevents to launch the DBMS in the mode of a separate server with local storage. This is not about high availability ... although it may be to some extent (i.e., sufficient for a given application) implemented at the iron level. There are many cases for this use. First of all, these are various staging- and dev-environments, but not only: secondary services also fall here, and disabling them for 15 minutes is not critical. In Kubernetes, this is implemented
StatefulSetwith one pod: In general, this is a viable option, which, from my point of view, has no disadvantages compared to installing a DBMS on a separate virtual machine.
2. Replicated pair with manual switching
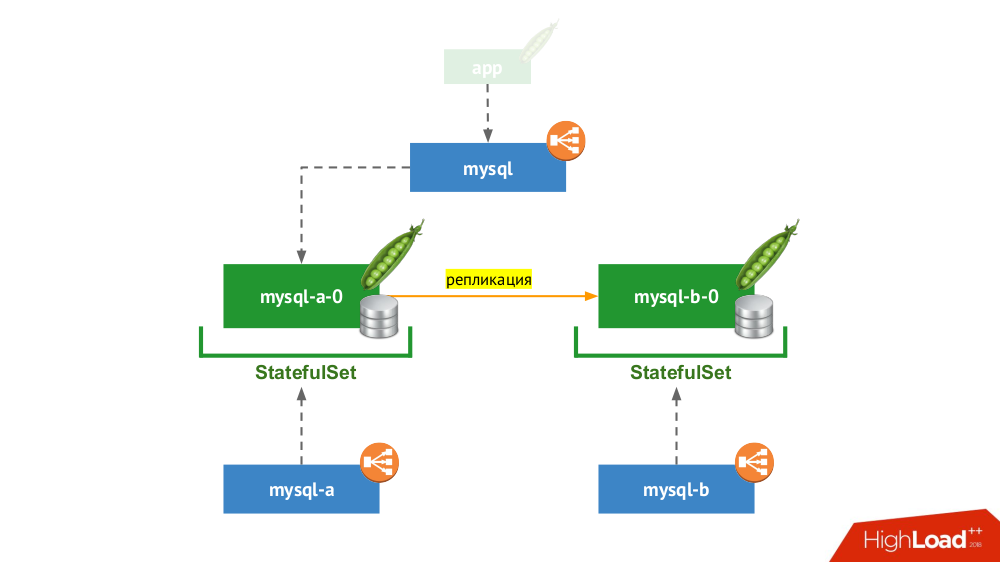
It is used again
StatefulSet, but the general scheme looks as follows: If one of the nodes (
mysql-a-0) fails , a miracle does not occur, but we have a replica ( mysql-b-0) to which we can switch traffic. At the same time - even before switching traffic - it is important not to forget not only to remove the requests to the DBMS from the service mysql, but also to go to the DBMS manually and make sure that all connections are completed (kill them), and also go to the second node from the DBMS and reconfigure the replica to back side. If you are currently using the classic version with two servers (master + standby) without failover , this solution is equivalent to Kubernetes. Suitable for MySQL, PostgreSQL, Redis and other products.
3. Scaling the read load
In fact, this case is not stateful, because we are talking only about reading. Here, the main DBMS server is outside the considered scheme, and within the Kubernetes framework, a “farm of slave servers” is created that are available only for reading. The general mechanism — the use of init containers to fill the database with data on each new pod of this farm (using a hot dump or the usual one with additional actions, etc. — depends on the database used). To be sure that each instance is not too far behind the master, you can use liveness samples.
4. Smart client
If you make
StatefulSetmemcached from three, a special service is available in Kubernetes that will not balance the requests, but will create each pod for its own domain. The client will be able to work with them if he can sharding and replication. You don’t have to go far for an example: storage of sessions in PHP works out of the box. For each session request, requests are made simultaneously to all servers, after which the most relevant answer is selected from them (similarly to recording).
5. Cloud Native Solutions
There are many solutions that are initially focused on node failure, i.e. they are able to do failover (failover) and recovery units (recovery) , provide a guarantee of consistency (consistency) . This is not a complete list of them, but only some of the popular examples:
All of them are simply put in
StatefulSet, after which the nodes find each other and form a cluster. The products themselves are different in how they implement three things:- How do nodes learn about each other? For this, there are methods such as the Kubernetes API, DNS records, static configuration, specialized nodes (seed), third-party service discovery ...
- How does the client connect? Through the load balancer, distributing to the hosts, or the client needs to know about all the hosts, and he himself decides how to proceed.
- How is horizontal scaling done? No, full or difficult / with limitations.
Regardless of the chosen solutions to these issues, all such products work well with Kubernetes, because they were originally created as a “herd” (cattle) .
6. Stolon PostgreSQL
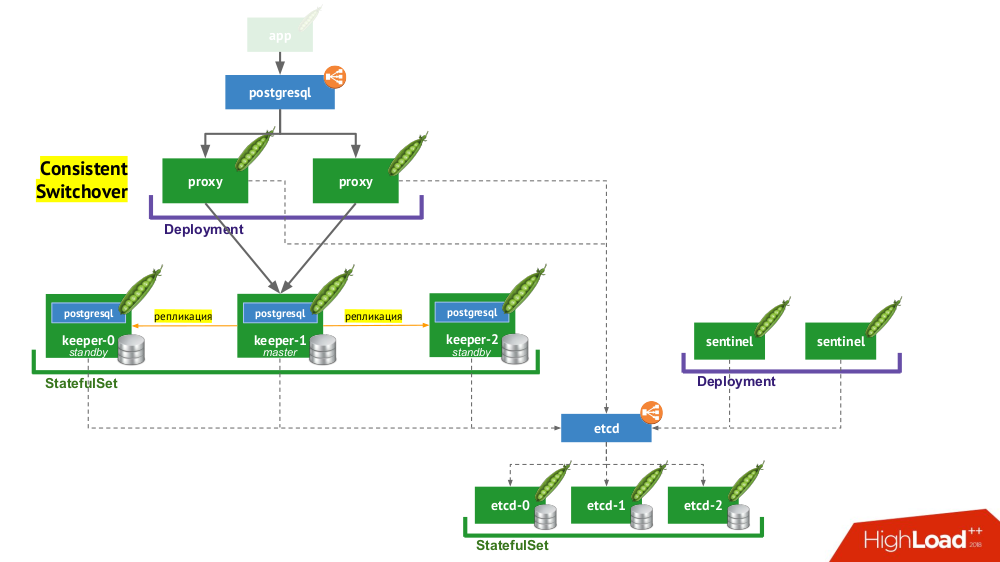
Stolon actually allows you to turn PostgreSQL DBMS, created as a pet , into a cattle . How is this achieved?
- First, you need a service discovery, in the role of which there may be etcd (other options are available) - a cluster of them is placed in
StatefulSet. - Another part of the infrastructure is
StatefulSetwith PostgreSQL instances. In addition to the DBMS itself, a component called keeper , which configures the DBMS, is also placed next to each installation . - Another component, sentinel, is deployed as
Deploymentit follows the cluster configuration. It is he who decides who will be the master and standby, writes this information to etcd. And keeper reads data from etcd and performs actions corresponding to the current status with a PostgreSQL instance. - Another component deployed to
Deploymentand facing PostgreSQL instances, the proxy, is an implementation of the Consistent Switchover pattern already mentioned . These components are connected to etcd, and if this connection is lost, then the proxy immediately kills outgoing connections, because from this moment it does not know the role of its server (now is it master or standby?). - Finally, before the proxy instances is the usual one
LoadBalancerfrom Kubernetes.
findings
So is it possible to base in Kubernetes? Yes, of course, it is possible, in some cases ... And if it is appropriate, then it is done like this (see the work scheme of Stolon) ...
Everyone knows that technologies are developing in waves. Initially, any new device can be very difficult to use, but over time, everything changes: the technology becomes available. Where are we going? Yes, it will remain like this inside, but how it will work, we will not know. In Kubernetes, operators are actively developing . So far there are not so many of them and they are not so good, but there is a movement in this direction.
Video and slides
Video from the performance (about an hour):
Presentation of the report:
PS We also found a very (!) Short text message from this report on the web - thanks for her Nikolai Volynkin.
Pps
Other reports on our blog:
- “ Monitoring and Kubernetes ”; (Dmitry Stolyarov; May 28, 2018 on RootConf) ;
- " Best Practices CI / CD with Kubernetes and GitLab "; (Dmitry Stolyarov; November 7, 2017 on HighLoad ++) ;
- “ Our experience with Kubernetes in small projects ”; (Dmitry Stolyarov; June 6, 2017 at RootConf) ;
- “ We assemble Docker images for CI / CD quickly and conveniently with dapp ” (Dmitry Stolyarov; November 8, 2016 on HighLoad ++) ;
- “ Practices of Continuous Delivery with Docker ” (Dmitry Stolyarov; May 31, 2016 at RootConf) .
You may also be interested in the following publications: