Information retrieval algorithm in ABBYY Compreno. Part 1
Hello, Habr!
My name is Ilya Bulgakov, I am a programmer at ABBYY, a department for extracting information. In a series of two posts, I will tell you our main secret - how the Extract Information technology works in ABBYY Compreno .
Earlier, my colleague Dania Skorinkin DSkorinkin managed to tell about the view on the system from the side of the engineer on the following topics:
This time we will go deeper into the bowels of ABBYY Compreno technology, talk about the architecture of the system as a whole, the basic principles of its operation and the algorithm for extracting information!

Recall the problem.
We analyze natural language texts using ABBYY Compreno technology. Our task is to extract important information for the customer represented by entities, facts and their attributes.
Onto engineer Danya wrote a post on Habr in 2014. The
parsing trees received by the semantic-syntactic parser look like this:

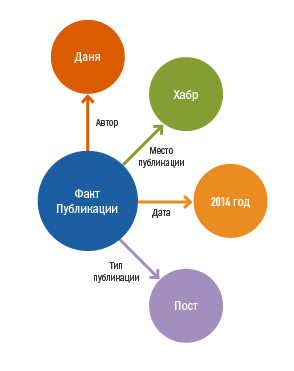
After a complete semantic-syntactic analysis, the system needs to understand what needs to be extracted from the text. This will require a domain model (ontology) and rules for extracting information. The creation of ontologies and rules is handled by a special department of computer linguists, whom we call ontologists. An example of an ontology modeling the fact of publication:

The system applies the rules to different fragments of the parse tree: if the fragment matches the template, the rule generates statements (for example, create a Person object, add the Last Name attribute, etc.). They are added to the “bag of statements” if they do not contradict the statements already contained in it. When no more rules can be applied, the system constructs an RDF graph (format for representing the extracted information) according to statements from the bag.
The complexity of the system is added by the fact that templates are built for semantic-syntactic trees, there is a wide variety of possible statements, rules can be written with almost no concern for the order of their application, the output RDF graph must correspond to a certain ontology and many other features. But let's talk about everything in order.
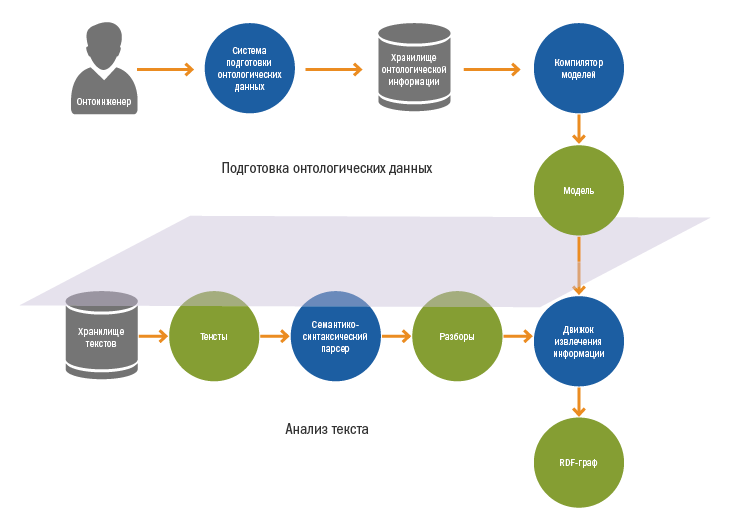
The system can be divided into two stages:
Ontological data preparation is performed by ontology engineers in a special environment. In addition to designing ontologies, ontologists are creating rules for extracting information. We spoke in detail about the process of writing rules in a previous article .
Rules and ontologies are stored in a special repository of ontological information, from where they fall into the compiler, which collects a binary model of the domain from them.
The model includes:
The compiled model goes to the input of the "engine" of information extraction.
In the very depths of ABBYY Compreno technology lies the Semantic-Syntactic Parser. The story about it is worthy of a separate article, today we will discuss only its most important features for our task. If you wish, you can study the article from the Dialogue conference .
What is important for us to know about the parser:
Inside our system, we are not working with an RDF graph, but with some internal representation of the extracted information. We consider the extracted information as a set of information objects, where each object represents a certain entity / fact and a set of statements associated with it. Inside the information extraction system, we operate with information objects.
Information objects are highlighted by the system using rules written by ontenezhnami. Objects can be used in rules to highlight other objects.
The following operations can be performed on objects:
The first four points are intuitive, and we already talked about them in a previous article. Let us dwell on the latter.
The mechanism of "anchors" occupies a very important place in the system. One information object can be, in the general case, connected by “anchors” to a certain set of nodes of semantic-syntactic trees. Snap to "anchors" allows you to re-access the objects in the rules.
Consider an example.
Ontengineer Danya Skorkin wrote a good post.

The rule below creates the person “Danya Skorkin” and connects it with two components.
The first part of the rule (before the sign =>) is a template on the parse tree. Two components with semantic classes “PERSON_BY_FIRSTNAME” and “PERSON_BY_LASTNAME” participate in the template. Two variables were mapped to them - name and surname. In the second part of the rule, the person P is created in the first line on the component, which is mapped to the variable name. This component is associated with the "anchor" with the object automatically. The second line,
The result is an information person object associated with two components.

After this, a fundamentally new opportunity appears in the template part of the rules - to verify that an information object is already attached to a specific place in the tree.
This rule will work only if an object of the Person class has been anchored to the component with the semantic class “PERSON_BY_LASTNAME”.
Why is this technique important to us?
The concept of the “anchors” mechanism is close to the concept of reference, however, it does not fully correspond to the model adopted by linguists. On the one hand, different referents of the same extracted subject are often marked with anchors. On the other hand, in practice this does not always happen, and anchor placement is sometimes used as a technical tool for the convenience of writing rules.
The arrangement of anchors in the system is a rather flexible mechanism, allowing to take into account coreferential (non-timber) connections. Using a special construction in the rules, it is possible to connect an object with an anchor not only with the selected component, but also with the components associated with it by the referential connections.
This feature is very important for increasing the completeness of the fact extraction - the allocated information objects are automatically associated with all nodes that the parser considered coreferent, after which the rules highlighting the facts begin to “see” them in new contexts.
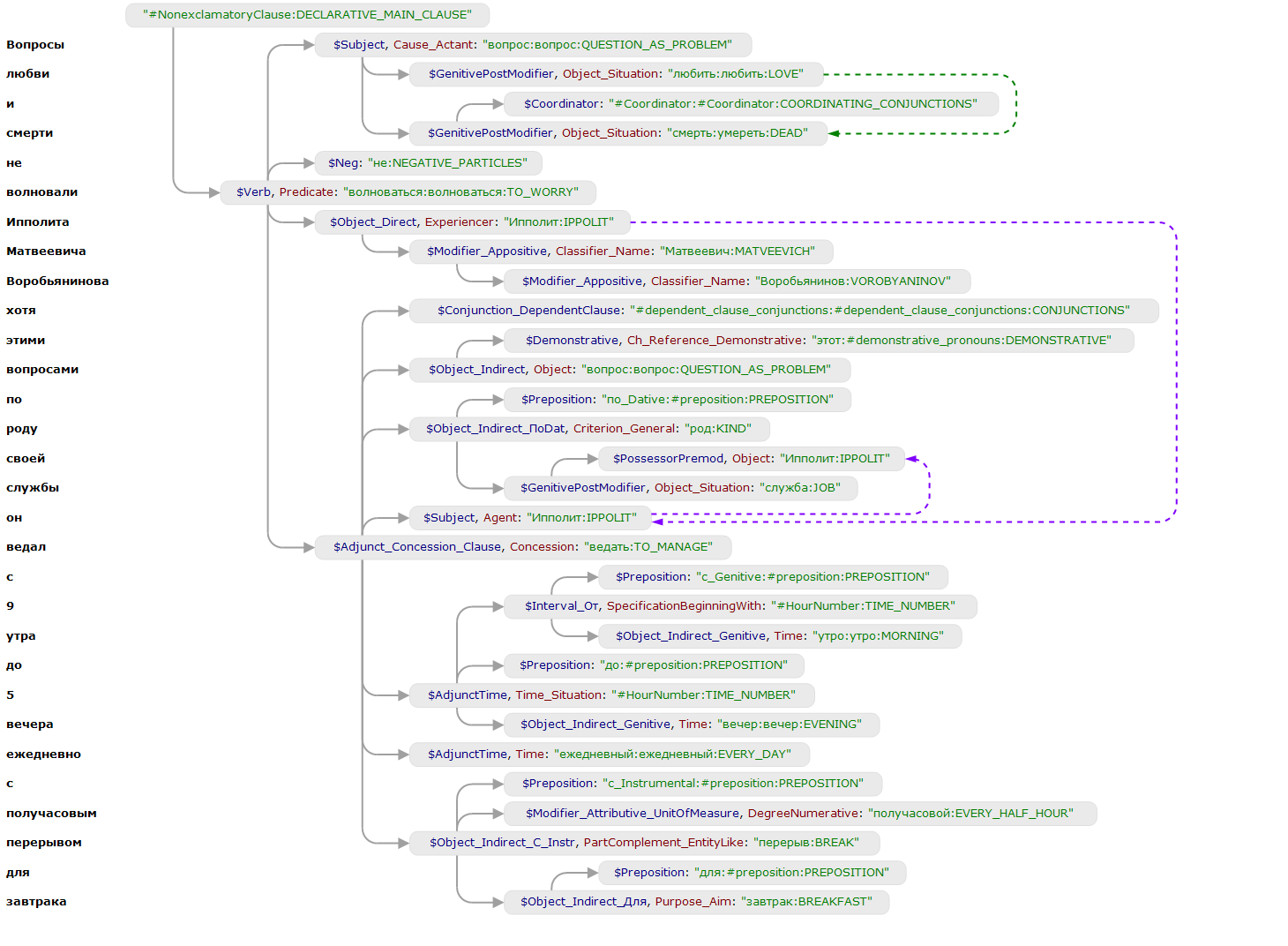
The following is an example of coreference. We analyze the text “Ippolit Matveevich Vorobyaninov did not care about love and death, although he was in charge of these issues from 9 a.m. to 5 p.m. daily, with a half-hour break for breakfast.”
The parser restores the semantic class “IPPOLIT” for the node “It”. The nodes are connected by a non-wood coreferential connection (indicated by a purple arrow).
The following construction in the rules allows us to connect an object P with an anchor, not only to the node that is mapped to the this variable, but also to those nodes that are connected to it by a co-referential connection (i.e., follow the purple arrows).
On this, the first part came to an end. In it, we talked about the general architecture of the system and dwelt in detail on the input data of the information extraction algorithm (analysis, ontology, rules).
The next post, which will be released tomorrow, we will begin right away with a discussion of how the “engine” for extracting information works and what ideas are embedded in it.
Thank you for staying with us!
Update: Part Two
My name is Ilya Bulgakov, I am a programmer at ABBYY, a department for extracting information. In a series of two posts, I will tell you our main secret - how the Extract Information technology works in ABBYY Compreno .
Earlier, my colleague Dania Skorinkin DSkorinkin managed to tell about the view on the system from the side of the engineer on the following topics:
- Trees of semantic and syntactic analysis and creation of ontologies
- Writing Information Retrieval Rules
This time we will go deeper into the bowels of ABBYY Compreno technology, talk about the architecture of the system as a whole, the basic principles of its operation and the algorithm for extracting information!
What are you talking about?
Recall the problem.
We analyze natural language texts using ABBYY Compreno technology. Our task is to extract important information for the customer represented by entities, facts and their attributes.
Onto engineer Danya wrote a post on Habr in 2014. The
parsing trees received by the semantic-syntactic parser look like this:
After a complete semantic-syntactic analysis, the system needs to understand what needs to be extracted from the text. This will require a domain model (ontology) and rules for extracting information. The creation of ontologies and rules is handled by a special department of computer linguists, whom we call ontologists. An example of an ontology modeling the fact of publication:
The system applies the rules to different fragments of the parse tree: if the fragment matches the template, the rule generates statements (for example, create a Person object, add the Last Name attribute, etc.). They are added to the “bag of statements” if they do not contradict the statements already contained in it. When no more rules can be applied, the system constructs an RDF graph (format for representing the extracted information) according to statements from the bag.
The complexity of the system is added by the fact that templates are built for semantic-syntactic trees, there is a wide variety of possible statements, rules can be written with almost no concern for the order of their application, the output RDF graph must correspond to a certain ontology and many other features. But let's talk about everything in order.
Information Retrieval System
The system can be divided into two stages:
- Preparation of ontologies and compilation of models
- Text analysis:
- Semantic and syntactic analysis of texts in natural language
- Information extraction and generation of the final RDF graph
Ontology data preparation and model compilation
Ontological data preparation is performed by ontology engineers in a special environment. In addition to designing ontologies, ontologists are creating rules for extracting information. We spoke in detail about the process of writing rules in a previous article .
Rules and ontologies are stored in a special repository of ontological information, from where they fall into the compiler, which collects a binary model of the domain from them.
The model includes:
- Ontology
- Information Retrieval Rules
- Identification Rules
The compiled model goes to the input of the "engine" of information extraction.
Semantic and syntactic analysis of texts
In the very depths of ABBYY Compreno technology lies the Semantic-Syntactic Parser. The story about it is worthy of a separate article, today we will discuss only its most important features for our task. If you wish, you can study the article from the Dialogue conference .
What is important for us to know about the parser:
- The parser generates semantic-syntactic parsing trees for sentences (one tree for one sentence). Subtrees we call constituents. As a rule, tree nodes correspond to the words of the input text, but there are exceptions: sometimes several words are grouped into one component (for example, text in quotation marks), sometimes zero nodes appear (instead of omitted words). Nodes and arcs are marked.

- Nodes rely on a semantic hierarchy. The semantic hierarchy is a tree of family relations, the intermediate nodes of which are language-independent semantic classes (for example, “HABRAHABR”), and the “leaves” are the language-specific lexical classes (“Habr: HABRAHABR”). Information on syntactic and semantic compatibility is correlated with the nodes of the hierarchy. The principle of inheritance works - everything that is true for the parent class turns out to be true for the child if there is no explicit refinement in the child class.
An example of a semantic class and lexical classes specific to different languages.

- In addition to semantic-syntactic trees, the ABBYY Compreno parser returns information about non-wood links between their nodes (additional links between nodes that cannot be represented in the tree structure). These are, first of all, relations expressing coreference (the same object of the real world is mentioned several times in the text). For example, for the phrase “Ontoengineer Dan sat and wrote a post”, for the verb “write”, the zero subject will be restored, which will be connected by a non-timber connection with the Ontoengineer node. ABBYY Compreno also uses some other types of non-wood ties. In some cases, non-wood communications can connect nodes from different sentences. This often happens, for example, when resolving the pronoun anaphora. We spoke about pronoun anaphora in detail in this post.and in a separate article at the Dialogue conference .
An example of a restored subject (a pink arrow leads to it).
Ontario Danya sat and wrote a post.
- Removing homonymy. In one of the previous articles, as an example of syntactic homonymy, we proposed to consider the phrase “These types of steel are in stock,” which can have completely different meanings in different contexts.
The removal of homonymy is due to two factors:- All restrictions inherent in the semantic hierarchy are taken into account.
The tree nodes generated by the parser are always attached to some lexical class of the semantic hierarchy. This means that in the process of analysis, the parser removes lexical ambiguity. - The statistics of compatibility are used, collected on cases of parallel texts (these are collections of texts in which texts in one language go along with their translations into another language). The idea of the approach is that, having a bilingual parser working on a single semantic hierarchy, you can collect qualitative statistics of compatibility on aligned parallel cases without additional markup.
When collecting statistics, only those aligned pairs of sentences are taken into account for which the resulting semantic structures are comparable. The latter means success in resolving homonymy, since homonymy is overwhelmingly asymmetric in different languages.
The absence of the need for additional marking allows the use of large enclosures.
- All restrictions inherent in the semantic hierarchy are taken into account.
A word about information objects
Inside our system, we are not working with an RDF graph, but with some internal representation of the extracted information. We consider the extracted information as a set of information objects, where each object represents a certain entity / fact and a set of statements associated with it. Inside the information extraction system, we operate with information objects.
Information objects are highlighted by the system using rules written by ontenezhnami. Objects can be used in rules to highlight other objects.
The following operations can be performed on objects:
- Create
- Annotate with text fragments
- Bind to ontology classes
- Fill Attributes
- Link with components using the anchors mechanism
The first four points are intuitive, and we already talked about them in a previous article. Let us dwell on the latter.
The mechanism of "anchors" occupies a very important place in the system. One information object can be, in the general case, connected by “anchors” to a certain set of nodes of semantic-syntactic trees. Snap to "anchors" allows you to re-access the objects in the rules.
Consider an example.
Ontengineer Danya Skorkin wrote a good post.
The rule below creates the person “Danya Skorkin” and connects it with two components.
name "PERSON_BY_FIRSTNAME" [ surname "PERSON_BY_LASTNAME " ]
=>
Person P(name),
Anchor(P, surname);
The first part of the rule (before the sign =>) is a template on the parse tree. Two components with semantic classes “PERSON_BY_FIRSTNAME” and “PERSON_BY_LASTNAME” participate in the template. Two variables were mapped to them - name and surname. In the second part of the rule, the person P is created in the first line on the component, which is mapped to the variable name. This component is associated with the "anchor" with the object automatically. The second line,
Anchor(P, surname)we explicitly associate the second component with the object, which is mapped to the surname variable. The result is an information person object associated with two components.
After this, a fundamentally new opportunity appears in the template part of the rules - to verify that an information object is already attached to a specific place in the tree.
name "PERSON_BY_LASTNAME" <% Person %>
=>
This.o.surname == Norm(name);
This rule will work only if an object of the Person class has been anchored to the component with the semantic class “PERSON_BY_LASTNAME”.
Why is this technique important to us?
- The entire system of fact extraction is based on already extracted information objects.
For example, when filling out the attribute “author” for the fact of publication, the rule is based on the previously created person object. - The technique helps with the decomposition of rules and improves their support.
For example, one rule can only create a person, and several others can highlight individual properties (name, surname, middle name, etc.).
The concept of the “anchors” mechanism is close to the concept of reference, however, it does not fully correspond to the model adopted by linguists. On the one hand, different referents of the same extracted subject are often marked with anchors. On the other hand, in practice this does not always happen, and anchor placement is sometimes used as a technical tool for the convenience of writing rules.
The arrangement of anchors in the system is a rather flexible mechanism, allowing to take into account coreferential (non-timber) connections. Using a special construction in the rules, it is possible to connect an object with an anchor not only with the selected component, but also with the components associated with it by the referential connections.
This feature is very important for increasing the completeness of the fact extraction - the allocated information objects are automatically associated with all nodes that the parser considered coreferent, after which the rules highlighting the facts begin to “see” them in new contexts.
The following is an example of coreference. We analyze the text “Ippolit Matveevich Vorobyaninov did not care about love and death, although he was in charge of these issues from 9 a.m. to 5 p.m. daily, with a half-hour break for breakfast.”
The parser restores the semantic class “IPPOLIT” for the node “It”. The nodes are connected by a non-wood coreferential connection (indicated by a purple arrow).
The following construction in the rules allows us to connect an object P with an anchor, not only to the node that is mapped to the this variable, but also to those nodes that are connected to it by a co-referential connection (i.e., follow the purple arrows).
// Утверждаем, что экземпляр P привязан так же к узлу, соотнесенному с
// переменной this. Служебное cлово Coreferential означает, что экземпляр
// автоматически будет привязан ко всем узлам, связанных с данным
// недревесными связями, обозначающими кореференцию.
anchor( P, this, Coreferential )
On this, the first part came to an end. In it, we talked about the general architecture of the system and dwelt in detail on the input data of the information extraction algorithm (analysis, ontology, rules).
The next post, which will be released tomorrow, we will begin right away with a discussion of how the “engine” for extracting information works and what ideas are embedded in it.
Thank you for staying with us!
Update: Part Two