Is the primary key a GUID or auto-increment? Part two
In a previous article , we considered the criteria for choosing between a GUID and auto-increment as a primary key. The main idea was that if according to some basic criteria (availability of replication, uniqueness requirements, etc.) there is a need to use a GUID, then you need to take into account the nuances associated with its performance. Tests for inserting records showed that the fastest option is sequential GUIDs generated on the client, and inserting in this case works even faster than using auto-increment. But the article did not address the performance loss of sampling when using a GUID as a key. In this article I will try to close this gap.
We will test the following scenarios:
Separation into a scenario with one child collection and several is needed to understand how much the number of connections (JOINs) by key in a single request affects the final result. And how much the decrease in performance depends on the type of key.
Using these scenarios, we compare three key options:
To do this, you need three sets of tables, each of which consists of a main table and 5 tables for child records.
We will conduct testing, as in the previous article, using the Entity Framework 6.1.3. Database - Microsoft SQL Server 2014 Developer Edition (64 bit). Add 10,000 records to each of the main tables, where each record will have 5 child collections containing 10 elements. Thus, the tables of the child collections will contain 100,000 rows.
The source code for the test program can be found here .
Below are charts of the results. For convenience of comparison, percentages are indicated on them, where the minimum result of all options is taken as 100%.
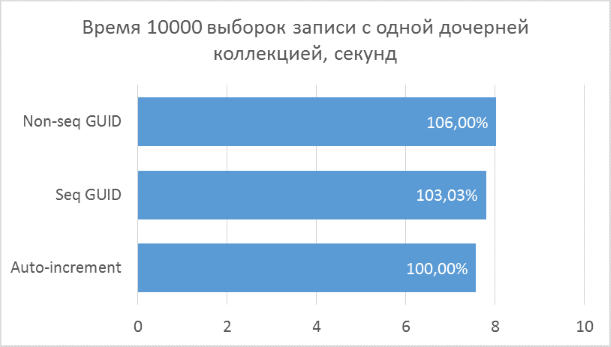

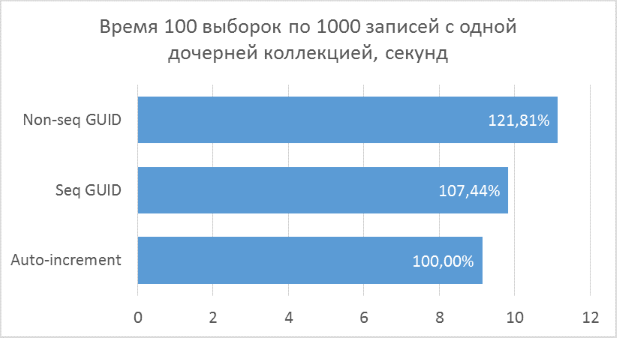
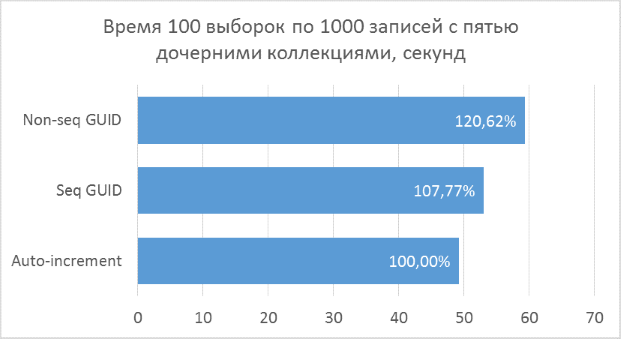
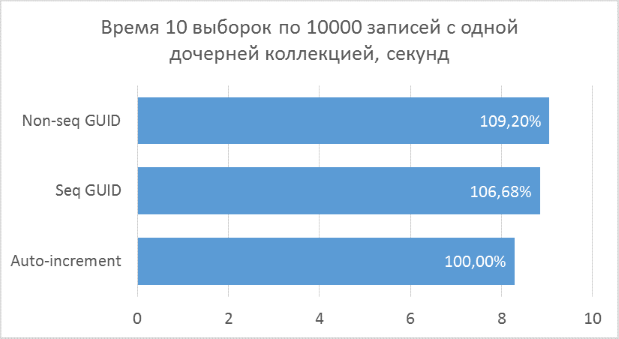
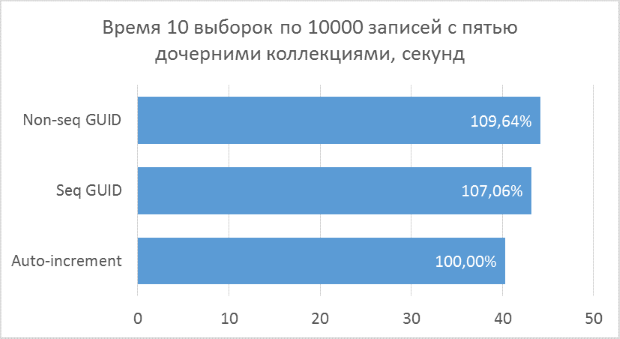
The results show that the selection operations that operate on integer keys are, of course, faster than in the case of the GUID. But the difference in performance between the sequential GUID and auto-increment is not so great as to tell a significant loss when choosing a GUID.
It should also be noted that the percentage difference in runtime persists with an increase in the number of connections in one request. Which, in fact, was to be expected, but it was necessary to make sure.
Inconsistent GUID in some cases showed significantly worse results, which, again, is natural. In practice, the difference between it and the other two options may turn out to be even greater - in cases where the database cannot be fully cached in RAM and a large amount of reads from the disk is required to get all neighboring child records (a similar test was described in a previous article to insert records). Accordingly, it makes no sense to use such a variant of the primary key in practice.
Despite the fact that this test showed a slight difference between auto-increment and sequential GUID, I would not consider the latter as an option that can be thoughtlessly used in all situations. The GUID takes up more space, especially in textual representation. If the system has a conversion of objects to a text format (JSON, XML), and a portion of objects converted at one time contains a large number of identifiers, the difference in volume compared to integer keys can be significant. The inverse transformation (deserialization) for a GUID is much slower than for a number, but, in my opinion, this difference can be neglected. This time is still very short - on my machine it takes 60 milliseconds to parse a hundred thousand GUIDs, against 12 milliseconds for integers.
I would formulate the general conclusion based on the results of both articles as follows: if for any reasons not related to performance, there is a need to use a GUID as a primary key, then from the possible implementations, choose the sequential generated on the client. In this case, in most cases, you can not worry about the loss of performance of read operations. The main problem with GUIDs in terms of sample performance is not that the processor needs to do more actions for comparison (this is most likely optimized, and there are few comparisons when searching by key, if this is not a scan), but because it takes 4 times more than usual int, correspondingly fewer pages of indexes and data can be cached in the same amount of RAM. If in your database the indexes of primary and foreign keys occupy tens of percent of the total database and the volume of actively used data cannot be fully cached, and there is no way to increase the amount of RAM, it makes sense to think about more “easy” keys. But this situation seems rather rare to me. You should also pay attention to the potential problems with serialization / deserialization mentioned above. However, the corresponding case, which I saw in practice, was not so much a problem of the GUID itself as a problem of incorrect design of the API - the entire collection was read out at a time without restrictions, paging, etc. and there is no way to increase the amount of RAM - it makes sense to think about more "light" keys. But this situation seems rather rare to me. You should also pay attention to the potential problems with serialization / deserialization mentioned above. However, the corresponding case, which I saw in practice, was not so much a problem of the GUID itself as a problem of incorrect design of the API - the entire collection was read out at a time without restrictions, paging, etc. and there is no way to increase the amount of RAM - it makes sense to think about more "light" keys. But this situation seems rather rare to me. You should also pay attention to the potential problems with serialization / deserialization mentioned above. However, the corresponding case, which I saw in practice, was not so much a problem of the GUID itself as a problem of incorrect design of the API - the entire collection was read out at a time without restrictions, paging, etc.
We will test the following scenarios:
- Search for a single record by primary key with proofreading of one child collection
- Search for a single record by primary key with the proof of several child collections
- Fetching multiple records with the subtraction of one child collection for each record
- Selection of several records with the subtraction of several child collections for each record
- Selection of all records from the table with subtraction of one child collection for each record
- Fetch all records from the table with the subtraction of all child collections
Separation into a scenario with one child collection and several is needed to understand how much the number of connections (JOINs) by key in a single request affects the final result. And how much the decrease in performance depends on the type of key.
Using these scenarios, we compare three key options:
- Auto increment
- Serial GUID
- Inconsistent GUID
To do this, you need three sets of tables, each of which consists of a main table and 5 tables for child records.
We will conduct testing, as in the previous article, using the Entity Framework 6.1.3. Database - Microsoft SQL Server 2014 Developer Edition (64 bit). Add 10,000 records to each of the main tables, where each record will have 5 child collections containing 10 elements. Thus, the tables of the child collections will contain 100,000 rows.
The source code for the test program can be found here .
Below are charts of the results. For convenience of comparison, percentages are indicated on them, where the minimum result of all options is taken as 100%.
The results show that the selection operations that operate on integer keys are, of course, faster than in the case of the GUID. But the difference in performance between the sequential GUID and auto-increment is not so great as to tell a significant loss when choosing a GUID.
It should also be noted that the percentage difference in runtime persists with an increase in the number of connections in one request. Which, in fact, was to be expected, but it was necessary to make sure.
Inconsistent GUID in some cases showed significantly worse results, which, again, is natural. In practice, the difference between it and the other two options may turn out to be even greater - in cases where the database cannot be fully cached in RAM and a large amount of reads from the disk is required to get all neighboring child records (a similar test was described in a previous article to insert records). Accordingly, it makes no sense to use such a variant of the primary key in practice.
Despite the fact that this test showed a slight difference between auto-increment and sequential GUID, I would not consider the latter as an option that can be thoughtlessly used in all situations. The GUID takes up more space, especially in textual representation. If the system has a conversion of objects to a text format (JSON, XML), and a portion of objects converted at one time contains a large number of identifiers, the difference in volume compared to integer keys can be significant. The inverse transformation (deserialization) for a GUID is much slower than for a number, but, in my opinion, this difference can be neglected. This time is still very short - on my machine it takes 60 milliseconds to parse a hundred thousand GUIDs, against 12 milliseconds for integers.
I would formulate the general conclusion based on the results of both articles as follows: if for any reasons not related to performance, there is a need to use a GUID as a primary key, then from the possible implementations, choose the sequential generated on the client. In this case, in most cases, you can not worry about the loss of performance of read operations. The main problem with GUIDs in terms of sample performance is not that the processor needs to do more actions for comparison (this is most likely optimized, and there are few comparisons when searching by key, if this is not a scan), but because it takes 4 times more than usual int, correspondingly fewer pages of indexes and data can be cached in the same amount of RAM. If in your database the indexes of primary and foreign keys occupy tens of percent of the total database and the volume of actively used data cannot be fully cached, and there is no way to increase the amount of RAM, it makes sense to think about more “easy” keys. But this situation seems rather rare to me. You should also pay attention to the potential problems with serialization / deserialization mentioned above. However, the corresponding case, which I saw in practice, was not so much a problem of the GUID itself as a problem of incorrect design of the API - the entire collection was read out at a time without restrictions, paging, etc. and there is no way to increase the amount of RAM - it makes sense to think about more "light" keys. But this situation seems rather rare to me. You should also pay attention to the potential problems with serialization / deserialization mentioned above. However, the corresponding case, which I saw in practice, was not so much a problem of the GUID itself as a problem of incorrect design of the API - the entire collection was read out at a time without restrictions, paging, etc. and there is no way to increase the amount of RAM - it makes sense to think about more "light" keys. But this situation seems rather rare to me. You should also pay attention to the potential problems with serialization / deserialization mentioned above. However, the corresponding case, which I saw in practice, was not so much a problem of the GUID itself as a problem of incorrect design of the API - the entire collection was read out at a time without restrictions, paging, etc.