按标签查看文章: clickhouse

ClickHouse跳过索引:bloom、set、minmax
ClickHouse跳过索引如何加速对ORDER BY之外列的查询。通过游戏和EXPLAIN示例,详细解析minmax、set、bloom_filter、ngrambf_v1、tokenbf_v1。

ClickHouse 物化视图:INSERT 触发器
ClickHouse 中 MV 的工作原理:增量聚合、分钟→小时→天链、Null+Kafka 模式、POPULATE 及其风险。包含 SummingMergeTree 和 AggregatingMergeTree 的示例。
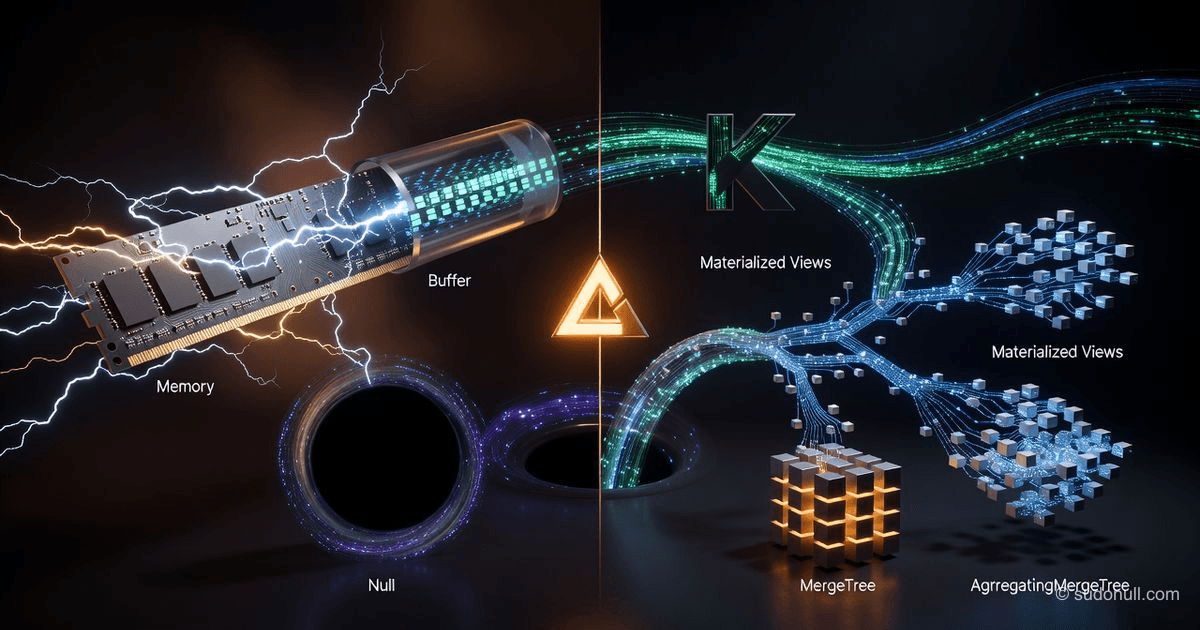
特殊ClickHouse引擎:何时不需要MergeTree
ClickHouse内存、缓冲区、空、日志、URL、S3和PostgreSQL引擎概述。包括系数缓存、从Kafka缓冲插入以及从外部数据库获取实时数据的示例。

ClickHouse中的字典:无需JOIN的快速查找
如何使用ClickHouse字典替代JOIN,实现微秒级内存查找。类型:flat/hashed/range、数据源、dictGet以及赌博场景示例。

ClickHouse中的TTL:数据生命周期管理
ClickHouse中的TTL如何自动删除、移动到HDD/S3、聚合和匿名化数据。适用于GDPR、分层存储和分组旧记录的示例。

ClickHouse中的ORDER BY和PRIMARY KEY:索引选择
如何在ClickHouse中正确选择ORDER BY:稀疏索引、列基数、等值与范围、通过EXPLAIN验证。赌博平台的规则和示例。

ClickHouse中的分区:策略与操作
ClickHouse中的分区如何加速DROP和数据管理。选择分区大小,system.parts,DETACH/ATTACH,FREEZE,MOVE到SSD/HDD,以及删除旧数据的脚本。

ClickHouse中的CollapsingMergeTree:无需UPDATE即可更新
CollapsingMergeTree和VersionedCollapsingMergeTree如何在ClickHouse中替代UPDATE:符号列、折叠对、SUM(amount*sign)、排序问题及通过版本解决的方案。

ClickHouse中的SummingMergeTree和AggregatingMergeTree
ClickHouse中的增量聚合:SummingMergeTree和AggregatingMergeTree如何将仪表盘加速100倍。示例、物化视图、陷阱和比较。

ClickHouse中的ReplacingMergeTree:完整指南
了解ReplacingMergeTree如何去除重复项、与版本和FINAL配合使用。包含示例、陷阱以及与CollapsingMergeTree的高级去重对比。

ClickHouse:为什么列式数据库管理系统能将分析速度提升100倍
我们使用真实基准测试和投注方案进行解释:ClickHouse vs PostgreSQL 和 MySQL。架构、查询示例、使用场景。阅读时间5分钟。
ClickHouse 物化视图:细微差别与解决方案
ClickHouse 中的 MV 如何工作?与传统 DBMS 的关键差异、UPDATE/DELETE 限制以及最佳实践。了解如何避免设计错误。

ClickHouse:MV 中的去重和数据丢失
ClickHouse 中由于物化视图中的块去重导致的数据丢失分析。设置 insert_deduplicate=0 和 deduplicate_blocks_in_dependent_materialized_views=1。配置无损存储 — 阅读详情。

Kafka Engine ClickHouse:无损失原子性
在 ClickHouse 中设置 Kafka Engine 以实现来自流可靠的插入。演示 offset-commit,避免故障时丢失。中高级开发者指南。

ClickHouse 与 Airflow 替代 PostgreSQL 用于大数据
了解为什么 Airflow + ClickHouse 正在取代分析中的 PostgreSQL。性能比较、数据工程师示例。为 ETL 管道切换到列式数据库。

ClickHouse 中的 CTE:宏而非优化
剖析 ClickHouse 中 WITH 为什么执行多次,以及如何用临时表替换。代码示例、EXPLAIN、开发者比较。加速查询无陷阱。

ClickHouse 中的 CPU 80% 诊断
ClickHouse 中查找问题查询的工具:system.processes、query_log、EXPLAIN。诊断步骤、SQL 示例、检查清单。无停机优化负载。