Raising a simplified provider network at home
- Tutorial
 Initially, this article was a laboratory work diary that I came up with for myself. Gradually, it began to seem to me that this information might be useful to someone else. Therefore, I tried to convert the note into a more or less decent look, add a description of some commands and technologies.
Initially, this article was a laboratory work diary that I came up with for myself. Gradually, it began to seem to me that this information might be useful to someone else. Therefore, I tried to convert the note into a more or less decent look, add a description of some commands and technologies. The article discusses the construction of a simple network with several providers and clients, in particular, technologies such as NAT, OSPF, BGP, MPLS VPN. Much, of course, will not be taken into account. For example, the article has almost no description of security problems, as you can talk endlessly on this subject, and the text is already quite voluminous. QoS is also left aside, as under laboratory conditions, you won’t especially check it.
About the target audience. For newcomers to networks, the article, I am afraid, will be incomprehensible. People who have knowledge at least at the CCNP level are not interested. Therefore, I approximately focus on CCNA R&S certification.
Lab built on the Cisco IOU emulator. About its installation and use has been written a lot of that , so I will not repeat.
The images i86bi_linux-adventerprisek9-ms.152-4.M1 and i86bi_linux_l2-ipbasek9-ms.jan24-2013-B are used.
We decide on the topology and IP addressing.
After some thought, I decided to make such a scheme:

Now it remains to come up with a legend:
- AS1234 is a major ISP1 provider. Owns a network of 50.0.0.0/16.
- AS67 is the ISP2 provider. Owns a network of 100.0.0.0/16. Needed to add extra complexity to the topology.
- AS812 - Customer Customer1. It owns the IPv4 175.0.0.0/24 PI block of IP addresses, but uses exclusively IPv6 inside its network.
- AS65000 - Customer2 Customer. It receives an address block 50.0.109.0/24 from the provider. Inside the network, it uses private addresses from the 192.168.109.0/24 subnet. AS65000 - Private.
- AS1114 - Customer3 Customer. Owns a block of PI addresses 150.0.0.0/24. It also uses them for internal nodes.
For simplicity, on p2p links between routers in different AS we will use addresses of the form 200.0.xy.0 / 24, where x, y are the numbers of the routers, x> y.
p2p links inside providers will also have a / 24 mask (it’s clear that this is wasteful, but it will be much easier to configure routing) and look like 50.0.xy.0 (100.0.xy.0 for AS67), where x, y are the numbers of routers, x> y.
Initial setup
Basic configuration
To begin, fill in all routers with approximately the same configuration (example for R2):
enable
configure terminal
Turn on aaa and configure the ability to log into the router remotely with local details:
aaa new-model
aaa authentication login default local
username cisco privilege 15 secret cisco
no ip domain-lookup
We write down everything necessary for ssh v1.99 and allow only it in the line parameters:
ip domain-name isp1.com
hostname R2
crypto key generate rsa modulus 2048
line console 0
exec-timeout 0
line vty 0 4
transport input ssh
exec-timeout 0
On each router, create several loopbacks. lo0 for routing protocols, the rest for simulating client connections so that the RIB does not look too small. It is clear that if the provider owns the 50.0.0.0/16 subnet, he has no right to announce, for example, the 2.0.0.0/24 subnet, but for clarity, we will assume that this situation is possible:
interface loopback 0
ip address 2.2.2.2 255.255.255.255
interface loopback 1
ip address 2.0.0.2 255.255.255.0
interface loopback 2
ip address 2.0.1.2 255.255.255.0
interface loopback 3
ip address 2.0.2.2 255.255.255.0
interface loopback 4
ip address 2.0.3.2 255.255.255.0
Assign the addresses and disable CDP on those interfaces that do not look at the router adjacent to AS:
interface ethernet 0/0
ip address 200.0.62.2 255.255.255.0
no cdp enable
no shutdown
interface ethernet 0/1
ip address 50.0.32.2 255.255.255.0
no shutdown
interface ethernet 0/2
ip address 200.0.72.2 255.255.255.0
no cdp enable
no shutdown
interface ethernet 0/3
ip address 50.0.52.2 255.255.255.0
no shutdown
end
write
Now you need to configure our customers.
HSRP, Stateful NAT
Let's start with the AS65000. From it, the 192.168.109.0/24 subnet will be broadcast to the address block 50.0.109.0/24 issued by the provider. At the same time, the autonomous system is connected to one ISP through two routers, therefore, to ensure redundancy, they will need to configure HSRP. In this regard, when using normal NAT, an asymmetric routing problem may arise:
- The private address is broadcast to the public on one of the routers.
- The answer comes to the second router.
- The second router does not have a translation rule for this packet, so it will simply drop the packet.
- To solve this problem, the official Cisco website suggests using Stateful NAT .

First, configure HSRP (config on R10).
Large companies rarely have just one VLAN, so we’ll do all the settings on the subinterface for 109 VLANs:
Create an HSRP group:
R10(config)#interface ethernet 0/1.109
R10(config-subif)#encapsulation dot1Q 109
R10(config-subif)#ip address 192.168.109.10 255.255.255.0
R10(config-subif)#standby 109 ip 192.168.109.109
R10(config-subif)#standby 109 preempt
R10(config-subif)#standby 109 name SNAT
We configure the ACL and NAT pool for Stateful NAT in the same way as for normal (mask length 25, not 24, because it was decided to leave half the subnet for other needs not considered here):
R10(config)#ip access-list standard SNAT_INSIDE
R10(config-std-nacl)#permit 192.168.109.0 0.0.0.255
R10(config)#ip nat pool SNAT_OUTSIDE 50.0.109.1 50.0.109.126 prefix-length 25
Configure Stateful NAT directly:
R10(config)#ip nat stateful id 109
R10(config-ipnat-snat)#redundancy SNAT
R10(config-ipnat-snat-red)#protocol udp
R10(config-ipnat-snat-red)#mapping-id 109
R10(config)#ip nat inside source list SNAT_INSIDE pool SNAT_OUTSIDE mapping-id 109 overload
And enable it on the interfaces:
R10(config)#interface ethernet 0/0
R10(config-if)#ip nat outside
R10(config)#interface ethernet 0/1.109
R10(config-subif)#ip nat inside
On eth 0/2 it is applicable so that in case the packet arrives at R10 and R5 is not available, the address is still broadcast and reaches the destination:
R10(config)#interface ethernet 0/2
R10(config-if)#ip nat outside
You can do it another way - do not use ip nat outside on eth0 / 2 of R10, but ip nat inside on eth0 / 1 of R9. The result will be exactly the same, the main thing is to understand why this is done and how it works.
On R9, the configuration is similar.
The configuration of SW13 is not given due to its simplicity. We will make the interfaces looking at routers trunks with encapsulation in 109 VLAN. We will also configure the interface in 109 VLAN'e to test our solution.
After that, you can raise the test routing on routers R3, R4, R5, R9 and R10 so that the ping goes along this path:
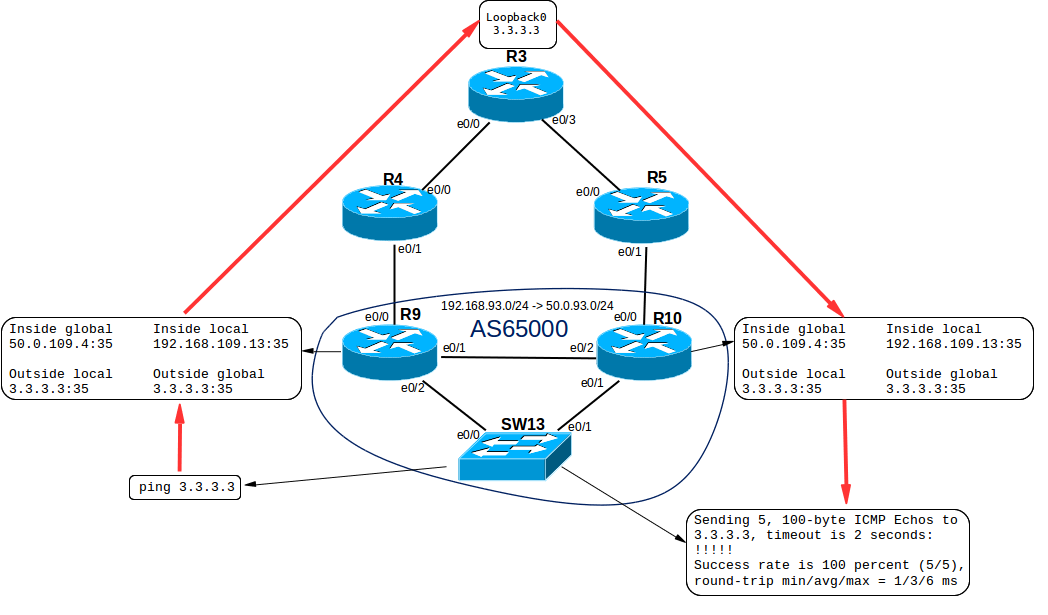
SW13#ping 3.3.3.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 3.3.3.3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/3/6 ms
R9#sh ip nat translations
Pro Inside global Inside local Outside local Outside global
icmp 50.0.109.4:35 192.168.109.13:35 3.3.3.3:35 3.3.3.3:35
--- 50.0.109.4 192.168.109.13 --- ---
R10#sh ip nat translations
Pro Inside global Inside local Outside local Outside global
icmp 50.0.109.4:35 192.168.109.13:35 3.3.3.3:35 3.3.3.3:35
--- 50.0.109.4 192.168.109.13 --- ---
As we can see, the information was synchronized between the two HSRP routers, and during asymmetric routing, the ping passed back through the router that did not translate the address directly.
IPv6, NAT-PT
Now let's turn to AS812. Recall that local engineers are actively introducing innovations, so the entire internal network is built on IPv6. Nevertheless, the provider to which this company is connected did not even hear about the existence of IPv6, so you will have to use NAT-PT (Protocol Translation) on the border router .
This technology, as the name implies, allows broadcasting from one network protocol to another, and, accordingly, communicate with hosts that support only IPv6 or only IPv4.
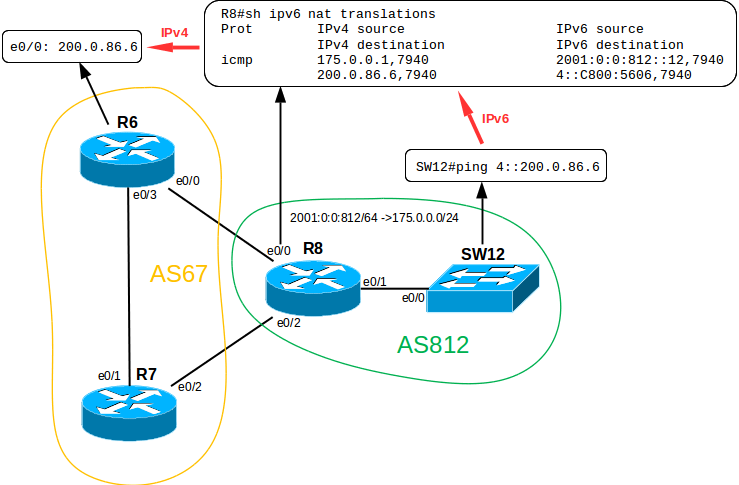
If we try to do this without translation, we get something like this:
SW12#ping 200.0.86.6
% Unrecognized host or address, or protocol not running.
Let's decide on the addressing: suppose that one large subnet is used 2001: 0: 0: 812 :: / 64
Then the interface address eth0 / 1 on R8 will be 2001: 0: 0: 812 :: 8/64.
Enable IPv6 packet routing:
R8(config)#ipv6 unicast-routing
Set IPv6 Address:
R8(config)#interface ethernet 0/1
R8(config-if)#ipv6 address 2001:0:0:812::8/64
Enable NAT on the interfaces:
R8(config)#interface range eth 0/0-2
R8(config-if-range)#ipv6 nat
We create an IPv4 pool to which our internal IPv6 addresses will be broadcast:
R8(config)#ipv6 nat v6v4 pool 6TO4 175.0.0.1 175.0.0.254 prefix-length 24
An ACL containing a prefix, when entered before an IPv4 address, we will inform the router that we need translation:
R8(config)#ipv6 access-list v6LIST
R8(config-ipv6-acl)#permit ipv6 any 4::/96
Apply this ACL:
R8(config)#ipv6 nat prefix 4::/96 v4-mapped v6LIST
And, actually, enable NAT-PT:
R8(config)#ipv6 nat v6v4 source list v6LIST pool 6TO4 overload
Note that the prefix length is 96 bits. If we take into account that the total length of the IPv6 address is 128 bits, we get the remaining 32 bits, which is equal to the length of the IPv4 address.
We check. Temporarily create the necessary routes on R6 and R8 and try to ping R6 from switch SW12:
SW12#ping 4::200.0.86.6
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4::C800:5606, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/3 ms
As we can see, the technology works. In order for the dedicated subnet 175.0.0.0/24 not to be wasted (after all, it’s extremely stupid to buy PI addresses and use them only for dynamic NAT), we could configure static translations v6v4 and v4v6, for example, an internal server having an IPv6 address was accessible from an external network by IPv4 address. Nevertheless, we will not do this.
At the moment, there’s nothing more for clients to configure, so you can proceed to configure routing.
OSPF, configuring routing within an autonomous system
Let's start with IGP, in particular with OSPF. EIGRP will not be considered, because on such small networks, there are few fundamental differences in configuration.
In the ISP1 provider's network, all routers except R1 are connected on a one-to-one basis. Since R1 is connected with only one link, it makes sense to place it in a completely totally stubby area (i.e., give R1 only the default route to R3).
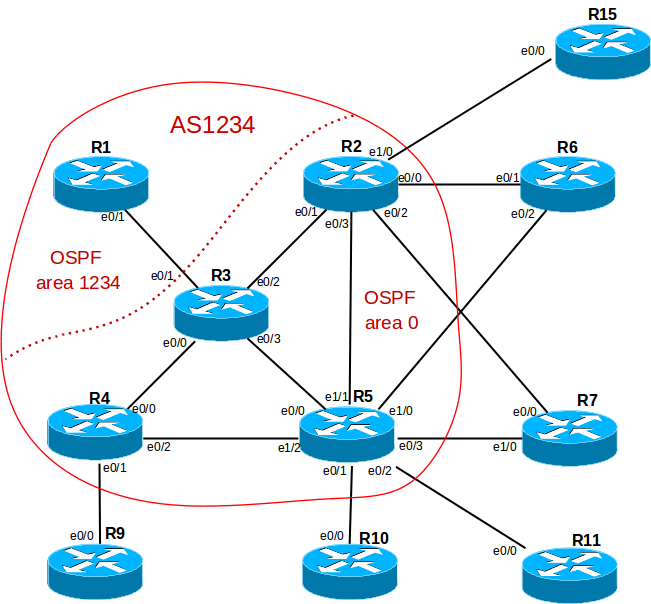
Here is an example of OSPF configuration on R3:
R3(config)#router ospf 1234
R3(config-router)#router-id 3.3.3.3
By default, we prohibit all interfaces from participating in the OSPF process, and then enable only the necessary ones (specifically, on R3, these commands have absolutely no meaning, since all its interfaces will be involved):
R3(config-router)#passive-interface default
R3(config-router)#no passive interface e0/1
R3(config-router)#no passive interface e0/2
R3(config-router)#no passive interface e0/3
R3(config-router)#no passive interface e0/4
The following command makes it possible, when changing the network map, to start the SPF process only partially, for a separate branch of the tree, which in large networks can slightly reduce the convergence time of the topology:
R3(config-router)#ispf
Add the network to the deadlock region and configure the region itself:
R3(config-router)#network 50.0.31.0 0.0.0.255 area 1234
R3(config-router)#area 1234 stub no-summary
Add subnets from the main region:
R3(config-router)#network 50.0.32.0 0.0.0.255 area 0
R3(config-router)#network 50.0.43.0 0.0.0.255 area 0
R3(config-router)#network 50.0.53.0 0.0.0.255 area 0
You can, of course, announce this:
R3(config-router)#network 50.0.0.0 0.0.255.255 area 0
but:
- There is a chance to accidentally capture an extra subnet;
- Deleting one of the summarized subnets may cause problems;
- This in principle gives less control over the situation and increases the risk of error.
You can also declare that the subnet belongs to the ospf process directly on the interface (and this is the only way in IPv6), but the method I use is trite faster (in my opinion), and more clearly, when the entire configuration associated with a particular protocol is stored in one place.
We add networks with loopbacks with the redistribute connected command. This must be done carefully, because there is always a risk of announcing something that I would not want to announce. Therefore, we will use the route-map to set clear restrictions:
R3(config)#ip access-list standard REDISTRIBUTE_CONNECTED
R3(config-std-nacl)#permit host 3.3.3.3
R3(config-std-nacl)#permit 3.0.0.3 0.0.0.255
R3(config-std-nacl)#permit 3.0.1.3 0.0.0.255
R3(config-std-nacl)#permit 3.0.2.3 0.0.0.255
R3(config-std-nacl)#permit 3.0.3.3 0.0.0.255
R3(config)#route-map REDISTRIBUTE_CONNECTED
R3(config-route-map)#match ip address REDISTRIBUTE_CONNECTED
R3(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED subnets
In general, route-map is an extremely flexible and convenient technology that allows you to create almost anything with subnets: summarize, hang various tags, labels, change all kinds of parameters, package routes, etc. In the section on configuring BGP, I will touch on route-maps in a little more detail.
Let us dwell in more detail on what else the redistribute command stands out:
R5(config)#do sh ip route
-----------------------------------------------------------------
3.0.0.0/8 is variably subnetted, 5 subnets, 2 masks
O E2 3.0.0.0/24 [110/20] via 50.0.53.3, 00:19:17, Ethernet0/0
O E2 3.0.1.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0
O E2 3.0.2.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0
O E2 3.0.3.0/24 [110/20] via 50.0.53.3, 00:19:07, Ethernet0/0
O E2 3.3.3.3/32 [110/20] via 50.0.53.3, 00:19:37, Ethernet0/0
-----------------------------------------------------------------
O 50.0.32.0/24 [110/20] via 50.0.53.3, 00:21:43, Ethernet0/0
O 50.0.43.0/24 [110/20] via 50.0.53.3, 00:21:43, Ethernet0/0
If we carefully look at the routing table, we will see that the subnets created by the redistribute connected command are marked as external routes for this AS, unlike those added by the network command. Accordingly, R3 becomes ASBR (Autonomous System Boundary Router), although in fact it is not.
Also, with the type of route E2 (and this label is set by default), the metric will not be recalculated, as is usually the case in the SPF process (that is, with an increase in the length of the path to the subnet, the cost of links will not be taken into account).
This can be avoided like this:
R3(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED subnets metric-type 1
Back to R1. After configuring area 1234 as totally stubby in the routing table, we will see only one route that came via OSPF. As expected, this is the default gateway:
R1(config-router)#do sh ip route
--------------------------------------------------------------
Gateway of last resort is 50.0.31.3 to network 0.0.0.0
O*IA 0.0.0.0/0 [110/11] via 50.0.31.3, 00:00:00, Ethernet0/1
-------------------------------------------------------------
All other routers in the laboratory are configured approximately the same, so there is no point in focusing on them.
BGP, configuration of routing between autonomous systems
Recently, at an interview in one large and well-known integrator, I was asked the question: “Why do we need IGP when we have iBGP?”. The answer about the terrible speed of protocol convergence compared to IGP, the need for a full-mesh topology (or Route Reflector), and the increased resource requirements of each router in the topology did not satisfy them.
It was only when I left the meeting room that I remembered that BGP would not put routes in the RIB for which next-hop is not available.
Accordingly, without IGP from internal routers, we will not be able to reach the next-hop (which, as a rule, is the eBGP address of the peer that is not connected directly) and we will not be able to route. I think they wanted to hear exactly that from me. By the way, they nevertheless offered me a position, but this is a completely different story.
Now a little more about the relationship of the neighborhood. In fact, in a good way, it would be worthwhile to establish relationships between eBGP peers using their loopback addresses. However, we do not have an urgent need for this. Each router is connected to each no more than one link; accordingly, this will not affect fault tolerance.
In order to reach the neighboring loopback for eBGP peers, we would need the following actions:
- Static route on neighbor loopback
- redistribute static in OSPF (you can do without this if you use the next-hop self command on all iBGP peers, but somehow I don’t really like to do this);
- The neighbor nnnn ebgp-multihop 2 command in order to increase the ttl of service BGP packets (default is 1);
- Neighbor nnnn update-source lo0 command
To reduce the configuration, we will use:
- loopback addresses for communication between iBGP peers (this really makes sense, because even if one of the links crashes, the TCP session will remain alive due to redundant connections);
- addresses on physical interfaces for eBGP peers
We will configure BGP in a standalone system 1234.
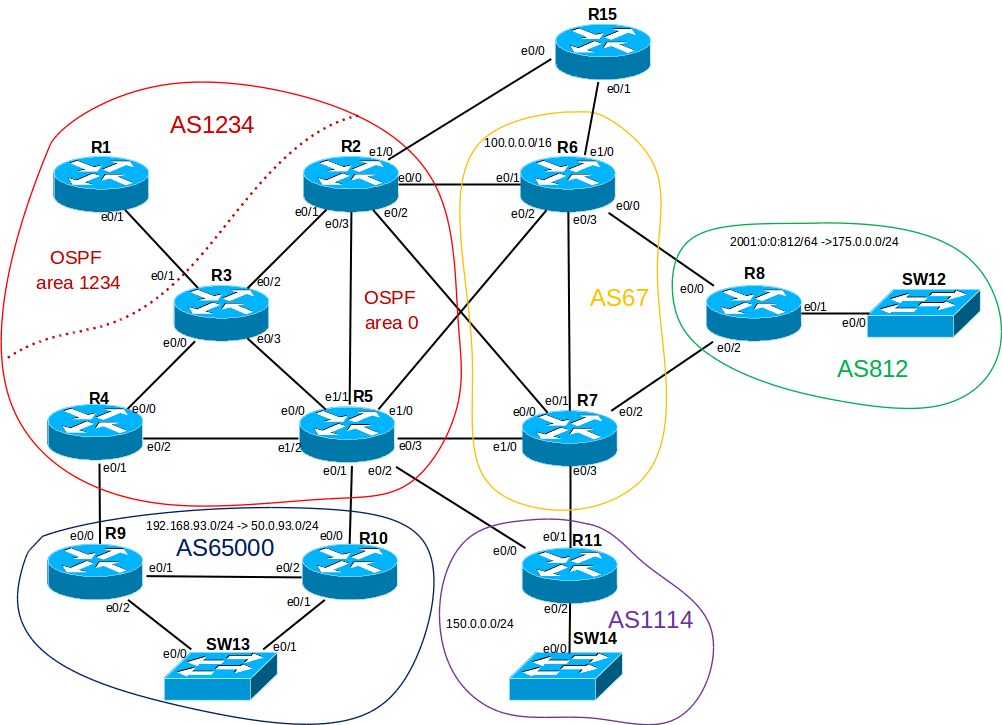
First, a small checklist:
- prefix-list filtering private networks;
- prefix-list filtering p2p links;
- prefix-list filtering addresses on lo0;
- prefix-list, filtering addresses advertised by a neighboring AS;
- route-map for a neighbor;
- route-map for the announcement of connected networks (if suddenly we do not want to announce them with the network command);
- directly BGP configuration;
The community attribute will not be used. In this case, the network is small, peer-to-peer wars are not expected, there will be no DDOS from anywhere, so there will be more confusion from the community, in my opinion, than good.
Why do we do filtering at all? Then, if the client is inadequate and suddenly decides to announce everything he wants (in our case, AS65000 will try to do just that), the provider MUST stop these actions on his part.
Let's go through the list. For example, we will configure R4:
1) Because it’s just a laboratory one, we’ll filter not all networks, but only the 3 most famous ones (there are still a bunch of prefixes reserved for different needs, for example 127.0.0.0/8):
R4(config)#ip prefix-list PRIVATE_IP permit 10.0.0.0/8 le 32
R4(config)#ip prefix-list PRIVATE_IP permit 172.16.0.0/12 le 32
R4(config)#ip prefix-list PRIVATE_IP permit 192.168.0.0/16 le 32
2) p2p links between routers inside an autonomous system, in my opinion, information that there is no need to disclose, so it’s better to leave it inside AS:
R4(config)#ip prefix-list P2P permit 50.0.31.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.32.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.43.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.52.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.53.0/24 le 32
R4(config)#ip prefix-list P2P permit 50.0.54.0/24 le 32
3) Our lo0 addresses should not be routed either. in this way, we can harm the real host 1.1.1.1, or, for example, make the google DNS server with the address 8.8.8.8 unavailable (in fact, for a long time already, all providers have been filtering networks with a mask of / 25 or more).
R4(config)#ip prefix-list LOOPBACK permit 1.1.1.1/32
R4(config)#ip prefix-list LOOPBACK permit 2.2.2.2/32
R4(config)#ip prefix-list LOOPBACK permit 3.3.3.3/32
R4(config)#ip prefix-list LOOPBACK permit 4.4.4.4/32
R4(config)#ip prefix-list LOOPBACK permit 5.5.5.5/32
4) Our neighboring AS65000 is not transitory, therefore, it cannot announce anything except the 50.0.109.0/24 subnet issued to it. We control this:
R4(config)#ip prefix-list ADVERTISED permit 50.0.109.0/24 le 32
This concludes with filtering. I have never (at the time of writing this part of the article) been working in ISP, but I have a very strong suspicion that they have several times more routes filtered in BGP, and the goals for this can be very different.
5) It's time to configure route-map. Since we wrote “permit” in the prefix sheets, now we will write “deny”.
Outbound filtering:
R4(config)#route-map AS65000_OUT deny 10
R4(config-route-map)#match ip address prefix-list LOOPBACK
R4(config-route-map)#match ip address prefix-list P2P
R4(config-route-map)#match ip address prefix-list PRIVATE_IP
R4(config)#route-map AS65000_OUT permit 20
Inbound filtering:
R4(config)#route-map AS65000_IN
R4(config-route-map)#match ip address prefix-list ADVERTISED
R4(config)#route-map AS65000_IN deny 20
6) On R4 we will add connected networks 4.0.0.0/24 - 4.0.3.0/24 summarized into one 4.0.0.0/22 subnet. You can do this in several ways, we will show one of them:
R4(config)#ip access-list standard REDISTRIBUTE_CONNECTED
R4(config-std-nacl)#permit 4.0.0.0 0.0.3.255
R4(config)#route-map REDISTRIBUTE_CONNECTED
R4(config-route-map)#match ip address REDISTRIBUTE_CONNECTED
R4(config-route-map)#router bgp 1234
R4(config-router)#redistribute connected route-map REDISTRIBUTE_CONNECTED
At this point, we get the following output: #sh ip bgp:
R4(config-router)#do sh ip bgp
-------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 4.0.0.0/24 0.0.0.0 0 32768 ?
*> 4.0.1.0/24 0.0.0.0 0 32768 ?
*> 4.0.2.0/24 0.0.0.0 0 32768 ?
*> 4.0.3.0/24 0.0.0.0 0 32768 ?
Now do
R4(config-router)#aggregate-address 4.0.0.0 255.255.252.0 summary-only
and see the following output:
R4(config-router)#do sh ip bgp
-------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
s> 4.0.0.0/24 0.0.0.0 0 32768 ?
*> 4.0.0.0/22 0.0.0.0 32768 i
s> 4.0.1.0/24 0.0.0.0 0 32768 ?
s> 4.0.2.0/24 0.0.0.0 0 32768 ?
s> 4.0.3.0/24 0.0.0.0 0 32768 ?
All routes except the total are marked with the letter “s” - suppressed, which means suppressed. They will not be announced. If for some reason we entered the aggregate-address command without the summary-only keyword, we would have announced the summarized subnet and each of / 24 individually.
7) The time has come to directly configure the BGP process, establish neighbor relations and configure other parameters that describe the general nature of the protocol:
R4(config)#router bgp 1234
R4(config-router)#bgp router-id 4.4.4.4
R4(config-router)#neighbor 3.3.3.3 remote-as 1234
R4(config-router)#neighbor 3.3.3.3 update-source lo0
R4(config-router)#neighbor 5.5.5.5 remote-as 1234
R4(config-router)#neighbor 5.5.5.5 update-source lo0
R4(config-router)#neighbor 200.0.94.9 remote-as 65000
We apply the previously configured route-map to the neighbor:
R4(config-router)#neighbor 200.0.94.9 route-map AS65000_IN in
R4(config-router)#neighbor 200.0.94.9 route-map AS65000_OUT out
Now is the time to configure R3.
We skip all the points about filtering, because R3 does not have eBGP peers. Instead, configure R3 as a Route Reflector . The fact is that iBGP peers when receiving a route do not send it further. Thus, we must have a full-mesh topology so that, for example, R4 can get routes with R2.
Looking at our topology, you can see that it does not reach a bit of full-mesh. Therefore, you will have to use Route Reflector so that all iBGP peers learn all iBGP routes.
Since we have as many as 3 neighbors, it makes sense to configure them using peer-group:
R3(config-router)#neighbor LOCAL peer-group
R3(config-router)#neighbor LOCAL remote-as 1234
R3(config-router)#neighbor 2.2.2.2 peer-group LOCAL
R3(config-router)#neighbor 4.4.4.4 peer-group LOCAL
R3(config-router)#neighbor 5.5.5.5 peer-group LOCAL
R3(config-router)#neighbor LOCAL update-source lo0
Set the group number for Route Reflector (you should pay special attention to this if you plan to make several clusters):
R3(config-router)#bgp cluster-id 1
And we will make all our neighbors customers:
R3(config-router)#neighbor LOCAL route-reflector-client
Please note that you do not need to configure anything on the clients themselves, it is enough to specify the RR neighbor as a regular iBGP peer.
We also show on R3 the second way to summarize subnets.
Create a summary route by null 0 (recall that if there is no route in the RIB, BGP will not announce it):
R3(config)#ip route 3.0.0.0 255.255.252.0 null 0
And just add it to BGP:
R3(config-router)#network 3.0.0.0 mask 255.255.252.0
As we can see, the summarized network is present in the BGP table and is announced. We also already received from R4 its summarized network 4.0.0.0/22:
R3(config-router)#do sh ip bgp
-------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 3.0.0.0/22 0.0.0.0 0 32768 i
*>i 4.0.0.0/22 4.4.4.4 0 100 0 i
It’s not up to me to decide which method of summarization is better, but the one that we used on R4 is uniquely more flexible in tuning, so I prefer to use it.
As we recall, R1 is connected only to R3 and does not use BGP, so on R3 we need to announce a network 50.0.254.0/24 with R1 so that it is also available. Let's do it in the simplest way:
R3(config-router)#network 50.0.254.0 mask 255.255.255.0
It would seem that everything should go perfectly, the route is announced, but let's look at R4:
R4(config-router)#do sh ip bgp
Network Next Hop Metric LocPrf Weight Path
-------------------------------------------------------------------
r>i 50.0.254.0/24 50.0.31.1 20 100 0 i
-------------------------------------------------------------------
We caught RIB-failure. In fact, absolutely nothing bad happened. There are several reasons why RIB-failure may occur. In this case, this happened because in RIB on R4 there is already a route with the best AD (received through OSPF) to this prefix. Will this route be announced to other AS? The answer is yes, there will be nothing to worry about.
For example, on R9 (assuming BGP is already configured there):
R9(config)#do sh ip bgp
---------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 3.0.0.0/22 200.0.94.4 0 1234 i
*> 4.0.0.0/22 200.0.94.4 0 0 1234 i
*> 50.0.109.0/24 0.0.0.0 0 32768 i
*> 50.0.254.0/24 200.0.94.4 0 1234 i
---------------------------------------------------------------------
By the way, since it turned out that BGP on R9 is already working, let's try for the sake of interest to announce the gray subnet 192.168.109.0/24 and see if filtering works on R4:
R4#debug ip bgp 200.0.94.9 updates
R9(config-router)#network 192.168.109.0 mask 255.255.255.0
R4#
*Nov 28 22:13:31.004: BGP(0): 200.0.94.9 rcvd UPDATE w/ attr: nexthop 200.0.94.9, origin i, metric 0, merged path 65000, AS_PATH
*Nov 28 22:13:31.004: BGP(0): 200.0.94.9 rcvd 192.168.109.0/24 -- DENIED due to: route-map;
As we can see, R4 tried to get the update, but route-map worked as it should.
By the way, we will not filter anything on R9 and R10, we will transfer these concerns to the provider. Suppose that the local engineers are not qualified enough (in fact, I’m just too lazy, besides, I promised that the AS65000 will not differ in particular adequacy).
On R5 and R2, add another command we need to the standard BGP configuration:
R5(config-router)#neighbor 200.0.115.11 remove-private-as
Thus, we will remove the private AS from the announcement. Let's see what the path to the 50.0.109.0/24 subnet (prefix from private AS 65000) for the R11 router will now look like:
R11(config-router)#do sh ip bgp
---------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
*> 3.0.0.0/22 200.0.115.5 0 1234 i
*> 4.0.0.0/22 200.0.115.5 0 1234 i
*> 5.0.0.0/24 200.0.115.5 0 0 1234 i
*> 5.0.1.0/24 200.0.115.5 0 0 1234 i
*> 5.0.2.0/24 200.0.115.5 0 0 1234 i
*> 5.0.3.0/24 200.0.115.5 0 0 1234 i
*> 50.0.109.0/24 200.0.115.5 0 1234 i
*> 50.0.254.0/24 200.0.115.5 0 1234 i
---------------------------------------------------------------------
In the path column for the prefix we are interested in, only one AS is indicated - 1234, therefore our idea was a success, and the private AS65000 is not displayed.
By the way, filtering on R11 is simply vital. The fact is that AS1114 is connected directly to two ISPs, but it is not transit (judging by wikis such ASs are called multi-interface). Therefore, if suddenly some traffic that is not related to this AS passes through it, it will be bad for everyone:
- providers, as channels most likely have not very large bandwidth, therefore, some packets will be lost;
- company owning AS, as her uplinks will be clogged with alien traffic absolutely uninteresting to her.
I will not show how to do filtering on R11, conceptually this process does not differ from the already described. I can only say that such a command will be present there:
R11(config)#ip prefix-list OUTBOUND permit 150.0.0.0/24 le 32
A little bit about why prefix lists are used everywhere, not ACLs:
- With one prefix list, we can filter all subnets of a given network at once (for example, the command just above filters not only the / 24 mask, but also all kinds of / 25, / 26, etc ...);
- I vaguely remember reading an article that said that the prefix-list has a tree structure as opposed to ACLs, so the router needs slightly less resources for a lookup (maybe it's a lie, I rely on memory, I can’t find the article).
Honestly, I’m really tired of fully configuring BGP on each router, so that on all the others the settings will be such that it rises and routes (I warn you in case it pops up somewhere later).
With fully configured routing, sh ip bgp to R8 looks like this:
sh ip bgp
R8(config-router)#do sh ip bgp
------------------------------------------------------------------------
Network Next Hop Metric LocPrf Weight Path
* 2.0.0.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 2.0.1.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 2.0.2.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 2.0.3.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 3.0.0.0/22 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 4.0.0.0/22 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.0.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.1.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.2.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 5.0.3.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 6.0.0.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 6.0.1.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 6.0.2.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 6.0.3.0/24 200.0.87.7 0 67 i
*> 200.0.86.6 0 0 67 i
* 7.0.0.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 7.0.1.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 7.0.2.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 7.0.3.0/24 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 50.0.109.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 50.0.254.0/24 200.0.87.7 0 67 1234 i
*> 200.0.86.6 0 67 1234 i
* 100.0.0.0/16 200.0.87.7 0 0 67 i
*> 200.0.86.6 0 67 i
* 150.0.0.0/24 200.0.87.7 0 67 1114 i
*> 200.0.86.6 0 67 1114 i
*> 175.0.0.0/24 0.0.0.0 0 32768 i
As we can see, R8 holds two local full views (there would be real Internet - there would be real full view).
Checking the connectivity, I was somewhat surprised by this:
SW12#ping 4::3.0.0.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4::300:3, timeout is 2 seconds:
!.!.!
Success rate is 60 percent (3/5), round-trip min/avg/max = 1/2/4 ms
Description and solution here .
I took extreme measures and turned off CEF on R8 (never do this). The situation has been corrected:
SW12#ping 4::3.0.0.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4::300:3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/3 ms
MPLS VPN
About MPLS will not be said as much as we would like. We just set it up and try to start L2 and L3 VPN. For these purposes, we use the previously left aside router R15.
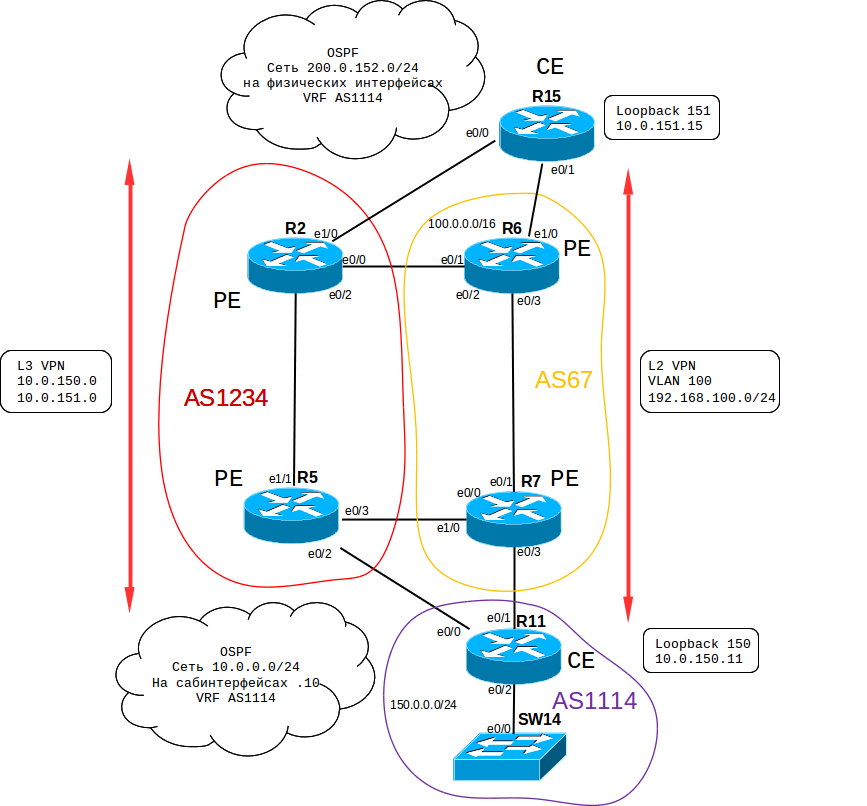
For starters, the basic (most basic, just to work) MPLS settings on routers (in AS67 we don’t have P (Provider) devices, only PE (Provider Edge), which is enough to demonstrate a VPN). I will show the configuration only on one side (R7 and R11), on the other everything is the same:
Turn on MPLS on the interfaces that OSPF runs on:
R7(config)#router ospf 67
R7(config-router)#mpls ldp autoconfig
R7(config)#mpls ldp router-id loopback 0
Set the range of labels used:
R7(config)#mpls label range 700 799
Enable MPLS globally:
R7(config)#mpls ip
Here it is better written about MPLS VPN than mine, but I will nevertheless repeat the setup process.
Through AS67 we will forward L2VPN R11 R15
First you need to configure VLAN for forwarding on R11 and R15:
R11(config)#bridge irb
R11(config)#bridge 100 protocol ieee
R11(config)#bridge 100 bridge ip
R11(config)#bridge 100 route ip
R11(config)#int bvi 100
R11(config-if)#ip address 192.168.100.11 255.255.255.0
R11(config)#int eth0/2.100
R11(config-subif)#encapsulation dot1Q 100
R11(config-subif)#bridge-group 100
R11(config)#int eth 0/1.100
R11(config-subif)#encapsulation dot1Q 100
R11(config-subif)#bridge-group 100
And now enter just a few commands on PE:
R7(config)#int eth 0/3.100
R7(config-subif)#encapsulation dot1Q 100
R7(config-subif)#xconnect 6.6.6.6 100 encapsulation mpls
R7(config-subif)#mpls ip
All L2 connectivity between VLAN 100 for R11 and R15 is raised. Check:
SW14#ping 192.168.100.15
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.100.15, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/8 ms
Through AS1234 we will forward L3VPN R11 R15
Settings, in general, are slightly more complicated than for L2 VPNs, but, by and large, there is nothing special about them:
We configure L3VPN only on PE and CE (Customer Edge) routers (you do not need to touch P).
To check the routing, create a private subnet 10.0.150.0/24 on R11 and a network 10.0.151.0/24 on R15. Our task is to get a working ping from Loopback 150 on R11 to Loopback 151 on R15.
First, you need to configure the PE-CE junction:
We will use the 10.0.0.0/24 subnet (we will configure it on the subinterfaces, because in the future we will tie them to VRF, and after that, if you pick it up on physics, you will need to reconfigure BGP more globally and transfer the neighbor to this VRF).
Everything is simple on CE:
R11(config)#router ospf 150
R11(config-router)#network 10.0.0.5 0.0.0.255 area 0
R11(config-router)#network 10.0.150.0 0.0.0.255 area 0
And on PE we need to create a separate client VRF (a virtual entity that simulates a separate router with its own routing table, interfaces, etc ...):
R5(config)#ip vrf AS1114
R5(config-vrf)#rd 1234:1
R5(config-vrf)#route-target export 1234:1
R5(config-vrf)#route-target import 1234:1
There is also a need to tighten up BGP:
R5(config-router)#address-family vpnv4
R5(config-router-af)#neighbor 2.2.2.2 activate
R5(config-router-af)#neighbor 2.2.2.2 send-community both
R5(config-router-af)#exit-address-family
Now on PE, create an OSPF process in client VRF:
R5(config)#router ospf 150 vrf AS1114
see this:
*Nov 29 13:29:51.725: %OSPF-4-NORTRID: OSPF process 150 failed to allocate unique router-id and cannot start
and assign the process router-id:
R5(config-router)#router-id 10.0.0.5
Add the network we need:
R5(config-router)#network 10.0.0.0 0.0.0.255 area 0
and bind BGP to OSPF:
R5(config)#router bgp 1234
R5(config-router)#address-family ipv4 vrf AS1114
R5(config-router-af)#redistribute ospf 150
R5(config-router-af)#exit-address-family
R5(config)#router ospf 150 vrf AS1114
R5(config-router)#redistribute bgp 1234 subnets
Bind the interface to VRF:
R5(config-subif)#ip vrf forwarding AS1114
And we see that we need to recreate the ip address on the interface:
% Interface Ethernet0/2.10 IPv4 disabled and address(es) removed due to enabling VRF AS1114
R5(config-subif)#ip add 10.0.0.5 255.255.255.0
Now the same on another pair of PE-CE. The only difference is that there is no BGP on R15, so we can not create subinterfaces for different VRFs, but do everything in one physical one. In the current configuration, this will work.
When everything is ready, we can watch RIB on R15:
R15(config)#do sh ip route ospf
-----------------------------------------------------------------------
O E2 10.0.150.11/32 [110/11] via 200.0.152.2, 00:02:26, Ethernet0/0
O E2 200.0.115.0/24 [110/1] via 200.0.152.2, 00:02:26, Ethernet0/0
-----------------------------------------------------------------------
We see that the routes through the L3 VPN have risen and are available:
R15(config)#do ping 10.0.150.11 source 10.0.151.15
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.150.11, timeout is 2 seconds:
Packet sent with a source address of 10.0.151.15
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/5 ms
Loopback address on R11 responds with R15 (and vice versa), then the goal is achieved.
By the way, traffic encryption is necessary here. I tried to log in with telnet from R11 to R15 and using Wireshark on the link R2 R5 easily found a pair of login / password and all entered configuration commands.
The BGP configuration on R5 currently looks like this:
sh run | sec bgp
R5(config-subif)#do sh run | sec bgp
router bgp 1234
bgp router-id 5.5.5.5
bgp log-neighbor-changes
neighbor 2.2.2.2 remote-as 1234
neighbor 2.2.2.2 update-source Loopback0
neighbor 3.3.3.3 remote-as 1234
neighbor 3.3.3.3 update-source Loopback0
neighbor 4.4.4.4 remote-as 1234
neighbor 4.4.4.4 update-source Loopback0
neighbor 200.0.65.6 remote-as 67
neighbor 200.0.75.7 remote-as 67
neighbor 200.0.105.10 remote-as 65000
neighbor 200.0.115.11 remote-as 1114
!
address-family ipv4
network 5.0.0.0 mask 255.255.255.0
network 5.0.1.0 mask 255.255.255.0
network 5.0.2.0 mask 255.255.255.0
network 5.0.3.0 mask 255.255.255.0
neighbor 2.2.2.2 activate
neighbor 3.3.3.3 activate
neighbor 4.4.4.4 activate
neighbor 200.0.65.6 activate
neighbor 200.0.65.6 remove-private-as
neighbor 200.0.75.7 activate
neighbor 200.0.75.7 remove-private-as
neighbor 200.0.105.10 activate
neighbor 200.0.105.10 route-map AS65000_IN in
neighbor 200.0.105.10 route-map AS65000_OUT out
neighbor 200.0.115.11 activate
neighbor 200.0.115.11 remove-private-as
neighbor 200.0.115.11 route-map AS1114_IN in
neighbor 200.0.115.11 route-map AS1114_OUT out
exit-address-family
!
address-family vpnv4
neighbor 2.2.2.2 activate
neighbor 2.2.2.2 send-community both
exit-address-family
!
address-family ipv4 vrf AS1114
redistribute ospf 150
exit-address-family
This concludes with MPLS and with the article as a whole.