Full-blown DevOps: Greek tragedy in three acts
Tragedy (from the German. Tragödie from the Latin. Tragoedia from the ancient Greek. Τραγωδία) - a genre of artwork, intended for statement on the stage in which the plot leads the characters to a disastrous outcome.
Most tragedies are written in verse. This tragedy was written by Baruch Sadogursky ( @jbaruch ) and Leonid Igolnik ( @ligolnik ). If we are talking about DevOps on a large scale, what is this if not a tragedy?
This article is marked by the severity of realism, depicts the reality of a large development of the most pointed, like a clot of internal contradictions. It reveals the deepest conflicts of reality in an extremely intense and saturated form, which acquires the value of an artistic symbol.
And now we finish playing in Belinsky and welcome to the cat! There is text and video. Hostages do not take!

As is known, the Greeks adored Venn diagrams. And we will show you as many as three - and all about DevOps.

There is a traditional description of DevOps - this is the intersection of the Operations, Development and QA areas. Historically, it is interesting that QA was added there later.
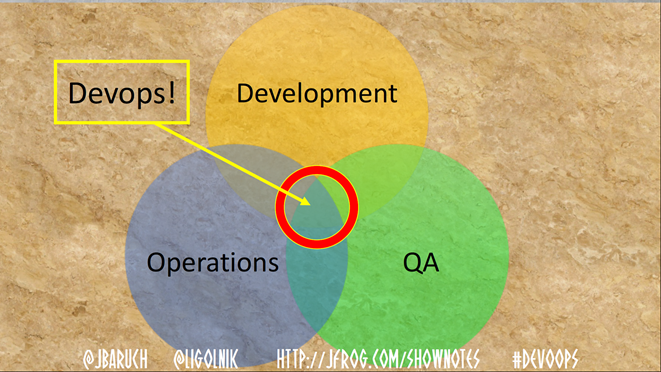
But today we will talk about something else - the intersection of technology, process and people. That it is necessary to make with all these three components that DevOps has turned out.
Now compare two more charts:
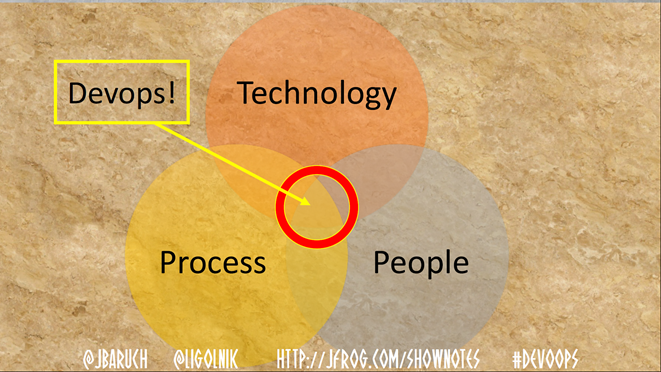
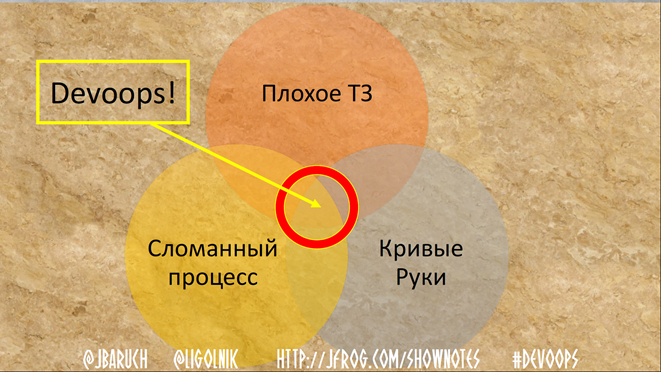
Sometimes it happens.
We begin the story with a mythical company called Pentagon, which deals with credit card transactions.

People . The company is just starting its work, it has three engineers. All three came from the same company from the defense industry. The guys are smart enough, so they have everything: JavaScript, Node, React, Docker, microservices.

Process . What can a process look like when there are three people in a team? Kanban: or on a blackboard with paper, or in Trello. Guys are intelligent and understand that QA is needed from the very beginning, so TDD, unit & integration tests. No ops, all root.

Tools . Accordingly, for three people who are just raising something: JIRA , GitHub , Travis CI, and so on.
Talk about how these people live on this beautiful stack. First, as in good startups - we are sawing, sawing the product and waiting for the first client.

Unexpectedly, a miracle happened - one organization that organizes the best conferences in the post-Soviet space decided to trust these guys and make their transactions through them.

What does a real startup do when it gets its first client? Marks! And about three o'clock in the morning, when everything is in a special state, the customer calls and says that nothing works.

Of course, first of all, panic!

The next step is to fight! Look logs, for example.

Looked, looked, it turned out that one of our three heroes - Vasya, having come home after the festival, committed his little idea. We remember that after the commit and passed tests, everything flies into production.
Well, who among us did not fill up the production? We will not blame Vasya. Roll back to the previous commit. It is not going to! For some reason, there is not enough library, called left-pad.
For those who do not know what happened with the left-pad, we tell. So, on March 23, 2016 half of the Internet broke . In general, the left-pad module in JavaScript simply inserts spaces in the left part of the lines. And half of the Internet directly or transitively depended on this module. The author of the left-pad somehow managed to quarrel with the owners of the central repository of npm, so he just walked away from them, taking all his developments. npm is generally a mysterious system: not only do they check when you add a new module for downloading, they also check all the old modules.
Thus, the fight against fire continues. And the problems are the same all the time.

Company news: they raised money, found an investor, hired 27 people, one of them with an ops background. There are 100 customers and even tech support.

The process, accordingly, should also receive an upgrade. Appeared normal Scrum, exploratory testing. We realized that NoOps does not exist at all, because there are Ops (if the serverless architecture is, then the server is still there, it is simply not yours). Since it was wrong to wake the whole team at night, the attendant (developer on call) appeared.

Accordingly, the set of tools has expanded. At least Knowledge Base has appeared, as now there is a person on duty, and he needs to look for information somewhere. Another novelty is JFrog Artifactory : a system that allows you to store what was deposited yesterday so that you can easily roll back (the lesson with the left-pad was not in vain), and not to rebuild everything anew. They put a system for collecting logs and searching for them. Pingdom was added - a fabulous monitoring-system: you give it a url, and it tells you whether it works or fell.

So, at this stage again raised money. So, we note. Friday, three in the morning, the customer calls. Something doesn't work: Visa and MasterCard pass, but American Express does not.

And how does the support react first when the customer calls at three in the morning? Panic!
Then call the duty officer. Guess who's on duty? Of course, Vasya! Guess what condition Vasya? M-yes. But Vasya takes himself in hand, looks at what the support sent him, and says that he is suspiciously familiar with all this and he has already done this. Therefore, Vasya just takes and repairs. Everyone is going to sleep. On Monday, debriefing begins.

Here is an example of a specific document that we produce for the knowledge base, so that if something happens again, it can be quickly found. In addition, sometimes it is shown to customers:
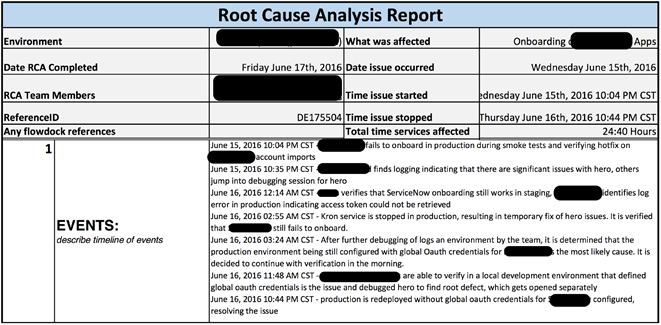


The document displays the main headers, causes, characteristics, list of events. Be sure to indicate the symptoms, given a technical description of what is broken and how to fix it. The most important part of the document is the key reason why something fell.
In the case of Vasya, our logs are full. It is necessary to clear it from credit card transactions, and in addition, to increase its size. For example, at 42!
Such a process is very good for internal continuous improvement and it guarantees the installation of the very "smoke detectors". The second reason why this document is important is the report to the client. Some services, after they "lay" for some time, publish the reasons for this.

Sometimes the problem is so catastrophic that it’s not worth talking about.
In GitLab in February 2017 , a person deleted a database on production. Here is the analysis that GitLab posted:

So, somewhere there is a backup, only no one knows where. Then backups were found, but they were empty. Yes, there is a base dump. But it was made in a different version of postgres, so it does not fit. We have a snapshot disc, but they don't have a database. Replication with S3 also did not work due to lack of data.
Thus, five different techniques for backing up data did not work. We think that it is impossible to publish this, since no one will trust them anything more. But, depending on how to tell about it, the client can forgive. True, only once.

By the way, the guy who did it got a promotion. In addition, he changed his twitter status to Database (removal) Specialist at GitLab .
So what happens in our company? They raised money again, hired a lot of people - now we have five ops engineers and one person who is engaged in performance. There is a main architect. A customer success team has emerged covering all industries that may require support. They are inhibited so that the rest of the team can continue to work. Often in such a team there is a group that can build relationships with ops or support, and periodically there must be thrown engineers on the scrum, or on the sprint, or for a month. The company has grown, a lawyer, financial director has appeared. The customer base has grown to 1000.

As the team grows, the development process has to change.
A SAFE appeared - a framework that explains what to do with scrum when there are many teams or development centers - more than one. The number of processes that are present in Safe can kill a horse, but if only all of them are taken at once. If you pick up only those pieces that are required at this stage of the company's development, then everything should be fine.
System testing appears when large teams have certain needs or if you have a huge system from which to build something. Individual scrum teams can test their systems well, but someone must be responsible for the fact that the entire system must assemble into production.
What can you say about the Ops Team? As we said, there are two options for doing DevOps. The first is on the book and on the instructions Netflix, Google and Twitter. The second is in real life, where not all engineers can be trusted with root in production.
Escalation path is an important concept that allows you to solve any problem at a given time, because at the end of the escalation path there is a mobile phone of the general director, after a call to which all problems disappear within 5 hours and 58 minutes.
SOC II - a set of standards that the vendor provides to the client. These standards confirm that the firm has certain security solutions, approaches to the division of work.
Backlog - a list of problems that need to be addressed to improve the system. Usually the chief architect becomes the backlog manager, who should look at the needs of the system and the needs of the product and prioritize these tasks.

Tools, of course, also improved.

There is more news. Vasya was promoted. He is now a VP of Engineering.
It takes Friday, Saturday, Sunday - nothing comes. Everything is working. All in shock. Monday comes, a lawyer comes to Vasya and says that he was at a law conference and heard about the LGPL 2.2. Vasya has no idea if they have the LGPL 2.2.

People worked for a long time, and then they found the LGPL 2.2. Need to cut out. But it is cut out by a healthy piece of the system, and nobody has canceled the release tomorrow. Well, nothing coped with this.

The financial director comes to Vasya:
Solved this problem.

They come to Vasya and say that there is a potential customer, but he is afraid that we have never had such a large-scale customer, and he wants to be convinced that it will be good. From the story we know that at this stage everyone died.

But since we must necessarily have a happy end, we attached it to the Greek tragedy.
Now let's tell about the latest stage of scaling DevOps - Proactive Improvement. This is about fire prevention.
No change happens to people. But with the process - very much so.

Since we have a Performance Engineer, it should somehow monitor the system. Appeared License and security management. Proactive Performance - now we carefully look at where the key indicators are moving, and fix things before a huge fire starts. When scaling a product, it is desirable to have something that says: if you want to have a microservice, then it should at least have standard monitoring, logs, and so on.
Accordingly, there are tools that support all of this. For example, the tool for license and security monitoring is JFrog Xray . Blazemeter- since now there is proactive performance, it is necessary to somehow generate load. There are things like Service Virtualization, which allows you to use mock objects for remote APIs, because not every vendor you work with can provide a test API.

Let us examine some of the events from the previous acts.
Remember the case when Vasily planned to budget a finger to the sky? In the work on one of our products, we wanted to figure out how resources are spent. Having grouped everything that was in the backlog, we got the following diagram:

We mistakenly thought that we were spending 80% on Big Feature A - in fact, it only takes 13%. At the same time, as much as 34% goes to Keep the lights on - the things that need to be done in products: fix bugs, update libraries, and so on.
In fact, there is only one objective metric of product quality: customer satisfaction, which is expressed in appeals to support.
The second example. Crashed all criticality defects:
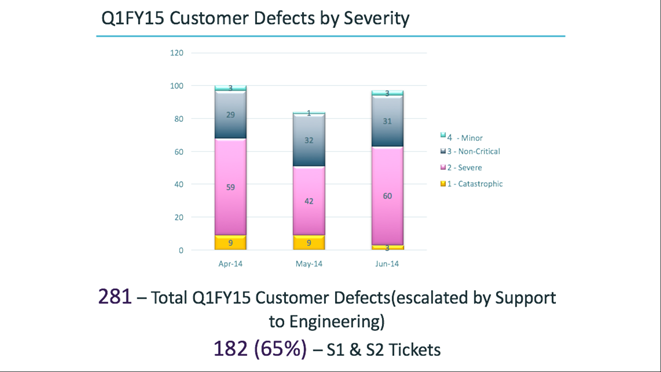
65% of tickets belong to the first levels of criticality. Is this a nightmare?
Now take the same data and look at it from a different angle.
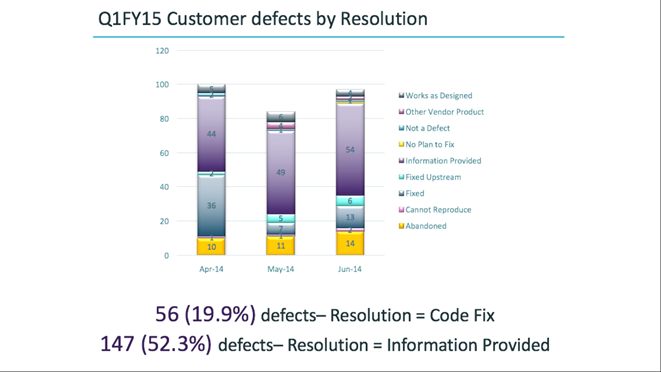
Now the chart reflects the situation after debriefing. It turned out that 52% of the tickets were closed by the engineer using the information provided, that is, he wrote to the support of what they did not know. Only about 20% of the tickets were closed with some kind of code change. Thus it turns out that R & D is not to blame at all. Not even support is to blame. In fact, we did not have enough training - and Vasya, like VP of engineering, having seen how much time he was spending on all sorts of nonsense, sent a bunch of engineers to train a support.
The guys corrected the documentation in narrow places, corrected the logs. As a result, the piece that a lot of developer time spent on has disappeared.
At all stages, from fire extinguishing to installing alarm systems and proactive problem solving, there are many processes, people, specialists, approaches, tools that need to be installed. All this can not be done in one day. In addition, some things at some stages of development are not needed.
It is important to understand that in people, in the processes, and in the bodies, some improvements are constantly needed.

What exactly needs to be improved, we will be helped to find out the very figures we were talking about. Only on the basis of these data can one make the right decisions about where to invest time and what to move forward.
And do not forget the two fundamental principles of DevOps:
Most tragedies are written in verse. This tragedy was written by Baruch Sadogursky ( @jbaruch ) and Leonid Igolnik ( @ligolnik ). If we are talking about DevOps on a large scale, what is this if not a tragedy?
This article is marked by the severity of realism, depicts the reality of a large development of the most pointed, like a clot of internal contradictions. It reveals the deepest conflicts of reality in an extremely intense and saturated form, which acquires the value of an artistic symbol.
And now we finish playing in Belinsky and welcome to the cat! There is text and video. Hostages do not take!
As is known, the Greeks adored Venn diagrams. And we will show you as many as three - and all about DevOps.
There is a traditional description of DevOps - this is the intersection of the Operations, Development and QA areas. Historically, it is interesting that QA was added there later.
But today we will talk about something else - the intersection of technology, process and people. That it is necessary to make with all these three components that DevOps has turned out.
Now compare two more charts:
Sometimes it happens.
Pentagon Inc.
We begin the story with a mythical company called Pentagon, which deals with credit card transactions.
Act I - Firefighters
People . The company is just starting its work, it has three engineers. All three came from the same company from the defense industry. The guys are smart enough, so they have everything: JavaScript, Node, React, Docker, microservices.
Process . What can a process look like when there are three people in a team? Kanban: or on a blackboard with paper, or in Trello. Guys are intelligent and understand that QA is needed from the very beginning, so TDD, unit & integration tests. No ops, all root.
Tools . Accordingly, for three people who are just raising something: JIRA , GitHub , Travis CI, and so on.
Talk about how these people live on this beautiful stack. First, as in good startups - we are sawing, sawing the product and waiting for the first client.
Unexpectedly, a miracle happened - one organization that organizes the best conferences in the post-Soviet space decided to trust these guys and make their transactions through them.
What does a real startup do when it gets its first client? Marks! And about three o'clock in the morning, when everything is in a special state, the customer calls and says that nothing works.
Of course, first of all, panic!
The next step is to fight! Look logs, for example.
Looked, looked, it turned out that one of our three heroes - Vasya, having come home after the festival, committed his little idea. We remember that after the commit and passed tests, everything flies into production.
Well, who among us did not fill up the production? We will not blame Vasya. Roll back to the previous commit. It is not going to! For some reason, there is not enough library, called left-pad.
For those who do not know what happened with the left-pad, we tell. So, on March 23, 2016 half of the Internet broke . In general, the left-pad module in JavaScript simply inserts spaces in the left part of the lines. And half of the Internet directly or transitively depended on this module. The author of the left-pad somehow managed to quarrel with the owners of the central repository of npm, so he just walked away from them, taking all his developments. npm is generally a mysterious system: not only do they check when you add a new module for downloading, they also check all the old modules.
Thus, the fight against fire continues. And the problems are the same all the time.
Act II - Fire Alarm Installers
Company news: they raised money, found an investor, hired 27 people, one of them with an ops background. There are 100 customers and even tech support.
The process, accordingly, should also receive an upgrade. Appeared normal Scrum, exploratory testing. We realized that NoOps does not exist at all, because there are Ops (if the serverless architecture is, then the server is still there, it is simply not yours). Since it was wrong to wake the whole team at night, the attendant (developer on call) appeared.
Accordingly, the set of tools has expanded. At least Knowledge Base has appeared, as now there is a person on duty, and he needs to look for information somewhere. Another novelty is JFrog Artifactory : a system that allows you to store what was deposited yesterday so that you can easily roll back (the lesson with the left-pad was not in vain), and not to rebuild everything anew. They put a system for collecting logs and searching for them. Pingdom was added - a fabulous monitoring-system: you give it a url, and it tells you whether it works or fell.
So, at this stage again raised money. So, we note. Friday, three in the morning, the customer calls. Something doesn't work: Visa and MasterCard pass, but American Express does not.
And how does the support react first when the customer calls at three in the morning? Panic!
Then call the duty officer. Guess who's on duty? Of course, Vasya! Guess what condition Vasya? M-yes. But Vasya takes himself in hand, looks at what the support sent him, and says that he is suspiciously familiar with all this and he has already done this. Therefore, Vasya just takes and repairs. Everyone is going to sleep. On Monday, debriefing begins.
Here is an example of a specific document that we produce for the knowledge base, so that if something happens again, it can be quickly found. In addition, sometimes it is shown to customers:
The document displays the main headers, causes, characteristics, list of events. Be sure to indicate the symptoms, given a technical description of what is broken and how to fix it. The most important part of the document is the key reason why something fell.
In the case of Vasya, our logs are full. It is necessary to clear it from credit card transactions, and in addition, to increase its size. For example, at 42!
Such a process is very good for internal continuous improvement and it guarantees the installation of the very "smoke detectors". The second reason why this document is important is the report to the client. Some services, after they "lay" for some time, publish the reasons for this.
Sometimes the problem is so catastrophic that it’s not worth talking about.
In GitLab in February 2017 , a person deleted a database on production. Here is the analysis that GitLab posted:
So, somewhere there is a backup, only no one knows where. Then backups were found, but they were empty. Yes, there is a base dump. But it was made in a different version of postgres, so it does not fit. We have a snapshot disc, but they don't have a database. Replication with S3 also did not work due to lack of data.
Thus, five different techniques for backing up data did not work. We think that it is impossible to publish this, since no one will trust them anything more. But, depending on how to tell about it, the client can forgive. True, only once.
By the way, the guy who did it got a promotion. In addition, he changed his twitter status to Database (removal) Specialist at GitLab .
Act III - Culmination
So what happens in our company? They raised money again, hired a lot of people - now we have five ops engineers and one person who is engaged in performance. There is a main architect. A customer success team has emerged covering all industries that may require support. They are inhibited so that the rest of the team can continue to work. Often in such a team there is a group that can build relationships with ops or support, and periodically there must be thrown engineers on the scrum, or on the sprint, or for a month. The company has grown, a lawyer, financial director has appeared. The customer base has grown to 1000.
As the team grows, the development process has to change.
A SAFE appeared - a framework that explains what to do with scrum when there are many teams or development centers - more than one. The number of processes that are present in Safe can kill a horse, but if only all of them are taken at once. If you pick up only those pieces that are required at this stage of the company's development, then everything should be fine.
System testing appears when large teams have certain needs or if you have a huge system from which to build something. Individual scrum teams can test their systems well, but someone must be responsible for the fact that the entire system must assemble into production.
What can you say about the Ops Team? As we said, there are two options for doing DevOps. The first is on the book and on the instructions Netflix, Google and Twitter. The second is in real life, where not all engineers can be trusted with root in production.
Escalation path is an important concept that allows you to solve any problem at a given time, because at the end of the escalation path there is a mobile phone of the general director, after a call to which all problems disappear within 5 hours and 58 minutes.
SOC II - a set of standards that the vendor provides to the client. These standards confirm that the firm has certain security solutions, approaches to the division of work.
Backlog - a list of problems that need to be addressed to improve the system. Usually the chief architect becomes the backlog manager, who should look at the needs of the system and the needs of the product and prioritize these tasks.
Tools, of course, also improved.
There is more news. Vasya was promoted. He is now a VP of Engineering.
It takes Friday, Saturday, Sunday - nothing comes. Everything is working. All in shock. Monday comes, a lawyer comes to Vasya and says that he was at a law conference and heard about the LGPL 2.2. Vasya has no idea if they have the LGPL 2.2.
People worked for a long time, and then they found the LGPL 2.2. Need to cut out. But it is cut out by a healthy piece of the system, and nobody has canceled the release tomorrow. Well, nothing coped with this.
The financial director comes to Vasya:
- How much money do you need for servers and production? Making a budget for next year ...
- 42 - says Vasya.
Solved this problem.
They come to Vasya and say that there is a potential customer, but he is afraid that we have never had such a large-scale customer, and he wants to be convinced that it will be good. From the story we know that at this stage everyone died.
But since we must necessarily have a happy end, we attached it to the Greek tragedy.
Epilogue - Proactive Improvement
Now let's tell about the latest stage of scaling DevOps - Proactive Improvement. This is about fire prevention.
No change happens to people. But with the process - very much so.
Since we have a Performance Engineer, it should somehow monitor the system. Appeared License and security management. Proactive Performance - now we carefully look at where the key indicators are moving, and fix things before a huge fire starts. When scaling a product, it is desirable to have something that says: if you want to have a microservice, then it should at least have standard monitoring, logs, and so on.
Accordingly, there are tools that support all of this. For example, the tool for license and security monitoring is JFrog Xray . Blazemeter- since now there is proactive performance, it is necessary to somehow generate load. There are things like Service Virtualization, which allows you to use mock objects for remote APIs, because not every vendor you work with can provide a test API.
Parsing
Let us examine some of the events from the previous acts.
Remember the case when Vasily planned to budget a finger to the sky? In the work on one of our products, we wanted to figure out how resources are spent. Having grouped everything that was in the backlog, we got the following diagram:
We mistakenly thought that we were spending 80% on Big Feature A - in fact, it only takes 13%. At the same time, as much as 34% goes to Keep the lights on - the things that need to be done in products: fix bugs, update libraries, and so on.
In fact, there is only one objective metric of product quality: customer satisfaction, which is expressed in appeals to support.
The second example. Crashed all criticality defects:
65% of tickets belong to the first levels of criticality. Is this a nightmare?
Now take the same data and look at it from a different angle.
Now the chart reflects the situation after debriefing. It turned out that 52% of the tickets were closed by the engineer using the information provided, that is, he wrote to the support of what they did not know. Only about 20% of the tickets were closed with some kind of code change. Thus it turns out that R & D is not to blame at all. Not even support is to blame. In fact, we did not have enough training - and Vasya, like VP of engineering, having seen how much time he was spending on all sorts of nonsense, sent a bunch of engineers to train a support.
The guys corrected the documentation in narrow places, corrected the logs. As a result, the piece that a lot of developer time spent on has disappeared.
findings
At all stages, from fire extinguishing to installing alarm systems and proactive problem solving, there are many processes, people, specialists, approaches, tools that need to be installed. All this can not be done in one day. In addition, some things at some stages of development are not needed.
It is important to understand that in people, in the processes, and in the bodies, some improvements are constantly needed.
What exactly needs to be improved, we will be helped to find out the very figures we were talking about. Only on the basis of these data can one make the right decisions about where to invest time and what to move forward.
And do not forget the two fundamental principles of DevOps:
- You build it - you own it.
- Pain is instructional.
Already on the following Sunday Baruch and Leonid will make a report «#DataDrivenDevOps» on DevOops 2018 in St. Petersburg. Come, there will be a lot of interesting things: here are the reports , here is John Willis , and here is the party with BoF and karaoke . Waiting for you!