How to shorten the time-to-market: a story about test automation in M.Video

Fast and effective software development today is unthinkable without perfected workflows: each component is transferred to the assembly at the time of installation, the product is not idle while waiting. Two years ago, together with M.Video, we began to introduce such an approach to the development process at the retailer and today we continue to develop it. What are the subtotals? The result fully justified itself: thanks to the implemented changes, it was possible to accelerate the release of releases by 20–30%. Want details? Wellcome to our backstage.
With Scrum on Kanban
First of all, a change of methodology was implemented - the transition from Scrum, that is, the sprint model, to Kanban. Previously, the development process looked like this:

There is a development branch, there are sprints for five teams. They code in their own development branches, sprints end on the same day, and all teams on the same day combine the results of their work with the master branch. After that, the regression tests are run for five days, then the branch is given to the pilot environment and after that - to the productive one. But, before starting the regression tests, it was necessary to somehow stabilize the master branch for 2–3 days, removing conflicts after merging with the command branches.
What is the advantage of Kanban? The teams do not wait for the end of the sprint, but combine their local changes with the master branch upon completion of the implementation of the task, each time checking for any association conflicts. On the appointed day, all associations with the master are blocked and regression tests are run.
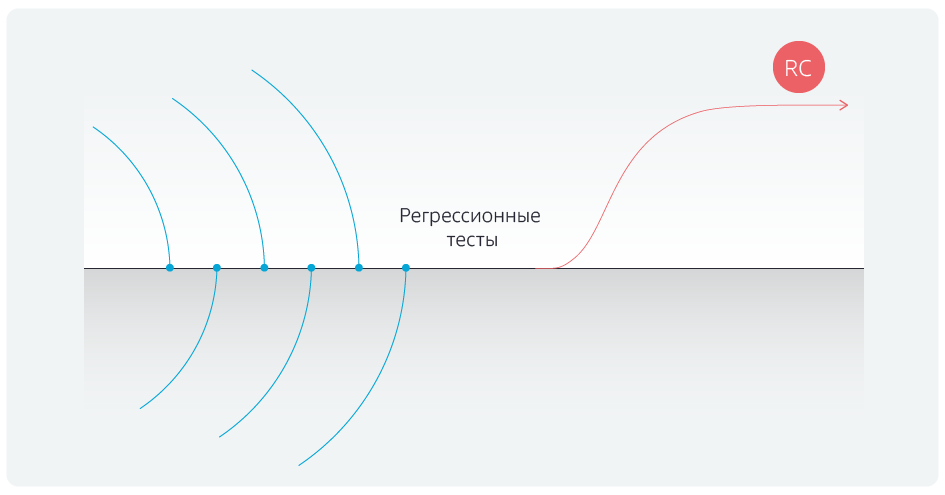
As a result, we managed to get rid of the constant shifts in the timing to the right, the regressions are
not delayed, the release candidate is shipped on time.
Ubiquitous Automation
Of course, merely changing the methodology was not enough. The second stage, together with the retailer, automated testing. In total, about 900 scenarios are checked, divided into groups by priorities.
About 100 scenarios - the so-called blockers. They should work on the website —the M.Video online store — even during an atomic war. If any of the blockers does not work, then there are big problems on the site. For example, blockers include the mechanism of purchasing goods, applying discounts, authorization, user registration, placing a credit order, etc.
Approximately 300 more scenarios are critical. These include, for example, the ability to choose products using filters. If this feature breaks, it is unlikely that users will buy goods, even if the mechanisms of purchase and direct search in the catalog will work.
The remaining scenarios are major and minor. If they do not work, people will gain negative experience using the site. This includes many problems of varying importance and visibility to the user. For example, the layout went (major), the description of the action (minor) is not displayed, the auto-prompt for passwords in the personal account (minor) does not work, the restoration (major) does not work.
Together with M.Video, we automated the testing of blockers by 95%, the remaining scenarios - by about 50%. Why about half are not automated? There are many reasons and different. There are scenarios, a priori not amenable to automation. There are complex integration cases, preparation for which requires manual work, for example, call the bank and cancel a loan application, contact the sales department and cancel orders in a productive environment.
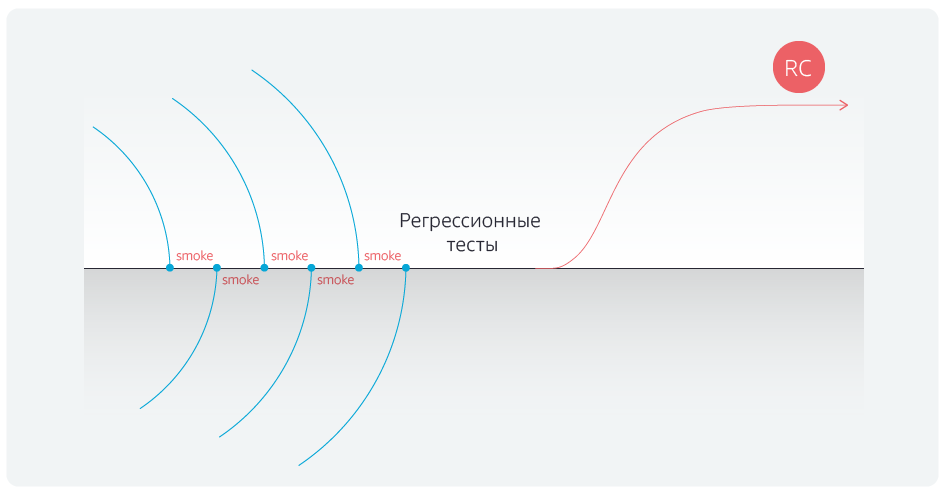
Automation of regression tests reduced their duration. But we went further and automated the smoke tests for the blockers after each merging of the branches of the teams with the master branch.
After automating the tests, we finally got rid of delays after completing unions with a master branch.
Gherkin to help
To consolidate the success, our team reworked the tests themselves. Previously, these were the tables: action → expected result → actual result. For example, I logged in with this login and password on the site; expected result: everything is in order; the actual result is also all right, I turn on the other pages. These were bulky scripts.
We translated them into Gherkin notation and automated some steps. Take the same authorization on the site, the script is now formulated as follows: “ as a user of the site, I logged in with authorization data, and the procedure was successful .” At the same time, the “ site user ” and “ logged in with authorization data»Rendered in separate tables. Now we can quickly run test scripts regardless of data.
What is the value of this stage? Suppose one project tester is involved in project testing. He does not care how he writes tests, he can do checks even in the form of a check list: “the authorization is verified, the registration is verified, the purchase with the card is verified, the purchase with Yandex.Money is verified - I am handsome” A new person comes and asks: have you logged in via e-mail or via Facebook? As a result, the checklist turns into a script.
There are five teams in the project, and each has at least two testers. Previously, each of them wrote the tests, as he pleases, and as a result, only their authors could support the tests. Everything was deaf with automation: either you need to recruit individual automatists who translate the entire zoo of tests into a scripting language, or forget about automation as a phenomenon. Gherkin helped to change everything: with the help of this scripting language we created “cubes” - authorization, basket, payment, etc. - of which testers now collect various scenarios. When you need to create a new script, a person does not write it from scratch, but simply tightens the necessary blocks in the form of autotests. Gherkin notations have trained all functional testers, and now they can independently interact with automation, maintain scripts and parse the results.
We did not stop at that.
Functional blocks
Suppose release 1 is the functionality that is already on the site. In release 2, we wanted to make some changes to user and business scenarios, and as a result, some of the tests stopped working because the functionality had changed.
We structured the test storage system: we divided it into functional blocks, for example, “personal account”, “purchase”, etc. Now that a new user script is introduced, the necessary functional blocks are already checked in it.
Thanks to this, after merging with the master branch, developers can check the work of not only the blockers, but also the scenarios related to the subject area affected by the changes made.
The second consequence - it became much easier to support the tests themselves. For example, if something has changed in your dashboard, ordering and delivery, we do not need to shake up the whole regression model, because you can immediately see the functional blocks that have been modified. That is, keeping the test suite up to date has become faster, and therefore cheaper.
Problem with stands
Previously, no one checked the performance of the stands prior to acceptance testing. For example, they give us a stand for testing, we drive regression tests on it for several hours. They fall, understand, fix, run tests again. That is, we lose time on debugging and repeated runs.
The problem was solved simply: only 15 API tests were written, testing the configuration of the stands, which are not related to functionality. Tests are independent of the build version; they only check all integration points that are critical for passing scripts.
This helped save a lot of time. After all, before the automation, we had 14 testers, the checks were cumbersome and lengthy, there were scenarios for almost the whole day of work, consisting of 150 steps. And now you are testing, and somewhere at the 30–40–110th step you understand that the stand does not work. Multiply the lost work time by 14 people and are terrified. And after the introduction of automation and testing of stands, it was possible to reduce the number of testers by half and get rid of downtime, which brought much joy to the chief accountant.
Cherry on the cake
The first cherry is the bugflow. Formally, this is the life cycle of any bug, and in fact any entity. For example, we operate on this concept in Jira. One additional status allowed us to speed up releases.
In general, the process looks like this: they found the incident, took it to work, completed work on it, transferred it to testing, tested it, closed it.

We understand that the defect has been closed, the problem has been solved. And they added another status: “for regression testing”. This means that after the analysis, scenarios that detect critical bugs are added to the regression set of 900 scenarios. If they were not there, or if they had insufficient detail, it means that we have instant feedback on the status of the product or pilot.

That is, we understand that there is a problem, and for some reason we have not considered it. And now adding a bug check script saves a lot of time.
We also implemented a retrospective at the level of testing. It looks like this: they made up a sign “release number, number of bugs in it, number of blockers and other scenarios, and number of resolutions”. At the same time, we estimated the number of invalid resolutions. For example, if out of 40 bugs it turns out 15 are invalid, then this is a very bad indicator, testers are wasting not only their time, but also the time of developers who are working on these bugs. The guys started to reflect, to deal with it, they introduced the procedure of revision of bugs by more experienced testers before being sent to the development. And they did it very well.
Thus, there is a constant reflection and work on quality improvement. All product bugs are analyzed: a test is created for each bug, which is immediately included in the regression set. If possible, this test is automated and runs on a regular basis.
results
It was originally planned to increase the frequency of releases and reduce the number of errors, but the result exceeded expectations somewhat. Reasonably built automation process made it possible to increase the number of automated tests in a short time, and the analysis of missed bugs conducted allowed the development and testing team to optimally prioritize the scenarios and focus on the most important.
Automation Summary:
- up to 4 days (instead of the previous 10), the duration of regression tests was reduced;
- manual testing team decreased by 50%;
- с 30–35 до 25 дней сократилась продолжительность time to market — с момента поступления фичи в бэклог команды до её выхода на пилот.
Команда автоматизации тестирования, «Инфосистемы Джет»