MIT course "Security of computer systems". Lecture 9: "Web Application Security", part 2
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems." Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Control of hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
Lecture 4: “Privilege Separation” Part 1 / Part 2 / Part 3
Lecture 5: “Where Security System Errors Come From” Part 1 / Part 2
Lecture 6: “Capabilities” Part 1 / Part 2 / Part 3
Lecture 7: “Native Client Sandbox” Part 1 / Part 2 / Part 3
Lecture 8: “Network Security Model” Part 1 / Part 2 / Part 3
Lecture 9: “Web Application Security” Part 1 / Part 2/ Part 3
For example, Django will take these angle brackets, translate them into HTML form and remake the rest of the characters. That is, if the custom value of the name contains angle brackets, double quotes, and the like, all these characters will be excluded. It will make the content not be interpreted as HTML code on the client’s browser side.
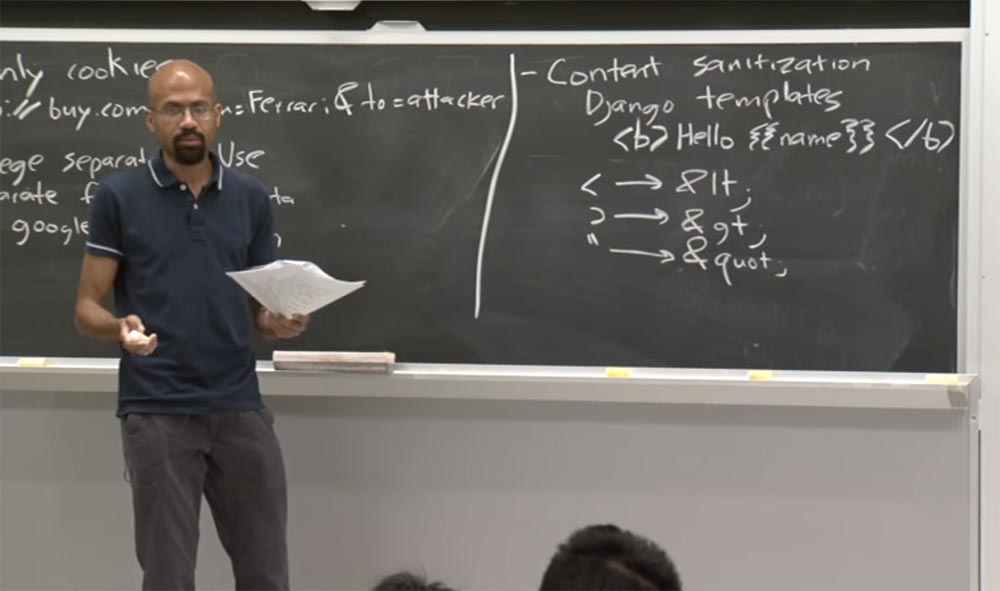
So now we know that this is not quite reliable protection against some cross-site scripting attacks. The reason, as we showed in the example, is that these grammars are for HTML, and CSS and JavaScript are so complex that they can easily confuse the browser's parser.
For example, we have a very common thing that is done within Django. So, you have some div function, and we want to set a dynamic class to it. We give the class a value of var, so on and so forth. The idea is that when Django processes this, he has to figure out what the current style is, and then insert it here.
In this case, the attacker can create a string that defines this class, for example, writes “class 1”. Up to this point, everything is going well with us, because it looks like a valid CSS expression.
But then the attacker places an onclick statement here, equal to the JavaScript code that makes the system call.

Since this is wrong, the browser would simply have to stop here. But the problem is that if you have ever seen the HTML of a real web page, everything is broken and confused, even for legitimate, “friendly” sites. So if the browser stops before every erroneous HTML expression, not one site that you like will simply never work. If you ever want to give up on the world, and I didn’t help you enough, just open the JavaScript console in your browser while browsing the site to see how many errors it will give you.
You can, for example, go to the CNN website and just see how many errors there will be. Yes, mostly CNN works, but very unevenly. For example, to open Acrobat reader, it is constantly required to reset the zero pointer exceptions, and at the same time you will feel a little deceived by life. But on the Internet, we learned to take this without much resentment.
Therefore, since browsers must be very tolerant of such things, they will try to turn malicious code into something that seems reasonable to them. And therein lies a security vulnerability.
This is how content disinfection works, and it's still better than nothing. She can catch a lot of bad stuff, but she can't defend against everything.
There is one more thing to think about - using a less expressive markup language. Let's see what is meant.
Audience: what to do if content clearing does not work?
Professor: yes, this is possible, for example, in this case Django will not be able to statically determine that it is bad. For example, in this particular case. But in the case when I insert a malicious image tag ...
Audience: in this particular case, I would expect the class assignment to be in quotes and in this case should not have any effect ...
Professor:Well, you see, there are some tricks there. If we assume that the grammar of HTML and CSS are carefully defined, then we can imagine a world in which ideal parsers could somehow grasp these problems or somehow transform them into normal things. But in fact, HTML grammars and CSS grammars suffer from inaccuracies. In addition, browsers do not implement specifications. Therefore, if we use a less expressive grammar, it will be much easier for us to disinfect the content.
Here the term Markdown is used - “easy-to-read markup” instead of the term Markup — ordinary markup. The main idea of Markdown is that it is designed as a language that, for example, allows users to send comments, but does not contain the ability to use an empty tag, applet support, and the like. Therefore, in Markdown, it is actually much easier to unambiguously identify a grammar and then simply apply it.

It is much easier to do disinfection in a simple language than in full-scale HTML, CSS, and JavaScript. And in a sense, it’s like the difference between understanding C code and Python code. There is actually a big difference in understanding a more expressive language. Therefore, by limiting expressiveness, you often improve security.
CSP, the content security policy, is also used to protect against cross-site scripting attacks. The idea of CSP is that it allows a web server ...
Audience: I'm just curious to find out about this Markdown language. Do all browsers know how to parse a language?
Professor: no, no, no. You can simply convert different types of languages to HTML, but in their original form, browsers do not understand them. In other words, you have a commenting system, and it uses Markdown. That is, comments, before being displayed on the page, go to the Markdown compiler, which translates them into HTML format.
Audience: so why not always use Markdown?
Professor:Markdown allows you to use embedded HTML, and as far as I know, there is a way to disable it in the compiler. But I could be wrong about that. The fact is that it is not always possible to use a limited language, and not everyone wants to do that.
So let's continue the conversation on how to increase security with the Content Security Policy. This policy allows the server to tell the web browser what types of content can be loaded on the page that it sends back, as well as where this content should come from.
For example, in an HTTP response, the server might use something like this: it includes the Content - Security - Policy header, the default source is self, and it will accept data from * .mydomain.com.

With the self operator, the server indicates that content from this site should only come from the domain of a particular page or any subdomain mydomain.com. This means that if we had a self binding to foo.com, the server would send this page back to the browser.
Suppose a cross-site scripting attack attempts to create a link to bar.com. In this case, the browser will see that bar.com is not self and is not the domain mydomain.com, and will not miss this request further. This is a fairly powerful mechanism in which you can specify more detailed controls. You set the parameters, indicating that your images should come from such a source, scripts from such and so on. It is actually convenient.
In addition, this policy actually prevents embedded JavaScript, so you cannot open the tag, write some script and close the tag, because everything that can go to the browser must come only from a specific source. CSP prevents such dangerous things as the use of the argument to the eval () function, which allows a web page to execute dynamically generated JavaScript code. So if the CSP header is set, the browser will not perform eval ().
Audience: Is this all that CSP protects against?
Professor: no. There is a whole list of resources that it actually protects, and you can set up protection against a lot of unwanted things, for example, specify where you can receive outgoing CSS and a bunch of other things.
Lecture hall:but there are other things besides eval () that threaten security?
Professor: Yes, they do. Therefore, the question always arises about the completeness of protection. For example, not only eval can dynamically generate JavaScript code. There is also a constructor of functions, there are certain ways to call a specified waiting time, you go to a string and can analyze the code in this way. CSP can disable all these dangerous attack vectors. But this is not a panacea for the complete isolation of malicious exploits.
Audience: Is it true that CSP can be configured to disallow checking all internal scripts on a page?
Professor:Yes, it helps prevent the execution of dynamically generated code, and the embedded code should be ignored. The browser should always get the code from the source attribute. In fact, I don’t know if all browsers do this. Personal experience shows that browsers exhibit different behaviors.
In general, Internet security is akin to the natural sciences, so people just put forward theories about how browsers work. And then you see how it actually happens. And the real picture may disappoint, because we are taught that there are algorithms, evidence, and the like. But these browsers behave so badly that the results of their work are unpredictable.
Browser developers try to be one step ahead of the attackers, and you will see examples of this in the lecture. In fact, CSP is a pretty cool thing.
Another useful thing is that the server can set an HTTP header called X-Content-Type-Options, the value of which is nosniff.

This header prevents MIME from discarding the response from the declared content type, since the header tells the browser not to override the content type of the response. With the nosniff option, if the server says the content is text / html, the browser will display it as text / html.
Simply put, this header prevents the browser from “sniffing” the response from the declared type of content, so that the browser doesn’t say: “aha, I sniffed the discrepancy between the file extension and the actual content, so I’ll turn this content into some other, understandable me a thing. " In this case, it turns out that you suddenly gave the keys to the kingdom to the barbarians.
Therefore, by setting this header, you are thereby instructing the browser to do nothing of the kind. This can significantly mitigate the effects of certain types of attacks. This is a brief overview of some vulnerability factors for cross-site scripting attacks.
Now let's look at another popular attack vector, SQL. You've probably heard about the attacks called “SQL injection”, or SQL-injection attack. The essence of these attacks is to use a website database. To dynamically build the page shown to the user, database queries are required that are issued to this internal server. Imagine that you have a request to fetch all the values from a particular table, where the User ID field is equal to what is determined on the Internet from a potentially unreliable source.

We all know how this story will end - it will end very badly, there will be no survivors here. Because what comes from an unverified source can cause a lot of trouble. Alternatively, you can give the user id string the following value: user id = “0; DELETE TABLE “.
So what will happen here? Basically, the server database will say: “OK, I will set the user ID to zero, and then execute the“ delete table ”command. And everything is finished with you!
They say that a couple of years ago a kind of viral image appeared. Some people in Germany installed license plates on which 0 was written; DELETE TABLE. The idea was that traffic cameras use OCR to recognize your number, and then put this number into the database. In general, the people of "Volkswagen" decided to use this vulnerability, placing the malicious code on their numbers.
I don’t know if it worked because it sounds funny. But I would like to believe that this is true. So I repeat once again - the idea of disinfection is to prevent content from untrusted sources from running on your site.

Therefore, pay attention to the fact that there may be some simple things that do not work as they should. So, you might think: “well, why can't I just put one more quote at the beginning of a line and another at the end, in order to rule out the execution of the malicious code of the intruder between the triple quotes”?
user id = "" + user id + ""
But it does not work, because the attacker can always just place the quotation marks inside the attacking line. So in most cases such a “half-hack” will not bring you as much security as you expect.
The solution here is that you need to carefully encrypt your data. And once again, when you receive information from an unreliable source, do not insert it into the system as it is. Make sure that it will not be able to jump out of the sandbox if you put it there in order to execute a malicious exploit.
For example, you want to insert the escape function to prevent the comma from being used in raw form. To do this, many of the web frameworks, such as Django, have built-in libraries that allow you to avoid SQL queries in order to prevent doing such things. These frameworks encourage developers to never directly interact with the database. For example, Django itself provides a high-level interface that performs disinfection for you.
But people always care about performance, and sometimes people think that these web frameworks are too slow. So, as you will soon see, people will still do raw SQL queries, which can lead to problems.
Problems can occur if the web server accepts path names from untrusted images. Imagine that somewhere on your server you are doing something like this: open with “www / images /” + filename, where filename is represented as something like ... / ... / ... / ... / etc / password.

That is, you give the command to open an image at this address from an untrusted user file, which in fact can seriously harm you. Thus, if you want to use a web server or web framework, then you should be able to detect these dangerous characters and avoid them in order to prevent these raw commands from being executed.
Let's take a break from discussing content disinfection and talk a little about cookies. Cookies are a very popular way to manage sessions in order to bind a user to some set of resources that exist on the server side. Many frameworks like Django or Zoobar, which you will get to know later, actually place a random session ID inside the cookie. The idea is that this session identifier is an index on some server-side
table : table [session ID] = user info.
That is, the session ID is equal to some user information. As a result, this session ID and cookies are very sensitive in their extension. Many attacks include theft of cookies to obtain this session ID. As we discussed in the last lecture, the same policy of the same source of origin can help you, to a certain extent, against some of these cookie theft attacks. Because there are rules based on the same origin policy that prevent arbitrary cookie changes.
The subtlety is that you don’t have to share a domain or subdomain with someone you don’t trust. Because, as we said in the last lecture, there are rules that allow two domains or subdomains of the same origin to access each other’s cookies. And therefore, if you trust a domain that you don’t have to trust, it may be able to directly set the session ID in these cookies, to which you both have access. This will allow the attacker to force the user to use the session identifier chosen by the attacker.

Suppose an attacker sets a Gmail user's cookie. A user logs in to Gmail and type in a few emails. The attacker can then use this cookie, in particular, use this session identifier, download Gmail and then access Gmail as if he or she were a victim user. Thus, there are many subtleties that can be done using these cookies to manage sessions. We will discuss some of them today and in subsequent lectures.
Maybe you think you can just get rid of cookies? After all, they bring more problems than good. Why can not they be abandoned?
Imagine the existence of a stateless cookie, or “stateless cookies,” to somehow get rid of the concept of sessions in general and to prevent this unpleasant attack vector, which seems to prevail in all our discussions.
So the basic idea is that if you don’t want to save the state of the request, you must authenticate each request. Therefore, a useful property of cookies is that they follow you wherever you go. Thus, you are authenticated once, and then in each subsequent request you have this small token. But if you want to get rid of these things, then, in fact, you must have some proof of your credentials in every request you make.
One way to do this is to use something called the MAS, the Message Authentication Codes, or message authentication codes. This is a kind of hash that requires a key. This code contains a hash of a certain key HCK and some message m. The basic idea is that the client, the user, and the server share the secret key K with each other. Thus, the client uses this key to create a message signature, which he sends to the server. And then the server, which also knows this key, can then use the same function to verify the signature.

Let's look at a specific example of how this works. One of the real services that use a stateless cookie is Amazon’s Internet services, for example, x3. Basically, Amazon’s web service, denoted by AWS, gives each user two things. The first is the secret key K, the second is the AWS user ID, which is not a secret.

And so every time you want to send a request to AWS via HTTP, you must send it in a special format.
For example, if you want to access photos of cats, which is not surprising, then the first line you will have:
GET / photos / cat; .jpg HTTP / 1.1, followed by a line from the host with the name of some AWS server:
HOST: - - - - -, and the third line with the date, for example:
DATE: Mon, June 4, and at the very end you will have a string with an authorization field, the place where the message authentication code is located. It consists of a part that represents your user ID, and a part that looks like a random set of letters, which is a signature.

So what does this signature look like? Basically this signature is above the line that encapsulates a bunch of details of this query from the top 3 lines.
In fact, the String To Sign authorization string looks like this:
- HTTP verb, in our case it is GET;
- checksum of the contents of the MDS message;
- content type, for example html or jpg image;
- date;
- the name of the resource, which is essentially the path that you see here.

In other words, this line is a message that you send to the HCK MAC. Please note that the server can see all this in the request in clear text. This allows the server to verify the correctness of the message authentication code, because the server shares this key with the user. Thus, this method allows the server to check this kind of material. It's clear?
In this case, for content, it looks like an empty string, but you can imagine it as a message or something like that. Yesterday, I checked the Amazon documentation and made sure that they still use the stateless cookie, since the MD5 hashing algorithm is not the best option in this case.
Not to confuse you, I’ll say that the basic idea is that we want to get rid of the notion of a persistent cookie that accompanies the user everywhere. But a problem arises - now the server needs a way to determine which client it is talking to.
To do this, you need to provide each client with a unique key that he will use with the server. Whenever a client sends a message to the server, it sends a special cryptographic operation “HCK, m” with it.

In the ordinary world, cookies would be used instead of authorization. But now we get rid of them and insert into the query this clear text message GET / photos / cat; .jpg HTTP / 1.1 and encryption, which allows the server to find out from whom this thing. Thus, the server knows who the user is, because it is embedded in the request. It's not a secret, right? But this allows the server to say: "Yeah, I know what secret key this user should have used to create this request, if this is a real user."
56:15
MIT course "Computer Security". Lecture 9: "Web Application Security", part 3
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only here2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?