The problem of cold start personalization news feed
Today we would like to talk about our research in the field of personalization of the news feed in the framework of the favoraim project . The very idea of showing the user only the news (hereinafter the entries) that will be of interest to him is not new and quite natural. To solve this problem, there are well-established and well-established models.
The principle of operation of these algorithms is similar: we analyze the response of users (feedback) to previous records and try to predict its reaction to current events. If the reaction is “positive”, the event falls into the tape, if “negative” - does not fall.About what is a "positive" and "negative" reaction later, but for now let's consider what kind of reaction we can get from the user:
For the first and second cases, we can predict the rating for an event that the user has not yet managed to rate, based on the ratings of the same event by other users. To do this, we can use some kind of correlation model (for example, k-nearest neighbor (kNN), where we use the estimates of “similar” users of the same record to predict record ratings), or a latent model based on matrix decomposition (for example, SVD or SVD ++), which is more preferred. In the latter case, when we only have data on the records we’ve viewed, we proceed from the assumption that the user will view the records he is interested in more often than uninteresting ones and perceive the viewing as a positive assessment. Here we have only positive-only feedback, and it’s better to use a different model, for example, Bayesian personalized ranking (BPR). Talking about these models does not make sense, there are a lot of materials on this topic on the network.
Predicted ratings can be used both for ranking records and as a filter (event “interesting” - show, “not interesting” - not show). For filtering, we need to enter some threshold value, above which we consider the rating to be positive. Here you can come up with as many heuristics as possible, for example, in the first case, the average user rating from our list of reactions suggests itself, in the second - 0. If we want to get a reasonable threshold value, we can use ROC analysis.
And now the problem: in order to predict the user's rating for any record, we need someone to rate this record, moreover, it is better that there are many such ratings. In practice, we will constantly encounter a situation where the record will not have ratings. An obvious example is a record just added. This is the so-called cold start problem. We will talk about this problem in more detail.
Obviously, to solve this problem, we need to stop considering the event as a kind of black box, as was done in the previous approach. You need to get some characteristics of the record itself. As such characteristics, we will begin to use the “themes” of the recording. We will proceed from the assumption that the user gives a rating to the record based on the fact that he liked or did not like one or more topics of this record. How to highlight the topics of the record we described in a previous article ( Automatic placement of search tags ). Such a model is a rather rough approximation and you can come up with as many examples of records with the same topics, to which the user will have a different reaction, but the error as a result is relatively small.
We’ll already have a lot of information about the user’s attitude to a particular topic if the user has shown any activity in the system (views and ratings of records with this topic, search queries with this topic, etc.). Thus, we have some information about the attitude of a particular user to the topics of a particular record and we need to predict whether the record will be “interesting” to the user or not.
Let's digress a bit and consider an example from biology. We will be interested in a simplified model of the nerve cell (Fig. 1). The principle of its operation is as follows: through dendrites, electrical impulses enter the nucleus of a nerve cell from the external environment. The impulse can be either positive or negative. Also, different dendrites may have different bandwidths, i.e. the pulse passing through different dendrites also differs in modulus. The nucleus of a neuron is able to accumulate charge. When the charge builds up sufficiently large, the cell generates an impulse that is transmitted along the axon. This behavior is described by the McCulloch – Pitts model (Fig. 2).
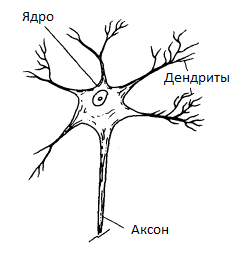
Fig. 1
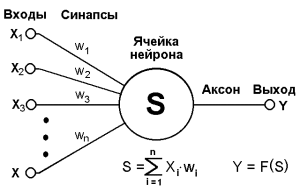
Fig. 2
Now apply this model to our task. We will submit data on the neuron’s inputs about the user's attitude to the subject of the event (various estimates of other events on these topics, the number of searches with these topics, the number of views of events with these topics, etc.) Then we find the value of S, and if S> 0, we will consider the event “interesting”. Otherwise - "uninteresting." This model is also called a linear classifier.
All that remains for us is to determine the values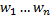 . This process is called classifier training. The principle of training is as follows: we take records that users have already rated (training sample), we find values for each of them
. This process is called classifier training. The principle of training is as follows: we take records that users have already rated (training sample), we find values for each of them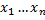 and with the help of our classifier we are trying to predict an already known estimate for this record. The task is to find the values that give the smallest number of errors in our training set. This problem is solved by any known optimization method. Most sources recommend that you use the stochastic gradient descent (SG) method for this task, but you won’t be able to apply it “forehead” to this task. There is a set of heuristics that still allow you to effectively apply this method to solve this problem, but in our case, we used genetic algorithms that seemed more preferable for solving this problem on relatively small training samples.
and with the help of our classifier we are trying to predict an already known estimate for this record. The task is to find the values that give the smallest number of errors in our training set. This problem is solved by any known optimization method. Most sources recommend that you use the stochastic gradient descent (SG) method for this task, but you won’t be able to apply it “forehead” to this task. There is a set of heuristics that still allow you to effectively apply this method to solve this problem, but in our case, we used genetic algorithms that seemed more preferable for solving this problem on relatively small training samples.
Genetic algorithms model the process of natural selection to solve the optimization problem. The principle of its work is as follows: a population of “individuals” is created, in the genotype of which the values of variables are encoded (in our case). Individuals of the population interbreed and mutate. The greater chance of "survival" - to remain in the population - is given to those individuals who better solve the task. This method has the following advantages:
The disadvantages include the speed of work. For super-large amounts of data, stochastic gradient descent will work incomparably faster. But here it all depends on the task.
Now let's move on to the mathematical part. Based on the training sample, we need to construct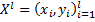 a classification algorithm
a classification algorithm 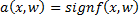 with two classes
with two classes 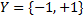 , where
, where  is the discriminant function, w is the vector of parameters.
is the discriminant function, w is the vector of parameters. 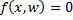 - dividing surface. The function has the form
- dividing surface. The function has the form 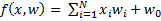 .
. 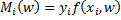 - margin of the object
- margin of the object 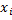 .
. 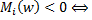 the algorithm
the algorithm 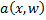 is wrong on .
is wrong on .
At this point, I want to drop everything and start training the classifier, minimizing the number of errors in the training sample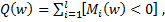 however, such a solution will not be entirely correct, because as a result, some objects can be quite close to the dividing plane. This will not affect the fitness function, as As a result, it will give the correct result on the training sample. However, with minor changes in x, the object can change the class, as a result of which, in the control sample, we most likely will not get the best results. In addition to this, we will have to minimize the discrete function, and this is a very dubious pleasure. To solve this problem, we introduce a non-increasing non-negative loss function
however, such a solution will not be entirely correct, because as a result, some objects can be quite close to the dividing plane. This will not affect the fitness function, as As a result, it will give the correct result on the training sample. However, with minor changes in x, the object can change the class, as a result of which, in the control sample, we most likely will not get the best results. In addition to this, we will have to minimize the discrete function, and this is a very dubious pleasure. To solve this problem, we introduce a non-increasing non-negative loss function 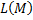 and we minimize the function
and we minimize the function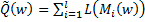 , thus encouraging large indentation, the value of which can be considered the degree of severity of the class. Most often, a logarithmic function is used as a loss function
, thus encouraging large indentation, the value of which can be considered the degree of severity of the class. Most often, a logarithmic function is used as a loss function 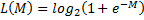 , however, it is not limited to one choice.
, however, it is not limited to one choice.
Along with the replacement of the loss function, it is recommended to add a penalty term to the functional Q that prohibits too large values of the norm of the weight vector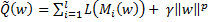 . The addition of a penalty term or regularization reduces the risk of retraining and increases the stability of the weight vector in relation to small changes in the training sample. The regularization parameter is
. The addition of a penalty term or regularization reduces the risk of retraining and increases the stability of the weight vector in relation to small changes in the training sample. The regularization parameter is 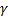 selected either from a priori considerations, or by rolling control (cross-validation).
selected either from a priori considerations, or by rolling control (cross-validation).
Functional optimization by a genetic algorithm is quite trivial. For the first experiments with data, the evoj library is quite suitable. In the future, it is better to use the coevolutionary algorithm in order to more efficiently select from local minima.
As a conclusion, I will say that this method can be used in conjunction with some latent model, transmitting the predicted record score as one of the parameters of the linear classifier.
The principle of operation of these algorithms is similar: we analyze the response of users (feedback) to previous records and try to predict its reaction to current events. If the reaction is “positive”, the event falls into the tape, if “negative” - does not fall.About what is a "positive" and "negative" reaction later, but for now let's consider what kind of reaction we can get from the user:
- Record rating, for example, on a five-point scale.
- Like / dislike, which is a special case of the first option (-1, +1)
- Implicit feedback (implicit feedback), it can be, for example, the fact that the user opened the page of this record; the time that the user was viewing recording information, etc.
For the first and second cases, we can predict the rating for an event that the user has not yet managed to rate, based on the ratings of the same event by other users. To do this, we can use some kind of correlation model (for example, k-nearest neighbor (kNN), where we use the estimates of “similar” users of the same record to predict record ratings), or a latent model based on matrix decomposition (for example, SVD or SVD ++), which is more preferred. In the latter case, when we only have data on the records we’ve viewed, we proceed from the assumption that the user will view the records he is interested in more often than uninteresting ones and perceive the viewing as a positive assessment. Here we have only positive-only feedback, and it’s better to use a different model, for example, Bayesian personalized ranking (BPR). Talking about these models does not make sense, there are a lot of materials on this topic on the network.
Predicted ratings can be used both for ranking records and as a filter (event “interesting” - show, “not interesting” - not show). For filtering, we need to enter some threshold value, above which we consider the rating to be positive. Here you can come up with as many heuristics as possible, for example, in the first case, the average user rating from our list of reactions suggests itself, in the second - 0. If we want to get a reasonable threshold value, we can use ROC analysis.
And now the problem: in order to predict the user's rating for any record, we need someone to rate this record, moreover, it is better that there are many such ratings. In practice, we will constantly encounter a situation where the record will not have ratings. An obvious example is a record just added. This is the so-called cold start problem. We will talk about this problem in more detail.
Obviously, to solve this problem, we need to stop considering the event as a kind of black box, as was done in the previous approach. You need to get some characteristics of the record itself. As such characteristics, we will begin to use the “themes” of the recording. We will proceed from the assumption that the user gives a rating to the record based on the fact that he liked or did not like one or more topics of this record. How to highlight the topics of the record we described in a previous article ( Automatic placement of search tags ). Such a model is a rather rough approximation and you can come up with as many examples of records with the same topics, to which the user will have a different reaction, but the error as a result is relatively small.
We’ll already have a lot of information about the user’s attitude to a particular topic if the user has shown any activity in the system (views and ratings of records with this topic, search queries with this topic, etc.). Thus, we have some information about the attitude of a particular user to the topics of a particular record and we need to predict whether the record will be “interesting” to the user or not.
Let's digress a bit and consider an example from biology. We will be interested in a simplified model of the nerve cell (Fig. 1). The principle of its operation is as follows: through dendrites, electrical impulses enter the nucleus of a nerve cell from the external environment. The impulse can be either positive or negative. Also, different dendrites may have different bandwidths, i.e. the pulse passing through different dendrites also differs in modulus. The nucleus of a neuron is able to accumulate charge. When the charge builds up sufficiently large, the cell generates an impulse that is transmitted along the axon. This behavior is described by the McCulloch – Pitts model (Fig. 2).
Fig. 1
Fig. 2
Now apply this model to our task. We will submit data on the neuron’s inputs about the user's attitude to the subject of the event (various estimates of other events on these topics, the number of searches with these topics, the number of views of events with these topics, etc.) Then we find the value of S, and if S> 0, we will consider the event “interesting”. Otherwise - "uninteresting." This model is also called a linear classifier.
All that remains for us is to determine the values
. This process is called classifier training. The principle of training is as follows: we take records that users have already rated (training sample), we find values for each of themand with the help of our classifier we are trying to predict an already known estimate for this record. The task is to find the values that give the smallest number of errors in our training set. This problem is solved by any known optimization method. Most sources recommend that you use the stochastic gradient descent (SG) method for this task, but you won’t be able to apply it “forehead” to this task. There is a set of heuristics that still allow you to effectively apply this method to solve this problem, but in our case, we used genetic algorithms that seemed more preferable for solving this problem on relatively small training samples.Genetic algorithms model the process of natural selection to solve the optimization problem. The principle of its work is as follows: a population of “individuals” is created, in the genotype of which the values of variables are encoded (in our case
). Individuals of the population interbreed and mutate. The greater chance of "survival" - to remain in the population - is given to those individuals who better solve the task. This method has the following advantages:- No need to select the initial approximation
- Due to mutation, the algorithm has a chance not to focus around local minima.
The disadvantages include the speed of work. For super-large amounts of data, stochastic gradient descent will work incomparably faster. But here it all depends on the task.
Now let's move on to the mathematical part. Based on the training sample, we need to construct
a classification algorithm with two classes , where is the discriminant function, w is the vector of parameters. - dividing surface. The function has the form . - margin of the object . the algorithm is wrong on . At this point, I want to drop everything and start training the classifier, minimizing the number of errors in the training sample
however, such a solution will not be entirely correct, because as a result, some objects can be quite close to the dividing plane. This will not affect the fitness function, as As a result, it will give the correct result on the training sample. However, with minor changes in x, the object can change the class, as a result of which, in the control sample, we most likely will not get the best results. In addition to this, we will have to minimize the discrete function, and this is a very dubious pleasure. To solve this problem, we introduce a non-increasing non-negative loss function and we minimize the function, thus encouraging large indentation, the value of which can be considered the degree of severity of the class. Most often, a logarithmic function is used as a loss function , however, it is not limited to one choice. Along with the replacement of the loss function, it is recommended to add a penalty term to the functional Q that prohibits too large values of the norm of the weight vector
. The addition of a penalty term or regularization reduces the risk of retraining and increases the stability of the weight vector in relation to small changes in the training sample. The regularization parameter is selected either from a priori considerations, or by rolling control (cross-validation).Functional optimization by a genetic algorithm is quite trivial. For the first experiments with data, the evoj library is quite suitable. In the future, it is better to use the coevolutionary algorithm in order to more efficiently select from local minima.
As a conclusion, I will say that this method can be used in conjunction with some latent model, transmitting the predicted record score as one of the parameters of the linear classifier.