Parallelism in PostgreSQL: not spherical, not a horse, not in a vacuum

Scaling a DBMS is a continually coming future. DBMSs are being improved and better scaled on hardware platforms, while hardware platforms themselves increase productivity, the number of cores, and memory — Achilles catches up with a turtle, but still has not caught up. The problem of scaling the database is full-length.
Postgres Professional faced the problem of scaling not only theoretically, but also practically: from its customers. And more than once. About one of these cases and will be discussed in this article.
PostgreSQL scales well on NUMA systems if it is a single motherboard with multiple processors and multiple data buses. Some optimizations can be read here and here.. However, there is another class of systems, they have several motherboards, the data exchange between them is carried out using an interconnect, and one instance of the operating system works on them and for the user this design looks like a single machine. And although formally such systems can also be attributed to NUMA, but in essence they are closer to supercomputers, since access to the local memory of a node and access to the memory of a neighboring node differ radically. The PostgreSQL community believes that the only Postgres instance running on such architectures is the source of the problems, and there is no systematic approach to solving them.
This is explained by the fact that the software architecture that uses shared memory is fundamentally calculated on the fact that the access time of different processes to its own and remote memory is more or less comparable. In the case when we work with many nodes, the rate on shared memory as a fast communication channel ceases to justify itself, because due to delays (latency) it is much “cheaper” to send a request to perform a certain action to the node (node) data of interest than to send this data on the bus. Therefore, cluster solutions are relevant for supercomputers and systems with many nodes in general.
This does not mean that a combination of multisite systems and a typical Postgres shared memory architecture must be put in a cross. After all, if the postgres processes spend most of the time doing complex calculations locally, then this architecture will even be very efficient. In our situation, the client had already purchased a powerful multi-node server, and we had to solve PostgreSQL problems on it.
And the problems were serious: the simplest write requests (change several field values in one record) were executed from a few minutes to an hour. As was later confirmed, these problems manifested themselves in all their glory precisely because of the large number of cores and, consequently, radical parallelism in the execution of requests with a relatively slow exchange between nodes.
Therefore, the article will turn out as a dual purpose:
- Share experience: what to do if in a multi-node system the base slows down in earnest. Where to start, how to diagnose, where to go.
- To tell how the problems of the PostgreSQL DBMS itself can be solved with a high level of concurrency. This includes how changing a lock algorithm affects PostgreSQL performance.
Server and DB
The system consisted of 8 blades with 2 sockets in each. In the amount of more than 300 cores (excluding hypertreaming). A fast tire (manufacturer's proprietary technology) connects the blades. Not that a supercomputer, but for a single instance of a DBMS, the configuration is impressive.
The load is also rather big. More than 1 terabyte of data. About 3000 transactions per second. Over 1000 connections to postgres.
Starting to deal with hourly wait recording, the first thing we have excluded as a reason for the delay recording on the disk. As soon as incomprehensible delays began, tests began to be done exclusively on
tmpfs. The picture has not changed. The disk has nothing to do with it.Getting mining diagnoses: submission
Since problems arose, most likely because of the high competition of processes that “knock” on the same objects, the first thing to check is blocking. In PostgreSQL, for such a check, there is a view
pg.catalog.pg_locksand pg_stat_activity. In the second, in version 9.6, information was added about what the process was waiting for ( Amit Kapila, Ildus Kurbangaliev ) - wait_event_type. Possible values for this field are described here . But first, just count:
postgres=# SELECT COUNT(*) FROM pg_locks;
count
—---—
88453
(1 row)
postgres=# SELECT COUNT(*) FROM pg_stat_activity;
count
—---—
1826
(1 row)
postgres=# SELECT COUNT(*) FROM pg_stat_activity WHERE state ='active';
count
—---—
1005These are real numbers. Reached up to 200,000 locks.
At the same time on the ill-fated request hung such locks:
SELECTCOUNT(mode), modeFROM pg_locks WHERE pid =580707GROUPBYmode;
count | mode
—-----+---------------—
93 | AccessShareLock
1 | ExclusiveLockWhen reading the buffer, the DBMS uses a lock
share, while writing it - exclusive. That is, write locks accounted for less than 1% of all requests. In the view, the
pg_lockstypes of locks do not always look as described in the user documentation . Here is a label:
AccessShareLock = LockTupleKeyShare
RowShareLock = LockTupleShare
ExclusiveLock = LockTupleNoKeyExclusive
AccessExclusiveLock = LockTupleExclusiveThe SELECT mode FROM pg_locks query showed that executions of the CREATE INDEX command (without CONCURRENTLY) are waiting for 234 INSERTs and 390 INSERTs are waiting
buffer content lock. A possible solution is to “teach” INSERTs from different sessions to intersect less over buffers.It's time to use perf
The utility
perfcollects a lot of diagnostic information. In the mode record... it records the statistics of system events in the files (by default, they are in ./perf_data), and in the mode it reportalizes the collected data, you can, for example, filter events related to postgresor only pid:$ perf record -u postgres или
$ perf record -p 76876 а затем, скажем
$ perf report > ./my_resultsAs a result, we'll see something like.
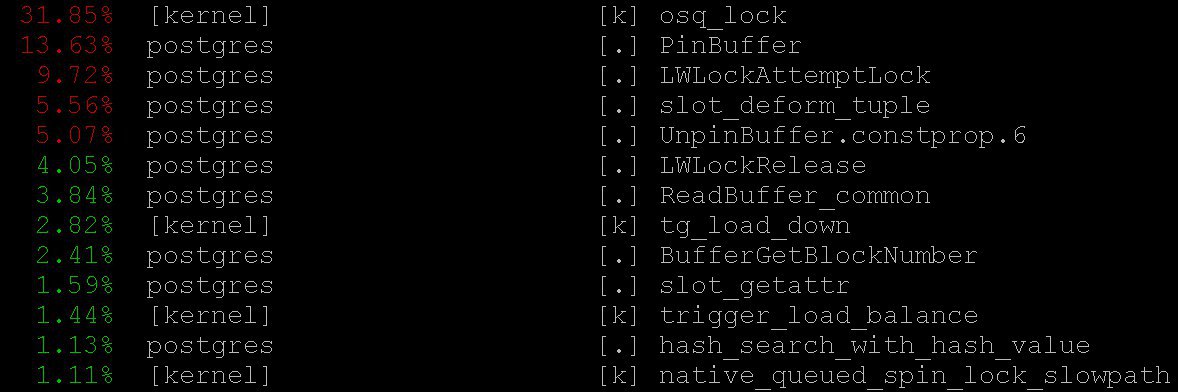
How to use
perfPostgreSQL for diagnostics is described, for example, here , as well as in the pg-wiki . In our case, even the simplest mode gave important information -
perf topworking, naturally, in the spirit of the topoperating system. With the help, perf topwe saw that the processor spends most of the time in kernel locks, as well as in functions PinBuffer()and LWLockAttemptLock().. PinBuffer()Is a function that increases the buffer reference count (displaying a data page to RAM), by which postgres processes know which buffers can be preempted and which ones can not. LWLockAttemptLock()- the function of taking LWLock'a. LWLock- this is a kind of loka with two levels sharedandexclusive, without defining deadlock's, locks are pre-allocated in shared memory, waiting processes are waiting in the queue. These functions have already been seriously optimized in PostgreSQL 9.5 and 9.6. Spinlock inside them were replaced by direct use of atomic operations.
Flame graphs
It is impossible to do without them: even if they were useless, they would still be worth telling about them - they are extraordinarily beautiful. But they are useful. Here is an illustration from
github, not from our case (neither we nor the client are ready for the disclosure of details yet). 
These beautiful pictures very clearly show what the processor cycles are going on. Data can collect the same
perf, but flame graphlucidly visualizes the data, and builds trees based on the collected call stacks. Details about profiling with flame graphs can be found, for example, here , and download everything you need here . In our case, the flame graphs showed a huge amount
nestloop. Apparently, the JOINs of a large number of tables in numerous parallel read requests caused a large number of access sharelocks. The statistics collected
perfshow where the processor cycles go. And although we have seen that most of the CPU time passes on locks, we did not see what exactly leads to such long waits for locks, because we don’t see where locks waits exactly, since pending processor time is not wasted. In order to see for yourself the expectations, you can build a query to the system view
pg_stat_activity.SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUPBY wait_event_type, wait_event;revealed that:
LWLockTranche | buffer_content | UPDATE *************
LWLockTranche | buffer_content | INSERT INTO ********
LWLockTranche | buffer_content | \r
| | insert into B4_MUTEX | | values (nextval('hib | | returning ID
Lock | relation | INSERT INTO B4_*****
LWLockTranche | buffer_content | UPDATE *************
Lock | relation | INSERT INTO ********
LWLockTranche | buffer_mapping | INSERT INTO ********
LWLockTranche | buffer_content | \r(asterisks here simply replace the details of the request that we do not disclose).
Values are visible
buffer_content(locking the contents of buffers) and buffer_mapping(locks on the components of the hash label shared_buffers).For help with GDB
But why so many expectations for these types of locks? For more detailed information about the expectations, we had to use the debugger
GDB. With the help GDBwe can receive a stack of calls of specific processes. Applying the sampling, i.e. Having collected a certain number of random call stacks, you can get an idea of which stacks have the longest expectations. Consider the process of building statistics. We will consider the “manual” collection of statistics, although in real life special scripts are used that do this automatically.
First
gdbyou need to attach to the PostgreSQL process. To do this, you need to find a pidserver process, say from$ ps aux | grep postgresSuppose we discovered:
postgres 2025 0.0 0.1172428 1240 pts/17 S июл23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/dataand now we
pidput in debager:igor_le:~$gdb -p 2025Once inside the debager, we write
bt[that is backtrace] or where. And we get a lot of information like this:(gdb) bt
#00x00007fbb65d01cd0in __write_nocancel () from
/lib64/libc.so.6
#10x00000000007c92f4in write_pipe_chunks (
data=0x110e6e8"2018‐06‐01 15:35:38 MSK [524647]:
[392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163
(http://192.168.70.163) LOG: relation 23554 new block 493:
248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1]
db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at
elog.c:3123
#20x00000000007cc07bin send_message_to_server_log
(edata=0xc6ee60 <errordata>) at elog.c:3024
#3EmitErrorReport () at elog.c:1479Collecting statistics, including call stacks from all postgre processes collected repeatedly at different points in time, we saw that for 3706 seconds (about an hour) the waiting
buffer partition lockinside lasted relation extension lock, that is, blocking the hash table of the buffer manager that was necessary for displacing the old buffer to later replace it with a new one corresponding to the extended part of the table. A number was also noticeable buffer content lock, which corresponded to the expectation of locking pages of the B-treeindex for the implementation of the insert. 
At first, there were two explanations for such a monstrous waiting time:
- Someone else took this
LWLockand stuck it. But this is unlikely. Because nothing complicated inside the buffer partition lock happens. - We are faced with some kind of pathological behavior
LWLock. That is, despite the fact that no one took a lock for too long, his expectation stretched out unnecessarily for a long time.
Diagnostic patches and treatment of trees
Having reduced the number of simultaneous connections, we would surely discharge the request flow for locks. But it would be like a surrender. Instead, Alexander Korotkov , the chief architect of Postgres Professional (of course, he helped prepare this article), suggested a series of patches.
First of all, it was necessary to get a more detailed picture of the disaster. No matter how good the finished tools, diagnostic patches of their own making will be useful.
A patch was written, adding a detailed logging of the time spent in
relation extension, what happens inside the function RelationAddExtraBlocks(). So we know what time is spent inside RelationAddExtraBlocks().And another patch was written in support of it, reporting
pg_stat_activityon what we are doing now relation extension. It was done this way: when expandingrelation, application_nameBecomes RelationAddExtraBlocks. This process is now conveniently analyzed with maximum details using gdb btand perf. Actually therapeutic (and not diagnostic) patches were written two. The first patch changed the behavior of leaf locks
B‐tree: earlier, when prompted to insert, the leaf was blocked as share, and after that it received exclusive. Now he immediately receives exclusive. Now this patch is already commited for PostgreSQL 12 . Fortunately, this year Alexander Korotkov received committer status - the second PostgreSQL committer in Russia and the second in the company. It has also been increased from 128 to 512.
NUM_BUFFER_PARTITIONSto reduce the load on the mapping locks: the hash table of the buffer manager was divided into smaller pieces, in the hope that the load on each specific piece will decrease. After the application of this patch, the blocking for the contents of the buffers is gone, but in spite of the increase
NUM_BUFFER_PARTITIONS, there remain buffer_mapping, that is, we recall, blocking the pieces of the hash table of the buffer manager:locks_count | active_session | buffer_content | buffer_mapping
----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐
12549 |1218| 0 |15And even not a lot. B-tree has ceased to be a bottleneck. The expansion came to the fore
heap-а.Treatment of conscience
Next, Alexander put forward the following hypothesis and solution:
We are waiting for a lot of time on the
buffer parittion lockdisplacement of the buffer. Perhaps buffer parittion lockthere is some very popular page on this, for example, the root of some B‐tree. In this place there is a non-stop stream of requests shared lockfrom reading requests. Waiting queue at
LWLock'e' not fair. Since shared lock's can be taken as many as you like at the same time, then if shared lockalready taken, then subsequent ones shared lock' and pass without a turn. Thus, if the stream of shared lock'ov has sufficient intensity so that between them there are no "windows", then the wait exclusive lockgoes almost to infinity.To fix this, you can try to offer - a patch of "gentleman's" behavior of locks. He awakens
shared lockerconsciences and they honestly stand in a queue when they are already there exclusive lock(interestingly, heavy locks hwlockhave no problems with conscience: they always honestly turn in the queue)locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec
‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------
173985 |1802| 0 |569| 0 |0All is well! Many
insertFemale not. Although the locks on the pieces of the hash tablets remained. But what to do, these are the properties of the bus of our little supercomputer. This patch was also proposed to the community . But whatever the fate of these patches in the community, nothing prevents them from getting into the next version of Postgres Pro Enterprise , which is designed just for customers with heavily loaded systems.
Morality
The
sharehighly moral, lightweight blocks — the blocks that pass into the queue exclusive— have solved the problem of hourly delays in a multi-node system. The hash label buffer manager-a did not work because of an excessively large stream of share locks which did not leave a chance for locks necessary for crowding out old buffers and loading new ones. Problems with expanding the buffer for the base tables were only a consequence of this. Before that, we managed to embroider a bottleneck with access to the root B-tree.PostgreSQL was not designed for NUMA architectures and supercomputers. Adapting Postgres to such architectures is a great job that would require (and possibly require) the coordinated efforts of many people and even companies. But the unpleasant consequences of these architectural problems can be mitigated. And we have to: the types of load that led to delays, similar to those described, are quite typical, we continue to receive similar distress signals from other places. Similar troubles were manifested before - on systems with a smaller number of cores, the consequences were not so monstrous, and the symptoms were treated in other ways and other patches. Now another medicine has appeared - not universal, but obviously useful.
So, when PostgreSQL works with the memory of the entire system as if it is local, no high-speed bus between nodes can compare with the access time to local memory. Tasks arise because of this difficult, often urgent, but interesting. And the experience of solving them is useful not only decisive, but also the entire community.
