Infrastructure as a code, we win on a scale (Kirill Vetchinkin, TYME)
The “Infrastructure as a code (IaC)” model, which is sometimes called the “programmable infrastructure”, is a model in which the process of setting up an infrastructure is similar to the process of programming software. In essence, she initiated the elimination of the boundaries between writing applications and creating environments for these applications. Applications may contain scripts that create and manage their own virtual machines. This is the foundation of cloud computing and an integral part of DevOps.
Infrastructure like code allows you to manage virtual machines at the program level. This eliminates the need for manual configuration and upgrades for individual hardware components. The infrastructure becomes extremely elastic, i.e. reproducible and scalable. One operator can deploy and manage both one and 1000 machines using the same set of code. Among the guaranteed benefits of infrastructure as a code are speed, efficiency and risk reduction.
About this is the decoding of the report of Kirill Vetchinkin at DevOpsDays Moscow 2018. In the report: reuse of Ansible modules, storage in Git, review, reassembly, financial benefits, horizontal scaling in 1 click.
Who cares, I ask under the cat.
Hello. As already mentioned, I am Kirill Vetchinkin. I work at TYME and today we will talk about infrastructure as a code. We will also talk about how we have learned to save on this practice, because it is quite expensive. To write a lot of code to set up the infrastructure is quite expensive.
Briefly tell about the company. I work for TYME. We had a rebranding. Now we are called PaySystem - as the name implies, we deal with payment systems. We have both our own solutions - these are processing and custom development. Custom development is electronic banking, billing and the like. And as you understand, if this is a custom development, then this is a large number of projects every year. The project is following the project. The more projects, the more the same type of infrastructure has to be raised. Since the projects are often highly loaded, we use microservice architecture. Therefore, in one project there are still many, many small subprojects.

Accordingly, it is very difficult to manage all this zoo without full-fledged DevOps. Therefore, in our company introduced various practices of DevOps. Naturally, we work on kanban, on SCRUM, we store everything in git. After zakommitili, there is a continuous integration, tests are run. Testers write on PyTest end-to-end tests that start every night. Unit-test starts after each commit. We use a separate process of assembly and deployment: collected, then deployed to different environments many times. We were on windows. On windows we deploy using Octopus deploy, This year we are developing on DotNet Core. Therefore, we are now able to run software on Linux systems. We left Octopus and came to Ansible. Today we will talk about this part, which is a new practice that we have developed this year, that which we did not have before. When you have tests, when you can build an application well, deploy it somewhere, everything is fine. But if you have two environments configured differently, then you still fall, and you fall on production. Therefore, managing configurations is a very important practice. Here we will talk about it today.

Briefly, I’ll tell you how a product's economy is built in terms of labor costs: 60 percent is spent on development , analytics takes about 10 percent, QA (testing) takes about 20 percent and everything else is spent on configuration. When systems run as a whole stream, many third-party software runs in them, the operating systems themselves are configured almost equally. We spend too much time on this, doing essentially the same thing. The idea was to automate everything and reduce the cost of infrastructure configuration. Tasks of the same type are automated, well debugged and do not contain manual operations.

Each application works in some environment. Let's see what it all consists of. We should at least have an operating system , it needs to be configured, there are some third - party applications that also need to be configured, the application itself needs to get configurations, but for the whole product to work, the application itself that runs in the entire system is running. There is still a network, which also needs to be configured, but we will not talk about the network today, because we have different customers, different network devices. We also tried to automate the configuration of the network, but since the devices are different, there was no particular use for it, they spent more resources on it. But we have automated operating systems, third-party applications, and the transfer of configuration parameters to the applications themselves.

Two approaches as you can configure the server: with hands - if you configure them with your hands, you can have such a situation that your production is configured in one way, the test is different, everything is green on the test, the tests are green. You deploy to production, and there is no framework in place — nothing works for you. Another example: three Application servers are configured by hand. One Application server is configured in one way, another Application server in another way. Servers can work in different ways. Another example: there was a situation when we have one Stage server completely stopped working. Launched the creation of a new server using and after 30 the server was ready. Another example: the server just stopped working. If you set up your hands, then you need to look for a person who knows how to set it up, you need to raise the documentation. As we know, documentation is hardly relevant. This is a big problem. And, most importantly, this is an audit, that is, roughly speaking, you have ten administrators, each of them is setting up something with his hands, it is not particularly clear that they have set it up correctly or incorrectly, and how to understand whether you need to do any then the settings could put something extra, open some unnecessary ports.

There is an alternative option - this is exactly what we are talking about today - this is the configuration from the code. That is, we have a git repository in which the entire infrastructure is stored. All scripts are stored there with the help of which we will customize it. Since this is all in git, we get all the benefits from managing the code, as in development, that is, we can do review, audit, change history, who did, why did, comments, we can roll back. To work with the code, you need to use a continuous assembly pipeline — a deployment pipeline. In order for some system to make changes to the server, that is, it was not the person who did something with his hands, but the system did it exclusively.

As a system that makes changes, we use Ansible. Since we do not have a huge number of servers, it suits us well. If you have 100-200 servers there, then you will have small problems, because it (ie, Ansible) still connects with each and adjusts them in turn - this is a problem. It is better to use other means that do not push (push), and bullet (pull). But for our history, when we have a lot of projects, but no more than 20 servers — this suits us perfectly. Ansible has a big plus - a low threshold of entry. That is, literally any IT specialist in three weeks can fully master it. He has many modules. That is, you can manage the clouds, networks, files, software installation, deployment - absolutely everything. If there are no modules, you can write your own,

In general, briefly consider how it looks at all, this tool. Ansible has modules, about which I have already spoken. That is, they can be delivered, they can write themselves, who do something. There are inventories - this is where we will roll our changes, that is, these are hosts, their IP addresses, variables specific to these hosts. And, accordingly, the role. Roles - this is what we will roll on these servers. And we also have hosts grouped in groups, that is, in this case, we see that we have two groups: a database server and an application server. In each group we have three cars. They are connected via ssh. Thus, we solve the problems that we talked about earlier, that in our first server we are configured identically, since the same role rolls onto the server. And in the same way, if we run this role on several machines,
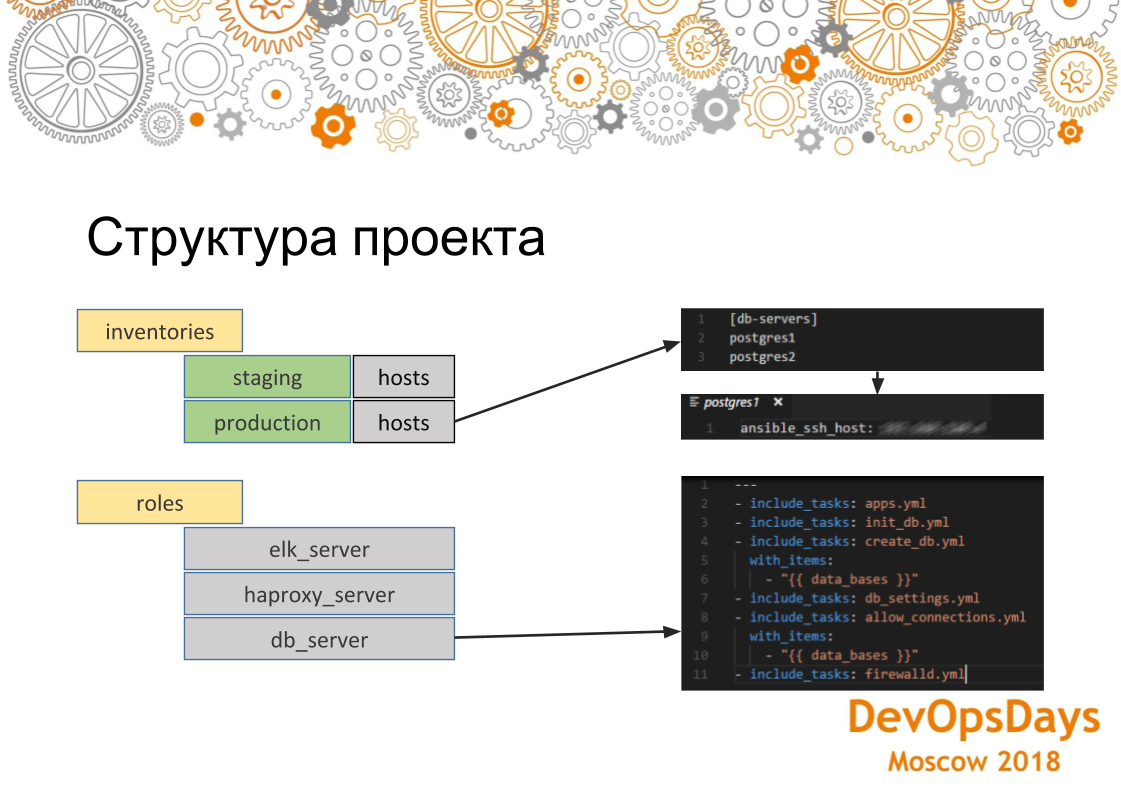
If we take a deeper look at how the Ansible project works, here we see that here inventories hosts are acceptable for production. This group is listed and there are two servers in it. If we go to a specific server, we see that the IP address of this machine is indicated here. There may also be other parameters - variables that are specific to this environment. If we look at the roles. That role contains several tasks (tasks) that will be executed. In this case, this is the role for installing PostgreSQL. That is, we install the necessary application, create databases. Here we use a loop. There are several of them (databases). Then we establish the necessary connection - IP addresses, which can be authorized in this database. And, accordingly, set up at the very end of the firewall. Settings will be applied to all servers in the group.

Just approaching the problem itself: we learned how to configure servers with Ansible perfectly and everything was fine. But, as I said, we have a lot of projects. They are almost all the same. Approximately such systems are involved in each project (k8s, RabbitMQ, Vault, ELK, PostgreSQL, HAProxy). For each we wrote our role. We can roll it from the button.

But we have a lot of projects and in each they essentially intersect. That is, in one such set, in the second such, in the third such. We get the intersection point, in which the same roles in different projects.

We have a repository with the application, there is a repository with the infrastructure for the project. The second project is exactly the same. The continuation of the infrastructure. And the third. If we implement the same thing, then in fact we get copy-paste. We will do the same role in 10 places. Then, if there is any mistake, we will rule in 10 places.

What we did: we each role that is common to all projects and all its configurations that come from the outside, we took out to a separate repository and put them into a separate daddy in a guitar - called TYME Infrastructure. There we have a role for PostgreSQL, for ELK, for deploying Kubernetes clusters. If we need to put the same PostgreSQL in some project, then we simply enable it as a submodule, rewrite the inventories, that is, roughly speaking, the configuration where to roll this role. We do not rewrite the role itself: it already exists. And we have PostgreSQL appearing at the click of a button in all new projects. If you need to raise the cluster Kubernetes - the same.

Thus, it turned out to reduce the cost of writing roles. That is, once written - 10 times used. When a project is following a project, it is very convenient. But since we are now working with infrastructure as with code, we naturally need pipelines, about which we spoke. People commit to git, they can commit some kind of incorrectness - we need to keep track of it all. Therefore, we have built such a pipeline. That is, the developer commits ansible scripts in git. TeamSity tracks them and sends them to Ansible. Teamcity is needed here for one reason only: firstly, it has a visual interface (there is a free version of Ansible Tower - AWX, which solves the same problem - ed.) As opposed to Ansible free and, in principle, we have Teamcity as one CI. So in principle, Ansible has a module that git can track itself. But in this case they did it just in the image and likeness. And as soon as he tracked him, he sends all the code to Ansible and Ansible, respectively, runs them on the integration server and changes the configuration. If this process is broken, then we understand what is wrong, why the scripts are not written well.

The second point is that there is a specific infrastructure, here we have the infrastructure deplots separately, the application deplots separately. But there is a specific infrastructure for each application, that is, which needs to be deployed before we launch it. Here, respectively, it is impossible to make it in a different pipeline. You should have this deployed in the same container as the application itself. That is, for example, frameworks are a popular thing when you need to install one framework for a new application, and another for another framework. Here's how with this situation. Either the caches need to be cleaned. For example, Ansible can also climb, clear the cache.

But here we use docker in combination with Ansible. That is, the specific infrastructure we are in docker, non-specific in Ansible. And thus, we sort of share this little delta in docker, everything else, the fundamental - in Ansible.

A very important point is that if you roll the infrastructure through some scripts, through code, then if you still have manual manipulation of the servers, then this is a potential vulnerability. Because suppose you put java on the test server, wrote the ELK role, rolled it. Depla in the test was successful. Deploy in production, but there is no java. And you did not specify java in the script - it fell into production. Therefore, you need to take the rights from all servers from the administrators so that they do not climb there with their hands and make all the changes via git. This whole conveyor we ourselves passed. There is one thing here - no need to tighten the screws too much. That is, it is necessary to introduce such a process gradually. Because it is still undated. In our case, we have left access to all systems at the most important head of administrators in case of unforeseen incidents.

How is the development going? Rollout in staging, production should be without errors. We can break something. If the rollout in the integration environment will constantly fall on errors - it will be bad. This is like debugging applications on a remote machine. When a developer first develops everything on the machine, compiles. If everything compiles, then sends it to the repository. It uses the same approach. Developers use Visual Studio Code with Ansible, Vagrant, Docker, etc. plugins. Developers are testing their infrastructure code on a local vagrant. There rises a clean operating system. The scripts themselves for raising this machine are also located in this repository with the infrastructure we talked about. The developer starts to install an FTP server on it. If something went wrong, it simply deletes it, reloads it, and re-trying to install the necessary software on it using deployment scripts. After debugging deployment scripts, it makes a Merge Request to the main branch. After the Merge Request merge, CI rolls out these changes to the integration server.

Since all the scripts are code, we can write tests. Suppose we installed PostgreSQL. We want to check it works or not. For this we use the module Ansible assert. Compare the installed version of PostgreSQL with the version in the scripts. Thus, we understand that it is installed, it is generally running, it is the version we expected.

We see that the test has passed. So our playbook worked correctly. You can write as many tests as you like. They are idempotent. Idempotency (operation, which, if applied to any value several times - always produces the same value as in a single application). If you write the proper script for installation, configuration, then make sure that your scripts always get the same value if you run them several times.

There is another type of test that does not directly relate to testing infrastructure. But they seem to affect him indirectly. These are end-to-end tests. Our infrastructure and the applications themselves are installed on the same server, which testers are testing. If we have rolled up some kind of incorrect infrastructure, then we simply will not pass complex tests. That is, our application will work somehow incorrectly. In this example, we installed a new version on production — the application is running. Then commit was made to the git and end-to-end tests, which take place at night, to track that here we do not have an ftp file. We analyze this case and see that the problem is in the ftp settings. We fix the scripts in the code, deploy again and everything turns green. Same story with code. Infrastructure code and infrastructure is indirectly tested one way or another. We can then deploy it to production.

When we implemented this approach, CI (Teamcity), which rolled out the changes to the integration server, fell 8 times out of 10. No one paid attention to this, because there was no feedback. For developers, these processes were introduced a long time ago, and messages did not reach the OPS (system administrators). Therefore, we added a Dashboard with assemblies of this project to a large monitor in the most prominent place in the office. On it, various projects are highlighted in green - this means that everything is in order with him. If highlighted in redIt means that everything is bad with him. We see that some tests failed. At the presentation in the left side of the second one from above, we see the result of the infrastructure deployable tasks. Infrastructure deploynye taskki green. This means that all tests passed, there were no defects, they successfully assembled. Alert: Suppose an IT professional has launched a script and has departed. If kommit broke everything. He receives an alert in the Slack channel that such an IT specialist broke our project with such a commit.

Ok, we are now talking about how we develop, how we commit some test environments, how we generally roll it out further to other environments. We use the trunk based approach. Therefore, here the Master branch is the main branch of development. When you commit to the Master, the CI server branch (Teamcity) rolls out the changes to the integration server. If the task in the CI server is green, then we write to testers that we can test the product on the integration server. We form a release candidate. On the test server, this configuration appears. Its testers can test along with the applications themselves. If everything is ok, if the end-to-end tests are passed, we can already roll out the configuration itself and the application to the staging environment. Then we can roll out to production. Due to such multi-level barriers, we achieve that the staging environment is always green.

Let's compare the management of the infrastructure from the code and the configuration of the infrastructure by hands. What kind of economy? This graph shows how we installed PostgreSQL. Infrastructure management from the code turned out 5 times more expensive at an early stage. All scripts must be written, otaladit hands. This will take 1-2 hours. Over time, there is an experience of writing these scripts. Let's compare the installation, configuration of PostgreSQL hands and hours using the deployment script. Since the deployment scripts and PostgreSQL settings have already been written, it takes 4 minutes to staging, production. The more environments, the more machines, then you start to win on labor costs in setting up the infrastructure. And if you have one project and one database, then it’s cheaper for you to do it by hand. That is, it is interesting only when you have some large-scale projects.

We have implemented a git submodule allowing the use of the Ansible role several times. We do not need to write a second time, it is already there. We add git submodule with the Ansible role we add to the project. We write in the inventories of the server, where the role deploit. It takes 30 minutes. In the case of using git submodule, the effort required to write deployment scripts greatly overtook manual operations.

About media identity: here I am not ready to say how many mistakes we had before and how much it became later. But I want to say that, while observing all the rules about which we spoke today, our staging is set up exactly the same as the test. Because if the test falls apart, we destroy the car, try to re-configure it, and only when it becomes green does the whole thing roll into staging. How many mistakes your team makes with your hands - you can think for yourself, calculate, each one has a certain threshold.

The graph shows the results for 6 months. Work - the complexity of a 10-point scale. The first two months, we just wrote these roles very painfully and for a long time. Because it was a new system. When we wrote them, the schedule went down. Somewhere in the middle, we implemented git submodule when we had already written the roles to reuse different projects. This led to a sharp decline in labor costs. If we compare it with the manual adjustment of the project for which this assessment was made, we set up three days by hand, using the infrastructure approach as the code set up for about a month. In perspective, using the approach of infrastructure as a code is more efficient than setting up servers manually.

Findings.
First, we got the documentation, that is, when the manager comes in and asks me: which port does the database listen to, I open the Ansible script in the git repository, say: “Look, look at this and that port”. What are our settings here? All this can be seen in the git repository. It can be audited, shown to managers and so on. This is 100% reliable information. Documentation is becoming obsolete. And in this case, nothing obsolete.
The important point about which we did not speak. About him indirectly say. There are development teams that need to raise RabbitMQ, ELK locally too in order to test various ideas. If they do with their hands, then lifting ELK can take more than an hour. When using the infrastructure approach as a code, the developer raises the virtual machine, presses the button, and ELK is installed on it. If the developer broke ELK, then he can delete, start ELK installation on the virtual machine again.
As we have said, this is all cheaper only when you have either many projects, or many environments, or many machines. If you do not have this, then, accordingly, it is not cheaper, it is more expensive. In our perspective, in our projects it turned out that it becomes cheaper over time. Therefore, there are both pros and cons.
Rapid disaster recovery. If you fell, you need to look for a person who can set up this machine, who knows how to set it up, who remembers how to set it up. In this case, all the settings and deployment scripts are in git. Even if a person quit, moved to another project - everything is in git, everything is in the comments, everything is clear: why he opened such a port, why he put such and such settings and so on. You can easily restore everything.
The number of errors decreased because we had different barriers, local tracking environments, development, plus code review. This is also important, because developers are looking at what they are doing. Thus, they are still learning. The complexity has increased, because this is, accordingly, a new system, these are pipelines, people need to be trained. This is not what they usually used to: they read the article and did it under the article. Here is a little more. Nevertheless, over time, it is quite easily mastered. If you look at the development completely, then it will be about three or four months.
The question is asked through the application, but the question is not heard.
Answer: Roles we use the latest version, that is, the role is allocated in a separate git submodule only when it is unique for absolutely all systems. If any commits occurred on it, then we go to the latest commit. And the whole configuration comes from inventories. That is, the role is just what will be performed. Database name, login, password, etc. comes outside. A role is simply an executable algorithm. All configuration comes from the project itself.
Question: If you have any transitive dependencies between the Ansible roles and how do you pull out when the application is deployed (role A depends on B, B depends on C and when you roll out role A so that it all pulls dependency)? What tools do you have if you have one?
Answer: There are no such dependencies in this paradigm. We have configuration dependencies. That is, we put some system and we know the IP addresses of the servers, and at the same time there is a balancer, which has now become, should drive itself, as it were, in order to balance this tuned machine. This is due to the configs being resolved. But, if you have a dependency on modules, there is nothing here, we have one free, it does not depend on anything, it is self-sufficient. And we don’t put into general roles that which has at least some non-general structure, that is, let's say RabbitMQ can also be in RabbitMQ in Africa, it does not depend on anything. We are keeping some specifics in the docker as we store, the same frameworks.
PS I suggest that all interested in jointly on github translate into the text interesting reports from conferences. You can make a group in github for translation. So far, I translate into text in my github account - there you can also send a Pull request to correct the article.