Analysis of a virtual machine protected application
In this article, we will consider building application protection using various software “tricks” such as resetting the entry point to zero, encrypting the file body and the decryptor covered by the garbage polymorph, hiding the logic of the application algorithm execution in the virtual machine body.
Unfortunately, the article will be quite difficult for a regular application programmer who is not interested in software protection topics, but there is nothing to be done.
For a more or less adequate perception of the article, minimal assembler knowledge (there will be a lot of it) as well as skills in working with the debugger will be required.
But those who hope that some simple steps will be taken here to implement this type of protection will have to be disappointed. The article will consider the already implemented functionality, but ... from the point of view of its hacking and complete reverse of the algorithm.
The main goals that I set for myself are to give a general idea of how such software protection works in general, but the most important thing is how a person who will remove your protection will approach this, because there is an old rule - you cannot implement a competent protection kernel algorithm, imagining methods of analyzing it and hacking.
As a recipient, on the advice of one fairly competent comrade, I chose a little old (but not lost its relevance, due to the quality of performance) keygenme from the notorious Ms-Rem.
Here is the original link where it appeared:http://exelab.ru/f/index.php?action=vthread&forum=1&topic=4732
And then he got here: http://www.crackmes.de/users/ms_rem/keygenme_by_ms_rem/
Where complexity was set for this keygenme 8 out of 10 (* VERY VERY * hard).
Although, to be honest, this is a slightly overestimated mark - I would put in the region of 5-6 points.
Let's start.
For the good, for the full debugging of this keygenme, the most convenient platform will be Windows XP 32 bits, it is generally the most optimal environment, therefore it is constantly deployed on my workstation as a virtual machine.
Under Windows 7 - 32 bits (on which debugging was actually performed during the writing of this article) there will be small difficulties, but they can be solved (this will be mentioned in the fourth chapter of the article).
Serious difficulties will begin on 64-bit OCs, because the keygenme used as the main tool (OllyDebug) during debugging will generate errors even at the boot loader stage. OllyDebug version 2 will not pour in these errors, but there is one more difficulty, there are no necessary plug-ins for it yet (or maybe I was looking badly).
Keygenme itself must be downloaded from this link: http://exelab.ru/f/files/3635_03.05.2006_CRACKLAB.rU.tgz (registration required).
To fully work with the text of the article, if you decide to go through all the steps described in it yourself, you will need a small set of tools.
I won’t describe them in detail here, everything that needs to be done is described in the used_tools.txt file located in the root of the archive with examples for the article: http://rouse.drkb.ru/blog/vm_analize.zip
It’s also necessary to remember the correct a couple of usernames and serial numbers provided by the very first link, namely “Ms-Rem” and “C38FB7A0CF38F73B1159”. This data will greatly help in the process of parsing keygenme.
Once everything is installed - you can start.
To begin with, it is worth deciding what exactly we are dealing with.
We start PEiD and open keygenme.exe in it.
Press the rightmost lower button and select the “Hardcore Scan” scan type in the menu.

The trouble starts right away, firstly the entry point “Entrypoint” is set to zero, which cannot be in the normal executable file, secondly, the scan showed that “UPolyX v0.5 *” is present.
The second one is just not scary - it would be something like “EXECryptor” or “Themida” - some of the commercial protectors, then yes, but here, apparently, some suitable signature was just found.
We press the second lower button on the right and in the dialog that appears, three buttons on the right.

He says that the file is packed and the entropy is already 7.56.
Well, let's say, although this still does not mean anything. Great entropy happens not only in packed, but also in encrypted files.
Close the dialog and click on the button to the right of "Subsystem:"

In addition to the entry point, the code and data bases were killed, the loading base is standard 4,000,000.
Well, okay - we have a file in our hands that was slightly corrected with handles.
Let's try to feel it all in the debugger.
Open OllyDebug, go to the “Options” menu, select “Debugging options” there, and on the “Events” tab set the checkbox “Make first pause at: -> System breakpoint”.
Thus, we will cause the debugger to interrupt when it receives the first debug message before transferring control to the body of the debugged application.
This is done due to the entry point thrown to zero.
We open keygenme.exe itself and immediately break off somewhere inside ntdll.dll

What is the entry point (for the application) is the offset from its load base (hInstance), to which the loader transfers control immediately after the process is initialized.
The download base always contains a PE header, where the _IMAGE_DOS_HEADER structure comes first.
Because keygenme's entry point is zero, which means that control will be transferred directly to its hInstance.
Knowing this, let's see what we have there.
Press “Ctrl + G” and drive in the address of the base “400000”, it should be something like this:

It’s quite a decent code instead of the standard header, but the header should be in place, otherwise the application would not have started, so the changes were made directly to _IMAGE_DOS_HEADER.
We look what exactly has changed:
Field e_magic - you can’t touch it and it should always contain the initials of Mark Zbikowski 'MZ' (0x4D, 0x5A).
Actually, it is not touched, and both of these symbols are interpreted as instructions:
The value of the second e_cblp field is changed to 0x45, 0x52, which as a result cancels the changes made by the first two instructions, restoring the correct state of the stack.
The remaining 4 fields are used to implement the MOV + JMP commands.
Here in this picture it is shown more clearly.

The whole point of such manipulations with _IMAGE_DOS_HEADER and a reset entry point is the transfer of control somewhere inside the application body at 4053B6.
Those. in principle, we can open keygenme.exe right now and specify 53B6 as the entry point (ignoring the changes in the file header), but is this the correct entry point?
We go to the transition address "Ctrl + G" 4056B6 and there we see this:

Generally solid garbage. Whatever the line, then the garbage instruction.
For example, all conditional branch operators (JG / JPE / JCXZ / JE) are complete garbage, because it doesn’t matter whether the condition is fulfilled or not, the transition will always be on the next line (pay attention to the jump addresses).
Instructions LEA, MOV, XCNG work with the same register without making any changes to its state - garbage.
Instructions for working with the matsoprocessor (FCLEX / FFREE) throw exceptions (which are not there, because work with the matsoprocessor has not yet been done) free the registers (which are actually not busy) - garbage.
Scroll through the code to the end to see where this garbage mess ends.
Just scroll down until we get to the code consisting of only zeros:

Yeah, but it looks like we need the address 401000, which is the jump to, which theoretically could be the original entry point.
Let's see what's there:

And there we have a code that obviously should not be in a Win32 application, which is clearly indicated by the IN and OUT instructions that will throw an exception when they are executed.
So it turns out that the code on the original entry point (OEP - Original Entry Point) is encrypted and the code in procedure 53B6 must decrypt it before performing the final jump.
But!!!
But in procedure 53B6, as previously shown, trash.
In fact, there should be not only garbage. Apparently we are dealing with the so-called garbage polymorphic, and in its simplest implementation.
The task of the polymorphic engine is to convert the original code by replacing the original instructions with their analogues (or groups of analogues). To make it difficult to analyze the resulting code, garbage instruction blocks are usually added.
There are no blocks here, just garbage instructions are generated, plus in the end, even if there was a replacement of instructions with analogues, I noticed this in only one case. It is quite possible that just a garbage generator was used here, cramming it abundantly between useful instructions, how to know ...
However, a task appeared - among all this garbage from address 4053B6 to 406839 (5251 bytes - however) find useful instructions that decrypt the application body .
There are two ways to do this.
The first is to look through the entire code with your eyes and try to find such instructions. I even tried and spent about 7 minutes for the sake of interest, as a result I even found two such instructions that are not garbage. True, as it turned out later, I missed one between them, and even after the second one I found further, I got a little sick of it - too tedious task.
Therefore, let's go the second way, and write a small script that will help clean up all the garbage and leave only the payload.
The script itself is located in the archive, which goes with the article along the following path: ". \ Scripts \ fill_trash_by_nop.txt".
To run it, the OllyScript plugin must be installed.
The script runs like this: you need to restart keygenme in the debugger and wait for the first BP to work inside NTDLL, then select “ODbgScript-> Run Script ...” in the “Plugins” menu, select the file with the script in the dialog (the path specified above) and run his.
As soon as the script starts its work, you can go make some tea for yourself, you will have about five minutes of free time.
Our logic is simple:
Because Since garbage instructions do not change the values of the registers (with the exception of EIP), the garbage instruction is detected by checking the status of the registers before and after its execution, if the registers have changed, the instruction does something useful, otherwise the instruction is considered garbage and NOP is placed instead.
When the script finishes its work and displays a message, you can view the results of its work (do not stop the debugger itself - it is still needed).

All garbage will be replaced by NOP and we will only have the following instructions on hand (you need to go from 4053B6 to 406839 and write everything that is not NOP in a notebook):
The first two lines will be a bit of garbage (sleep is called with zero delay).
Well, more precisely, how-it’s not really garbage, this line forces the bootloader to load kernel32.dll into the address space of the process, at the start of the process, in parallel with the already loaded ntdll.dll, because this library is declared in the keygenme import table (just as a single sleep function).
Next, the decryptor code itself will go:
and directly switching to OEP on which the debugger has now stopped.
Roughly speaking, if you look at the instructions of the decryptor, the keygenme body is decrypted with this simple algorithm:
Now, in order not to wait for the decryption of the file each time, you need to dump the result (the OllyDump plugin must be installed).
To do this, go to OEP ("Ctrl + G" 401000) and put the breakpoint there, and then continue the program.
As soon as the debugger stops at the installed BP, go to the “Plugins” menu, select “OllyDump-> Dump debugged process” there, this dialog will open:

Focusing on the “Virtual Offset” column, set the code base equal to 1000, and the database equal to 7000, uncheck “Rebuil import” and press the “Dump” button.
In the dialog that appears, specify the new name "keygen_unpacked.exe".
Actually everything - so we removed the first envelope.
A little trick:
In general, it was much easier to dump, without considering the source code of the decryptor and other things, but since I decided to consider everything thoroughly, so I also had to dwell on it.
The second unpacking option is as follows.
1. Run the debugger and wait for the first BP to fire inside NTDLL.
2. Go to the tab of the memory card "Alt + M" and at the address 401000 we put MBP on the record:

3. Run the program for execution as soon as the recording operations are interrupted (this will be the STOS DWORD instruction), again go to the memory card and remove the MBP, after which we go to OEP (401000) and there we put the usual breakpoint.
4. Well, as soon as we break on it, you need to follow the steps already described to dump the process.
By the way, if you want, you can check the resulting file under PEiD, the entropy magically became 6.95 - and just simply decrypted the data block.
Now we will work with the already unpacked file.
Since the entry point in it is set correctly, in order not to make unnecessary gestures, you need to configure Olly to make the first stop no longer in NTDLL, but directly at the entry point.
Open OllyDebug, go to the “Options” menu, select “Debugging options” there, and on the “Events” tab set the checkbox “Make first pause at: -> Entry point of main module”.
Open keygenme_unpacked.exe and look at what the previously encrypted code turned into:

We immediately see the first "nuisance", the first call to CALL goes inside itself (the address 401004 is called, while the next instruction starts only with 4010005).
I already talked about such hops earlier in this article: “Learning the debugger, part two”
The essence of this trick is to confuse the disassembler and make it display the wrong code that will actually be executed. There is nothing wrong with such a “trick”, just press F7 to execute this CALL and immediately see the correct code:

You can now once again dump the process + remove the POP EBX instruction to turn off this “focus”, but since it will not interfere - we will leave it as is and begin to analyze.
First comes a block of five instructions, reading some data from the PEB (Process Environment Block), whose address is always located in FS: [$ 30].
If you open the PEB structure and see what the offsets shown in the code mean, we get about the following:
Thus, these five instructions look for hInstance "kernel32.dll", which will be located at this address, although under Vista and higher, hInstance "kernelbase.dll" will be located at this address and one unpleasant error will be associated with this.
The LEA ESI instruction places a pointer in ESI to a small array of Ansi strings located at 004012DE. These are three lines separated by zeros: “LoadLibraryA”, “ExitProcess” and “VirtualAlloc”.
By the way, I completely forgot to mention this earlier, if you look at the keygenme.exe import table, you will see that it imports one single kernel32.sleep function, the rest are missing. So the addresses of the rest necessary for work, the application must find on its own.
The following LEA EDI instruction places a pointer into the EDI buffer into which addresses of the found functions will be placed (this will be a virtual import table for kernel32), after which the procedure is called at 401198.
In fact, both LEA EDI / ESI calls are garbage. because these registers will be overwritten when the procedure is called at 401198, but they will be used in it in exactly the same way as I described above (EDI, more precisely EBP + 305, in the end it will contain the addresses of functions).
In short, the task of procedure 401198 is to prepare the ESI register, which contains a pointer to the name of the desired function, as well as the EDI register, which contains a pointer to the library export table, whose hInstance we received by reading data from PEB,
then call the function at 4011E2, which will search by name.

And here we are waiting for the second trouble, much more serious than the CALL trick at the very beginning.
The very first will be searched for "LoadLibraryA", which "kernelbase.dll" does not export.
This means that under Windows Vista and above, this keygenme will not work and will crash at startup.
You can check, the exception will be raised here:
To get around this is quite simple, it is enough after starting keygenme to put BP on the instruction:
those. immediately after receiving the library load address, and replace the value in the EAX register with hInstance of the “kernel32.dll” library (the correct address can be seen in the Alt + M process memory card).
After such manipulations, keygenme will start normally.
In order not to do this every time you start the application, it will be enough to run the script from the ". \ Scripts \ run_at_vista.txt" folder, which will automatically replace the EAX value with the correct one every time you start and run the program without errors.
Now it's time to see how the login and serial number are read into the application’s memory and what modifications are made to them.
Usually, reading data from EDIT occurs using the GetWindowsText or GetDlgItemText functions, but since the second function eventually calls the first one anyway, then we will set the breakpoint on “GetWindowsText”.
To do this, after keygenme has started (and the user32.dll library has loaded) and its dialog box appears, go to the debugger and look for all available functions in all modules:

In the dialog that appears, look for the name of the exported function “GetWindowsTextA”, and select “Follow in Disassembler” from the menu:

After that, put BP, go into the dialogue with keygenme and drive into the appropriate fields the username “Ms-Rem” and the serial number “C38FB7A0CF38F73B1159”.

Click the “Check” button and ... stop at the breakdown inside user32 just at the beginning of the “GetWindowsTextA” function.
Now you need to return to the place of her call.
Press:
1. Ctrl + Shift + F9 - jumping to the end of the GetWindowsTextA function
2. F8 - go up to the GetDlgItemText function
3. Ctrl + Shift + F9 - jumping to the end of the GetDlgItemText function
4. F8 - go up to place of call

The blue frame contains the just made call “GetDlgItemText”, with the following parameters:
hDlg = ESI
nIDDlgItem = 65
lpString = EAX
nMaxCount = $ 10
We read this login value into the buffer pointed to by the EAX register of 16 bytes, and in the red frame The call to read the serial number to the buffer is highlighted, which will be indicated by EDI (EBP + 414E) of 32 bytes in size.
The most interesting part starts right after reading the serial number.
An interesting loop of 10 iterations follows, with the ESI register pointing to the buffer with the serial number just read, and the EDI register pointing to the buffer where the result is placed:
Those. over the serial number in function 40117B some kind of conversions are made, the result of which is placed in EDI.
This function is as follows:

This is something like converting two characters from a string HEX representation into bytes.
If it's rude then this is an analogue of Result: = StrToInt ('$' + Value);
Take for example the original known serial number: “C38FB7A0CF38F73B1159”
After 10 iterations, it will be converted into an array with the following contents:
But since the function does not check for boundaries beyond which HEX values in string format should not go, that is, a very large range of valid values that, after such a cast, will give the same number.
For example, that “C3” that “s1” as a result of such a conversion will be equal to 195 (or $ C3). Therefore, this, too, will be quite a valid serial number: " s1 8FB7A0CF38F73B1159".
Thus, we conclude: the entered login is read as is, and the serial number after reading is converted into a byte representation, moreover, because iterations are only 10, then the length of the serial number should not exceed 20 HEX characters (the rest will not be taken into account).
Basically, all this information that we need is now the time has come to look at the keygenme source code from a slightly different angle.
We start IDA Pro and open keygenme_unpacked.exe in it, right after opening we go to the tab “Functions”.
Only 8 pieces:
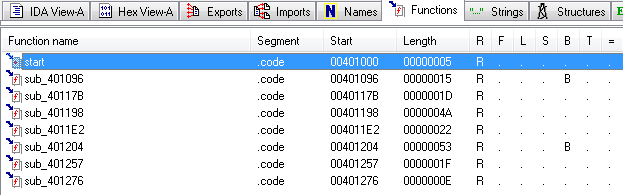
Moreover, almost everything we know:
401000 is OEP, 401096 is not interesting
- and this seems to be the initial entry point, which was before all the encryption and creation of virtual IATs were hung there, but, by the way, we no longer need it.

40117B is HexToInt, we saw ...
401198 - filling in the virtual IAT, we saw ...
4011E2 - finding the address of the function by name, we saw ...
sub_401204 - something interesting (judging by the graph), we’ll probably start with it, by the way, it calls the two remaining functions sub_401257 and sub_401276.
And the calls to the read functions from the EDITs at addresses 004010F5 and 00401107, as well as the loop at address 00401111, were not recognized by IDA Pro as procedures because of garbage instructions in front of them (and not so important).
So, we look at the function graph sub_401204:

Have you ever seen what the VM graph looks like in the IDA?
If not, then look - this is the body of the virtual machine, and quite simple.
What is a virtual machine?
Roughly ... a conventional processor executes a set of instructions known to it (a machine code that can be disassembled).
A virtual machine is essentially also a processor, it only executes its own set of instructions that are generated and placed somewhere in the accessible memory area in the form of the so-called P-Code.
It is not at all necessary that these instructions coincide with those that the real processor can execute (more precisely, on the contrary - in most cases they just will not match).
In the process of protection, commercial protectors disassemble the protected blocks of code, generate a virtual machine for each of them with a unique set of logic and a set of instructions, translate the disassembled code into a picode that a specific virtual machine can execute and save the result as a buffer somewhere in the body applications. Each VM, upon gaining control during the execution of a program, sequentially reads out pikode instructions intended only for it and executes them.
Thus, the logic of the protected algorithm, which he could parse under the debugger, is hidden from the cracker. After such modifications, it will be necessary to first analyze each VM, and only after its complete analysis, pull out the algorithm from the picode it executes, converting it back into a machine code that is understandable to the ordinary processor. That work is still ...
In the picture above we see just one of the VM implementations, which can execute only 8 instructions known to it.
Let's take a closer look:

It all starts with the initialization of the EBX register, which indicates the beginning of the buffer with a picode for the virtual machine, as well as the EAX register, which is the cursor (index of the executable instruction).
VM operation begins with the loc_40120D procedure.
Its task is to first obtain the opcode of the executed instruction by calling the sub_401276 function, the code of which is given in the hint.
Judging by this code, it can be understood that the pico itself is also encrypted, and immediately after reading each byte, it decrypts with approximately this algorithm:
After receiving the opcode, it is checked, if it is zero, then control is transferred here:

Where the unit of some variable is simply added (let's call it arg_4 as it is)
And in the end, the control goes to the finalizing block, which starts the execution of the next opcode, incrementing the EAX register.

And in it we can find out the overall size of the picocode, it is equal to $ 3DA2 (15778 bytes).
So, let’s take a look at all the instructions in order:
0. (loc_4012CA): increases the value of the variable arg_4
1. (loc_4012C5): decreases the value of the variable arg_4
2. (loc_4012BE): increases the value pointed to by arg_4
3. ( loc_4012B7): decreases the value pointed to by arg_4
4. (loc_4012A8): puts the value pointed to by arg_4 into the memory pointed to by arg_8, then increases the value of the variable arg_8
5 (loc_401299) :. puts the value pointed to by arg_C into the memory pointed to by arg_4, and then increases the value of the variable arg_C
6. (loc_401284): checks the value pointed to by arg_4, and if it is zero, starts the procedure sub_401257, passing the value 1 to EDX
7. (0040123E): checks the value pointed to by arg_4, and if it is not equal to zero, it starts the procedure “sub_401257” passing the value -1 to EDX
And in the procedure “sub_401257” the following happens, EDX is the direction of scanning the pico code, if the value is positive, it looks for opcode number 7, which corresponds to opcode number 6 taking into account nesting (i.e. e. if 066770 goes then when called from the first opcode 6, the EAX cursor will be set to zero, and when called from the second opcode 6, EAX will point to the second seven).
And if EDX = -1, then the scan goes in the opposite direction as well taking into account nesting.
That's actually the whole VM.
Doesn’t resemble anything?
Yeah - it's actually Brainfuck as it is.
http://ru.wikipedia.org/wiki/Brainfuck
i.e. it turns out that inside the keygenme there is an encrypted P-Code, which must be executed on the Brainfuck interpreter, which actually acts as a virtual machine (well, why not?)
By the way, if you pay attention to the description of BF on wikipedia and the implementation of handlers in given version of the interpreter, you will see that the fourth and fifth opcodes (reading and writing) are mixed up.
Well, if so, all that is left for us is to remove the picode from the keygenme body and we don’t need keygenme anymore, then we ourselves.
In order to determine the location of the buffer with a picode, put BP at the beginning of the VM and look at the address that initializes EBX.
We start OllyDebug and in it we put BP at the address 401208.

After BP is triggered, we look at the EBX value, this is address 401380.
We go to it in the dump window and look at the HEX values, the first 8 bytes are equal to “CE44 4E53101708DD”.
Now open keygenme_unpacked.exe in any HEX editor and look for these 8 bytes.
The size of the VM, as we found out earlier, is 15778 bytes.
We copy 15778 bytes starting from those found in the file “vm.mem”.
Well, now we have the P-Code of a virtual machine on hand, with which we have a long and hard work to do, and we no longer need keygenme together with OllyDebug and IDA Pro, they worked out their own.
PS: the already copied file "vm.mem" is available in the archive with examples for the article and is located in the folder ". \ Data \ vm.mem".
By the way.
In the process of proofreading the article, they pointed out to me at such a moment: in a real combat application, the number of functions will be several orders of magnitude more, but how in this case to determine the body of a virtual machine?
In this situation, it will be enough to set BP to read external data (login and serial number), from which it will be quite easy to track the transition to one of the virtual machine’s handlers, or perform the same actions with the output buffer (because something the VM should do and have interaction with the environment).
But all this, of course, depends on the specific implementation of the VM, and this approach is not always applicable.
First, decode the resulting “vm.mem” into the normal representation with something like this:
The result is a “vm.brainfuck” file containing BF code in the form in which it is usually written, and here the instructions are already taken into account. and "," are confused.
This file, in principle, can already be fed to any BF interpreter, and if you slip the correct buffer with login and serial number, it will even execute.
By the way, about the buffer with login and serial number - I completely forgot to mention it. It goes to the input of the virtual machine in the form of a block of 20 bytes, where the first 10 bytes are filled with login characters (if the login is less than 10 bytes, the remaining bytes are zero), and immediately after them are 10 bytes of the serial number converted from a string HEX representation to byte.
Those. for the known “Ms-Rem” and “C38FB7A0CF38F73B1159” the buffer will look like this:
('M', 's', '-', 'R', 'e', 'm', 0, 0, 0, 0, $ C3, $ 8F, $ B7, $ A0, $ CF, $ 38, $ F7, $ 3B, $ 11, $ 59)
This could be seen when starting the virtual machine under the debugger, looking at the data located at the address pointed to by the variable arg_C.
For the BF interpreter to work, a buffer of 300,000 bytes is required (under the conditions described in the wiki), but in fact, this version of the code uses only 221 bytes from 300,000.
Actually, we write the code.
It remains only to run all this:
We start and look at the result:

Well, everything seems to be done right and works as it should.
(The source code of the interpreter in the archive with examples '. \ Tools \ bf_execute \')
Thus - the second envelope is removed.
But now what do we do with all this?
It will not work to analyze the picocode forehead - there are no tools, the only thing that can be seen is the number of cells in which the login and password are entered and from which the result is derived.
We put BP on the read and write procedures and see what
happens with us ... Nothing good, at the moment when the login and serial number data are read, each byte is always read in cell number six of the working buffer.
The same thing happens with the output of data from the VM, the next character is also taken from cell number six.
The only thing that can at least somehow clarify the picture is a dump of the working buffer at the time of data output, look at it:

Here it is at least visible that the username and password are in the working buffer of VM, as well as just below it are two already prepared lines with “good message” and “bad”.
And in the sixth cell of the working buffer (the second from the top right) the prepared character “C” from the displayed message “Congratulations !!! It is valid serial! ”
This is such an ambush.
What is a decompiler?
In fact, this is a utility that converts a set of machine codes for a processor into a set of assembly instructions that a programmer understands. For each processor, it will be its own assembler (32/64 / ARM, etc.). Well, a virtual machine (as mentioned earlier) is the same processor with its own set of instructions, expressed as a pico code.
Now the task is to write a picode decompiler in 32-bit assembler so that you can somehow work with the result, since in this case we already have a tool for analysis - it's a debugger.
Moreover, the task is essentially simple, no prefixes need to be taken into account, ModRM / SIB parsing is only eight instructions, but first you need to figure out how it will look.
Disassembling forehead will not be a good idea, you need to minimize the blocks of repeated instructions for the BF code.
For example, we have a brainfuck script of this kind: ">>> +++ << ----"
Here we go to the fourth cell, increase its value by three, go to the second and decrease its value by four.
If you disassemble in the forehead, you get something slurred:
It is much easier to collapse repeating sets of instructions:
Input and output are assembled quite simply.
We only need to know where to read and where to get it. And you need to consider that every time you read or output data, you need to shift the position so as not to read what has already been read or not to write over what is already written.
Only the option with brackets remains.
The brackets in BF execute an analog of the while loop, i.e. until the cell is zero, the loop body is executed.
The opening bracket "[" is responsible for entering the body of the loop, for the transition to the next iteration, closing the "]".
Those. roughly in assembler we need to provide two conditional transitions, one to enter the loop, one to go to the next iteration.
At least one more thing is needed before the heap, this is the address where you must go if the condition for entering the loop is not fulfilled, or if the condition for moving to the next iteration of the loop is not fulfilled.
The next step is to figure out how to disassemble the loops, taking into account the three jumps described above.
For example, there is such a picode:

More convenient for disassembling (at least for me) will be the removal of the loop body outside the main code, something like this:

If you approach in this way, then you only need to know from the disassembler the beginning and end of each procedure and decompile the body of each in a loop, inserting jumps into internal loops in the right places.
PS: True, now I look at this picture and understand that it probably might not have been worth it, because an extra jump appeared, but ... too lazy to rewrite.
Well, okay, now about the working buffer and input / output buffers: the ESI register will be used as a pointer to the working buffer, it will also be the cursor, i.e. on operations ">" or "<" this register will increase or decrease.
A pointer to the buffer with login and serial number will store the EBX register, and the EDI register will be responsible for the output buffer.
We are writing a code.
The decompiler will need a buffer with a picode and a small list in which the beginning and end of each While loop will be stored.
Next, several utilitarian procedures are needed.
It remains in the loop to cause decompilation of each While block:
And write the startup code for all of this:
(The source code of the decompiler in the archive with examples '. \ Tools \ bf_decompiler \')
Now you need to check its operation on something.
Take for example the Hello World from a wiki with this content:
And let's see what this decompiles into:
It looks like it. I agree, it is possible to optimize, but not the task.
We check how it will work and write a test:
We look at the result:

Well, not bad.
It turned out what was intended, now we decompile the body of the VM itself.
The output was 8153 lines of pure assembler :)
(the result of decompiling the VM in the archive with examples '. \ Data \ vm.inc')
But ... all the same, more than 8 thousand lines, they cannot be analyzed from a snap.
Need to write additional tools.
In the demo application settings, you need to enable the generation of the MAP file (in Detailed mode), it will be useful to us in the next chapter.
In order to understand what exactly is happening in the decompiled code, it is necessary to build an execution path. Moreover, there will be enough information about which blocks are being executed and where the transition is going from.
The essence of the route is to build a directed graph, analyzing which you can stop the logical branches into vector blocks (roughly, like a block diagram).
To do this, you need a debugger: http://habrahabr.ru/post/178159/
In the process of constructing a trace, the debugger will step by step follow the recipient code, interrupting at the addresses that we can lead to the line number in the source code that we generated earlier.
To cast the address to the line number in the asm listing, you need a small module that will parse the MAP file and return this information.
You will also need one more module, which, by the line number in the asm listing, will return the name of the subprocedure that stopped.
I will not give the source code of the last two modules - they are very simple, in any case the code can be seen in the archive with examples for the article along the following path: '. \ Tools \ tracer \'.
You will also need a class that will store the data on the removed track.
Roughly, his whole task is to store an array of records like this:
and provide methods of working with him.
Also very simple, you can see the code in the archive along the path: '. \ Tools \ common \ trace_data.pas'
The execution track will be removed in 4 passes in 4 different modes.
1. A full track of program execution.
2. Partial trace, from one iteration of reading a buffer with login and serial number.
3. A partial trace from one iteration of the output of the result.
4. Detection of procedures in which cells are recorded with login and password.
A little later, the tracer will have to be added, adding a fifth mode to it to completely remove the trace, but removed from the demo example, in which the serial number will be thrown into a sequence of zeros (in the source code this mode will be called ttWrongSN).
But more about that later, and now ...
The implementation of the tracer is quite commonplace:
In short, in full dump mode (ttFull), the second HBP will mean the completion of the tracing process, the ttIn, ttOut modes will stop when the second HBP fires (one I / O pass), but ttCheckLoginBuff will perform tracing using MBP until the entire VM cycle will be executed.
The first monitors the branching of transitions, and the second simply collects the names of the procedures from which the buffer was accessed, in which the login and serial number are located.
As a result of the tracer’s work, we will have 4 files on the basis of which we can easily analyze all the work of the VM, but ...
But for this it is necessary to somehow display the received data in the form in which you can work with them ...
IDA Pro is an excellent tool, the graphs given to them greatly help in the process of analyzing the source code, but ... but it is not universal.
In particular, it is not very convenient to work with the graph of decompiled VM code built by IDA in this case.
That is why I went for the removal of the route with my own hands (described in the last chapter) and writing a tool that allows us to visualize it.
The essence of the tool is as follows:
1. collapse the software execution trace into the visualized graph
2. display the logical execution blocks in the graph
3. as a result, show block addresses interesting for code analysis.
The very first stage is the conversion of data from the tracer into a directional graph.
It is built quite simply - we take the current block and build outgoing transitions from it recursively. The main thing is to forget about while loops, where the transition at the end of the procedure to its beginning will be directed to the already added element.
Therefore, when constructing the graph, it is necessary for each element to add a custom property in which the node of the graph will be stored, on which the link should be exposed during the first call.
Analyzing the BF code, we can draw the following conclusions:
1. In each of the while loops, there can be only 2 inputs (from the external code block and the transition from the end of the loop).
2. The end of each while loop has only 2 outputs (if the cycle is completed, go to the next level in the code, otherwise return to the beginning of the cycle).
3. From the body of the while block can be a plurality of outputs, provided that there are ifthen blocks in its body (but this is not our case).
Code convolution means the following:
1. If the procedure has one input and one output (based on the results of the trace), then it is added to the current convolution block.
2. The beginning of each convolution block will be any procedure that has two inputs (while loop).
3. The end of the convolution block will be a transition to the already added code (end while) or any other code block that has two outputs according to the results of the trace (which implies the same end of the loop, based on the previous paragraph 3).
The result of processing the path of the decompiled code (in which there are no complicated cases in the form of multiple exits from while) will be this picture:

It displays the program execution track, with the execution blocks collapsed.
Do not pay attention to the fact that everything is so beautifully arranged with vertical columns - I did not write an algorithm for such a arrangement and scattered everything in pens (because it is much faster than writing the same visualization engine as IDA.
I will not give the source code of this utility , you can see it in the archive ". \ tools \ trace_viewer \".
Its main task is to give a starting point from which you can start when analyzing the VM code.
And here are two pictures that show part of the logic of work.
This happens when reading the login and serial number:

But these procedures are performed when the result is displayed:

Pay attention to the execution of procedures in the center of the circuit; they are a hardware and do not participate in the work of the logic of the algorithm hidden in the VM.
I’ll make a reservation right away - this conclusion was already made in the process of researching the code.
Initially, having received these two pictures in my hands, I was a little puzzled and suggested that inside could be hidden another mini-VM (green vertical block from the bottom left), which scatters logic based on my own instructions, but ... the assumption was incorrect.
And so, judging by the pictures, we have on hand:
1. The upper left block of the circuit - reading data.
2. Lower right - the conclusion of the result.
3. The central branch is some kind of hardware (as a result, you don’t even have to analyze it).
All that is not highlighted in green is the third envelope (logic hidden under the VM).
For those who will study the source code of this viewer, I apologize in advance - the tool code is very crude and was written literally on my knee in two evenings, so the utility does not have great functionality. It can only display the graph itself, provides a mechanism for its modification (read - you can move blocks as it will be more convenient).
ZOOM mode has not been added, for this there is a separate button that generates a general preview (from which these screenshots were taken).
But the role of a graph analysis tool is not bad.
In the archive with the article there is an already arranged graph ('. \ Data \ current.graph') which was obtained from the trace taken in the previous chapter ('. \ Data \ full.trace').
However ... to our sheep.
The tool for analyzing decompiled VM code is ready, let's proceed directly to its analysis ...
Starting to analyze VM, I already had some idea what I would have to work with.
Relying on the memory card with which the VM works (shown in Chapter 7), I knew the offsets on which the “correct” and “not correct” lines are located with the results, as well as the offset, on which the buffer with login and serial number is located.
Knowing how the BF interpreter works, I even figured out an approximate algorithm for working with data, taking into account the fact that certain operations should be performed on the login and SN.
For example, if you want to add two fields Z and X, then Brainfuck does not have an addition operation, for this it will be necessary to write a while loop in which the value of cell X will be iteratively decremented and the value of cell Y will be incremented.
Thus, cell Y will contain the sum of both cells, and cell X will be zeroed.
But when outputting data, as was shown above, one can observe that the buffer with the login and serial number is located where it should be and not one of its fields has been changed. So the VM takes some other approach to reading data.
A strange nuance, which I immediately noticed - that the login, that the serial number, that the "correct" and "not correct" lines in the memory card are not in the form as they are, but each byte is separated from the next by zero. It seems that we are working with Unicode, although in reality we are working with ANSI strings.
These two points were not clear to me.
However, starting with something is still necessary, and I decided to start the analysis of the algorithm from its end, assuming that the decision on the conclusion of the result is made with this block of procedures (where the result is displayed):

Moreover, the graph shows this block as a single function with one entry point and one output.
(By the way, the assumption that a decision is made in this block turned out to be incorrect in the end).
For debugging, I used the CPU-View mode directly from Delphi itself (this turned out to be enough for the eyes).
The debugged application was “decompiled_vm_text.exe” from which the execution track was removed.
Three variables were added to the Watch List as auxiliary hints:
1. The current value of the working buffer cursor (ESI register), which was calculated by the difference from the address of the beginning of the working buffer (pWorkBuff) and the current value of the register. (esi- $ 4E5008)
2. The value of the current cell pWorkBuff (pbyte (esi) ^)
3. It is the same only in HEX mode.
4. The dump window was configured to start the working VM buffer ($ 4E5008).
PS: your working buffer address may be different, so you should calculate the number 4E5008 in advance when starting debugging by looking at this value in the pWorkBuff variable.
Thus, the configured debugger, stopped at the beginning of the procedure "@ vm_code_39D7", looked like this:

Actually with this procedure and proceed.
If you look at the picture of the graph, this is the very first procedure in a collapsed execution block that calls itself (while the loop).
At the time of calling this procedure, the cursor of the working buffer is set to cell No. 27 (in the picture with the memory card highlighted in red), which contains a certain number (40 or $ 28). This cell is located just in front of the buffer with the login and serial number (located on offset 28, in which the first login symbol is stored - “M”).
Remember the number of this cell - it is one of the central elements of the VM logic.
Let's see the source code of a collapsed block:
Here I built the execution blocks in the order of their execution (not in the form in which they go in the source code), so that it is easier to analyze the logic from the work.
So what is going on here?
This algorithm initializes zeros (which separate each element of the login / serial number, as well as the “bad” and “good” lines) by units.
If you stop at the finalization of the cycle and look at the result, you can see this picture:

Cell No. 27 will be reset to zero, but as a result, you can see that the buffer will be initialized with units ending just before the first VM output “good line” character, namely the “C” character.
Notice how interestingly the transitions to the beginning and end of the data being modified were performed (procedures @ vm_code_39D8 and @ vm_code_39DD). As the detection of end blocks, a reconciliation of the value of the current cell with zero is used, the leftmost zero will indicate the position of cell No. 27 (with a shift), and the rightmost zero will mean a cell not yet initialized by one.
Thus, the essence of this block is reduced to constructing the index (in the form of units) to the cell with which the next while loop will start working, starting with the @ vm_code_39EB procedure.
He will start his work with the cell, which is indicated by the last unit of the index built earlier, namely with cell number 108, where the symbol “C” is located (highlighted in blue), which the VM should now output to an external buffer.
Before calling this procedure, VM managed to perform some preparatory actions, one of which was the initialization of cell No. 27 with a unit, i.e. the leftmost cell to which the algorithm for searching the left end of the index from that moment will go will be cell No. 26.
So:
The logic of the second cycle is as follows: it transfers the value of cell number 108 to cells number 26 and number 6 (note that this is the sixth cell from which the symbol that I pointed out in chapter seven is taken).
And in fact, the very logic of working with data is already beginning to emerge (when reading the value, the value is duplicated at two addresses).
The memory card starts to look like this:

The green rectangles indicate the places with which the changes occurred, the cell No. 108 from which the value was taken is highlighted in red.
The next while loop in the graph begins with the procedure "@ vm_code_3A2A".
He will start his work from cell number 26, which stores a copy of the number previously placed in cell number 108.
The code is as follows:
The task of this code is to move the value of the cells of cell number 26 back to cell number 108, thus restoring the original value of the cell with which the algorithm began its work.
Let's look at the memory card after the algorithm works:

And the final step in this slightly confusing logic of working with cells will be the final located in the procedure "@ vm_code_3A41"
It is quite simple:
Her whole task is to start working with the very last cell equal to one (by means of which the index is built) and remove all the units of the index.
The result of her work will be such a map:

The green indicates the index fields that the last procedure removed, and the red indicates the result of all four collapsed blocks.
Confused?
Nothing strange, but if you look closely at the latest picture, you can understand that all this tricked-out logic of four stages essentially performs one simple operation.
And this operation is the assignment of the value of cell “A” to cell “B”.
Moreover, the algorithm is flexible enough and thus allows you to read the value of any login / serial number symbol or “good / bad” lines, for this it is enough to initialize cell No. 27 with the symbol number and perform all four of the above steps.
A beautiful approach - you can’t say anything, the logic of working with cells is quite solidly smeared, though there is a small nuance.
Having understood how the cell value is obtained and having the execution graph on hand, it will take an hour and a half to analyze the entire logic of the work from this moment on.
The rest of the procedures from the top image with a graph does not make sense, there is hidden some kind of internal hardware needed for the VM to work, there are frankly garbage pieces of code (for example, in a cycle, changing the value of two / three cells in places and eventually returning everything to its original state) .
Thus, it turned out that the cell value is obtained by performing three cycles, which can be clearly seen on the graph and the final block of finalization, which removes the array of indices immediately after the end of the third cycle.
Here in this picture, I immediately highlighted them with red rectangles and repelled from this image throughout the analysis of VM logic:

Two blue rectangles also highlight the reading cycles of cell values, but since the values of the characters Login [0] and Login [1] are read in them (I learned this by analyzing all the cycles of the algorithm), then the index array of units is not built in these two cases, in the first cycle the value is read into cells No. 26 and No. 6, and in the second, the value from cell No. 26 is returned back.
The picture is not very clearly visible (zoom affects), so that it is more clear, here is the second option, which shows the principle by which I circled the blocks with rectangles:

To check my assumption, I checked myself and displayed on the graph the blocks in which the login and serial number fields change (the button "Show access to the buffer with login and SN"). Using this button, the viewer will load the list of such procedures created earlier by the tracer in ttCheckLoginBuff mode and display this picture:

Everything as expected in the previous image, the only block from the top left (circled by a blue rectangle) is knocked out of the logic, this is a section of code that reads the login and serial number values from an external buffer, so there is nothing surprising in it that these fields change.
Here I concluded that, apparently, each of the vertical blocks is one of the stages of checking the serial number (the assumption also turned out to be true).
The next step was interesting to me, and where is the decision on the correctness of the serial number made, for this I reassembled the decompiled_vm_text.exe example in which I changed the value of the serial number to zeros, and again took the trace in ttWrongSN mode.
After all these steps, I looked at the differences of the route (the button "Show differences of the route with the wrong SN") as a result I saw the following:

You could say bingo.
At the first operation (right vertical block), an exit occurred, and not all procedures were performed (the block marked in red). So it is in him that the decision is made according to the results of the first operation on the buffer with login and serial number.
More precisely, there will be several such blocks in the end, for each operation its own, however, you will not have to disassemble their logic of operation, because the meaning of all operations will be quite transparent.
The next step I put the breaks in the debugger at the beginning of each vertical block (which I previously marked with rectangles), in order to understand in what order the operations are performed.
The following list turned out:
It remains, focusing on the graph, just to go through all the selected places (skipping the already known logic elements in which the login / SN symbol is taken) and analyze what operations are performed on these symbols.
I will not give ranges of procedures in which the index is created, the value is read, the value is returned and the index is removed. For simplicity, I will show only the name of the procedure of the first cycle (in which the construction of the index array from units).
Let's
start the analysis of the logic: 1. vm_code_17AB
1.1 vm_code_1815 - read the value of SN [0] in cell number 6
1.2 vm_code_17AB_1880 add to cell number 6 number 12
1.3 vm_code_1903 - read the value of SN [4] in cell number 7
As a result, in both cells (6, 7) we get the same number, so we conclude that the first mathematical operation performs the following check: SN [4] = SN [0] + 12
2. vm_code_1A63
2.1 vm_code_1AD4 - read the value SN [0] in cell number 6
2.2 vm_code_1B58 this value is transferred to cell number 7
2.3 vm_code_1BC8 - read the value SN [3] in cell number 6
2.4 vm_code_1C4C the value of cell number 6 is summed with cell number 7 (result in 7)
2.5 vm_code_1A63_1C5A - cell №7 increased by the number 84
2.6 vm_code_1D12 - read value SN [2] a cell №6
As a result, both cells (6, 7) is obtained one and the same numbers, thereby de amu conclusion that the second mathematical operation produces the following test: SN [2] = SN [0] + SN [3] + 84
3. vm_code_1E74
3.1 vm_code_1EE8 - read the value of Login [0] in cell number 6
3.2 vm_code_1F5B - transfer the value from 6 to 7 cell
3.3 vm_code_1FDD - read the value of Login [1] in cell number 6
3.4 vm_code_204D - the value of cell number 6 is summed with cell number 6 7 (result in 7)
3.5 vm_code_20CB - read the value of SN [4] in cell No. 6
3.6 vm_code_214F - the value of cell No. 6 is added to cell No. 7 (result in 7)
3.7 vm_code_21C3 - read the value of SN [1] in cell No. 8
B the result in both cells (7, 8) will get the same number, so we conclude that the third mathematical operation performs the following check: SN [1] = Login [0] + Login [1] + SN [4]
4 . v m_code_2333
4.1 vm_code_239B - read the value of Login [8] in cell No. 7
4.2 vm_code_2493 - read the value of Login [4] in cell number 6
4.3 vm_code_2517 - the value of cell number 6 is summed with cell number 7 (result in 7)
4.4 vm_code_2586 - read the value of Login [2] in cell number 6
4.5 vm_code_260A - value of cell number 6 subtracted from cell No. 7 (result in 7)
4.6 vm_code_2689 - read the value of SN [5] in cell No. 6
As a result, in both cells (6, 7) we get the same number, so we conclude that the fourth mathematical operation produces the following test: SN [5] = login [8] + login [4] - login [2]
5. vm_code_28DA - loop 10 pass all the symbols login and sum them to a cell №7
Roughly in Reza tate fifth mathematical operation is carried out here such code:
The sum of all login characters will remain in cell number 7.
6. vm_code_2AF3
6.1 vm_code_2bc5 - read the value of SN [8] in cell number 6.
As a result, in both cells (6, 7) we get the same number, so we conclude that the sixth the mathematical operation performs the following check: SN [8] = Tmp (the sum of all login numbers)
7. vm_code_2D27
7.1 vm_code_2D27_2D29 - the number 72
7.2 is added to cell No. 7 vm_code_2DD5 - we read the SN [9] value in cell No. 8
As a result, in both cells ( 7, 8) we get the same number, so we conclude that the seventh mathematical operation performs the following check: SN [9] = Tmp (the sum of all login numbers) + 72
8. vm_code_2F41(at the time this procedure is called, the sum of the login numbers will be in cell number 18)
8.1 vm_code_2FA1 - read the value of SN [6] in cell number 6
8.2 vm_code_2F41_300C - cell number 6 increases by 51
8.3 vm_code_3071_307D + vm_code_308B transfer Tmp to cell number 7
8.4 vm_code_30AA - the value of cell No. 7 is summed with cell No. 6 (the result is 6)
8.5 vm_code_311D - we read the value of SN [7] in cell No. 7
As a result, in both cells (6, 7) we get the same number, so we do the conclusion is that the eighth mathematical operation performs the following check: SN [7] = SN [6] + 51 + Tmp
Here is the whole algorithm, hidden in the ritual machine, in full view.
Well ... that’s practically it, the last third envelope has been removed.
Left just a little bit.
There was a condition in the keygenme task - it is necessary to keygenize it, i.e. write an algorithm that will generate a serial number based on the entered login.
Having on hand the algorithm for checking the serial number to do this is quite trivial.
If you look at the fields of the serial number, you can see that SN [0], SN [3] and SN [6] are not checked, they only participate in checking the values of other fields. Therefore, these three fields can contain absolutely any values, and the remaining fields will be calculated already on their basis.
As a result, here is a short list of serial numbers for the login “Rouse_”:
Keygenme resolved.
Let's go through the steps again and recall what methods were used to hide the serial number verification algorithm:
1. Resetting the entry point to zero is a debatable method; moreover, antiviruses will look with suspicion on executable files that use this trick, because the usual the compiler will never generate such an executable file, so someone modified it, which is a signal for the antivirus.
2. Encryption of the executable file body is not punishable in principle, but as shown above, such encryption is removed quite simply and does not constitute a serious obstacle.
3. The decryptor code is abundantly diluted with garbage - a controversial solution, it is simply removed due to the fact that garbage blocks were not used as garbage. Well, for example, instead of the ADD EAX, 2 instruction, you can write such a garbage block (the first thing that came to mind):
Such a garbage block can no longer be removed on the machine with a script that detects the absence of changes in the registers, because each instruction in reality will change their meaning.
If over such a block it is good to puff and inflate to a large size, then determining the beginning and end of the garbage will be quite problematic. Moreover, there is always a stack available, keeping the value of the registers on it can be, as garbage, although Fermat’s theorem cannot be proved until until then simply restore the values of the registers and continue the program :)
4. Virtual machine - due to unprotected handlers (VM instruction handlers), writing its analogue did not take a lot of time. For a good combat application, VM handlers should be properly obfuscated to make it difficult to understand the logic of the VM. It is clear that for keygenme this stage is redundant, but do not forget about such subtlety.
5. The logic of the P-Code - despite the presence of clearly garbage instructions, the main algorithm for obtaining data from the buffer with the login / SN turned out to be the same at all stages, which made it possible to quickly parse all the logic based on the template. If several options for obtaining data were introduced (or, better, a unique option for obtaining each character), this would greatly complicate the analysis.
6. VM analysis would be complicated at times if another virtual machine (for example, based on the same Brainfuck) sat inside the P-Code and would interpret its own P-Code.
What is the result:
A very high-quality keygenme, perfectly showing the work with the virtual machine. The only nuance to which he does not give an answer is how the P-Code was obtained for the virtual machine that it executes :)
This stage is individual for each developer, each uses its own methods, however, I have an article on the implementation of the picode generation algorithm , true for a slightly different type of VM.
For my part, I showed one of the options for hacking such VMs, without the stage of deobfuscating the ASM listing, using the VM execution graph as a toolkit.
I think this can help you in analyzing your own VM implementations, for their resistance to this type of hacking.
Well, if you have not come to the actual implementation of VM, at least now you have a minimal idea of how it can work.
The source code of demo examples for the article can be taken from this link: http://rouse.drkb.ru/blog/vm_analize.zip
Draw conclusions and good luck.
Unfortunately, the article will be quite difficult for a regular application programmer who is not interested in software protection topics, but there is nothing to be done.
For a more or less adequate perception of the article, minimal assembler knowledge (there will be a lot of it) as well as skills in working with the debugger will be required.
But those who hope that some simple steps will be taken here to implement this type of protection will have to be disappointed. The article will consider the already implemented functionality, but ... from the point of view of its hacking and complete reverse of the algorithm.
The main goals that I set for myself are to give a general idea of how such software protection works in general, but the most important thing is how a person who will remove your protection will approach this, because there is an old rule - you cannot implement a competent protection kernel algorithm, imagining methods of analyzing it and hacking.
As a recipient, on the advice of one fairly competent comrade, I chose a little old (but not lost its relevance, due to the quality of performance) keygenme from the notorious Ms-Rem.
Here is the original link where it appeared:http://exelab.ru/f/index.php?action=vthread&forum=1&topic=4732
And then he got here: http://www.crackmes.de/users/ms_rem/keygenme_by_ms_rem/
Where complexity was set for this keygenme 8 out of 10 (* VERY VERY * hard).
Although, to be honest, this is a slightly overestimated mark - I would put in the region of 5-6 points.
Let's start.
0. Requirements
For the good, for the full debugging of this keygenme, the most convenient platform will be Windows XP 32 bits, it is generally the most optimal environment, therefore it is constantly deployed on my workstation as a virtual machine.
Under Windows 7 - 32 bits (on which debugging was actually performed during the writing of this article) there will be small difficulties, but they can be solved (this will be mentioned in the fourth chapter of the article).
Serious difficulties will begin on 64-bit OCs, because the keygenme used as the main tool (OllyDebug) during debugging will generate errors even at the boot loader stage. OllyDebug version 2 will not pour in these errors, but there is one more difficulty, there are no necessary plug-ins for it yet (or maybe I was looking badly).
Keygenme itself must be downloaded from this link: http://exelab.ru/f/files/3635_03.05.2006_CRACKLAB.rU.tgz (registration required).
To fully work with the text of the article, if you decide to go through all the steps described in it yourself, you will need a small set of tools.
I won’t describe them in detail here, everything that needs to be done is described in the used_tools.txt file located in the root of the archive with examples for the article: http://rouse.drkb.ru/blog/vm_analize.zip
It’s also necessary to remember the correct a couple of usernames and serial numbers provided by the very first link, namely “Ms-Rem” and “C38FB7A0CF38F73B1159”. This data will greatly help in the process of parsing keygenme.
Once everything is installed - you can start.
1. Initial analysis
To begin with, it is worth deciding what exactly we are dealing with.
We start PEiD and open keygenme.exe in it.
Press the rightmost lower button and select the “Hardcore Scan” scan type in the menu.
The trouble starts right away, firstly the entry point “Entrypoint” is set to zero, which cannot be in the normal executable file, secondly, the scan showed that “UPolyX v0.5 *” is present.
The second one is just not scary - it would be something like “EXECryptor” or “Themida” - some of the commercial protectors, then yes, but here, apparently, some suitable signature was just found.
We press the second lower button on the right and in the dialog that appears, three buttons on the right.
He says that the file is packed and the entropy is already 7.56.
Well, let's say, although this still does not mean anything. Great entropy happens not only in packed, but also in encrypted files.
Close the dialog and click on the button to the right of "Subsystem:"
In addition to the entry point, the code and data bases were killed, the loading base is standard 4,000,000.
Well, okay - we have a file in our hands that was slightly corrected with handles.
Let's try to feel it all in the debugger.
2. We analyze the behavior of the application with Entrypoint = 0
Open OllyDebug, go to the “Options” menu, select “Debugging options” there, and on the “Events” tab set the checkbox “Make first pause at: -> System breakpoint”.
Thus, we will cause the debugger to interrupt when it receives the first debug message before transferring control to the body of the debugged application.
This is done due to the entry point thrown to zero.
We open keygenme.exe itself and immediately break off somewhere inside ntdll.dll
What is the entry point (for the application) is the offset from its load base (hInstance), to which the loader transfers control immediately after the process is initialized.
The download base always contains a PE header, where the _IMAGE_DOS_HEADER structure comes first.
Because keygenme's entry point is zero, which means that control will be transferred directly to its hInstance.
Knowing this, let's see what we have there.
Press “Ctrl + G” and drive in the address of the base “400000”, it should be something like this:
It’s quite a decent code instead of the standard header, but the header should be in place, otherwise the application would not have started, so the changes were made directly to _IMAGE_DOS_HEADER.
We look what exactly has changed:
_IMAGE_DOS_HEADER = record { DOS .EXE header }
e_magic: Word; { Magic number }
e_cblp: Word; { Bytes on last page of file }
e_cp: Word; { Pages in file }
e_crlc: Word; { Relocations }
e_cparhdr: Word; { Size of header in paragraphs }
e_minalloc: Word; { Minimum extra paragraphs needed }
Field e_magic - you can’t touch it and it should always contain the initials of Mark Zbikowski 'MZ' (0x4D, 0x5A).
Actually, it is not touched, and both of these symbols are interpreted as instructions:
DEC EBP // уменьшаем указатель стекового фрейма
POP EDX // читаем значение со стека в регистр EDX
The value of the second e_cblp field is changed to 0x45, 0x52, which as a result cancels the changes made by the first two instructions, restoring the correct state of the stack.
The remaining 4 fields are used to implement the MOV + JMP commands.
Here in this picture it is shown more clearly.
The whole point of such manipulations with _IMAGE_DOS_HEADER and a reset entry point is the transfer of control somewhere inside the application body at 4053B6.
Those. in principle, we can open keygenme.exe right now and specify 53B6 as the entry point (ignoring the changes in the file header), but is this the correct entry point?
3. We parse the decryptor code of the application body and unpack the application
We go to the transition address "Ctrl + G" 4056B6 and there we see this:
Generally solid garbage. Whatever the line, then the garbage instruction.
For example, all conditional branch operators (JG / JPE / JCXZ / JE) are complete garbage, because it doesn’t matter whether the condition is fulfilled or not, the transition will always be on the next line (pay attention to the jump addresses).
Instructions LEA, MOV, XCNG work with the same register without making any changes to its state - garbage.
Instructions for working with the matsoprocessor (FCLEX / FFREE) throw exceptions (which are not there, because work with the matsoprocessor has not yet been done) free the registers (which are actually not busy) - garbage.
Scroll through the code to the end to see where this garbage mess ends.
Just scroll down until we get to the code consisting of only zeros:
Yeah, but it looks like we need the address 401000, which is the jump to, which theoretically could be the original entry point.
Let's see what's there:
And there we have a code that obviously should not be in a Win32 application, which is clearly indicated by the IN and OUT instructions that will throw an exception when they are executed.
So it turns out that the code on the original entry point (OEP - Original Entry Point) is encrypted and the code in procedure 53B6 must decrypt it before performing the final jump.
But!!!
But in procedure 53B6, as previously shown, trash.
In fact, there should be not only garbage. Apparently we are dealing with the so-called garbage polymorphic, and in its simplest implementation.
The task of the polymorphic engine is to convert the original code by replacing the original instructions with their analogues (or groups of analogues). To make it difficult to analyze the resulting code, garbage instruction blocks are usually added.
There are no blocks here, just garbage instructions are generated, plus in the end, even if there was a replacement of instructions with analogues, I noticed this in only one case. It is quite possible that just a garbage generator was used here, cramming it abundantly between useful instructions, how to know ...
However, a task appeared - among all this garbage from address 4053B6 to 406839 (5251 bytes - however) find useful instructions that decrypt the application body .
There are two ways to do this.
The first is to look through the entire code with your eyes and try to find such instructions. I even tried and spent about 7 minutes for the sake of interest, as a result I even found two such instructions that are not garbage. True, as it turned out later, I missed one between them, and even after the second one I found further, I got a little sick of it - too tedious task.
Therefore, let's go the second way, and write a small script that will help clean up all the garbage and leave only the payload.
The script itself is located in the archive, which goes with the article along the following path: ". \ Scripts \ fill_trash_by_nop.txt".
To run it, the OllyScript plugin must be installed.
The script runs like this: you need to restart keygenme in the debugger and wait for the first BP to work inside NTDLL, then select “ODbgScript-> Run Script ...” in the “Plugins” menu, select the file with the script in the dialog (the path specified above) and run his.
As soon as the script starts its work, you can go make some tea for yourself, you will have about five minutes of free time.
Our logic is simple:
Because Since garbage instructions do not change the values of the registers (with the exception of EIP), the garbage instruction is detected by checking the status of the registers before and after its execution, if the registers have changed, the instruction does something useful, otherwise the instruction is considered garbage and NOP is placed instead.
When the script finishes its work and displays a message, you can view the results of its work (do not stop the debugger itself - it is still needed).
All garbage will be replaced by NOP and we will only have the following instructions on hand (you need to go from 4053B6 to 406839 and write everything that is not NOP in a notebook):
The first two lines will be a bit of garbage (sleep is called with zero delay).
0040548B PUSH 0
0040548D CALL DWORD PTR DS:[<&kernel32.Sleep>] ; kernel32.Sleep
Well, more precisely, how-it’s not really garbage, this line forces the bootloader to load kernel32.dll into the address space of the process, at the start of the process, in parallel with the already loaded ntdll.dll, because this library is declared in the keygenme import table (just as a single sleep function).
Next, the decryptor code itself will go:
004054B4 MOV ESI,keygenme.00401000 // в ESI помещаем указатель на зашифрованный буфер
0040559D MOV EDI,ESI // в EDI на результирующий
// они равны т.е. расшифрованные данные помещаются туда же
00405677 MOV ECX,1058 // устанавливаем количество итераций цикла.
// Всего расшифруется 16736 байт,
// т.к. зачитываем блоками по 4 байта ($1058 * 4)
004057FE LODS DWORD PTR DS:[ESI] // читаем 4 байта
00405904 NEG EAX // умножаем на -1
00405B69 NOT EAX // выполняем операцию NOT,
// в результате просто уменьшаем EAX на 1
// (NEG + NOT = DEC)
00405D3A BSWAP EAX // инвертируем байты
00405E90 SUB EAX,4FE62125 // отнимаем 0x4FE62125
00406121 XOR EAX,12345 // ксорим на 0x12345
00406256 STOS DWORD PTR ES:[EDI] // результат помещаем обратно
00406442 DEC ECX // уменьшаем значение счетчика итераций
004065C8 JNZ keygenme.004057D9 // переходим в начало цикла (на инструкцию 004057FE LODS)
and directly switching to OEP on which the debugger has now stopped.
00406839 JMP keygenme.00401000
Roughly speaking, if you look at the instructions of the decryptor, the keygenme body is decrypted with this simple algorithm:
uses
Classes,
Winsock;
var
I, A: Integer;
M: TMemoryStream;
begin
M := TMemoryStream.Create;
try
M.LoadFromFile('keygenme.exe');
M.Position := 512; // после выравнивания позиция данных байтов будет $1000
for I := 0 to $1058 - 1 do
begin
M.ReadBuffer(A, 4); // LODS
Dec(A); // NEG + NOT
A := htonl(A); // BSWAP
Dec(A, $4FE62125); // SUB
A := A xor $12345; // XOR
M.Position := M.Position - 4;
M.WriteBuffer(A, 4); // STOS
end;
M.SaveToFile('keygenme.exe');
finally
M.Free;
end;
end.
Now, in order not to wait for the decryption of the file each time, you need to dump the result (the OllyDump plugin must be installed).
To do this, go to OEP ("Ctrl + G" 401000) and put the breakpoint there, and then continue the program.
As soon as the debugger stops at the installed BP, go to the “Plugins” menu, select “OllyDump-> Dump debugged process” there, this dialog will open:
Focusing on the “Virtual Offset” column, set the code base equal to 1000, and the database equal to 7000, uncheck “Rebuil import” and press the “Dump” button.
In the dialog that appears, specify the new name "keygen_unpacked.exe".
Actually everything - so we removed the first envelope.
A little trick:
In general, it was much easier to dump, without considering the source code of the decryptor and other things, but since I decided to consider everything thoroughly, so I also had to dwell on it.
The second unpacking option is as follows.
1. Run the debugger and wait for the first BP to fire inside NTDLL.
2. Go to the tab of the memory card "Alt + M" and at the address 401000 we put MBP on the record:
3. Run the program for execution as soon as the recording operations are interrupted (this will be the STOS DWORD instruction), again go to the memory card and remove the MBP, after which we go to OEP (401000) and there we put the usual breakpoint.
4. Well, as soon as we break on it, you need to follow the steps already described to dump the process.
By the way, if you want, you can check the resulting file under PEiD, the entropy magically became 6.95 - and just simply decrypted the data block.
4. Initial analysis of the unpacked file and bypassing the launch problem under Vista and higher.
Now we will work with the already unpacked file.
Since the entry point in it is set correctly, in order not to make unnecessary gestures, you need to configure Olly to make the first stop no longer in NTDLL, but directly at the entry point.
Open OllyDebug, go to the “Options” menu, select “Debugging options” there, and on the “Events” tab set the checkbox “Make first pause at: -> Entry point of main module”.
Open keygenme_unpacked.exe and look at what the previously encrypted code turned into:
We immediately see the first "nuisance", the first call to CALL goes inside itself (the address 401004 is called, while the next instruction starts only with 4010005).
I already talked about such hops earlier in this article: “Learning the debugger, part two”
The essence of this trick is to confuse the disassembler and make it display the wrong code that will actually be executed. There is nothing wrong with such a “trick”, just press F7 to execute this CALL and immediately see the correct code:
You can now once again dump the process + remove the POP EBX instruction to turn off this “focus”, but since it will not interfere - we will leave it as is and begin to analyze.
First comes a block of five instructions, reading some data from the PEB (Process Environment Block), whose address is always located in FS: [$ 30].
If you open the PEB structure and see what the offsets shown in the code mean, we get about the following:
0040100A MOV EAX,DWORD PTR FS:[30] // получаем указатель на PEB
00401010 MOV EAX,DWORD PTR DS:[EAX+C] // читаем значение на PEB->LoaderData
00401013 MOV EAX,DWORD PTR DS:[EAX+1C] // читаем LoaderData->InInitOrder
00401016 MOV EAX,DWORD PTR DS:[EAX] // переходим на структуру _LDR_DATA_TABLE_ENTRY
00401018 MOV EAX,DWORD PTR DS:[EAX+8] // читаем поле DllBase
Thus, these five instructions look for hInstance "kernel32.dll", which will be located at this address, although under Vista and higher, hInstance "kernelbase.dll" will be located at this address and one unpleasant error will be associated with this.
The LEA ESI instruction places a pointer in ESI to a small array of Ansi strings located at 004012DE. These are three lines separated by zeros: “LoadLibraryA”, “ExitProcess” and “VirtualAlloc”.
By the way, I completely forgot to mention this earlier, if you look at the keygenme.exe import table, you will see that it imports one single kernel32.sleep function, the rest are missing. So the addresses of the rest necessary for work, the application must find on its own.
The following LEA EDI instruction places a pointer into the EDI buffer into which addresses of the found functions will be placed (this will be a virtual import table for kernel32), after which the procedure is called at 401198.
In fact, both LEA EDI / ESI calls are garbage. because these registers will be overwritten when the procedure is called at 401198, but they will be used in it in exactly the same way as I described above (EDI, more precisely EBP + 305, in the end it will contain the addresses of functions).
In short, the task of procedure 401198 is to prepare the ESI register, which contains a pointer to the name of the desired function, as well as the EDI register, which contains a pointer to the library export table, whose hInstance we received by reading data from PEB,
then call the function at 4011E2, which will search by name.
And here we are waiting for the second trouble, much more serious than the CALL trick at the very beginning.
The very first will be searched for "LoadLibraryA", which "kernelbase.dll" does not export.
This means that under Windows Vista and above, this keygenme will not work and will crash at startup.
You can check, the exception will be raised here:
004011EB CMPS BYTE PTR DS:[ESI],BYTE PTR ES:[EDI]
To get around this is quite simple, it is enough after starting keygenme to put BP on the instruction:
0040101B LEA ESI,DWORD PTR SS:[EBP+2DE]
those. immediately after receiving the library load address, and replace the value in the EAX register with hInstance of the “kernel32.dll” library (the correct address can be seen in the Alt + M process memory card).
After such manipulations, keygenme will start normally.
In order not to do this every time you start the application, it will be enough to run the script from the ". \ Scripts \ run_at_vista.txt" folder, which will automatically replace the EAX value with the correct one every time you start and run the program without errors.
5. Reading login and serial number
Now it's time to see how the login and serial number are read into the application’s memory and what modifications are made to them.
Usually, reading data from EDIT occurs using the GetWindowsText or GetDlgItemText functions, but since the second function eventually calls the first one anyway, then we will set the breakpoint on “GetWindowsText”.
To do this, after keygenme has started (and the user32.dll library has loaded) and its dialog box appears, go to the debugger and look for all available functions in all modules:
In the dialog that appears, look for the name of the exported function “GetWindowsTextA”, and select “Follow in Disassembler” from the menu:
After that, put BP, go into the dialogue with keygenme and drive into the appropriate fields the username “Ms-Rem” and the serial number “C38FB7A0CF38F73B1159”.
Click the “Check” button and ... stop at the breakdown inside user32 just at the beginning of the “GetWindowsTextA” function.
Now you need to return to the place of her call.
Press:
1. Ctrl + Shift + F9 - jumping to the end of the GetWindowsTextA function
2. F8 - go up to the GetDlgItemText function
3. Ctrl + Shift + F9 - jumping to the end of the GetDlgItemText function
4. F8 - go up to place of call
The blue frame contains the just made call “GetDlgItemText”, with the following parameters:
hDlg = ESI
nIDDlgItem = 65
lpString = EAX
nMaxCount = $ 10
We read this login value into the buffer pointed to by the EAX register of 16 bytes, and in the red frame The call to read the serial number to the buffer is highlighted, which will be indicated by EDI (EBP + 414E) of 32 bytes in size.
The most interesting part starts right after reading the serial number.
An interesting loop of 10 iterations follows, with the ESI register pointing to the buffer with the serial number just read, and the EDI register pointing to the buffer where the result is placed:
00401111 MOV ECX,0A // выставляем счетчик цикла
00401116 LODS WORD PTR DS:[ESI] // читаем два символа серийного номера
00401118 CALL keygenme.0040117B // вызываем функцию
0040111D STOS BYTE PTR ES:[EDI] // сохраняем 1 байт
0040111E LOOPD SHORT keygenme.00401116 // переход на следующую итерацию
Those. over the serial number in function 40117B some kind of conversions are made, the result of which is placed in EDI.
This function is as follows:
This is something like converting two characters from a string HEX representation into bytes.
If it's rude then this is an analogue of Result: = StrToInt ('$' + Value);
Take for example the original known serial number: “C38FB7A0CF38F73B1159”
After 10 iterations, it will be converted into an array with the following contents:
var
sn: array [0..9] of Byte = ($C3, $8F, $B7, $A0, $CF, $38, $F7, $3B, $11, $59);
But since the function does not check for boundaries beyond which HEX values in string format should not go, that is, a very large range of valid values that, after such a cast, will give the same number.
For example, that “C3” that “s1” as a result of such a conversion will be equal to 195 (or $ C3). Therefore, this, too, will be quite a valid serial number: " s1 8FB7A0CF38F73B1159".
Thus, we conclude: the entered login is read as is, and the serial number after reading is converted into a byte representation, moreover, because iterations are only 10, then the length of the serial number should not exceed 20 HEX characters (the rest will not be taken into account).
Basically, all this information that we need is now the time has come to look at the keygenme source code from a slightly different angle.
6. We analyze keygenme under IDA Pro, we sort VM and we receive its P-Code
We start IDA Pro and open keygenme_unpacked.exe in it, right after opening we go to the tab “Functions”.
Only 8 pieces:
Moreover, almost everything we know:
401000 is OEP, 401096 is not interesting
- and this seems to be the initial entry point, which was before all the encryption and creation of virtual IATs were hung there, but, by the way, we no longer need it.
40117B is HexToInt, we saw ...
401198 - filling in the virtual IAT, we saw ...
4011E2 - finding the address of the function by name, we saw ...
sub_401204 - something interesting (judging by the graph), we’ll probably start with it, by the way, it calls the two remaining functions sub_401257 and sub_401276.
And the calls to the read functions from the EDITs at addresses 004010F5 and 00401107, as well as the loop at address 00401111, were not recognized by IDA Pro as procedures because of garbage instructions in front of them (and not so important).
So, we look at the function graph sub_401204:
Have you ever seen what the VM graph looks like in the IDA?
If not, then look - this is the body of the virtual machine, and quite simple.
What is a virtual machine?
Roughly ... a conventional processor executes a set of instructions known to it (a machine code that can be disassembled).
A virtual machine is essentially also a processor, it only executes its own set of instructions that are generated and placed somewhere in the accessible memory area in the form of the so-called P-Code.
It is not at all necessary that these instructions coincide with those that the real processor can execute (more precisely, on the contrary - in most cases they just will not match).
In the process of protection, commercial protectors disassemble the protected blocks of code, generate a virtual machine for each of them with a unique set of logic and a set of instructions, translate the disassembled code into a picode that a specific virtual machine can execute and save the result as a buffer somewhere in the body applications. Each VM, upon gaining control during the execution of a program, sequentially reads out pikode instructions intended only for it and executes them.
Thus, the logic of the protected algorithm, which he could parse under the debugger, is hidden from the cracker. After such modifications, it will be necessary to first analyze each VM, and only after its complete analysis, pull out the algorithm from the picode it executes, converting it back into a machine code that is understandable to the ordinary processor. That work is still ...
In the picture above we see just one of the VM implementations, which can execute only 8 instructions known to it.
Let's take a closer look:
It all starts with the initialization of the EBX register, which indicates the beginning of the buffer with a picode for the virtual machine, as well as the EAX register, which is the cursor (index of the executable instruction).
VM operation begins with the loc_40120D procedure.
Its task is to first obtain the opcode of the executed instruction by calling the sub_401276 function, the code of which is given in the hint.
Judging by this code, it can be understood that the pico itself is also encrypted, and immediately after reading each byte, it decrypts with approximately this algorithm:
var
A, B: Byte;
...
A := PicodeBuff[I];
B := A;
B := B shr 4;
A := A xor B;
Result := A and 7;
After receiving the opcode, it is checked, if it is zero, then control is transferred here:
Where the unit of some variable is simply added (let's call it arg_4 as it is)
And in the end, the control goes to the finalizing block, which starts the execution of the next opcode, incrementing the EAX register.
And in it we can find out the overall size of the picocode, it is equal to $ 3DA2 (15778 bytes).
So, let’s take a look at all the instructions in order:
0. (loc_4012CA): increases the value of the variable arg_4
1. (loc_4012C5): decreases the value of the variable arg_4
2. (loc_4012BE): increases the value pointed to by arg_4
3. ( loc_4012B7): decreases the value pointed to by arg_4
4. (loc_4012A8): puts the value pointed to by arg_4 into the memory pointed to by arg_8, then increases the value of the variable arg_8
5 (loc_401299) :. puts the value pointed to by arg_C into the memory pointed to by arg_4, and then increases the value of the variable arg_C
6. (loc_401284): checks the value pointed to by arg_4, and if it is zero, starts the procedure sub_401257, passing the value 1 to EDX
7. (0040123E): checks the value pointed to by arg_4, and if it is not equal to zero, it starts the procedure “sub_401257” passing the value -1 to EDX
And in the procedure “sub_401257” the following happens, EDX is the direction of scanning the pico code, if the value is positive, it looks for opcode number 7, which corresponds to opcode number 6 taking into account nesting (i.e. e. if 066770 goes then when called from the first opcode 6, the EAX cursor will be set to zero, and when called from the second opcode 6, EAX will point to the second seven).
And if EDX = -1, then the scan goes in the opposite direction as well taking into account nesting.
That's actually the whole VM.
Doesn’t resemble anything?
Yeah - it's actually Brainfuck as it is.
http://ru.wikipedia.org/wiki/Brainfuck
i.e. it turns out that inside the keygenme there is an encrypted P-Code, which must be executed on the Brainfuck interpreter, which actually acts as a virtual machine (well, why not?)
By the way, if you pay attention to the description of BF on wikipedia and the implementation of handlers in given version of the interpreter, you will see that the fourth and fifth opcodes (reading and writing) are mixed up.
Well, if so, all that is left for us is to remove the picode from the keygenme body and we don’t need keygenme anymore, then we ourselves.
In order to determine the location of the buffer with a picode, put BP at the beginning of the VM and look at the address that initializes EBX.
We start OllyDebug and in it we put BP at the address 401208.
After BP is triggered, we look at the EBX value, this is address 401380.
We go to it in the dump window and look at the HEX values, the first 8 bytes are equal to “CE44 4E53101708DD”.
Now open keygenme_unpacked.exe in any HEX editor and look for these 8 bytes.
The size of the VM, as we found out earlier, is 15778 bytes.
We copy 15778 bytes starting from those found in the file “vm.mem”.
Well, now we have the P-Code of a virtual machine on hand, with which we have a long and hard work to do, and we no longer need keygenme together with OllyDebug and IDA Pro, they worked out their own.
PS: the already copied file "vm.mem" is available in the archive with examples for the article and is located in the folder ". \ Data \ vm.mem".
By the way.
In the process of proofreading the article, they pointed out to me at such a moment: in a real combat application, the number of functions will be several orders of magnitude more, but how in this case to determine the body of a virtual machine?
In this situation, it will be enough to set BP to read external data (login and serial number), from which it will be quite easy to track the transition to one of the virtual machine’s handlers, or perform the same actions with the output buffer (because something the VM should do and have interaction with the environment).
But all this, of course, depends on the specific implementation of the VM, and this approach is not always applicable.
7. We write our own interpreter Brainfuck
First, decode the resulting “vm.mem” into the normal representation with something like this:
const
BrainFuckOpcode: array [0..7] of AnsiChar = ('>', '<', '+', '-', ',', '.', '[', ']');
const
PicodeBuffSize = 15778;
var
PicodeBuff: array [0..PicodeBuffSize - 1] of Byte;
M: TMemoryStream;
I: Integer;
A, B: Byte;
begin
M := TMemoryStream.Create;
try
M.LoadFromFile('..\..\data\vm.mem');
M.ReadBuffer(PicodeBuff[0], PicodeBuffSize);
for I := 0 to PicodeBuffSize - 1 do
begin
A := PicodeBuff[I];
B := A;
B := B shr 4;
A := A xor B;
PicodeBuff[I] := Byte(BrainFuckOpcode[A and 7]);
end;
M.Clear;
M.WriteBuffer(PicodeBuff[0], PicodeBuffSize);
M.SaveToFile('..\..\data\vm.brainfuck');
finally
M.Free;
end;
The result is a “vm.brainfuck” file containing BF code in the form in which it is usually written, and here the instructions are already taken into account. and "," are confused.
This file, in principle, can already be fed to any BF interpreter, and if you slip the correct buffer with login and serial number, it will even execute.
By the way, about the buffer with login and serial number - I completely forgot to mention it. It goes to the input of the virtual machine in the form of a block of 20 bytes, where the first 10 bytes are filled with login characters (if the login is less than 10 bytes, the remaining bytes are zero), and immediately after them are 10 bytes of the serial number converted from a string HEX representation to byte.
Those. for the known “Ms-Rem” and “C38FB7A0CF38F73B1159” the buffer will look like this:
('M', 's', '-', 'R', 'e', 'm', 0, 0, 0, 0, $ C3, $ 8F, $ B7, $ A0, $ CF, $ 38, $ F7, $ 3B, $ 11, $ 59)
This could be seen when starting the virtual machine under the debugger, looking at the data located at the address pointed to by the variable arg_C.
For the BF interpreter to work, a buffer of 300,000 bytes is required (under the conditions described in the wiki), but in fact, this version of the code uses only 221 bytes from 300,000.
Actually, we write the code.
We need 4 buffers, for pikode, for the VM workspace, input and output buffers.
const
PicodeBuffSize = 15778;
var
// Буфер с пикодом
PicodeBuff: array [0..PicodeBuffSize - 1] of Byte;
PicodeIndex: Integer;
// Буфер для работы VM
WorkBuff: array [0..220] of Byte;
WorkBuffIndex: Integer;
// Выходной буфер
OutputBuff: array [0..39] of AnsiChar;
OutputBuffIndex: Integer;
// Буфер с логином и серийным номером
LoginAndPwd: array [0..29] of AnsiChar;
LoginAndPwdIndex: Integer;
At startup, it is necessary to load the pico code and correctly initialize the buffer with login and serial number:
procedure InitVM;
var
M: TMemoryStream;
begin
M := TMemoryStream.Create;
try
M.LoadFromFile('..\..\data\vm.brainfuck');
M.Read(PicodeBuff[0], PicodeBuffSize);
finally
M.Free;
end;
end;
procedure InitLoginAndPwd(const Login, Password: AnsiString);
var
I: Integer;
A, B: Byte;
begin
// Колируем логин
Move(Login[1], LoginAndPwd[0], Length(Login));
Move(Password[1], LoginAndPwd[10], Min(Length(Password), 20));
// подготавливаем буфер с серийным номером
for I := 0 to 9 do
begin
A := Byte(LoginAndPwd[10 + I * 2]);
B := Byte(LoginAndPwd[11 + I * 2]);
if A > $39 then
Dec(A, $37)
else
Dec(A, $30);
if B > $39 then
Dec(B, $37)
else
Dec(B, $30);
A := a shl 4;
A := A or B;
LoginAndPwd[10 + I] := AnsiChar(A);
end;
end;
Then you need to write the interpreter code itself:
procedure RunVM;
var
I: Integer;
Count: Integer;
begin
repeat
case PicodeBuff[PicodeIndex] of
Byte('>'): Inc(WorkBuffIndex);
Byte('<'): Dec(WorkBuffIndex);
Byte('+'): Inc(WorkBuff[WorkBuffIndex]);
Byte('-'): Dec(WorkBuff[WorkBuffIndex]);
Byte('.'):
begin
OutputBuff[OutputBuffIndex] := AnsiChar(WorkBuff[WorkBuffIndex]);
Inc(OutputBuffIndex);
end;
Byte(','):
begin
WorkBuff[WorkBuffIndex] := Byte(LoginAndPwd[LoginAndPwdIndex]);
Inc(LoginAndPwdIndex);
end;
Byte('['):
begin
if WorkBuff[WorkBuffIndex] <> 0 then
begin
Inc(PicodeIndex);
Continue;
end;
Count := 1;
for I := PicodeIndex + 1 to PicodeBuffSize - 1 do
begin
if PicodeBuff[I] = Byte('[') then
begin
Inc(Count);
Continue;
end;
if PicodeBuff[I] = Byte(']') then
begin
Dec(Count);
if Count = 0 then
begin
PicodeIndex := I;
Break;
end;
end;
end;
end;
Byte(']'):
begin
if WorkBuff[WorkBuffIndex] = 0 then
begin
Inc(PicodeIndex);
Continue;
end;
Count := 1;
for I := PicodeIndex - 1 downto 0 do
begin
if PicodeBuff[I] = Byte(']') then
begin
Inc(Count);
Continue;
end;
if PicodeBuff[I] = Byte('[') then
begin
Dec(Count);
if Count = 0 then
begin
PicodeIndex := I;
Break;
end;
end;
end;
end;
end;
Inc(PicodeIndex);
until PicodeIndex = PicodeBuffSize;
end;
It remains only to run all this:
InitVM;
InitLoginAndPwd('Ms-Rem', 'C38FB7A0CF38F73B1159');
RunVM;
Writeln(PAnsiChar(@OutputBuff[0]));
Readln;
We start and look at the result:

Well, everything seems to be done right and works as it should.
(The source code of the interpreter in the archive with examples '. \ Tools \ bf_execute \')
Thus - the second envelope is removed.
But now what do we do with all this?
It will not work to analyze the picocode forehead - there are no tools, the only thing that can be seen is the number of cells in which the login and password are entered and from which the result is derived.
We put BP on the read and write procedures and see what
happens with us ... Nothing good, at the moment when the login and serial number data are read, each byte is always read in cell number six of the working buffer.
The same thing happens with the output of data from the VM, the next character is also taken from cell number six.
The only thing that can at least somehow clarify the picture is a dump of the working buffer at the time of data output, look at it:

Here it is at least visible that the username and password are in the working buffer of VM, as well as just below it are two already prepared lines with “good message” and “bad”.
And in the sixth cell of the working buffer (the second from the top right) the prepared character “C” from the displayed message “Congratulations !!! It is valid serial! ”
This is such an ambush.
8. We write the Brainfuck decompiler
What is a decompiler?
In fact, this is a utility that converts a set of machine codes for a processor into a set of assembly instructions that a programmer understands. For each processor, it will be its own assembler (32/64 / ARM, etc.). Well, a virtual machine (as mentioned earlier) is the same processor with its own set of instructions, expressed as a pico code.
Now the task is to write a picode decompiler in 32-bit assembler so that you can somehow work with the result, since in this case we already have a tool for analysis - it's a debugger.
Moreover, the task is essentially simple, no prefixes need to be taken into account, ModRM / SIB parsing is only eight instructions, but first you need to figure out how it will look.
Disassembling forehead will not be a good idea, you need to minimize the blocks of repeated instructions for the BF code.
For example, we have a brainfuck script of this kind: ">>> +++ << ----"
Here we go to the fourth cell, increase its value by three, go to the second and decrease its value by four.
If you disassemble in the forehead, you get something slurred:
inc eax
inc eax
inc eax
inc byte ptr [eax]
inc byte ptr [eax]
inc byte ptr [eax]
dec eax
dec eax
dec byte ptr [eax]
dec byte ptr [eax]
dec byte ptr [eax]
dec byte ptr [eax]
It is much easier to collapse repeating sets of instructions:
add eax, 3
add byte ptr [eax], 3
sub eax, 2
sub byte ptr [eax], 4
Input and output are assembled quite simply.
We only need to know where to read and where to get it. And you need to consider that every time you read or output data, you need to shift the position so as not to read what has already been read or not to write over what is already written.
Only the option with brackets remains.
The brackets in BF execute an analog of the while loop, i.e. until the cell is zero, the loop body is executed.
The opening bracket "[" is responsible for entering the body of the loop, for the transition to the next iteration, closing the "]".
Those. roughly in assembler we need to provide two conditional transitions, one to enter the loop, one to go to the next iteration.
At least one more thing is needed before the heap, this is the address where you must go if the condition for entering the loop is not fulfilled, or if the condition for moving to the next iteration of the loop is not fulfilled.
The next step is to figure out how to disassemble the loops, taking into account the three jumps described above.
For example, there is such a picode:
More convenient for disassembling (at least for me) will be the removal of the loop body outside the main code, something like this:
If you approach in this way, then you only need to know from the disassembler the beginning and end of each procedure and decompile the body of each in a loop, inserting jumps into internal loops in the right places.
PS: True, now I look at this picture and understand that it probably might not have been worth it, because an extra jump appeared, but ... too lazy to rewrite.
Well, okay, now about the working buffer and input / output buffers: the ESI register will be used as a pointer to the working buffer, it will also be the cursor, i.e. on operations ">" or "<" this register will increase or decrease.
A pointer to the buffer with login and serial number will store the EBX register, and the EDI register will be responsible for the output buffer.
We are writing a code.
The decompiler will need a buffer with a picode and a small list in which the beginning and end of each While loop will be stored.
var
PicodeBuffSize: Integer;
PicodeBuff: array of Byte;
type
TWhileSubProc = record
StartAddr, EndAddr: Integer;
SubProcEndLabel, SubProcStartLabel: string;
end;
TWhileSubProcList = TList;
Next, several utilitarian procedures are needed.
The first builds the list itself, and the second and third, returns a list item focusing on the StartAddr and EndAddr fields.
function GetWhileSubProcList: TWhileSubProcList;
var
I, A, Z: Integer;
Item: TWhileSubProc;
begin
Result := TWhileSubProcList.Create;
for I := 0 to PicodeBuffSize - 1 do
if PicodeBuff[I] = Byte('[') then
begin
Item.StartAddr := I;
Z := 1;
for A := I + 1 to PicodeBuffSize - 1 do
begin
if PicodeBuff[A] = Byte('[') then
begin
Inc(Z);
Continue;
end;
if PicodeBuff[A] = Byte(']') then
begin
Dec(Z);
if Z = 0 then
begin
Item.EndAddr := A;
Break;
end;
end;
end;
Result.Add(Item);
end;
end;
function IndexAtStart(List: TWhileSubProcList; Value: Integer): Integer;
var
I: Integer;
begin
Result := -1;
for I := 0 to List.Count - 1 do
if List[I].StartAddr = Value then
Exit(I);
end;
function IndexAtEnd(List: TWhileSubProcList; Value: Integer): Integer;
var
I: Integer;
begin
Result := -1;
for I := 0 to List.Count - 1 do
if List[I].EndAddr = Value then
Exit(I);
end;
Now the main procedure is the decompiler of the block indicated from outside While:
procedure DecodeSubRoutine(List: TWhileSubProcList; Index: Integer);
function GetCharSimbol(Value: Integer): string;
begin
if Value < 32 then
Result := ' // #' + IntToHex(Abs(Value), 2)
else
Result := string(' // char "' + AnsiChar(Value) + '"');
end;
const
LabelPfx = '@vm_code_';
var
Count, I: Integer;
SubRoutineName: string;
Item: TWhileSubProc;
begin
if Index >= 0 then
begin
// если декомпилируем while цикл, генерируем ему имя по его адресу
PicodeIndex := List[Index].StartAddr;
SubRoutineName := LabelPfx + IntToHex(PicodeIndex, 4);
MakeAsmCode(SubRoutineName + ':');
Inc(PicodeIndex);
end
else
// в противном случае идет декомпиляция самой главной ветви пикода
SubRoutineName := '@root';
repeat
case PicodeBuff[PicodeIndex] of
// сворачиваем идущие подряд подвижки курсора
Byte('>'), Byte('<'):
begin
Count := 0;
while PicodeBuff[PicodeIndex] in [Byte('>'), Byte('<')] do
begin
if PicodeBuff[PicodeIndex] = Byte('>') then
Inc(Count)
else
Dec(Count);
Inc(PicodeIndex);
end;
if Count = 0 then Continue;
if Count < 0 then
begin
if Count = -1 then
MakeAsmCode(' dec esi')
else
MakeAsmCode(' sub esi, ' + IntToStr(Abs(Count)));
end;
if Count > 0 then
begin
if Count = 1 then
MakeAsmCode(' inc esi')
else
MakeAsmCode(' add esi, ' + IntToStr(Count));
end;
Continue;
end;
// сворачиваем идущие подряд изменения ячейки
Byte('+'), Byte('-'):
begin
Count := 0;
while PicodeBuff[PicodeIndex] in [Byte('+'), Byte('-')] do
begin
if PicodeBuff[PicodeIndex] = Byte('+') then
Inc(Count)
else
Dec(Count);
Inc(PicodeIndex);
end;
if Count = 0 then Continue;
if Count < 0 then
begin
if Count = -1 then
MakeAsmCode(' dec byte ptr [esi]')
else
MakeAsmCode(' sub byte ptr [esi], ' +
IntToStr(Abs(Count)) + GetCharSimbol(Count));
end;
if Count > 0 then
begin
if Count = 1 then
MakeAsmCode(' inc byte ptr [esi]')
else
MakeAsmCode(' add byte ptr [esi], ' +
IntToStr(Count) + GetCharSimbol(Count));
end;
Continue;
end;
// выводим значение ячейки
Byte('.'):
begin
MakeAsmCode(' mov al, byte ptr [esi]');
MakeAsmCode(' mov byte ptr [edi], al');
MakeAsmCode(' inc edi');
end;
// зачитываем значение из входного буфера
Byte(','):
begin
MakeAsmCode(' mov al, byte ptr [ebx]');
MakeAsmCode(' inc ebx');
MakeAsmCode(' mov byte ptr [esi], al');
end;
// вход в цикл While
Byte('['):
begin
I := IndexAtStart(List, PicodeIndex);
Item := List[I];
MakeAsmCode(' cmp byte ptr [esi], 0 // [');
Item.SubProcEndLabel :=
SubRoutineName + '_' + IntToHex(PicodeIndex + 1, 4);
Item.SubProcStartLabel := LabelPfx + IntToHex(PicodeIndex, 4);
// если не ноль, перейти на выполнение кода подпроцедуры
// сразу же за этой инструкцией будет код идущий за соответствующей закрывающей скобкой
MakeAsmCode(' jne ' + Item.SubProcStartLabel);
MakeAsmCode(Item.SubProcEndLabel + ':');
PicodeIndex := Item.EndAddr + 1;
List[I] := Item;
Continue;
end;
// переход на следующую итерацию
Byte(']'):
begin
I := IndexAtEnd(List, PicodeIndex);
MakeAsmCode(' cmp byte ptr [esi], 0 // ]');
// если не ноль, перейти на выполнение кода подпроцедуры
MakeAsmCode(' jne ' + List[I].SubProcStartLabel);
// в противном случае перейти на код следующий за завершением подпроцедуры
MakeAsmCode(' jmp ' + List[I].SubProcEndLabel);
// подпроцедура завершилась - идем на выход
Exit;
end;
end;
Inc(PicodeIndex);
until PicodeIndex = PicodeBuffSize;
// достигнут конец пикода, пишем финализацию
MakeAsmCode(' popa');
MakeAsmCode(' ret');
end;
It remains in the loop to cause decompilation of each While block:
procedure DecodeVM;
var
I: Integer;
List: TWhileSubProcList;
begin
MakeAsmCode('procedure RunBrainfuck(pWorkBuff, pInBuf, pOutBuf: Pointer);');
MakeAsmCode('asm');
MakeAsmCode(' pusha');
MakeAsmCode(' mov esi, pWorkBuff');
MakeAsmCode(' mov ebx, pInBuf');
MakeAsmCode(' mov edi, pOutBuf');
List := GetWhileSubProcList;
try
DecodeSubRoutine(List, -1);
for I := 0 to List.Count - 1 do
DecodeSubRoutine(List, I);
finally
List.Free;
end;
MakeAsmCode('end;');
end;
And write the startup code for all of this:
function InitPicode: Boolean;
var
M: TMemoryStream;
begin
Result := False;
if (ParamCount = 0) or not FileExists(ParamStr(1)) then
begin
Writeln('Brainfuck file not found.');
Exit;
end;
M := TMemoryStream.Create;
try
M.LoadFromFile(ParamStr(1));
PicodeBuffSize := M.Size;
SetLength(PicodeBuff, PicodeBuffSize);
M.ReadBuffer(PicodeBuff[0], PicodeBuffSize);
Result := True;
finally
M.Free;
end;
end;
begin
if InitPicode then
begin
AsmCode := TFileStream.Create(ChangeFileExt(ParamStr(1), '.inc'), fmCreate);
try
DecodeVM;
finally
AsmCode.Free;
end;
Writeln('Done.');
end;
Readln;
end.
(The source code of the decompiler in the archive with examples '. \ Tools \ bf_decompiler \')
Now you need to check its operation on something.
Take for example the Hello World from a wiki with this content:
++++++++++ [> ++++++++> ++++++++++> +++> + <<<< -]> ++
.> +. + ++++++ .. +++.> ++. << ++++++++++++++++.>. +++.
------.--------.> +.>.
And let's see what this decompiles into:
procedure RunBrainfuck(pWorkBuff, pInBuf, pOutBuf: Pointer);
asm
pusha
mov esi, pWorkBuff
mov ebx, pInBuf
mov edi, pOutBuf
add byte ptr [esi], 10 // #0A
cmp byte ptr [esi], 0 // [
jne @vm_code_000B
@root_000C:
inc esi
add byte ptr [esi], 2 // #02
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
inc byte ptr [esi]
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
add byte ptr [esi], 7 // #07
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
add byte ptr [esi], 3 // #03
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
add byte ptr [esi], 2 // #02
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
sub esi, 2
add byte ptr [esi], 15 // #0F
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
add byte ptr [esi], 3 // #03
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
sub byte ptr [esi], 6 // #06
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
sub byte ptr [esi], 8 // #08
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
inc byte ptr [esi]
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
popa
ret
@vm_code_000B:
inc esi
add byte ptr [esi], 7 // #07
inc esi
add byte ptr [esi], 10 // #0A
inc esi
add byte ptr [esi], 3 // #03
inc esi
inc byte ptr [esi]
sub esi, 4
dec byte ptr [esi]
cmp byte ptr [esi], 0 // ]
jne @vm_code_000B
jmp @root_000C
end;
It looks like it. I agree, it is possible to optimize, but not the task.
We check how it will work and write a test:
program hello_world_test;
{$APPTYPE CONSOLE}
{$R *.res}
{$I ..\..\data\helloworld.inc}
var
WorkBuff: array [0..300000] of Byte;
OutBuf: array [0..100] of Byte;
begin
RunBrainfuck(@WorkBuff[0], nil, @OutBuf[0]);
Writeln(PAnsiChar(@OutBuf[0]));
Readln;
end.
We look at the result:
Well, not bad.
It turned out what was intended, now we decompile the body of the VM itself.
The output was 8153 lines of pure assembler :)
(the result of decompiling the VM in the archive with examples '. \ Data \ vm.inc')
A quick glance through his eyes, you can immediately notice the initialization of the 'good' and 'bad' lines inside vm_code_001B_001D:
@vm_code_001B_001D:
add esi, 105
add byte ptr [esi], 67 // char "C"
add esi, 2
add byte ptr [esi], 111 // char "o"
add esi, 2
add byte ptr [esi], 110 // char "n"
add esi, 2
add byte ptr [esi], 103 // char "g"
add esi, 2
add byte ptr [esi], 114 // char "r"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 116 // char "t"
add esi, 2
add byte ptr [esi], 117 // char "u"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 116 // char "t"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 111 // char "o"
add esi, 2
add byte ptr [esi], 110 // char "n"
add esi, 2
add byte ptr [esi], 115 // char "s"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 73 // char "I"
add esi, 2
add byte ptr [esi], 116 // char "t"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 115 // char "s"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 118 // char "v"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 100 // char "d"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 115 // char "s"
add esi, 2
add byte ptr [esi], 101 // char "e"
add esi, 2
add byte ptr [esi], 114 // char "r"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 4
add byte ptr [esi], 83 // char "S"
add esi, 2
add byte ptr [esi], 101 // char "e"
add esi, 2
add byte ptr [esi], 114 // char "r"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 110 // char "n"
add esi, 2
add byte ptr [esi], 118 // char "v"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 100 // char "d"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 58 // char ":"
add esi, 2
add byte ptr [esi], 40 // char "("
But ... all the same, more than 8 thousand lines, they cannot be analyzed from a snap.
Need to write additional tools.
But for this you need to write a small demo application that executes decompiled VM code, with which we will work throughout the rest of the article.
program decompiled_vm_test;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Classes,
Math;
var
// Буфер для работы VM
WorkBuff: array [0..220] of Byte;
WorkBuffIndex: Integer;
// Выходной буфер
OutputBuff: array [0..39] of AnsiChar;
OutputBuffIndex: Integer;
// Буфер с логином и серийным номером
LoginAndPwd: array [0..29] of AnsiChar;
LoginAndPwdIndex: Integer;
procedure InitLoginAndPwd(const Login, Password: AnsiString);
var
I: Integer;
A, B: Byte;
begin
// Колируем логин
Move(Login[1], LoginAndPwd[0], Length(Login));
Move(Password[1], LoginAndPwd[10], Min(Length(Password), 20));
// подготавливаем буфер с серийным номером
for I := 0 to 9 do
begin
A := Byte(LoginAndPwd[10 + I * 2]);
B := Byte(LoginAndPwd[11 + I * 2]);
if A > $39 then
Dec(A, $37)
else
Dec(A, $30);
if B > $39 then
Dec(B, $37)
else
Dec(B, $30);
A := a shl 4;
A := A or B;
LoginAndPwd[10 + I] := AnsiChar(A);
end;
end;
{$I ..\..\data\vm.inc}
begin
InitLoginAndPwd('Ms-Rem', 'C38FB7A0CF38F73B1159');
RunBrainfuck(@WorkBuff[0], @LoginAndPwd[0], @OutputBuff[0]);
Writeln(PAnsiChar(@OutputBuff[0]));
Readln;
end.
In the demo application settings, you need to enable the generation of the MAP file (in Detailed mode), it will be useful to us in the next chapter.
9. We write a tracer
In order to understand what exactly is happening in the decompiled code, it is necessary to build an execution path. Moreover, there will be enough information about which blocks are being executed and where the transition is going from.
The essence of the route is to build a directed graph, analyzing which you can stop the logical branches into vector blocks (roughly, like a block diagram).
To do this, you need a debugger: http://habrahabr.ru/post/178159/
In the process of constructing a trace, the debugger will step by step follow the recipient code, interrupting at the addresses that we can lead to the line number in the source code that we generated earlier.
To cast the address to the line number in the asm listing, you need a small module that will parse the MAP file and return this information.
You will also need one more module, which, by the line number in the asm listing, will return the name of the subprocedure that stopped.
I will not give the source code of the last two modules - they are very simple, in any case the code can be seen in the archive with examples for the article along the following path: '. \ Tools \ tracer \'.
You will also need a class that will store the data on the removed track.
Roughly, his whole task is to store an array of records like this:
type
TTraceItem = record
SubName: string;
InList, OutList: TStringList;
CustomData: Pointer;
end;
and provide methods of working with him.
Also very simple, you can see the code in the archive along the path: '. \ Tools \ common \ trace_data.pas'
The execution track will be removed in 4 passes in 4 different modes.
1. A full track of program execution.
2. Partial trace, from one iteration of reading a buffer with login and serial number.
3. A partial trace from one iteration of the output of the result.
4. Detection of procedures in which cells are recorded with login and password.
A little later, the tracer will have to be added, adding a fifth mode to it to completely remove the trace, but removed from the demo example, in which the serial number will be thrown into a sequence of zeros (in the source code this mode will be called ttWrongSN).
But more about that later, and now ...
The implementation of the tracer is quite commonplace:
1. overlap the OnCreateProcess debugger and initialize it by setting the appropriate BP:
procedure TTracer.OnCreateProcess(Sender: TObject; ThreadIndex: Integer;
Data: TCreateProcessDebugInfo);
begin
Writeln('process start');
case FTraceType of
// трассируем от начала до конца
ttFull:
begin
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.StartLine)), hsByte, hmExecute, 0, 'vm_start');
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.EndLine)), hsByte, hmExecute, 1, 'vm_end');
end;
ttIn:
// включаем трассу от чтения логина
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.ReadPwdLine)), hsByte, hmExecute, 0, 'read_pwd_start');
ttOut:
// включаем трассу от вывода
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.OutputBufLine)), hsByte, hmExecute, 0, 'out_data_start');
ttCheckLoginBuff:
begin
// включаем трассу по первому обращению к буферу с логином и паролем
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.StartLine)), hsByte, hmExecute, 0, 'LoginAndSN_MBP_Present');
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.EndLine)), hsByte, hmExecute, 1, 'vm_end');
end;
end;
end;
2. After that, we set the operating modes in the processor of the hardwood breaker:
procedure TTracer.OnHardwareBreakpoint(Sender: TObject; ThreadIndex: Integer;
ExceptionRecord: Windows.TExceptionRecord; BreakPointIndex: THWBPIndex;
var ReleaseBreakpoint: Boolean);
var
CurrentName: string;
ThreadData: TThreadData;
I: Integer;
begin
Inc(FTotalStepCount);
ThreadData := FDebuger.GetThreadData(ThreadIndex);
Writeln(ThreadData.Breakpoint.Description[BreakPointIndex]);
case FTraceType of
ttFull:
begin
if BreakPointIndex = 0 then
begin
FDebuger.ResumeAction := raTraceInto;
ReleaseBreakpoint := True;
end
else
begin
ReleaseBreakpoint := True;
CurrentName :=
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress)));
FTrace.AddTace(FPreviousName, CurrentName);
FTrace.SaveToFile('..\..\data\full.trace');
Writeln('Trace done.');
Writeln('Total instructions traced: ', FTotalStepCount);
Writeln('Traced subroutine added: ', FTrace.Count);
Writeln('Time elapsed: ', GetTickCount - FStart, 'ms');
end;
end;
ttIn, ttOut:
begin
if FProcList.Count > 0 then
begin
ReleaseBreakpoint := True;
CurrentName :=
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress)));
FTrace.AddTace(FPreviousName, CurrentName);
if FTraceType = ttIn then
FProcList.SaveToFile('..\..\data\in.proclist')
else
FProcList.SaveToFile('..\..\data\out.proclist');
Writeln('Trace done.');
Writeln('Total instructions traced: ', FTotalStepCount);
Writeln('Traced subroutine added: ', FProcList.Count);
Writeln('Time elapsed: ', GetTickCount - FStart, 'ms');
FDebuger.ResumeAction := raRun;
end
else
FDebuger.ResumeAction := raTraceInto;
end;
ttCheckLoginBuff:
begin
ReleaseBreakpoint := True;
if BreakPointIndex = 0 then
begin
FWorkBuffAddr := PByte(FDebuger.GetContext(0).Eax);
for I := 0 to 9 do
FDebuger.SetMemoryBreakpoint(FWorkBuffAddr + 28 + (I * 2), 1, True, 'Login' + IntToStr(I));
for I := 0 to 9 do
FDebuger.SetMemoryBreakpoint(FWorkBuffAddr + 48 + (I * 2), 1, True, 'SN' + IntToStr(I));
end
else
begin
FProcList.SaveToFile('..\..\data\change_buff.proclist');
Writeln('Trace done.');
Writeln('Total instructions traced: ', FTotalStepCount);
Writeln('Traced subroutine added: ', FProcList.Count);
Writeln('Time elapsed: ', GetTickCount - FStart, 'ms');
end;
end;
end;
end;
In short, in full dump mode (ttFull), the second HBP will mean the completion of the tracing process, the ttIn, ttOut modes will stop when the second HBP fires (one I / O pass), but ttCheckLoginBuff will perform tracing using MBP until the entire VM cycle will be executed.
3. The trace results will be collected in these two handlers:
procedure TTracer.OnSingleStep(Sender: TObject; ThreadIndex: Integer;
ExceptionRecord: Windows.TExceptionRecord);
var
CurrentName: string;
begin
Inc(FTotalStepCount);
CurrentName :=
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress)));
if FTraceType = ttFull then
begin
if FPreviousName = '' then FPreviousName := CurrentName;
if FPreviousName <> CurrentName then
begin
FTrace.AddTace(FPreviousName, CurrentName);
FPreviousName := CurrentName;
end;
end
else
FProcList.Add(CurrentName);
FDebuger.ResumeAction := raTraceInto;
end;
procedure TTracer.OnMemoryBreakpoint(Sender: TObject; ThreadIndex: Integer;
ExceptionRecord: Windows.TExceptionRecord; BreakPointIndex: Integer;
var ReleaseBreakpoint: Boolean);
begin
Inc(FTotalStepCount);
FProcList.Add(
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress))));
end;
The first monitors the branching of transitions, and the second simply collects the names of the procedures from which the buffer was accessed, in which the login and serial number are located.
As a result of the tracer’s work, we will have 4 files on the basis of which we can easily analyze all the work of the VM, but ...
But for this it is necessary to somehow display the received data in the form in which you can work with them ...
10. We display the execution trace in the form of a graph
IDA Pro is an excellent tool, the graphs given to them greatly help in the process of analyzing the source code, but ... but it is not universal.
In particular, it is not very convenient to work with the graph of decompiled VM code built by IDA in this case.
That is why I went for the removal of the route with my own hands (described in the last chapter) and writing a tool that allows us to visualize it.
The essence of the tool is as follows:
1. collapse the software execution trace into the visualized graph
2. display the logical execution blocks in the graph
3. as a result, show block addresses interesting for code analysis.
The very first stage is the conversion of data from the tracer into a directional graph.
It is built quite simply - we take the current block and build outgoing transitions from it recursively. The main thing is to forget about while loops, where the transition at the end of the procedure to its beginning will be directed to the already added element.
Therefore, when constructing the graph, it is necessary for each element to add a custom property in which the node of the graph will be stored, on which the link should be exposed during the first call.
Analyzing the BF code, we can draw the following conclusions:
1. In each of the while loops, there can be only 2 inputs (from the external code block and the transition from the end of the loop).
2. The end of each while loop has only 2 outputs (if the cycle is completed, go to the next level in the code, otherwise return to the beginning of the cycle).
3. From the body of the while block can be a plurality of outputs, provided that there are ifthen blocks in its body (but this is not our case).
Code convolution means the following:
1. If the procedure has one input and one output (based on the results of the trace), then it is added to the current convolution block.
2. The beginning of each convolution block will be any procedure that has two inputs (while loop).
3. The end of the convolution block will be a transition to the already added code (end while) or any other code block that has two outputs according to the results of the trace (which implies the same end of the loop, based on the previous paragraph 3).
A fairly simple recursive procedure ('. \ Tools \ trace_viewer \ trace_graph.pas') is responsible for all these steps:
procedure TTraceGraph.LoadItem(Index: Integer; AParent: TExecutionBlock);
var
Block: TExecutionBlock;
Item: TTraceItem;
begin
// начало блока исполнения - любая подпроцедура
// тело блока исполнения - подпроцедуры из одного входящего и одного исходящего вектора
// конец блока - ссылка на уже добавленную подпроцедуру или если два выходных вектора
// Если элемент был добавлен, делаем ссылку на него и на выход
Item := FTrace[Index];
if Item.CustomData <> nil then
begin
AddVector(AParent, Item.CustomData);
Exit;
end;
Block := TExecutionBlock(AddNode(NodesCount));
if AParent = nil then
Block.Level := 0
else
begin
AddVector(AParent, Block);
Block.Level := AParent.Level + 1;
FMaxLevel := Max(FMaxLevel, Block.Level);
end;
Block.ProcList.Add(Item.SubName);
FTrace.SetCustomData(Index, Block);
// если исходящих ссылок нет - дошли до конца трассы
if Item.OutList.Count = 0 then Exit;
// если у итема две исходящих ссылки - добавляем их через рекурсию
if (Item.OutList.Count = 2) then
begin
LoadItem(FTrace.GetItemIndexByName(Item.OutList[0]), Block);
LoadItem(FTrace.GetItemIndexByName(Item.OutList[1]), Block);
Exit;
end;
// в противном случае крутим цикл
Item := FTrace.ItemByName(Item.OutList[0]);
while Item.InList.Count = 1 do
begin
Block.ProcList.Add(Item.SubName);
FTrace.SetCustomData(FTrace.GetItemIndexByName(Item.SubName), Block);
case Item.OutList.Count of
0: Exit;
1: Item := FTrace.ItemByName(Item.OutList[0]);
2:
begin
LoadItem(FTrace.GetItemIndexByName(Item.OutList[0]), Block);
LoadItem(FTrace.GetItemIndexByName(Item.OutList[1]), Block);
Exit;
end;
end;
end;
if Item.InList.Count = 2 then
LoadItem(FTrace.GetItemIndexByName(Item.SubName), Block);
end;
The result of processing the path of the decompiled code (in which there are no complicated cases in the form of multiple exits from while) will be this picture:
It displays the program execution track, with the execution blocks collapsed.
Do not pay attention to the fact that everything is so beautifully arranged with vertical columns - I did not write an algorithm for such a arrangement and scattered everything in pens (because it is much faster than writing the same visualization engine as IDA.
I will not give the source code of this utility , you can see it in the archive ". \ tools \ trace_viewer \".
Its main task is to give a starting point from which you can start when analyzing the VM code.
And here are two pictures that show part of the logic of work.
This happens when reading the login and serial number:
But these procedures are performed when the result is displayed:
Pay attention to the execution of procedures in the center of the circuit; they are a hardware and do not participate in the work of the logic of the algorithm hidden in the VM.
I’ll make a reservation right away - this conclusion was already made in the process of researching the code.
Initially, having received these two pictures in my hands, I was a little puzzled and suggested that inside could be hidden another mini-VM (green vertical block from the bottom left), which scatters logic based on my own instructions, but ... the assumption was incorrect.
And so, judging by the pictures, we have on hand:
1. The upper left block of the circuit - reading data.
2. Lower right - the conclusion of the result.
3. The central branch is some kind of hardware (as a result, you don’t even have to analyze it).
All that is not highlighted in green is the third envelope (logic hidden under the VM).
For those who will study the source code of this viewer, I apologize in advance - the tool code is very crude and was written literally on my knee in two evenings, so the utility does not have great functionality. It can only display the graph itself, provides a mechanism for its modification (read - you can move blocks as it will be more convenient).
ZOOM mode has not been added, for this there is a separate button that generates a general preview (from which these screenshots were taken).
But the role of a graph analysis tool is not bad.
In the archive with the article there is an already arranged graph ('. \ Data \ current.graph') which was obtained from the trace taken in the previous chapter ('. \ Data \ full.trace').
However ... to our sheep.
The tool for analyzing decompiled VM code is ready, let's proceed directly to its analysis ...
11. Analysis and detection of the algorithm for reading variables.
Starting to analyze VM, I already had some idea what I would have to work with.
Relying on the memory card with which the VM works (shown in Chapter 7), I knew the offsets on which the “correct” and “not correct” lines are located with the results, as well as the offset, on which the buffer with login and serial number is located.
Knowing how the BF interpreter works, I even figured out an approximate algorithm for working with data, taking into account the fact that certain operations should be performed on the login and SN.
For example, if you want to add two fields Z and X, then Brainfuck does not have an addition operation, for this it will be necessary to write a while loop in which the value of cell X will be iteratively decremented and the value of cell Y will be incremented.
Thus, cell Y will contain the sum of both cells, and cell X will be zeroed.
But when outputting data, as was shown above, one can observe that the buffer with the login and serial number is located where it should be and not one of its fields has been changed. So the VM takes some other approach to reading data.
A strange nuance, which I immediately noticed - that the login, that the serial number, that the "correct" and "not correct" lines in the memory card are not in the form as they are, but each byte is separated from the next by zero. It seems that we are working with Unicode, although in reality we are working with ANSI strings.
These two points were not clear to me.
However, starting with something is still necessary, and I decided to start the analysis of the algorithm from its end, assuming that the decision on the conclusion of the result is made with this block of procedures (where the result is displayed):
Moreover, the graph shows this block as a single function with one entry point and one output.
(By the way, the assumption that a decision is made in this block turned out to be incorrect in the end).
For debugging, I used the CPU-View mode directly from Delphi itself (this turned out to be enough for the eyes).
The debugged application was “decompiled_vm_text.exe” from which the execution track was removed.
Three variables were added to the Watch List as auxiliary hints:
1. The current value of the working buffer cursor (ESI register), which was calculated by the difference from the address of the beginning of the working buffer (pWorkBuff) and the current value of the register. (esi- $ 4E5008)
2. The value of the current cell pWorkBuff (pbyte (esi) ^)
3. It is the same only in HEX mode.
4. The dump window was configured to start the working VM buffer ($ 4E5008).
PS: your working buffer address may be different, so you should calculate the number 4E5008 in advance when starting debugging by looking at this value in the pWorkBuff variable.
Thus, the configured debugger, stopped at the beginning of the procedure "@ vm_code_39D7", looked like this:
Actually with this procedure and proceed.
If you look at the picture of the graph, this is the very first procedure in a collapsed execution block that calls itself (while the loop).
At the time of calling this procedure, the cursor of the working buffer is set to cell No. 27 (in the picture with the memory card highlighted in red), which contains a certain number (40 or $ 28). This cell is located just in front of the buffer with the login and serial number (located on offset 28, in which the first login symbol is stored - “M”).
Remember the number of this cell - it is one of the central elements of the VM logic.
Let's see the source code of a collapsed block:
@vm_code_39D7:
cmp byte ptr [esi], 0 // равно ли значение ячейки №27 нулю?
jne @vm_code_39D8 // если нет, ищем правый ноль
@vm_code_39D8:
add esi, 2 // от текущего номера ячейки прыгаем на 2 ячейки вправо
cmp byte ptr [esi], 0 // ячейка равна нулю?
jne @vm_code_39D8 // если нет, переходим к следующей
@vm_code_39D7_39D9: // нашлась ячейка равная нулю?
inc byte ptr [esi] // увеличиваем ее значение на 1
cmp byte ptr [esi], 0
jne @vm_code_39DD // и переходим на поиск ячейки #27
@vm_code_39DD:
sub esi, 2 // ищем первый ноль слева (через 2 ячейки),
// т.к. справа все уже заполнено единицами, то первый ноль будет перед ячейкой #27
cmp byte ptr [esi], 0
jne @vm_code_39DD
@vm_code_39D7_39DE:
add esi, 2 // нашли ячейку #27
dec byte ptr [esi] // декрементируем ее значение
cmp byte ptr [esi], 0 // и если оно не равно нулю, пеереходим к началу цикла
jne @vm_code_39D7
jmp @vm_code_397A_39D8 // цикл завершен
Here I built the execution blocks in the order of their execution (not in the form in which they go in the source code), so that it is easier to analyze the logic from the work.
So what is going on here?
This algorithm initializes zeros (which separate each element of the login / serial number, as well as the “bad” and “good” lines) by units.
If you stop at the finalization of the cycle and look at the result, you can see this picture:
Cell No. 27 will be reset to zero, but as a result, you can see that the buffer will be initialized with units ending just before the first VM output “good line” character, namely the “C” character.
Notice how interestingly the transitions to the beginning and end of the data being modified were performed (procedures @ vm_code_39D8 and @ vm_code_39DD). As the detection of end blocks, a reconciliation of the value of the current cell with zero is used, the leftmost zero will indicate the position of cell No. 27 (with a shift), and the rightmost zero will mean a cell not yet initialized by one.
Thus, the essence of this block is reduced to constructing the index (in the form of units) to the cell with which the next while loop will start working, starting with the @ vm_code_39EB procedure.
He will start his work with the cell, which is indicated by the last unit of the index built earlier, namely with cell number 108, where the symbol “C” is located (highlighted in blue), which the VM should now output to an external buffer.
Before calling this procedure, VM managed to perform some preparatory actions, one of which was the initialization of cell No. 27 with a unit, i.e. the leftmost cell to which the algorithm for searching the left end of the index from that moment will go will be cell No. 26.
So:
@vm_code_39EB:
dec esi // сейчас находимся на ячейке №108, сдвигаемся и
cmp byte ptr [esi], 0 // проверяем, выставлен ли на нее индекс
jne @vm_code_39ED
@vm_code_39ED:
sub esi, 2 // если да, то
cmp byte ptr [esi], 0 // ищем левый ноль (перед ячейкой №26)
jne @vm_code_39ED
jmp @vm_code_39EB_39EE
@vm_code_39EB_39EE:
inc esi // сдвигаемся с индекса на ячейку №26
inc byte ptr [esi] // инкрементируем значение ячейки №26
sub esi, 20 // сдвигаемся на ячейку №6
inc byte ptr [esi] // инкрементируем и ее
add esi, 21 // прыгаем на начало индексного массива единиц
cmp byte ptr [esi], 0
jne @vm_code_3A1D
@vm_code_3A1D:
add esi, 2 // и ищем правый конец индекса (ячейку указывающую на 108)
cmp byte ptr [esi], 0
jne @vm_code_3A1D
jmp @vm_code_39EB_3A1E // сюда приходим тогда, когда закончился индекс
@vm_code_39EB_3A1E:
dec esi // сдвигаемся на ячейку №108
dec byte ptr [esi] // декремнтируем ее и
cmp byte ptr [esi], 0 // пока она не равна нулю, крутим цикл с самого начала...
jne @vm_code_39EB
jmp @vm_code_397A_39EC // выход
The logic of the second cycle is as follows: it transfers the value of cell number 108 to cells number 26 and number 6 (note that this is the sixth cell from which the symbol that I pointed out in chapter seven is taken).
And in fact, the very logic of working with data is already beginning to emerge (when reading the value, the value is duplicated at two addresses).
The memory card starts to look like this:
The green rectangles indicate the places with which the changes occurred, the cell No. 108 from which the value was taken is highlighted in red.
The next while loop in the graph begins with the procedure "@ vm_code_3A2A".
He will start his work from cell number 26, which stores a copy of the number previously placed in cell number 108.
The code is as follows:
@vm_code_3A2A:
inc esi // прыгаем на начало индексного массива единиц
cmp byte ptr [esi], 0
jne @vm_code_3A2C
@vm_code_3A2C:
add esi, 2
cmp byte ptr [esi], 0 // ищем конец индекса, указывающий на ячейку №108
jne @vm_code_3A2C
jmp @vm_code_3A2A_3A2D
@vm_code_3A2A_3A2D:
dec esi // переходим с индекса на ячейку №108
inc byte ptr [esi] // и инкрементируем ее значние
dec esi // сдвинаемся обратно на индекс
cmp byte ptr [esi], 0
jne @vm_code_3A33
@vm_code_3A33:
sub esi, 2 // ищем начало индекса
cmp byte ptr [esi], 0
jne @vm_code_3A33
jmp @vm_code_3A2A_3A34 // сюда приходим тогда, когда закончился индекс
@vm_code_3A2A_3A34:
inc esi // сдвигаемся на ячейку №26
dec byte ptr [esi] // декрементируем ее
cmp byte ptr [esi], 0 // если она не равна нулю
jne @vm_code_3A2A // крутим цикл
jmp @vm_code_397A_3A2B // выход
The task of this code is to move the value of the cells of cell number 26 back to cell number 108, thus restoring the original value of the cell with which the algorithm began its work.
Let's look at the memory card after the algorithm works:
And the final step in this slightly confusing logic of working with cells will be the final located in the procedure "@ vm_code_3A41"
It is quite simple:
@vm_code_3A41:
dec byte ptr [esi]
sub esi, 2
cmp byte ptr [esi], 0
jne @vm_code_3A41
Her whole task is to start working with the very last cell equal to one (by means of which the index is built) and remove all the units of the index.
The result of her work will be such a map:
The green indicates the index fields that the last procedure removed, and the red indicates the result of all four collapsed blocks.
Confused?
Nothing strange, but if you look closely at the latest picture, you can understand that all this tricked-out logic of four stages essentially performs one simple operation.
And this operation is the assignment of the value of cell “A” to cell “B”.
Moreover, the algorithm is flexible enough and thus allows you to read the value of any login / serial number symbol or “good / bad” lines, for this it is enough to initialize cell No. 27 with the symbol number and perform all four of the above steps.
A beautiful approach - you can’t say anything, the logic of working with cells is quite solidly smeared, though there is a small nuance.
Having understood how the cell value is obtained and having the execution graph on hand, it will take an hour and a half to analyze the entire logic of the work from this moment on.
The rest of the procedures from the top image with a graph does not make sense, there is hidden some kind of internal hardware needed for the VM to work, there are frankly garbage pieces of code (for example, in a cycle, changing the value of two / three cells in places and eventually returning everything to its original state) .
12. Analysis of logic elements into components.
Thus, it turned out that the cell value is obtained by performing three cycles, which can be clearly seen on the graph and the final block of finalization, which removes the array of indices immediately after the end of the third cycle.
Here in this picture, I immediately highlighted them with red rectangles and repelled from this image throughout the analysis of VM logic:
Two blue rectangles also highlight the reading cycles of cell values, but since the values of the characters Login [0] and Login [1] are read in them (I learned this by analyzing all the cycles of the algorithm), then the index array of units is not built in these two cases, in the first cycle the value is read into cells No. 26 and No. 6, and in the second, the value from cell No. 26 is returned back.
The picture is not very clearly visible (zoom affects), so that it is more clear, here is the second option, which shows the principle by which I circled the blocks with rectangles:
To check my assumption, I checked myself and displayed on the graph the blocks in which the login and serial number fields change (the button "Show access to the buffer with login and SN"). Using this button, the viewer will load the list of such procedures created earlier by the tracer in ttCheckLoginBuff mode and display this picture:
Everything as expected in the previous image, the only block from the top left (circled by a blue rectangle) is knocked out of the logic, this is a section of code that reads the login and serial number values from an external buffer, so there is nothing surprising in it that these fields change.
Here I concluded that, apparently, each of the vertical blocks is one of the stages of checking the serial number (the assumption also turned out to be true).
The next step was interesting to me, and where is the decision on the correctness of the serial number made, for this I reassembled the decompiled_vm_text.exe example in which I changed the value of the serial number to zeros, and again took the trace in ttWrongSN mode.
After all these steps, I looked at the differences of the route (the button "Show differences of the route with the wrong SN") as a result I saw the following:
You could say bingo.
At the first operation (right vertical block), an exit occurred, and not all procedures were performed (the block marked in red). So it is in him that the decision is made according to the results of the first operation on the buffer with login and serial number.
More precisely, there will be several such blocks in the end, for each operation its own, however, you will not have to disassemble their logic of operation, because the meaning of all operations will be quite transparent.
The next step I put the breaks in the debugger at the beginning of each vertical block (which I previously marked with rectangles), in order to understand in what order the operations are performed.
The following list turned out:
- vm_code_17AB
- vm_code_1A63
- vm_code_1E74
- vm_code_2333
- vm_code_28DA — выполняется много раз в цикле
- vm_code_2AF3
- vm_code_2D27
- vm_code_2F41
It remains, focusing on the graph, just to go through all the selected places (skipping the already known logic elements in which the login / SN symbol is taken) and analyze what operations are performed on these symbols.
I will not give ranges of procedures in which the index is created, the value is read, the value is returned and the index is removed. For simplicity, I will show only the name of the procedure of the first cycle (in which the construction of the index array from units).
Let's
start the analysis of the logic: 1. vm_code_17AB
1.1 vm_code_1815 - read the value of SN [0] in cell number 6
1.2 vm_code_17AB_1880 add to cell number 6 number 12
1.3 vm_code_1903 - read the value of SN [4] in cell number 7
As a result, in both cells (6, 7) we get the same number, so we conclude that the first mathematical operation performs the following check: SN [4] = SN [0] + 12
2. vm_code_1A63
2.1 vm_code_1AD4 - read the value SN [0] in cell number 6
2.2 vm_code_1B58 this value is transferred to cell number 7
2.3 vm_code_1BC8 - read the value SN [3] in cell number 6
2.4 vm_code_1C4C the value of cell number 6 is summed with cell number 7 (result in 7)
2.5 vm_code_1A63_1C5A - cell №7 increased by the number 84
2.6 vm_code_1D12 - read value SN [2] a cell №6
As a result, both cells (6, 7) is obtained one and the same numbers, thereby de amu conclusion that the second mathematical operation produces the following test: SN [2] = SN [0] + SN [3] + 84
3. vm_code_1E74
3.1 vm_code_1EE8 - read the value of Login [0] in cell number 6
3.2 vm_code_1F5B - transfer the value from 6 to 7 cell
3.3 vm_code_1FDD - read the value of Login [1] in cell number 6
3.4 vm_code_204D - the value of cell number 6 is summed with cell number 6 7 (result in 7)
3.5 vm_code_20CB - read the value of SN [4] in cell No. 6
3.6 vm_code_214F - the value of cell No. 6 is added to cell No. 7 (result in 7)
3.7 vm_code_21C3 - read the value of SN [1] in cell No. 8
B the result in both cells (7, 8) will get the same number, so we conclude that the third mathematical operation performs the following check: SN [1] = Login [0] + Login [1] + SN [4]
4 . v m_code_2333
4.1 vm_code_239B - read the value of Login [8] in cell No. 7
4.2 vm_code_2493 - read the value of Login [4] in cell number 6
4.3 vm_code_2517 - the value of cell number 6 is summed with cell number 7 (result in 7)
4.4 vm_code_2586 - read the value of Login [2] in cell number 6
4.5 vm_code_260A - value of cell number 6 subtracted from cell No. 7 (result in 7)
4.6 vm_code_2689 - read the value of SN [5] in cell No. 6
As a result, in both cells (6, 7) we get the same number, so we conclude that the fourth mathematical operation produces the following test: SN [5] = login [8] + login [4] - login [2]
5. vm_code_28DA - loop 10 pass all the symbols login and sum them to a cell №7
Roughly in Reza tate fifth mathematical operation is carried out here such code:
Tmp := 0;
for I := 0 to 9 do
Inc(Tmp, Login[I]); // значение логина "Ms-Rem" в результате будет равно $11
The sum of all login characters will remain in cell number 7.
6. vm_code_2AF3
6.1 vm_code_2bc5 - read the value of SN [8] in cell number 6.
As a result, in both cells (6, 7) we get the same number, so we conclude that the sixth the mathematical operation performs the following check: SN [8] = Tmp (the sum of all login numbers)
7. vm_code_2D27
7.1 vm_code_2D27_2D29 - the number 72
7.2 is added to cell No. 7 vm_code_2DD5 - we read the SN [9] value in cell No. 8
As a result, in both cells ( 7, 8) we get the same number, so we conclude that the seventh mathematical operation performs the following check: SN [9] = Tmp (the sum of all login numbers) + 72
8. vm_code_2F41(at the time this procedure is called, the sum of the login numbers will be in cell number 18)
8.1 vm_code_2FA1 - read the value of SN [6] in cell number 6
8.2 vm_code_2F41_300C - cell number 6 increases by 51
8.3 vm_code_3071_307D + vm_code_308B transfer Tmp to cell number 7
8.4 vm_code_30AA - the value of cell No. 7 is summed with cell No. 6 (the result is 6)
8.5 vm_code_311D - we read the value of SN [7] in cell No. 7
As a result, in both cells (6, 7) we get the same number, so we do the conclusion is that the eighth mathematical operation performs the following check: SN [7] = SN [6] + 51 + Tmp
Here is the whole algorithm, hidden in the ritual machine, in full view.
This is how its source code will look:
program keygenme_source;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Windows,
Math;
function CheckSerial(const ALogin, ASerial: AnsiString): string;
const
ValidSN = 'Congratulations!!! It is valid serial!';
InvalidSN = 'Serial invalid :(';
var
Login: array [0..9] of Byte;
Serial: array [0..9] of Byte;
I, A, B, Tmp: Byte;
Checked: Boolean;
begin
ZeroMemory(@Login[0], 10);
Move(ALogin[1], Login[0], Min(10, Length(ALogin)));
// инициализируем серийник
for I := 0 to 9 do
begin
A := Byte(ASerial[1 + I * 2]);
B := Byte(ASerial[2 + I * 2]);
if A > $39 then
Dec(A, $37)
else
Dec(A, $30);
if B > $39 then
Dec(B, $37)
else
Dec(B, $30);
A := A shl 4;
Serial[I] := A or B;
end;
// проверка серийника
Checked := True;
// первый этап
if Serial[4] <> Byte(Serial[0] + 12) then
Checked := False;
// второй этап
if Serial[2] <> Byte(Serial[0] + Serial[3] + 84) then
Checked := False;
// третий этап
if Serial[1] <> Byte(Login[0] + Login[1] + Serial[4]) then
Checked := False;
// четвертый этап
if Serial[5] <> Byte(Login[8] + Login[4] - Login[2]) then
Checked := False;
// пятый этап
Tmp := 0;
for I := 0 to 9 do
Inc(Tmp, Login[I]);
// шестой этап
if Serial[8] <> Tmp then
Checked := False;
// седьмой этап
if Serial[9] <> Byte(Tmp + 72) then
Checked := False;
// восьмой этап
if Serial[7] <> Byte(Serial[6] + 51 + Tmp) then
Checked := False;
// вывод результата
if Checked then
Result := ValidSN
else
Result := InvalidSN;
end;
begin
Writeln(CheckSerial('Ms-Rem', 'C38FB7A0CF38F73B1159'));
Readln;
end.
Well ... that’s practically it, the last third envelope has been removed.
Left just a little bit.
13. We are writing a serial number generator.
There was a condition in the keygenme task - it is necessary to keygenize it, i.e. write an algorithm that will generate a serial number based on the entered login.
Having on hand the algorithm for checking the serial number to do this is quite trivial.
If you look at the fields of the serial number, you can see that SN [0], SN [3] and SN [6] are not checked, they only participate in checking the values of other fields. Therefore, these three fields can contain absolutely any values, and the remaining fields will be calculated already on their basis.
Thus, the generator code will look like this:
program serial_generator;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Windows,
Math,
SysUtils;
function GetSN(const ALogin: AnsiString): string;
var
Login: array [0..9] of Byte;
Serial: array [0..9] of Byte;
I, Tmp: Byte;
begin
ZeroMemory(@Login[0], 10);
Move(ALogin[1], Login[0], Min(10, Length(ALogin)));
Randomize;
// эти три поля не проверяются и могут содержать любые значения
Serial[0] := Random(255);
Serial[3] := Random(255);
Serial[6] := Random(255);
// генерируем число для проверки первого этапа
Serial[4] := Serial[0] + 12;
// генерируем число для проверки второго этапа
Serial[2] := Serial[0] + Serial[3] + 84;
// генерируем число для проверки третьего этапа
Serial[1] := Login[0] + Login[1] + Serial[4];
// генерируем число для проверки четвертого этапа
Serial[5] := Login[8] + Login[4] - Login[2];
// запоминаем сумму символов логина получаемом на пятом этапе
Tmp := 0;
for I := 0 to 9 do
Inc(Tmp, Login[I]);
// генерируем число для проверки шестого этапа
Serial[8] := Tmp;
// генерируем число для проверки седьмого этапа
Serial[9] := Tmp + 72;
// генерируем число для проверки восьмого этапа
Serial[7] := Serial[6] + 51 + Tmp;
// выводим результат в виде набора символов в HEX представлении
Result := '';
for I := 0 to 9 do
Result := Result + IntToHex(Serial[I], 2);
end;
begin
Writeln(GetSN('Rouse_'));
Readln;
end.
As a result, here is a short list of serial numbers for the login “Rouse_”:
- 5E2BB2006AF04EEE6DB5
- C5929D84D1F0F9996DB5
- BC894434C8F0BA5A6DB5
- 14E19B3320F0B2526DB5
Keygenme resolved.
14. Conclusions
Let's go through the steps again and recall what methods were used to hide the serial number verification algorithm:
1. Resetting the entry point to zero is a debatable method; moreover, antiviruses will look with suspicion on executable files that use this trick, because the usual the compiler will never generate such an executable file, so someone modified it, which is a signal for the antivirus.
2. Encryption of the executable file body is not punishable in principle, but as shown above, such encryption is removed quite simply and does not constitute a serious obstacle.
3. The decryptor code is abundantly diluted with garbage - a controversial solution, it is simply removed due to the fact that garbage blocks were not used as garbage. Well, for example, instead of the ADD EAX, 2 instruction, you can write such a garbage block (the first thing that came to mind):
asm
inc eax // первая реальная инструкция
// начало мусорного блока
push eax
lea eax, @label
inc eax
xchg eax, [esp]
call @label
@label:
ret
// конец мусорного блока
inc eax // вторая реальная инструкция
end;
Such a garbage block can no longer be removed on the machine with a script that detects the absence of changes in the registers, because each instruction in reality will change their meaning.
If over such a block it is good to puff and inflate to a large size, then determining the beginning and end of the garbage will be quite problematic. Moreover, there is always a stack available, keeping the value of the registers on it can be, as garbage, although Fermat’s theorem cannot be proved until until then simply restore the values of the registers and continue the program :)
4. Virtual machine - due to unprotected handlers (VM instruction handlers), writing its analogue did not take a lot of time. For a good combat application, VM handlers should be properly obfuscated to make it difficult to understand the logic of the VM. It is clear that for keygenme this stage is redundant, but do not forget about such subtlety.
5. The logic of the P-Code - despite the presence of clearly garbage instructions, the main algorithm for obtaining data from the buffer with the login / SN turned out to be the same at all stages, which made it possible to quickly parse all the logic based on the template. If several options for obtaining data were introduced (or, better, a unique option for obtaining each character), this would greatly complicate the analysis.
6. VM analysis would be complicated at times if another virtual machine (for example, based on the same Brainfuck) sat inside the P-Code and would interpret its own P-Code.
What is the result:
A very high-quality keygenme, perfectly showing the work with the virtual machine. The only nuance to which he does not give an answer is how the P-Code was obtained for the virtual machine that it executes :)
This stage is individual for each developer, each uses its own methods, however, I have an article on the implementation of the picode generation algorithm , true for a slightly different type of VM.
For my part, I showed one of the options for hacking such VMs, without the stage of deobfuscating the ASM listing, using the VM execution graph as a toolkit.
I think this can help you in analyzing your own VM implementations, for their resistance to this type of hacking.
Well, if you have not come to the actual implementation of VM, at least now you have a minimal idea of how it can work.
The source code of demo examples for the article can be taken from this link: http://rouse.drkb.ru/blog/vm_analize.zip
Draw conclusions and good luck.