Language Barrier and NLP. Why don't chatbots understand us?
People have long wanted to teach a machine to understand a person. However, only now we are a little closer to the plots of science fiction films: we can ask Alice to turn down the volume, Google Assistant - order a taxi or Siri - set an alarm. Language processing technologies are in demand in developments related to the construction of artificial intelligence: in search engines, to extract facts, assess the tonality of the text, machine translation and dialogue.

We’ll talk about the last two areas: they have a rich history and have had a significant impact on language processing. In addition, we will deal with the basic possibilities of processing natural language when creating a chat bot together with the speaker of our course AI Weekend, computer linguist Anna Vlasova.
The first talk about processing natural language with a computer began back in the 30s of the 20th century with Ayer philosophical reasoning - he proposed distinguishing an intelligent person from a stupid machine using an empirical test. In 1950, Alan Turing in the philosophical journal Mind proposed a test where the judge must determine who he is talking with: a person or a computer. Using the test, criteria were set for assessing the work of artificial intelligence, the possibility of its construction was not questioned. The test has many limitations and disadvantages, but it had a significant impact on the development of chat bots.
The first area where language processing was successfully applied was machine translation. In 1954, Georgetown University together with IBM demonstrated a machine translation program from Russian to English, which worked on the basis of a dictionary of 250 words and a set of 6 grammar rules. The program was far from what could really be called machine translation, and translated 49 pre-selected offers at a demonstration. Until the mid-60s, many attempts were made to create a fully-functional translation program, but in 1966 the Advisory Commission on Automatic Language Processing (ALPAC)declared machine translation a hopeless direction. State subsidies ceased for some time, public interest in machine translation decreased, but research did not stop there.

In parallel with attempts to teach a computer to translate text, scientists and entire universities were thinking of creating a robot that could imitate human speech behavior. The first successful implementation of the chatbot was the ELIZA virtual interlocutor, written in 1966 by Joseph Weizenbaum. Eliza parodied the psychotherapist’s behavior, extracting significant words from the interlocutor’s phrase and asking a counter question. We can assume that this was the first chat bot based on rules (rule-based bot), and it laid the foundation for a whole class of such systems. Interviewers like Cleverbot, WeChat Xiaoice, Eugene Goostman - formally passed the Turing test in 2014 - and even Siri, Jarvis and Alexa would not have appeared without Eliza.
In 1968, Terry Grapes developed the SHRDLU program in LISP. She moved simple objects on command: cones, cubes, balls, and could support the context - she understood which element needed to be moved, if it was mentioned earlier. The next step in the development of chat bots was the ALICE program, for which Richard Wallace developed a special markup language - AIML (English Artificial Intelligence Markup Language) . Then, in 1995, expectations from the chatbot were overstated: they thought that ALICE would be even smarter than a person. Of course, the chatbot did not succeed in being smarter, and for some time the business in chatbots was disappointed, and investors for a long time sidestepped the topic of virtual assistants.
Today chatbots still work on the basis of a set of rules and behavioral scenarios, however, a natural language is fuzzy and ambiguous, one thought can have many ways of presentation, therefore, the commercial success of dialogue systems depends on solving language processing problems. The machine must be taught to clearly classify the whole variety of incoming questions and interpret them clearly.
All languages are arranged differently, and this is very important for parsing. From the point of view of the morphological composition, the significant elements of the word can join the root sequentially, as, for example, in the Turkic languages, or they can break the root, as in Arabic and Hebrew. From the point of view of syntax, some languages allow the free order of words in a phrase, while others are organized more rigidly. In classical systems, word order plays an essential role. For modern NLP statistical methods, it does not have such a value, since processing does not occur at the level of words, but of whole sentences.
Other difficulties in the development of chat bots arise in connection with the development of multilingual communication. Now people often do not communicate in their native languages, they use words incorrectly. For example, in the phrase “I have shipped two days ago, but goods didn’t come” from the point of view of vocabulary, we should talk about the delivery of physical objects, for example, goods, and not about the electronic money transaction, which is described by these words by a person who speaks not in native language. But in real communication, a person will understand the interlocutor correctly, and the chat bot may have problems. In certain topics, such as investments, banking or IT, people often switch to other languages. But the chatbot is unlikely to understand what is at stake, since it is most likely trained in one language.
Before the advent of voice assistants and the widespread dissemination of chatbots, machine translation was the most demanded intellectual task, which required processing of a natural language. Talk about neural networks and deep learning went back to the 90s, and the first Mark-1 neurocomputer appeared in general in 1958. But everywhere it was not possible to use them because of the low performance of computers and the lack of sufficient language corpus. Only large research teams could afford to do research in the field of neural networks.
Machine translators in the middle of the 20th century were far from Google Translate and Yandex.Translator, but with each new method of translation ideas came up that were applied in one form or another even today.
1970 yearRule-based machine translation (RBMT) was the first attempt to teach a machine to translate. The translation was obtained as in a fifth grader with a dictionary, but in one form or another, the rules for a machine translator or chat bot are still being used.
1984 Example-based machine translation (EBMT) was able to translate even languages that were completely different from each other, where it was useless to set any rules. All modern machine translators and chat bots use ready-made examples and patterns.
1990. Statistical Machine Translation (SMT)in the era of the development of the Internet, it allowed to use not only ready-made language corps, but even books and freely translated articles. More data available increased the quality of the translation. Statistical methods are now actively used in language processing.
With the development of natural language processing, many problems were solved by classical statistical methods and many rules, but this did not solve the problem of fuzziness and ambiguity in the language. If we say “bow” without any context, then even a living interlocutor is unlikely to understand what is being said. The semantics of the word in the text are determined by the neighboring words. But how to explain this to a machine if it understands only a numerical representation? Thus was born the statistical text analysis method word2vec (English Word to vector) .
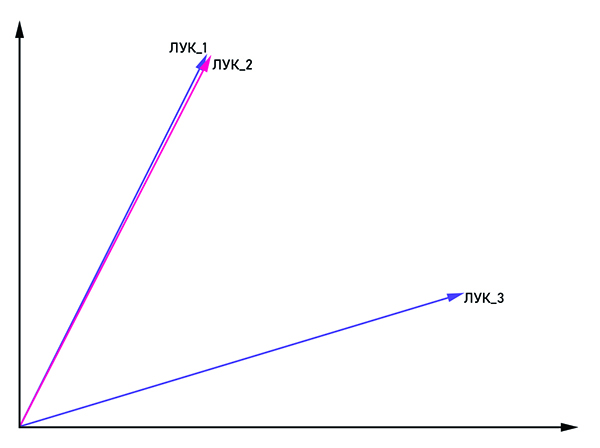
Vectors bow_1 and bow_2 are parallel, therefore this is one word, and bow_3 is a homonym.
The idea is quite obvious from the name: present the word as a vector with coordinates (x 1 , x 2 , ..., x n) To combat homonymy, the same words are joined with the tag: "bow_1", "bow_2" and so on. If the vectors bow_n and bow_m are parallel, then they can be considered as one word. Otherwise, these words are homonyms. At the output, each word has its own vector representation in multidimensional space (the dimension of the vector space can vary from 50 to 1000).

The question remains what type of neural network to use for training a conditional chat bot. Consistency is important in human speech: we draw conclusions and make decisions based on what was mentioned in the previous sentence or even the paragraph. A recurrent neural network (RNN) is perfect for these criteria, however, as the distance between the connected parts of the text increases, the size of the RNN needs to be increased, which results in a decrease in the quality of information processing. This problem is solved by the LSTM network (English Long short-term memory) . It has one important feature - the state of the cell, which can remain constant, or change if necessary. Thus, the information in the chain is not lost, which is critical for processing natural language.
Today there are a huge number of libraries for processing natural language. If we talk about the Python language, which is often used for data analysis, then these are NLTK and Spacy . Large companies also take part in developing libraries for NLP, such as NLP Architect from Intel or PyTorch from researchers from Facebook and Uber. Despite such great interest in large-scale companies in the neural network methods of language processing, coherent dialogs are built mainly on the basis of classical methods, and the neural network plays a supporting role in solving the problems of speech pre-processing and classification.
The most obvious applications for natural language processing include machine translators, chat bots, and voice assistants — something we encounter every day. Most of the call center employees can be replaced by virtual assistants, since about 80% of customer requests to banks relate to fairly typical issues. The chatbot will also calmly cope with the initial interview of the candidate and record it at a “live” meeting. Oddly enough, jurisprudence is a fairly accurate direction, so even here the chat bot can become a successful consultant.

The b2c direction is not the only one where chat bots can be used. In large companies, employee rotation is quite active, so everyone has to help in adapting to the new environment. Since the questions of the new employee are fairly typical, the whole process is easily automated. There is no need to look for a person who will explain how to refuel the printer, whom to contact on any issue. The company's internal chat bot will do just fine with this.
Using NLP, you can accurately measure user satisfaction with a new product by analyzing reviews on the Internet. If the program identified the review as negative, then the report is automatically sent to the appropriate department, where living people are already working with it.
The possibilities of language processing will only expand, and with them the scope of its application. If 40 people work in the call center of your company, it’s worth considering: maybe it’s better to replace them with a team of programmers who will put together a chat bot for you?
You can learn more about the possibilities of language processing on our AI Weekend course , where Anna Vlasova will talk in detail about chat bots in the framework of the topic of artificial intelligence.
We’ll talk about the last two areas: they have a rich history and have had a significant impact on language processing. In addition, we will deal with the basic possibilities of processing natural language when creating a chat bot together with the speaker of our course AI Weekend, computer linguist Anna Vlasova.
How did it all start?
The first talk about processing natural language with a computer began back in the 30s of the 20th century with Ayer philosophical reasoning - he proposed distinguishing an intelligent person from a stupid machine using an empirical test. In 1950, Alan Turing in the philosophical journal Mind proposed a test where the judge must determine who he is talking with: a person or a computer. Using the test, criteria were set for assessing the work of artificial intelligence, the possibility of its construction was not questioned. The test has many limitations and disadvantages, but it had a significant impact on the development of chat bots.
The first area where language processing was successfully applied was machine translation. In 1954, Georgetown University together with IBM demonstrated a machine translation program from Russian to English, which worked on the basis of a dictionary of 250 words and a set of 6 grammar rules. The program was far from what could really be called machine translation, and translated 49 pre-selected offers at a demonstration. Until the mid-60s, many attempts were made to create a fully-functional translation program, but in 1966 the Advisory Commission on Automatic Language Processing (ALPAC)declared machine translation a hopeless direction. State subsidies ceased for some time, public interest in machine translation decreased, but research did not stop there.
In parallel with attempts to teach a computer to translate text, scientists and entire universities were thinking of creating a robot that could imitate human speech behavior. The first successful implementation of the chatbot was the ELIZA virtual interlocutor, written in 1966 by Joseph Weizenbaum. Eliza parodied the psychotherapist’s behavior, extracting significant words from the interlocutor’s phrase and asking a counter question. We can assume that this was the first chat bot based on rules (rule-based bot), and it laid the foundation for a whole class of such systems. Interviewers like Cleverbot, WeChat Xiaoice, Eugene Goostman - formally passed the Turing test in 2014 - and even Siri, Jarvis and Alexa would not have appeared without Eliza.
In 1968, Terry Grapes developed the SHRDLU program in LISP. She moved simple objects on command: cones, cubes, balls, and could support the context - she understood which element needed to be moved, if it was mentioned earlier. The next step in the development of chat bots was the ALICE program, for which Richard Wallace developed a special markup language - AIML (English Artificial Intelligence Markup Language) . Then, in 1995, expectations from the chatbot were overstated: they thought that ALICE would be even smarter than a person. Of course, the chatbot did not succeed in being smarter, and for some time the business in chatbots was disappointed, and investors for a long time sidestepped the topic of virtual assistants.
Language matters
Today chatbots still work on the basis of a set of rules and behavioral scenarios, however, a natural language is fuzzy and ambiguous, one thought can have many ways of presentation, therefore, the commercial success of dialogue systems depends on solving language processing problems. The machine must be taught to clearly classify the whole variety of incoming questions and interpret them clearly.
All languages are arranged differently, and this is very important for parsing. From the point of view of the morphological composition, the significant elements of the word can join the root sequentially, as, for example, in the Turkic languages, or they can break the root, as in Arabic and Hebrew. From the point of view of syntax, some languages allow the free order of words in a phrase, while others are organized more rigidly. In classical systems, word order plays an essential role. For modern NLP statistical methods, it does not have such a value, since processing does not occur at the level of words, but of whole sentences.
Other difficulties in the development of chat bots arise in connection with the development of multilingual communication. Now people often do not communicate in their native languages, they use words incorrectly. For example, in the phrase “I have shipped two days ago, but goods didn’t come” from the point of view of vocabulary, we should talk about the delivery of physical objects, for example, goods, and not about the electronic money transaction, which is described by these words by a person who speaks not in native language. But in real communication, a person will understand the interlocutor correctly, and the chat bot may have problems. In certain topics, such as investments, banking or IT, people often switch to other languages. But the chatbot is unlikely to understand what is at stake, since it is most likely trained in one language.
Success Story: Machine Translators
Before the advent of voice assistants and the widespread dissemination of chatbots, machine translation was the most demanded intellectual task, which required processing of a natural language. Talk about neural networks and deep learning went back to the 90s, and the first Mark-1 neurocomputer appeared in general in 1958. But everywhere it was not possible to use them because of the low performance of computers and the lack of sufficient language corpus. Only large research teams could afford to do research in the field of neural networks.
Machine translators in the middle of the 20th century were far from Google Translate and Yandex.Translator, but with each new method of translation ideas came up that were applied in one form or another even today.
1970 yearRule-based machine translation (RBMT) was the first attempt to teach a machine to translate. The translation was obtained as in a fifth grader with a dictionary, but in one form or another, the rules for a machine translator or chat bot are still being used.
1984 Example-based machine translation (EBMT) was able to translate even languages that were completely different from each other, where it was useless to set any rules. All modern machine translators and chat bots use ready-made examples and patterns.
1990. Statistical Machine Translation (SMT)in the era of the development of the Internet, it allowed to use not only ready-made language corps, but even books and freely translated articles. More data available increased the quality of the translation. Statistical methods are now actively used in language processing.
Neural networks in the service of NLP
With the development of natural language processing, many problems were solved by classical statistical methods and many rules, but this did not solve the problem of fuzziness and ambiguity in the language. If we say “bow” without any context, then even a living interlocutor is unlikely to understand what is being said. The semantics of the word in the text are determined by the neighboring words. But how to explain this to a machine if it understands only a numerical representation? Thus was born the statistical text analysis method word2vec (English Word to vector) .
Vectors bow_1 and bow_2 are parallel, therefore this is one word, and bow_3 is a homonym.
The idea is quite obvious from the name: present the word as a vector with coordinates (x 1 , x 2 , ..., x n) To combat homonymy, the same words are joined with the tag: "bow_1", "bow_2" and so on. If the vectors bow_n and bow_m are parallel, then they can be considered as one word. Otherwise, these words are homonyms. At the output, each word has its own vector representation in multidimensional space (the dimension of the vector space can vary from 50 to 1000).
The question remains what type of neural network to use for training a conditional chat bot. Consistency is important in human speech: we draw conclusions and make decisions based on what was mentioned in the previous sentence or even the paragraph. A recurrent neural network (RNN) is perfect for these criteria, however, as the distance between the connected parts of the text increases, the size of the RNN needs to be increased, which results in a decrease in the quality of information processing. This problem is solved by the LSTM network (English Long short-term memory) . It has one important feature - the state of the cell, which can remain constant, or change if necessary. Thus, the information in the chain is not lost, which is critical for processing natural language.
Today there are a huge number of libraries for processing natural language. If we talk about the Python language, which is often used for data analysis, then these are NLTK and Spacy . Large companies also take part in developing libraries for NLP, such as NLP Architect from Intel or PyTorch from researchers from Facebook and Uber. Despite such great interest in large-scale companies in the neural network methods of language processing, coherent dialogs are built mainly on the basis of classical methods, and the neural network plays a supporting role in solving the problems of speech pre-processing and classification.
How can NLP be used in business?
The most obvious applications for natural language processing include machine translators, chat bots, and voice assistants — something we encounter every day. Most of the call center employees can be replaced by virtual assistants, since about 80% of customer requests to banks relate to fairly typical issues. The chatbot will also calmly cope with the initial interview of the candidate and record it at a “live” meeting. Oddly enough, jurisprudence is a fairly accurate direction, so even here the chat bot can become a successful consultant.
The b2c direction is not the only one where chat bots can be used. In large companies, employee rotation is quite active, so everyone has to help in adapting to the new environment. Since the questions of the new employee are fairly typical, the whole process is easily automated. There is no need to look for a person who will explain how to refuel the printer, whom to contact on any issue. The company's internal chat bot will do just fine with this.
Using NLP, you can accurately measure user satisfaction with a new product by analyzing reviews on the Internet. If the program identified the review as negative, then the report is automatically sent to the appropriate department, where living people are already working with it.
The possibilities of language processing will only expand, and with them the scope of its application. If 40 people work in the call center of your company, it’s worth considering: maybe it’s better to replace them with a team of programmers who will put together a chat bot for you?
You can learn more about the possibilities of language processing on our AI Weekend course , where Anna Vlasova will talk in detail about chat bots in the framework of the topic of artificial intelligence.