Parse the protocol pager messages POCSAG, P2
Hi, Habr!
In the first part , the POCSAG paging protocol was considered. Were considered digital messages, we now turn to the more "full" messages in ASCII format. Moreover, it is more interesting to decode them, because the output will be readable text.

For those who are interested in how it works, continued under the cut.
First, the signal must be accepted, for which we will use the same rtl-sdr receiver and HDSDR program. We already know from the first part that paging messages can be numeric (the content is only numbers 0-9, the letter U is “ugrent”, a space and a pair of brackets) and alphanumeric, the content is full ASCII characters. Naturally, we do not know in advance the type of message (it’s still impossible to decode them “by ear”), so when recording, we simply choose a longer message.
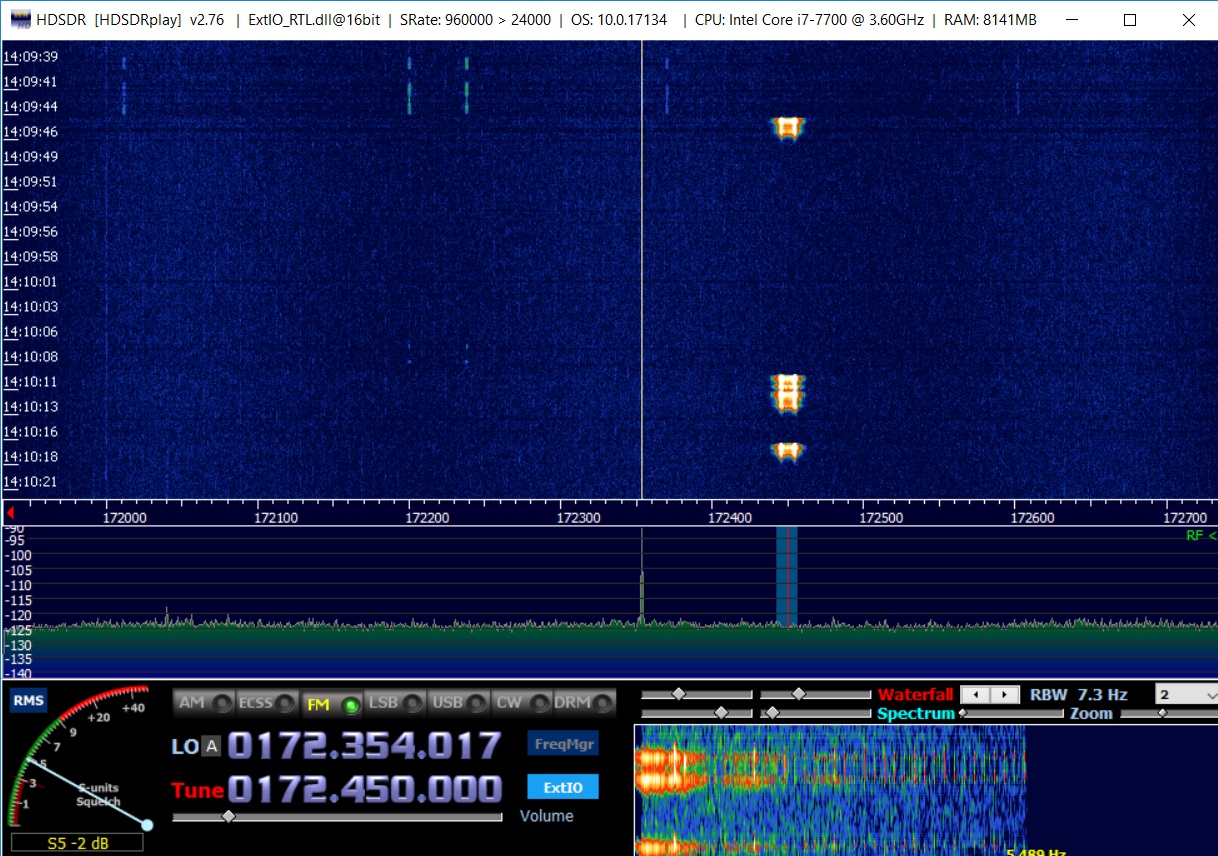
The program for converting a wav file into a bitstream has already been considered, so we will immediately show the result - the paging message looks like this:

Some features are immediately visible to the naked eye - for example, it can be seen that the starting sequence 01010101010101 is repeated twice. Those. This message is not only longer, but in fact consists of two “glued” together, but the standard does not prohibit it.
To begin, we recall a brief summary of the previous part . The paging message starts with a long header 0101010101, followed by a sequence of “packets”, shown in the picture as Batch1..N:
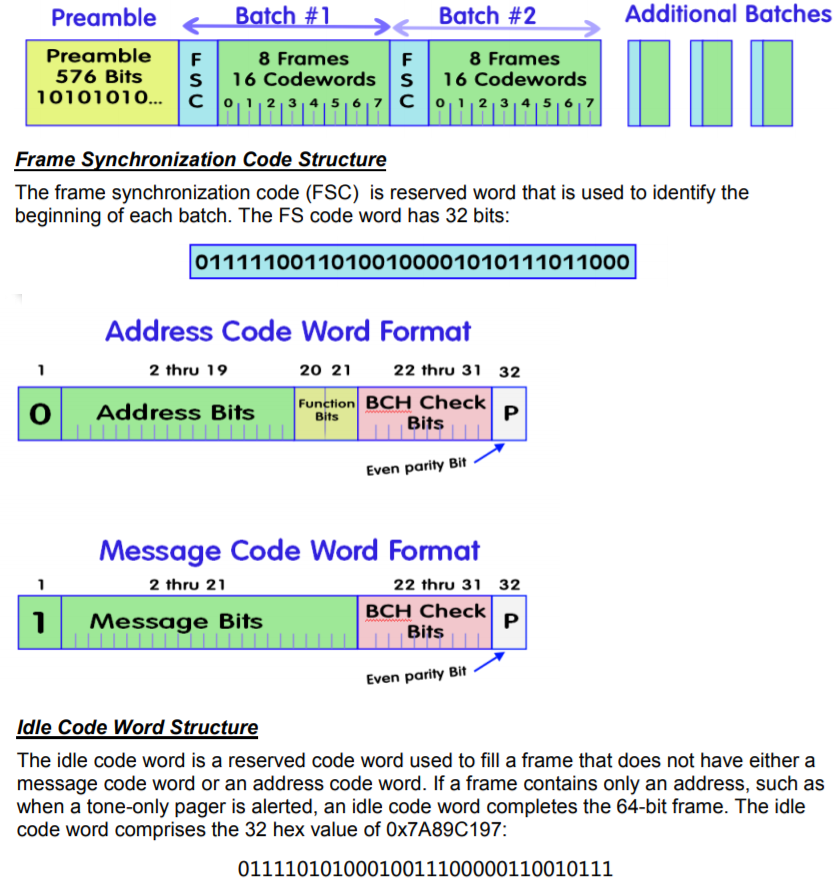
Each packet starts with the starting frame of the Frame Sync Code (01111100 ...) followed by 32-bit blocks. Each block can store either an address or a message body.
The last time we looked at only digital messages, now we are interested in ASCII messages. First of all, you need to learn to distinguish between them. For this we need the field “Function Bits” - if these 2 bits are equal to 00, then the message is digital, if 11, then the text message.
As can be seen from the figure, 20 bits are assigned to the message field, which is ideally placed in 5 4-bit BCD codes if the message is digital. But if the message is text, then the text in 20 bits does not fit much, and even 20 is not divided into 7 or 8. We can assume that the first version of the protocol (and it was created already in 1982) supported only digital messages (yes and it is unlikely that the first pagers of those years on nixie-tubes could display more ), and only then, in the next version, support for ASCII was added. But since it was no longer possible to break the format standard, they did it easier - the bitstream is simply merged as is (20 bits are extracted from each message and added to the end of the buffer), and then, at the end, all of this is decoded into characters.
Consider one block of the received message (spaces added for clarity):
In the first line, “0” in the first bit indicates that this is an address field, and “11” in bits 20-21 indicates that this message is symbolic. Then simply take 20 bits from each line and add them together.
We get this bit sequence:
The POCSAG protocol uses 7-bit ASCII, so just divide the string into blocks of 7 bits:
We are trying to decode character codes (the ASCII table is easily googled on the Internet), and ... we get garbage at the output. Once again, open the documentation and find the unobtrusive phrase "ASCII characters are placed from left to right (MSB to LSB). The LSB is transmitting first. ” Those. the low-order bit is transmitted first, and then the high-order bit — to correctly decode ASCII codes, the 7-bit strings must be flipped.
In order not to do this manually, we write the code in Python:
As a result, we get the following sequence (bits, character codes, and the characters themselves):
Combine the characters together and get the string: "(03-feb-2019 13:31:45 * 476) AWZ". As promised at the beginning of the article, the text is quite readable.
By the way, another interesting point is that as you can see, the protocol uses 7-bit ASCII. Cyrillic characters do not fit into this range, so the question how the Russian language was paged was left open. If anyone knows, write in the comments.
Of course, the protocol was not completely disassembled, but the most interesting part was done, and then the routine, which is no longer so interesting, remains. At a minimum, there is no decoding of recipient addresses (capcodes), and the support of the error correction code (BCH Check Bits) is not implemented - this would allow correcting up to 2 bits corrupted during transmission. However, the goal is to make a full-fledged decoder and did not stand - such decoders are already there, and one is hardly needed.
Those who want to try decoding messages with rtl-sdr can do it themselves using the free PDW program . It does not require installation, after starting it is necessary to redirect the HDSDR output to the PDW input using the Virtual Audio Cable program and select the appropriate device in the PDW audio settings.
The result of the program looks like this:
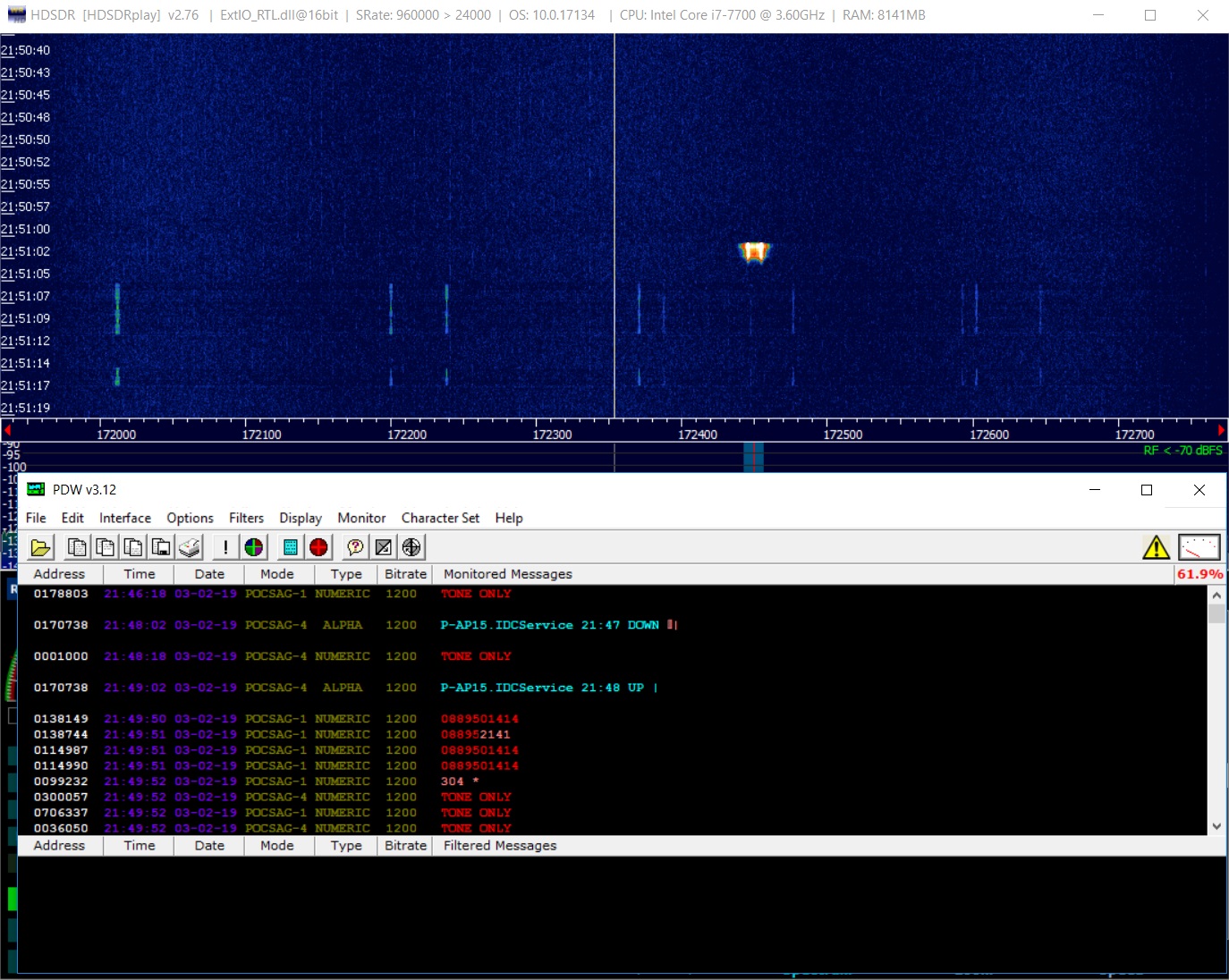
On this topic paging messages can be considered closed. Those who wish to study the topic in more detail, can study the source codes of the multimon-ng program , which can decode many protocols, including POCSAG and FLEX.
In the first part , the POCSAG paging protocol was considered. Were considered digital messages, we now turn to the more "full" messages in ASCII format. Moreover, it is more interesting to decode them, because the output will be readable text.
For those who are interested in how it works, continued under the cut.
Receive signal
First, the signal must be accepted, for which we will use the same rtl-sdr receiver and HDSDR program. We already know from the first part that paging messages can be numeric (the content is only numbers 0-9, the letter U is “ugrent”, a space and a pair of brackets) and alphanumeric, the content is full ASCII characters. Naturally, we do not know in advance the type of message (it’s still impossible to decode them “by ear”), so when recording, we simply choose a longer message.
The program for converting a wav file into a bitstream has already been considered, so we will immediately show the result - the paging message looks like this:
Some features are immediately visible to the naked eye - for example, it can be seen that the starting sequence 01010101010101 is repeated twice. Those. This message is not only longer, but in fact consists of two “glued” together, but the standard does not prohibit it.
Decoding
To begin, we recall a brief summary of the previous part . The paging message starts with a long header 0101010101, followed by a sequence of “packets”, shown in the picture as Batch1..N:
Each packet starts with the starting frame of the Frame Sync Code (01111100 ...) followed by 32-bit blocks. Each block can store either an address or a message body.
The last time we looked at only digital messages, now we are interested in ASCII messages. First of all, you need to learn to distinguish between them. For this we need the field “Function Bits” - if these 2 bits are equal to 00, then the message is digital, if 11, then the text message.
As can be seen from the figure, 20 bits are assigned to the message field, which is ideally placed in 5 4-bit BCD codes if the message is digital. But if the message is text, then the text in 20 bits does not fit much, and even 20 is not divided into 7 or 8. We can assume that the first version of the protocol (and it was created already in 1982) supported only digital messages (
Consider one block of the received message (spaces added for clarity):
0 0001010011100010111111110010010
1 00010100000110110011 11100111001
1 01011010011001110100 01111011100
1 11010001110110100100 11011000100
1 11000001101000110100 10011110111
1 11100000010100011011 11101110000
1 00110010111011001101 10011011010
1 00011001011100010110 10011000010
1 10101100000010010101 10110000101
1 00010110111011001101 00000011011
1 10100101000000101000 11001010100
1 00111101010101101100 11011111010In the first line, “0” in the first bit indicates that this is an address field, and “11” in bits 20-21 indicates that this message is symbolic. Then simply take 20 bits from each line and add them together.
We get this bit sequence:
00010100000110110011010110100110011101001101000111011010010011000001101000
11010011100000010100011011001100101110110011010001100101110001011010101100
000010010101000101101110110011011010010100000010100000111101010101101The POCSAG protocol uses 7-bit ASCII, so just divide the string into blocks of 7 bits:
0001010 0000110 1100110 1011010 0110011 1010011 ...We are trying to decode character codes (the ASCII table is easily googled on the Internet), and ... we get garbage at the output. Once again, open the documentation and find the unobtrusive phrase "ASCII characters are placed from left to right (MSB to LSB). The LSB is transmitting first. ” Those. the low-order bit is transmitted first, and then the high-order bit — to correctly decode ASCII codes, the 7-bit strings must be flipped.
In order not to do this manually, we write the code in Python:
defparse_msg(block):
msgs = ""for cw in range(16):
cws = block[32 * cw:32 * (cw + 1)]
# Skip the idle wordif cws.startswith("0111101010"):
continueif cws[0] == "0":
addr, type = cws[1:19], cws[19:21]
print(" Addr:" + addr, type)
else:
msg = cws[1:21]
print(" Msg: " + msg)
msgs += msg
# Split long string to 7 chars blocks
bits = [msgs[i:i+7] for i in range(0, len(msgs), 7)]
# Get the message
msg = ""for b in bits:
b1 = b[::-1] # Revert string
value = int(b1, 2)
msg += chr(value)
print("Msg:", msg)
print()
As a result, we get the following sequence (bits, character codes, and the characters themselves):
0101000 40 (
0110000 48 0
0110011 51 3
0101101 45 -
1100110 102 f
1100101 101 e
1100010 98 b
0101101 45 -
0110010 50 2
0110000 48 0
0110001 49 1
0111001 57 9
0100000 32
0110001 49 1
0110011 51 3
0111010 58 :
0110011 51 3
0110001 49 1
0111010 58 :
0110100 52 4
0110101 53 5
0100000 32
0101010 42 *
0110100 52 4
0110111 55 7
0110110 54 6
0101001 41 )
0100000 32
1000001 65 A
1010111 87 W
1011010 90 Z
Combine the characters together and get the string: "(03-feb-2019 13:31:45 * 476) AWZ". As promised at the beginning of the article, the text is quite readable.
By the way, another interesting point is that as you can see, the protocol uses 7-bit ASCII. Cyrillic characters do not fit into this range, so the question how the Russian language was paged was left open. If anyone knows, write in the comments.
findings
Of course, the protocol was not completely disassembled, but the most interesting part was done, and then the routine, which is no longer so interesting, remains. At a minimum, there is no decoding of recipient addresses (capcodes), and the support of the error correction code (BCH Check Bits) is not implemented - this would allow correcting up to 2 bits corrupted during transmission. However, the goal is to make a full-fledged decoder and did not stand - such decoders are already there, and one is hardly needed.
Those who want to try decoding messages with rtl-sdr can do it themselves using the free PDW program . It does not require installation, after starting it is necessary to redirect the HDSDR output to the PDW input using the Virtual Audio Cable program and select the appropriate device in the PDW audio settings.
The result of the program looks like this:
On this topic paging messages can be considered closed. Those who wish to study the topic in more detail, can study the source codes of the multimon-ng program , which can decode many protocols, including POCSAG and FLEX.