Counts for the smallest: DFS
In this article I would like to talk about one of the most common algorithms on graphs - about going in depth - using the example of solving the problem of finding a path through a maze. Everyone who is interested - welcome to the cut!

 It’s rather inconvenient to work on the “raw” labyrinth (at least the introduction of the graph will be beloved), so we will divide it into “rooms” connected by partitions. Approximately as shown in the figure on the right.
It’s rather inconvenient to work on the “raw” labyrinth (at least the introduction of the graph will be beloved), so we will divide it into “rooms” connected by partitions. Approximately as shown in the figure on the right.
Now the task has taken this form: there are many rooms, you can move between some of them. It is required to find a way from room A to room B.
In graph theory, “rooms” are called vertices, “transitions” between them are called edges. Room A is the starting peak, room B is the ending.
The graph in the picture on the right can be redrawn in a somewhat more common form in graph theory:
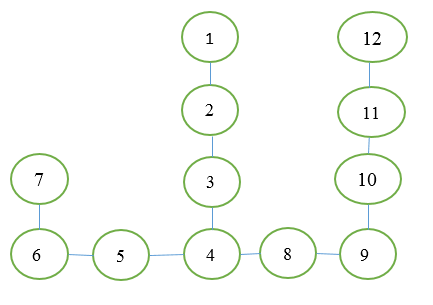
Here, ovals are vertices (or rooms), lines are edges (or transitions between them). Vertex 1 is the initial, vertex 12 is the final.
The first thing I want to do is write an exhaustive search: at each moment of time we are at some peak, and we go from it to all the neighbors:
Alas, this code doesn’t already work on a graph of three vertices, in which each vertex is connected with edges - when starting from vertex 1, we go to vertex 2, from it to vertex 1, from it again to vertex 2, ... and at some point, the program simply crashes due to a stack overflow.
The solution that immediately comes to mind is to mark each vertex at the entrance to it, and never go to the already marked vertices - this is a walk in depth:
Yes, the program went along some path, but how to determine which path?
We will remember for each vertex where we came from in a special array prior.
Then the task of restoring the path will be trivial:
The algorithm will always find a path to the top, if it exists. Proof:
For an arbitrary graph G:
Base. The algorithm finds the paths from no more than 1 vertex correctly (the path from the initial vertex to it is the same).
Assumption: The algorithm visits all peaks located at a distance of no more than k - 1 from the initial one.
Step: Consider any vertex v located at a distance k from the initial one. Obviously, it is connected by an edge with some vertex located at a distance k - 1 from the initial one - let's call it w. So, we will go to the vertex v when viewing the vertex w.
The algorithm scans each edge once, and performs a constant number of actions for each vertex. Denoting the number of vertices as V and edges as E, we get that the operating time is O (V + E).
The depth of the recursion we are in does not exceed the total number of calls to the DFS function — the number of vertices. That is, the amount of memory required for the algorithm to work is O (V).
Any recursive algorithm can be rewritten in a non-recursive form. Here is the code for DFS:
I hope it was informative. In the following articles I will try to tell more about what tasks can be solved using DFS, as well as why BFS, Dijkstra and other graph algorithms are needed.
Formulation of the problem
It’s rather inconvenient to work on the “raw” labyrinth (at least the introduction of the graph will be beloved), so we will divide it into “rooms” connected by partitions. Approximately as shown in the figure on the right. Now the task has taken this form: there are many rooms, you can move between some of them. It is required to find a way from room A to room B.
In graph theory, “rooms” are called vertices, “transitions” between them are called edges. Room A is the starting peak, room B is the ending.
The graph in the picture on the right can be redrawn in a somewhat more common form in graph theory:
Here, ovals are vertices (or rooms), lines are edges (or transitions between them). Vertex 1 is the initial, vertex 12 is the final.
And how will we solve this problem?
The first thing I want to do is write an exhaustive search: at each moment of time we are at some peak, and we go from it to all the neighbors:
Brute force
It is assumed that the graph is stored in a vector array> edges, and edges [v] contains the numbers of all vertices to which there is an edge from v. It is also assumed that the final vertex number is stored in the global variable finish.
void travel(int v)
{
if (v == finish) // Проверяем, конец ли
{
cout << "Hooray! The path was found!\n";
return;
}
for (int i = 0; i < (int)edges[v].size(); ++i) // Для каждого ребра
{
travel(edges[v][i]); // Запускаемся из соседа
}
}
Alas, this code doesn’t already work on a graph of three vertices, in which each vertex is connected with edges - when starting from vertex 1, we go to vertex 2, from it to vertex 1, from it again to vertex 2, ... and at some point, the program simply crashes due to a stack overflow.
What to do?
The solution that immediately comes to mind is to mark each vertex at the entrance to it, and never go to the already marked vertices - this is a walk in depth:
Dfs
void DFS(int v)
{
if (mark[v] != 0) // Если мы здесь уже были, то тут больше делать нечего
{
return;
}
mark[v] = 1; // Помечаем, что мы здесь были
if (v == finish) // Проверяем, конец ли
{
cout << "Hooray! The path was found!\n";
return;
}
for (int i = 0; i < (int)edges[v].size(); ++i) // Для каждого ребра
{
DFS(edges[v][i]); // Запускаемся из соседа
}
}
So what?
Yes, the program went along some path, but how to determine which path?
We will remember for each vertex where we came from in a special array prior.
Dfs
void DFS(int v, int from)
{
if (mark[v] != 0) // Если мы здесь уже были, то тут больше делать нечего
{
return;
}
mark[v] = 1; // Помечаем, что мы здесь были
prior[v] = from; // Запоминаем, откуда пришли
if (v == finish) // Проверяем, конец ли
{
cout << "Hooray! The path was found!\n";
return;
}
for (int i = 0; i < (int)edges[v].size(); ++i) // Для каждого ребра
{
DFS(edges[v][i], v); // Запускаемся из соседа
}
}
Then the task of restoring the path will be trivial:
get_path
vector get_path()
{
vector ans;
for (int v = finish; v != start; v = prior[v]) // Проходим по пути из конца в начало
{
ans.push_back(v); // Запоминаем вершину
}
ans.push_back(start);
reverse(ans.begin(), ans.end()); // Переворачиваем путь
return ans;
}
Why does it work?
The algorithm will always find a path to the top, if it exists. Proof:
For an arbitrary graph G:
Base. The algorithm finds the paths from no more than 1 vertex correctly (the path from the initial vertex to it is the same).
Assumption: The algorithm visits all peaks located at a distance of no more than k - 1 from the initial one.
Step: Consider any vertex v located at a distance k from the initial one. Obviously, it is connected by an edge with some vertex located at a distance k - 1 from the initial one - let's call it w. So, we will go to the vertex v when viewing the vertex w.
How many resources does the algorithm need?
The algorithm scans each edge once, and performs a constant number of actions for each vertex. Denoting the number of vertices as V and edges as E, we get that the operating time is O (V + E).
The depth of the recursion we are in does not exceed the total number of calls to the DFS function — the number of vertices. That is, the amount of memory required for the algorithm to work is O (V).
Non-recursive DFS
Any recursive algorithm can be rewritten in a non-recursive form. Here is the code for DFS:
Dfs
void DFS()
{
stack s;
s.push(start);
while (!s.empty())
{
int v = s.top();
s.pop();
for (int i = 0; i < edges[v].size(); ++i)
{
if (mark[edges[v][i]] == 0)
{
s.push(edges[v][i]);
mark[edges[v][i]] = 1;
}
}
}
}
What's next?
I hope it was informative. In the following articles I will try to tell more about what tasks can be solved using DFS, as well as why BFS, Dijkstra and other graph algorithms are needed.