Asynchronous C # programming: how are you doing with performance?
More recently, we have already talked about whether Equals and GetHashCode should be redefined when programming in C #. Today we will deal with the performance parameters of asynchronous methods. Join now!

In the last two articles in the msdn blog, we looked at the internal structure of asynchronous methods in C # and the extension points that the C # compiler provides to control the behavior of asynchronous methods.
Based on the information in the first article, the compiler performs many transformations to make asynchronous programming as similar to synchronous as possible. To do this, it creates a copy of the state machine, passes it to the builder of the asynchronous method, which calls the awaiter object for the task, etc. Of course, this logic has its price, but how much will it cost us?
Until the TPL library appeared, asynchronous operations were not used in such a large amount, and therefore the costs were low. But today, even a relatively simple application can perform hundreds, if not thousands, of asynchronous operations per second. The library of parallel tasks TPL was created taking into account such a workload, but there is no magic here, and you have to pay for everything.
To estimate the costs of asynchronous methods, we will use a slightly modified example from the first article.
The class
The method is
In the first performance test, we compare an asynchronous method that calls an asynchronous initialization method (
The results are shown below:

Already at this stage we obtained quite interesting data:
(*) Of course, one cannot say that the costs of synchronous execution of the asynchronous method are 15% for all possible cases. This value depends on the workload performed by the method. The difference between the costs of a pure asynchronous method call (which does nothing) and a synchronous method (which does nothing) will be huge. The idea of this comparative test is to show that the costs of an asynchronous method that performs a relatively small amount of work are relatively low.
How did it happen that during the call
The answer to the above question is very simple: it
The method
But this is not the only possible optimization.
This is confirmed by the following test:
You should not overly rely on this behavior , but it is always pleasant to realize that the creators of the language and the platform are doing everything possible to improve performance by all available means. Task caching is a popular optimization method that also finds application in other areas. For example, the new implementation
Optimization number 2: use
The optimization method described above only works in a few cases. Therefore, instead of it, we can use
This special type helps prevent excessive heap allocation when performing an operation synchronously. To be able to use
Now we can estimate the difference using the additional benchmark:
As you can see, the version c
If you often use some asynchronous method and want to reduce costs even more, I suggest you the following optimization: remove the async modifier, and then check the state of the task inside the method and perform the entire operation synchronously, completely abandoning the asynchronous approaches.
Looks hard? Consider an example.
In this case, the method
Using a local function is not the only one, but one of the easiest ways. But there is one nuance. In the course of the most natural implementation, the local function will receive the external state (local variable and argument):
But, unfortunately, due to a compiler error, this code will cause closure, even if the method is executed within the framework of a common path. Here is how this method looks from the inside:
As discussed in the article Dissecting the Local Functions in C # (“Truncating Local Functions in C #”), the compiler uses a common instance of closure for all local variables and arguments in a particular area. Consequently, there is some sense in such code generation, but it makes the whole struggle with heap allocation useless.
TIP . Such optimization is a very insidious thing. The advantages are insignificant, and even if you write the correct initial local function, in the course of further changes, you can accidentally get the external state that causes the selection of the heap. You can still resort to optimization if you work with a frequently used library (for example, BCL) in a method that will definitely be used on a loaded portion of code.
At the moment we have considered only one specific case: the costs of the asynchronous method, which is performed synchronously. This is intentional. The “less” the asynchronous method, the more noticeable are the costs in its overall performance. More detailed asynchronous methods, as a rule, run synchronously and perform a lower workload. And we usually call them more often.
But we need to know about the costs of the asynchronous mechanism when the method “waits” for the completion of an unfulfilled task. To estimate these costs, we will make changes to
Add to our package for comparative testing the following methods:

As you can see, the difference is palpable - both in terms of speed and in terms of memory usage. We briefly explain the results.
(**) It depends on the platform (x64 or x86) and a number of local variables and arguments of the asynchronous method.
Of course, measurements are our everything. If you see that an asynchronous operation causes performance problems, you can switch from
In the last two articles in the msdn blog, we looked at the internal structure of asynchronous methods in C # and the extension points that the C # compiler provides to control the behavior of asynchronous methods.
Based on the information in the first article, the compiler performs many transformations to make asynchronous programming as similar to synchronous as possible. To do this, it creates a copy of the state machine, passes it to the builder of the asynchronous method, which calls the awaiter object for the task, etc. Of course, this logic has its price, but how much will it cost us?
Until the TPL library appeared, asynchronous operations were not used in such a large amount, and therefore the costs were low. But today, even a relatively simple application can perform hundreds, if not thousands, of asynchronous operations per second. The library of parallel tasks TPL was created taking into account such a workload, but there is no magic here, and you have to pay for everything.
To estimate the costs of asynchronous methods, we will use a slightly modified example from the first article.
publicclassStockPrices
{
privateconstint Count = 100;
private List<(string name, decimal price)> _stockPricesCache;
// Async versionpublicasync Task<decimal> GetStockPriceForAsync(string companyId)
{
await InitializeMapIfNeededAsync();
return DoGetPriceFromCache(companyId);
}
// Sync version that calls async initpublicdecimalGetStockPriceFor(string companyId)
{
InitializeMapIfNeededAsync().GetAwaiter().GetResult();
return DoGetPriceFromCache(companyId);
}
// Purely sync versionpublicdecimalGetPriceFromCacheFor(string companyId)
{
InitializeMapIfNeeded();
return DoGetPriceFromCache(companyId);
}
privatedecimalDoGetPriceFromCache(string name)
{
foreach (var kvp in _stockPricesCache)
{
if (kvp.name == name)
{
return kvp.price;
}
}
thrownew InvalidOperationException($"Can't find price for '{name}'.");
}
[MethodImpl(MethodImplOptions.NoInlining)]
privatevoidInitializeMapIfNeeded()
{
// Similar initialization logic.
}
privateasync Task InitializeMapIfNeededAsync()
{
if (_stockPricesCache != null)
{
return;
}
await Task.Delay(42);
// Getting the stock prices from the external source.// Generate 1000 items to make cache hit somewhat expensive
_stockPricesCache = Enumerable.Range(1, Count)
.Select(n => (name: n.ToString(), price: (decimal)n))
.ToList();
_stockPricesCache.Add((name: "MSFT", price: 42));
}
}
The class
StockPrices saves the stock prices from an external source to the cache and allows them to be requested through the API. The main difference from the example from the first article is the transition from the dictionary to the list of prices. In order to estimate the costs of various asynchronous methods in comparison with synchronous ones, the operation itself must perform a certain work, in our case it is a linear search for stock prices. The method is
GetPricesFromCacheintentionally built on the basis of a simple cycle in order to avoid resource allocation.Comparison of synchronous methods and asynchronous methods based on tasks
In the first performance test, we compare an asynchronous method that calls an asynchronous initialization method (
GetStockPriceForAsync), a synchronous method that calls an asynchronous initialization method ( GetStockPriceFor), and a synchronous method that calls a synchronous initialization method.privatereadonly StockPrices _stockPrices = new StockPrices();
publicSyncVsAsyncBenchmark()
{
// Warming up the cache
_stockPrices.GetStockPriceForAsync("MSFT").GetAwaiter().GetResult();
}
[Benchmark]
publicdecimalGetPricesDirectlyFromCache()
{
return _stockPrices.GetPriceFromCacheFor("MSFT");
}
[Benchmark(Baseline = true)]
publicdecimalGetStockPriceFor()
{
return _stockPrices.GetStockPriceFor("MSFT");
}
[Benchmark]
publicdecimalGetStockPriceForAsync()
{
return _stockPrices.GetStockPriceForAsync("MSFT").GetAwaiter().GetResult();
}
The results are shown below:
Already at this stage we obtained quite interesting data:
- The asynchronous method is quite fast.
GetPricesForAsyncruns synchronously in this test and about 15% (*) slower than the purely synchronous method. - The synchronous method
GetPricesFor, which calls the asynchronous methodInitializeMapIfNeededAsync, has even lower costs, but what is most surprising is that it does not allocate resources at all (in the Allocated column in the above table it is 0 for bothGetPricesDirectlyFromCache, and forGetStockPriceFor).
(*) Of course, one cannot say that the costs of synchronous execution of the asynchronous method are 15% for all possible cases. This value depends on the workload performed by the method. The difference between the costs of a pure asynchronous method call (which does nothing) and a synchronous method (which does nothing) will be huge. The idea of this comparative test is to show that the costs of an asynchronous method that performs a relatively small amount of work are relatively low.
How did it happen that during the call
InitializeMapIfNeededAsync no resources were allocated at all? In the first article in this series, I mentioned that the asynchronous method should allocate at least one object in the managed header — the task instance itself. Let's discuss this point in more detail.Optimization # 1: caching task instances when possible
The answer to the above question is very simple: it
AsyncMethodBuilder uses one instance of the task for each successfully completed asynchronous operation . The asynchronous method that returns Taskuses AsyncMethodBuilder with the following logic in the method SetResult:// AsyncMethodBuilder.cs from mscorlibpublicvoidSetResult()
{
// I.e. the resulting task for all successfully completed// methods is the same -- s_cachedCompleted.
m_builder.SetResult(s_cachedCompleted);
}The method
SetResult is invoked only for successfully completed asynchronous methods, and a successful result for each method based on Task can be used without interruption . We can even trace this behavior with the following test:[Test]
publicvoidAsyncVoidBuilderCachesResultingTask()
{
var t1 = Foo();
var t2 = Foo();
Assert.AreSame(t1, t2);
async Task Foo() { }
}
But this is not the only possible optimization.
AsyncTaskMethodBuilder<T>optimizes work in a similar way: it caches tasks for Task<bool>some other simple types. For example, it caches all default values for a group of integer types and uses a special cache for Task<int>, putting values from the range [-1; 9] (for more details see AsyncTaskMethodBuilder<T>.GetTaskForResult()). This is confirmed by the following test:
[Test]
publicvoidAsyncTaskBuilderCachesResultingTask()
{
// These values are cached
Assert.AreSame(Foo(-1), Foo(-1));
Assert.AreSame(Foo(8), Foo(8));
// But these are not
Assert.AreNotSame(Foo(9), Foo(9));
Assert.AreNotSame(Foo(int.MaxValue), Foo(int.MaxValue));
async Task<int> Foo(int n) => n;
}
You should not overly rely on this behavior , but it is always pleasant to realize that the creators of the language and the platform are doing everything possible to improve performance by all available means. Task caching is a popular optimization method that also finds application in other areas. For example, the new implementation
Socket in the corefx repo repository makes extensive use of this method and applies cached tasks wherever possible.Optimization number 2: use ValueTask
The optimization method described above only works in a few cases. Therefore, instead of it, we can use
ValueTask<T> (**), a special type of values, similar to the problem; it will not allocate resources if the method is executed synchronously. ValueTask<T>is a distinguishable union Tand Task<T>: if the “value-task” is completed, then the base value will be used. If the baseline is not yet exhausted, then resources will be allocated for the task. This special type helps prevent excessive heap allocation when performing an operation synchronously. To be able to use
ValueTask<T>, you need to change the return type to GetStockPriceForAsync: instead, you Task<decimal>should specify ValueTask<decimal>:publicasync ValueTask<decimal> GetStockPriceForAsync(string companyId)
{
await InitializeMapIfNeededAsync();
return DoGetPriceFromCache(companyId);
}
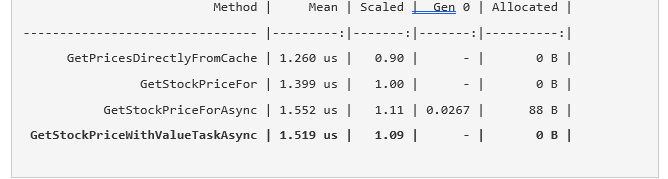
Now we can estimate the difference using the additional benchmark:
[Benchmark]
publicdecimalGetStockPriceWithValueTaskAsync_Await()
{
return _stockPricesThatYield.GetStockPriceValueTaskForAsync("MSFT").GetAwaiter().GetResult();
}
As you can see, the version c
ValueTask is only slightly faster than the version with Task. The main difference is that heap allocation is prevented. In a minute we will discuss the feasibility of such a transition, but before that I would like to tell you about a clever optimization.Optimization number 3: the rejection of asynchronous methods within a common path
If you often use some asynchronous method and want to reduce costs even more, I suggest you the following optimization: remove the async modifier, and then check the state of the task inside the method and perform the entire operation synchronously, completely abandoning the asynchronous approaches.
Looks hard? Consider an example.
public ValueTask<decimal> GetStockPriceWithValueTaskAsync_Optimized(string companyId)
{
var task = InitializeMapIfNeededAsync();
// Optimizing for acommon case: no async machinery involved.if (task.IsCompleted)
{
returnnew ValueTask<decimal>(DoGetPriceFromCache(companyId));
}
return DoGetStockPricesForAsync(task, companyId);
async ValueTask<decimal> DoGetStockPricesForAsync(Task initializeTask, string localCompanyId)
{
await initializeTask;
return DoGetPriceFromCache(localCompanyId);
}
}
In this case, the method
GetStockPriceWithValueTaskAsync_Optimizeddoes not use a modifier async, therefore, receiving the task from the method InitializeMapIfNeededAsync, it checks the status of its execution. If the task is completed, the method simply uses DoGetPriceFromCacheto get the result immediately. If the initialization task is still running, the method calls a local function and waits for the results. Using a local function is not the only one, but one of the easiest ways. But there is one nuance. In the course of the most natural implementation, the local function will receive the external state (local variable and argument):
public ValueTask<decimal> GetStockPriceWithValueTaskAsync_Optimized2(string companyId)
{
// Oops! This will lead to a closure allocation at the beginning of the method!var task = InitializeMapIfNeededAsync();
// Optimizing for acommon case: no async machinery involved.if (task.IsCompleted)
{
returnnew ValueTask<decimal>(DoGetPriceFromCache(companyId));
}
return DoGetStockPricesForAsync();
async ValueTask<decimal> DoGetStockPricesForAsync()
{
await task;
return DoGetPriceFromCache(companyId);
}
}
But, unfortunately, due to a compiler error, this code will cause closure, even if the method is executed within the framework of a common path. Here is how this method looks from the inside:
public ValueTask<decimal> GetStockPriceWithValueTaskAsync_Optimized(string companyId)
{
var closure = new __DisplayClass0_0()
{
__this = this,
companyId = companyId,
task = InitializeMapIfNeededAsync()
};
if (closure.task.IsCompleted)
{
return ...
}
// The rest of the code
}
As discussed in the article Dissecting the Local Functions in C # (“Truncating Local Functions in C #”), the compiler uses a common instance of closure for all local variables and arguments in a particular area. Consequently, there is some sense in such code generation, but it makes the whole struggle with heap allocation useless.
TIP . Such optimization is a very insidious thing. The advantages are insignificant, and even if you write the correct initial local function, in the course of further changes, you can accidentally get the external state that causes the selection of the heap. You can still resort to optimization if you work with a frequently used library (for example, BCL) in a method that will definitely be used on a loaded portion of code.
Costs associated with waiting for a task
At the moment we have considered only one specific case: the costs of the asynchronous method, which is performed synchronously. This is intentional. The “less” the asynchronous method, the more noticeable are the costs in its overall performance. More detailed asynchronous methods, as a rule, run synchronously and perform a lower workload. And we usually call them more often.
But we need to know about the costs of the asynchronous mechanism when the method “waits” for the completion of an unfulfilled task. To estimate these costs, we will make changes to
InitializeMapIfNeededAsync and will call Task.Yield()even when the cache is initialized:privateasync Task InitializeMapIfNeededAsync()
{
if (_stockPricesCache != null)
{
await Task.Yield();
return;
}
// Old initialization logic
}
Add to our package for comparative testing the following methods:
[Benchmark]
publicdecimalGetStockPriceFor_Await()
{
return _stockPricesThatYield.GetStockPriceFor("MSFT");
}
[Benchmark]
publicdecimalGetStockPriceForAsync_Await()
{
return _stockPricesThatYield.GetStockPriceForAsync("MSFT").GetAwaiter().GetResult();
}
[Benchmark]
publicdecimalGetStockPriceWithValueTaskAsync_Await()
{
return _stockPricesThatYield.GetStockPriceValueTaskForAsync("MSFT").GetAwaiter().GetResult();
}
As you can see, the difference is palpable - both in terms of speed and in terms of memory usage. We briefly explain the results.
- Each await operation for an unfinished task runs approximately 4 microseconds and allocates nearly 300 bytes (**) for each call. That is why GetStockPriceFor runs almost twice as fast as GetStockPriceForAsync and allocates less memory.
- An asynchronous method based on ValueTask takes a little longer than the Task option when this method is not executed synchronously. A state machine based on ValueTask <T> must store more data than a state machine based on Task <T>.
(**) It depends on the platform (x64 or x86) and a number of local variables and arguments of the asynchronous method.
Productivity of asynchronous methods 101
- If the asynchronous method runs synchronously, the costs are quite small.
- If the asynchronous method runs synchronously, the following memory overheads arise: there are no costs for the async Task methods, and the async Task <T> methods have an overrun of 88 bytes per operation (for x64 platforms).
- ValueTask <T> eliminates the above costs for asynchronous methods that are performed synchronously.
- When an asynchronous method based on ValueTask <T> is performed synchronously, it takes a little less time than the method with Task <T>, otherwise there are slight differences in favor of the second option.
- The performance cost for asynchronous methods that are waiting for an unfinished task is much higher (approximately 300 bytes per operation for x64 platforms).
Of course, measurements are our everything. If you see that an asynchronous operation causes performance problems, you can switch from
Task<T>to ValueTask<T>, cache the task, or make the common execution path synchronous, if possible. You can also try to consolidate your asynchronous operations. This will help improve performance, simplify debugging and code analysis in general. Not every small piece of code should be asynchronous.