About Amazon Clouds and MPLS Transport
During the development of one project based on Amazon's cloud services, I had to face one problem, which could not be found in the public domain - significant delays in accessing the Amazon RDS service. However, to help me deal with it, I was helped by knowledge of the technology of data transfer that I received while working in one industry research institute.
So, first the diagnosis of the patient. An IT system with a client application is being developed. The system is a server that is hosted in the Amazon cloud as an EC2 service. This server interacts with the MySQL database, which is located in the same region (US-west) on the RDS (Relational Database Service) service. A mobile application interacts with the server, which registers through the server and downloads some data. During the operation of this application, communication errors are often observed, to which the application displays a popup with the words Connection Error. However, users complain about the slow operation of the application. This situation arises among users both in the USA and in Russia.
Transferring the entire system to independent hosting (the most common, cheap) led to a noticeably faster application work, and the absence of Amazon RDS delays. A search in various forums did not give an answer about the reasons for this behavior.
To collect the time characteristics of the process of interaction between the application and the server and the database, a script was written that made a query to the MySQL database 10 times in a row. To eliminate the cache situation of the query, the SQL_NO_CACHE statement was added to the query. However, the database does not cache such a SELECT query. The request and measurement of its duration is carried out by the following function, which measures the duration of the transaction taking into account network delay.
This script was uploaded to Russian hosting, and launched. The result is as follows (script - Russia, DBMS - Amazon RDS, California).
For comparison - the same thing, but from a different hosting site - in France (script - France, DBMS - Amazon RDS, California).
This situation was extremely surprising, and made me delve into the reference information about caching SQL queries. But all the research said one thing - the script was written correctly. The situation was interesting. Everything seems to be understandable, but the very small thing is not clear: a) what is happening, and b) how to at least formulate a request for support?
Good. The next experiment is to run this script locally, on a server in the same Amazon data center in California. Surely the servers are physically nearby, and everything should happen very quickly. We try (script and DBMS - Amazon AWS, California).
The delays decreased significantly, but overall the picture is the same - the first request is executed many times longer than the subsequent ones. And I think that this is the reason for all the problems with the final application. After all, the application exchanges information with the server “in one request”, which just falls on this longest operation. Accordingly, it is this operation that determines the entire “inhibition” of the application.
To check what is still interfering, the database was migrated from Amazon RDS to a separate hosting (the cheapest). And here a small surprise awaited - equal speed of the first and subsequent transactions (script - Russia, DBMS - low-cost hosting in the USA).
I’m a little distracted - the best situation was when the server itself was installed on this weak hosting, in general (the script and the DBMS are the same inexpensive hosting in the USA).
Here you can notice a similar situation, but in units of milliseconds the delays of the OS, and not the network, are already taking effect. Therefore, you should not pay attention to this.
But back to our situation. For the purity of the experiment, they did another test - they launched a script from this cheap hosting on Amazon RDS. The result is again a long first transaction (script - US hosting, DBMS - Amazon RDS, California).
Neither I nor the developers on the Internet could find any analogues to such oddities. However, meanwhile, looking at these figures, I began to lay a vague suspicion that the situation was caused not by the settings of IT systems, but by the peculiarity of data transfer in the IP transport network that connects Amazon data centers.
The considerations below are just my assumptions, in which the timings shown above are quite logical. However, I do not have full confidence in this, and maybe the reasons for the big delay are different, and they lie afloat. It would be interesting to hear alternative opinions.
So, in the telecommunication world, the basis of all communication networks is the transport layer formed by the IP protocol. To transmit IP packets through many intermediate routers, two methods are generally used, routing and switching.
What is routing? Suppose there are four network nodes. From the first to the second, an IP packet is transmitted. How to determine where to direct it - to node 3 or 4? Node 2 looks inside the routing table, looks for the destination address (Ethernet port), and transmits the packet - in the figure, to node 4 (with the address 48.136.23.03).
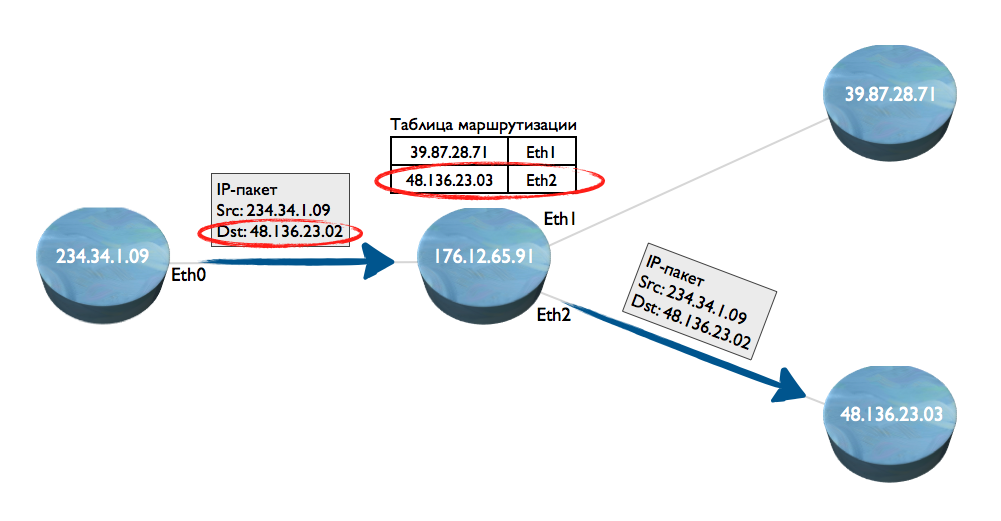
The disadvantages of this method are the low packet routing speed for the following reasons: a) you need to parse millions of IP packets and extract an address from them, b) you need to run each packet in a database (routing table), where the IP address corresponds to the Ethernet network interface number.
In large networks, the Tier 1 operator class, this simply requires incredible processor resources and still, each router introduces a delay.
To avoid this, MPLS (Multiprotocol Label Switching) technology was invented. In common parlance, packet switching. How does she work? Let's say the transmission of the first packet has begun. On node 1, over the IP address, a label was added to the packet. A label is a 4-byte integer that is easily and quickly processed by processors. Such a packet got to node 2. Node 2 on the routing table determines in the way described above that it should be sent to node 3. At the same time, a table is created on node 2, in which the label corresponds to the Eternet interface, which looks towards node 4.
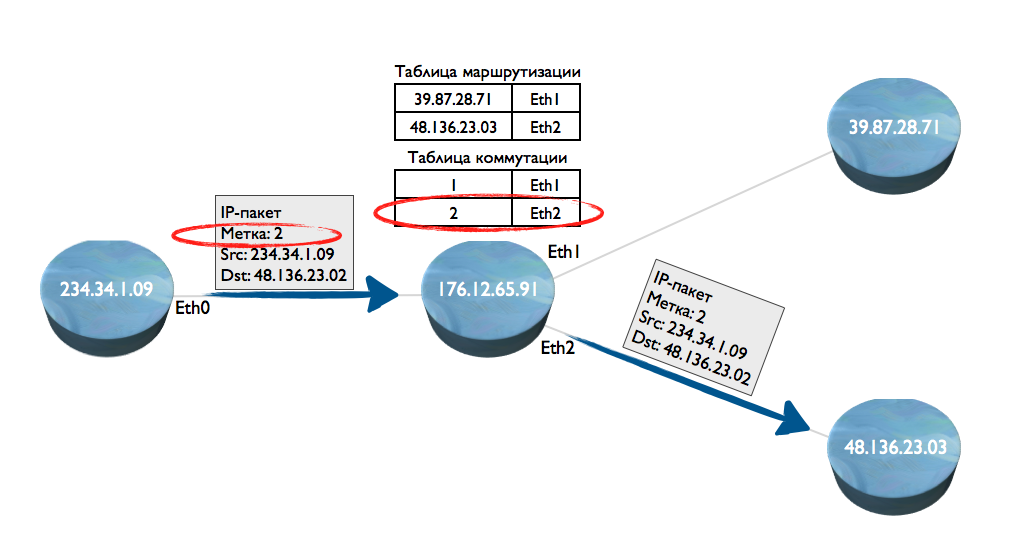
Next, host 1 sends a second IP packet, and adds the same label to it that was set for the first IP packet. When such a packet arrives at node 2, the node will no longer process the IP address and look for it in the routing table. It will immediately extract the label, and check whether there is an output interface for it.
In fact, due to the construction of such switching tables on each intermediate node, a “tunnel” is built along which further data transmission is carried out, without using routing tables.
The advantages of this method are a significant reduction in network latency.
And now the main thing ...
Minus - the first packets are transmitted by the routing method, building a “tunnel” of labels behind them, and only the next packets are already transmitted quickly. It is this picture that we observe above. It is unlikely that a cheap hoster has MPLS equipment. As a result, we see the same duration of the first and subsequent requests. But in Amazon, it seems that the MPLS protocol is just manifesting itself - sending the first request takes 3-5 times longer than subsequent ones.
I think this is precisely the reason for the unstable and long interaction of the application with the database. Although, if the exchange with the database was more intense, then most likely, after 3-4 requests, Amazon would overtake the cheap hosting. It is paradoxical that a technology designed to significantly accelerate data transfer, in my particular case, leads to unstable operation of the system as a whole.
If we take this version as a working one, the question arises - what about the others? After all, large customers work on Amazon, social networks, and do not experience such problems. A fair question, for which I do not have an exact answer. However, there are some considerations.
In any case, I have no other explanation for the situation.
But there is a solution. Three weeks ago, the system was migrated to the Canadian dedicated servers of the OVH hosting provider. The problem was solved on this: everything worked noticeably faster and no one else saw Connection Error.
So, first the diagnosis of the patient. An IT system with a client application is being developed. The system is a server that is hosted in the Amazon cloud as an EC2 service. This server interacts with the MySQL database, which is located in the same region (US-west) on the RDS (Relational Database Service) service. A mobile application interacts with the server, which registers through the server and downloads some data. During the operation of this application, communication errors are often observed, to which the application displays a popup with the words Connection Error. However, users complain about the slow operation of the application. This situation arises among users both in the USA and in Russia.
Transferring the entire system to independent hosting (the most common, cheap) led to a noticeably faster application work, and the absence of Amazon RDS delays. A search in various forums did not give an answer about the reasons for this behavior.
To collect the time characteristics of the process of interaction between the application and the server and the database, a script was written that made a query to the MySQL database 10 times in a row. To eliminate the cache situation of the query, the SQL_NO_CACHE statement was added to the query. However, the database does not cache such a SELECT query. The request and measurement of its duration is carried out by the following function, which measures the duration of the transaction taking into account network delay.
function query_execute ($link)
{
$time = microtime (true);
$res = mysqli_query ($link, «SELECT SQL_NO_CACHE ui.* FROM `user_item_id` ui INNER JOIN `users` u ON u.`user_id`=ui.`user_id` WHERE u.`username`='any@user.com';»);
return array («rows» => mysqli_num_rows ($res), «time» => sprintf («%4f», microtime (true) — $time));
}
This script was uploaded to Russian hosting, and launched. The result is as follows (script - Russia, DBMS - Amazon RDS, California).
Start time to aws measure
rows: 10, duration: 2.659313
rows: 10, duration: 0.594934
rows: 10, duration: 0.595982
rows: 10, duration: 0.594558
rows: 10, duration: 0.397052
rows: 10, duration: 0.399988
rows: 10 , duration: 0.399615
rows: 10, duration: 0.396856
rows: 10, duration: 0.399138
rows: 10, duration: 0.396113
- Average duration: 0.6833549
For comparison - the same thing, but from a different hosting site - in France (script - France, DBMS - Amazon RDS, California).
Start time to aws measure
rows: 14, duration: 1.980444
rows: 14, duration: 0.472865
rows: 14, duration: 0.318233
rows: 14, duration: 0.417172
rows: 14, duration: 0.342588
rows: 14, duration: 0.303614
rows: 14 , duration: 0.908241
rows: 14, duration: 1.809397
rows: 14, duration: 0.497458
rows: 14, duration: 0.316923
- Average duration: 0.7366935
This situation was extremely surprising, and made me delve into the reference information about caching SQL queries. But all the research said one thing - the script was written correctly. The situation was interesting. Everything seems to be understandable, but the very small thing is not clear: a) what is happening, and b) how to at least formulate a request for support?
Good. The next experiment is to run this script locally, on a server in the same Amazon data center in California. Surely the servers are physically nearby, and everything should happen very quickly. We try (script and DBMS - Amazon AWS, California).
Start time to aws measure
rows: 10, duration: 0.024818
rows: 10, duration: 0.009796
rows: 10, duration: 0.006747
rows: 10, duration: 0.005163
rows: 10, duration: 0.007998
rows: 10, duration: 0.006088
rows: 10 , duration: 0.009614
rows: 10, duration: 0.007938
rows: 10, duration: 0.008052
rows: 10, duration: 0.007804
- average duration: 0.0094018
The delays decreased significantly, but overall the picture is the same - the first request is executed many times longer than the subsequent ones. And I think that this is the reason for all the problems with the final application. After all, the application exchanges information with the server “in one request”, which just falls on this longest operation. Accordingly, it is this operation that determines the entire “inhibition” of the application.
To check what is still interfering, the database was migrated from Amazon RDS to a separate hosting (the cheapest). And here a small surprise awaited - equal speed of the first and subsequent transactions (script - Russia, DBMS - low-cost hosting in the USA).
Start time to linode measure
rows: 10, duration: 0.018506
rows: 10, duration: 0.017285
rows: 10, duration: 0.011917
rows: 10, duration: 0.011928
rows: 10, duration: 0.027923
rows: 10, duration: 0.011141
rows: 10 , duration: 0.072708
rows: 10, duration: 0.011934
rows: 10, duration: 0.007816
rows: 10, duration: 0.008045
- average duration: 0.0199203
I’m a little distracted - the best situation was when the server itself was installed on this weak hosting, in general (the script and the DBMS are the same inexpensive hosting in the USA).
Start time to linode measure
rows: 10, duration: 0.008159
rows: 10, duration: 0.000344
rows: 10, duration: 0.000317
rows: 10, duration: 0.000309
rows: 10, duration: 0.000269
rows: 10, duration: 0.000282
rows: 10 , duration: 0.000260
rows: 10, duration: 0.000263
rows: 10, duration: 0.000303
rows: 10, duration: 0.000297
- Average duration: 0.0010803
Here you can notice a similar situation, but in units of milliseconds the delays of the OS, and not the network, are already taking effect. Therefore, you should not pay attention to this.
But back to our situation. For the purity of the experiment, they did another test - they launched a script from this cheap hosting on Amazon RDS. The result is again a long first transaction (script - US hosting, DBMS - Amazon RDS, California).
Start time to aws measure
rows: 10, duration: 0.098134
rows: 10, duration: 0.016168
rows: 10, duration: 0.011697
rows: 10, duration: 0.007868
rows: 10, duration: 0.008148
rows: 10, duration: 0.010468
rows: 10 , duration: 0.033403
rows: 10, duration: 0.011947
rows: 10, duration: 0.012217
rows: 10, duration: 0.008185
- average duration: 0.0218235
Neither I nor the developers on the Internet could find any analogues to such oddities. However, meanwhile, looking at these figures, I began to lay a vague suspicion that the situation was caused not by the settings of IT systems, but by the peculiarity of data transfer in the IP transport network that connects Amazon data centers.
The considerations below are just my assumptions, in which the timings shown above are quite logical. However, I do not have full confidence in this, and maybe the reasons for the big delay are different, and they lie afloat. It would be interesting to hear alternative opinions.
So, in the telecommunication world, the basis of all communication networks is the transport layer formed by the IP protocol. To transmit IP packets through many intermediate routers, two methods are generally used, routing and switching.
What is routing? Suppose there are four network nodes. From the first to the second, an IP packet is transmitted. How to determine where to direct it - to node 3 or 4? Node 2 looks inside the routing table, looks for the destination address (Ethernet port), and transmits the packet - in the figure, to node 4 (with the address 48.136.23.03).
The disadvantages of this method are the low packet routing speed for the following reasons: a) you need to parse millions of IP packets and extract an address from them, b) you need to run each packet in a database (routing table), where the IP address corresponds to the Ethernet network interface number.
In large networks, the Tier 1 operator class, this simply requires incredible processor resources and still, each router introduces a delay.
To avoid this, MPLS (Multiprotocol Label Switching) technology was invented. In common parlance, packet switching. How does she work? Let's say the transmission of the first packet has begun. On node 1, over the IP address, a label was added to the packet. A label is a 4-byte integer that is easily and quickly processed by processors. Such a packet got to node 2. Node 2 on the routing table determines in the way described above that it should be sent to node 3. At the same time, a table is created on node 2, in which the label corresponds to the Eternet interface, which looks towards node 4.
Next, host 1 sends a second IP packet, and adds the same label to it that was set for the first IP packet. When such a packet arrives at node 2, the node will no longer process the IP address and look for it in the routing table. It will immediately extract the label, and check whether there is an output interface for it.
In fact, due to the construction of such switching tables on each intermediate node, a “tunnel” is built along which further data transmission is carried out, without using routing tables.
The advantages of this method are a significant reduction in network latency.
And now the main thing ...
Minus - the first packets are transmitted by the routing method, building a “tunnel” of labels behind them, and only the next packets are already transmitted quickly. It is this picture that we observe above. It is unlikely that a cheap hoster has MPLS equipment. As a result, we see the same duration of the first and subsequent requests. But in Amazon, it seems that the MPLS protocol is just manifesting itself - sending the first request takes 3-5 times longer than subsequent ones.
I think this is precisely the reason for the unstable and long interaction of the application with the database. Although, if the exchange with the database was more intense, then most likely, after 3-4 requests, Amazon would overtake the cheap hosting. It is paradoxical that a technology designed to significantly accelerate data transfer, in my particular case, leads to unstable operation of the system as a whole.
If we take this version as a working one, the question arises - what about the others? After all, large customers work on Amazon, social networks, and do not experience such problems. A fair question, for which I do not have an exact answer. However, there are some considerations.
- The application I'm writing about is now version 1.0. Most likely, and even for sure, we now have a suboptimal database query structure. In the future, it will be optimized, and due to this we will get a gain in speed. But now, it seems, one has overlapped with the other.
- Assuming that large social networks are based on Amazon is still strange. Most likely, the architecture of such systems is geographically distributed, and information can only asynchronously flock to Amazon data centers. At least, the tracing from Moscow Facebook shows the Irish server as the end point, Twitter - some site of its own, Pinterest - on the Telia network and so on.
- Between large nodes of social networks, static routes are most likely preinstalled.
In any case, I have no other explanation for the situation.
But there is a solution. Three weeks ago, the system was migrated to the Canadian dedicated servers of the OVH hosting provider. The problem was solved on this: everything worked noticeably faster and no one else saw Connection Error.