Python is slow. Why?
- Transfer
Recently, one can observe the growing popularity of the Python programming language. It is used in DevOps, data analysis, web development, security, and other areas. But here's the speed ... Here, this language has nothing to boast of. The author of the material, the translation of which we are publishing today, decided to find out the reasons for the sluggishness of Python and find the means to accelerate it.

How does Java, in terms of performance, relate to C or C ++? How to compare C # and Python? Answers to these questions seriously depend on the type of applications analyzed by the researcher. There is no perfect benchmark, but studying the performance of programs written in different languages can be a good starting point for the project The Computer Language Benchmarks Game.
I refer to The Computer Language Benchmarks Game for more than ten years. Python, in comparison with other languages such as Java, C #, Go, JavaScript, C ++, is one of the slowest . This includes languages that use JIT compilation (C #, Java), and AOT compilation (C, C ++), as well as interpreted languages such as JavaScript.
Here I would like to note that saying “Python”, I mean the reference implementation of the Python interpreter - CPython. In this material we will touch on its other implementations. In fact, here I want to find the answer to the question of why Python takes 2-10 times more time than other languages to solve comparable tasks, and whether it can be done faster.
Here are the main theories trying to explain the reasons behind Python's slow work:
Let us analyze these ideas and try to find the answer to the question of what has the greatest impact on the performance of Python applications.
Modern computers have multi-core processors, and sometimes multi-processor systems are also found. In order to use all this computing power, the operating system uses low-level structures, called threads, while processes (for example, the Chrome browser process) can run multiple threads and use them accordingly. As a result, for example, if a process is particularly in need of processor resources, its execution can be divided among several cores, which allows most applications to quickly solve the problems they face.
For example, my Chrome browser, at the moment when I write this, has 44 open threads. It is worth considering here that the structure and API of the threading system differs in operating systems based on Posix (Mac OS, Linux) and in the Windows operating system family. The operating system is also involved in scheduling work flows.
If you have never met with multithreaded programming, now you need to get acquainted with the so-called locks. The meaning of locks is that they provide the system behavior when, in a multi-threaded environment, for example, when a variable in a memory changes, access to the same memory area (for reading or change) cannot receive several threads simultaneously.
When the CPython interpreter creates variables, it allocates memory, and then counts the number of existing references to these variables. This concept is known as reference counting. If the number of links equals zero, then the corresponding section of memory is freed. That is why, for example, creating “temporary” variables, say, within the scope of cycles, does not lead to an excessive increase in the amount of memory consumed by the application.
The most interesting thing begins when several threads share the same variables, and the main problem here is how CPython performs reference counting. This is where the “global interpreter blocking” action manifests itself, which carefully controls the execution of threads.
An interpreter can perform only one operation at a time, no matter how many threads there are in the program.
If we have a single-threaded application running in the same Python interpreter process, then GIL does not affect performance in any way. If, for example, get rid of GIL, we will not notice any difference in performance.
If, within the same Python interpreter process, you need to implement parallel data processing using multi-threading mechanisms, and the threads used will heavily use an I / O subsystem (for example, if they work with a network or with a disk), then you can observe the consequences how GIL manages threads. Here is how it looks in the case of using two threads, intensively loading processes.

Visualizing GIL work (taken from here )
If you have a web application (for example, based on the Django framework) and you use WSGI, then each request to the web application will be serviced by a separate Python interpreter process, that is, we have only 1 lock on request. Since the Python interpreter starts slowly, some implementations of WSGI have a so-called “daemon mode”, using which the interpreter processes are maintained in a working state, which allows the system to serve requests faster.
In PyPy there GIL, it is usually more than 3 times faster than CPython.
In Jython no GIL, since Python Jython flows are presented in the form of Java threads. Such threads use JVM memory management capabilities.
If we talk about JavaScript, then, first of all, it should be noted that all JS-engines use mark-and-sweep garbage collection algorithm . As already mentioned, the main reason for using GIL is the memory management algorithm used in CPython.
There is no GIL in JavaScript, however, JS is a single-threaded language, so there is no need for such a mechanism in it. Instead of parallel code execution in JavaScript, asynchronous programming techniques are used, based on the event loop, promises and callbacks. In Python, there is something similar represented by the module
I have often heard that the poor Python performance is due to the fact that it is an interpreted language. Such statements are based on a crude simplification of how CPython actually works. If, in the terminal, enter a command like
For us, when considering this process, it is especially important that here, at the compilation stage, a
This applies not only to the scripts we have written, but also to the imported code, including third-party modules.
As a result, most of the time (unless you write code that runs only once) Python is doing the execution of the finished bytecode. If we compare this with what is happening in Java and in C #, it turns out that Java code is compiled into “Intermediate Language”, and the Java virtual machine reads the byte code and performs its JIT compilation into machine code. The “intermediate language” .NET CIL (this is the same as the .NET Common-Language-Runtime, CLR) uses JIT compilation to go to the machine code.
As a result, both in Java and in C # some "intermediate language" is used and there are similar mechanisms. Why, then, does Python show much worse results in benchmarks than Java and C #, if all these languages use virtual machines and some kinds of bytecode? First of all - due to the fact that in .NET and in Java JIT-compilation is used.
JIT compilation (Just In Time compilation, “on-the-fly” or “just-in-time” compilation) requires an intermediate language in order to allow code breaking into fragments (frames). AOT-compilation systems (Ahead Of Time compilation, compilation before execution) are designed to ensure that the code is fully operational before the interaction of this code with the system begins.
By itself, the use of JIT does not speed up the execution of the code, since, as in Python, some bytecode fragments arrive at execution. However, JIT allows you to perform code optimizations during its execution. A good JIT optimizer is able to identify the most loaded parts of an application (such a part of an application is called a “hot spot”) and optimize the corresponding code fragments, replacing them with optimized and more efficient variants than those used previously.
This means that when an application again and again performs certain actions, such optimization can significantly speed up the execution of such actions. In addition, do not forget that Java and C # are languages with strong typing, so the optimizer can make more code for the assumptions that can improve program performance.
The JIT compiler is in PyPy, and, as already mentioned, this implementation of the Python interpreter is much faster than CPython. Details regarding the comparison of different Python interpreters can be found in this article.
JIT compilers have drawbacks. One of them is launch time. CPython is already relatively slow to launch, and PyPy is 2-3 times slower than CPython. The long launch time of a JVM is also a well-known fact. The .NET CLR bypasses this problem, starting up during the boot process, but here it should be noted that both the CLR and the operating system in which the CLR runs are developed by the same company.
If you have one Python process that runs for a long time, while in such a process there is code that can be optimized, since it contains heavily used areas, then you should seriously look at the interpreter that has the JIT compiler.
However, CPython is an implementation of a general-purpose Python interpreter. Therefore, if you are developing, using Python, a command line application, then the need to wait a long time for the JIT compiler to run every time you start this application will slow down greatly.
CPython is trying to provide support for as many Python usage options as possible. For example, there is the possibility of connecting the JIT compiler to Python, however, the project , in which this idea is implemented, is not developing very actively.
As a result, you can say that if you, using Python, write a program whose performance can improve with the JIT compiler, use the PyPy interpreter.
In statically typed languages, when declaring variables, it is necessary to specify their types. Among such languages are C, C ++, Java, C #, Go.
In dynamically typed languages, the concept of a data type has the same meaning, but the type of a variable is dynamic.
In this simplest example, Python first creates the first variable
It may seem that writing in languages with dynamic typing is more convenient and easier than in languages with static typing, however, such languages are not created by whim. In their development, the features of computer systems are taken into account. Everything that is written in the text of the program, as a result, comes down to the processor instructions. This means that the data used by the program, for example, in the form of objects or other types of data, is also converted to low-level structures.
Python performs such conversions automatically, the programmer does not see these processes, and he does not need to take care of such conversions.
The absence of the need to specify the type of a variable when it is declared is not a feature of the language that makes Python slow. The architecture of the language allows you to make almost anything dynamic. For example, at run time, you can replace the methods of objects. Again, during the execution of the program, you can use the technique of "monkey patches" as applied to low-level system calls. In Python, almost everything is possible.
It is the Python architecture that makes it extremely difficult to optimize.
In order to illustrate this idea, I'm going to use a tool for tracing system calls in MacOS, which is called DTrace.
There is no DTrace support mechanism in the finished CPython distribution, so CPython will need to be recompiled with the appropriate settings. Version 3.6.6 is used here. So, we use the following sequence of actions:
Now, using it
But how the tracing tool
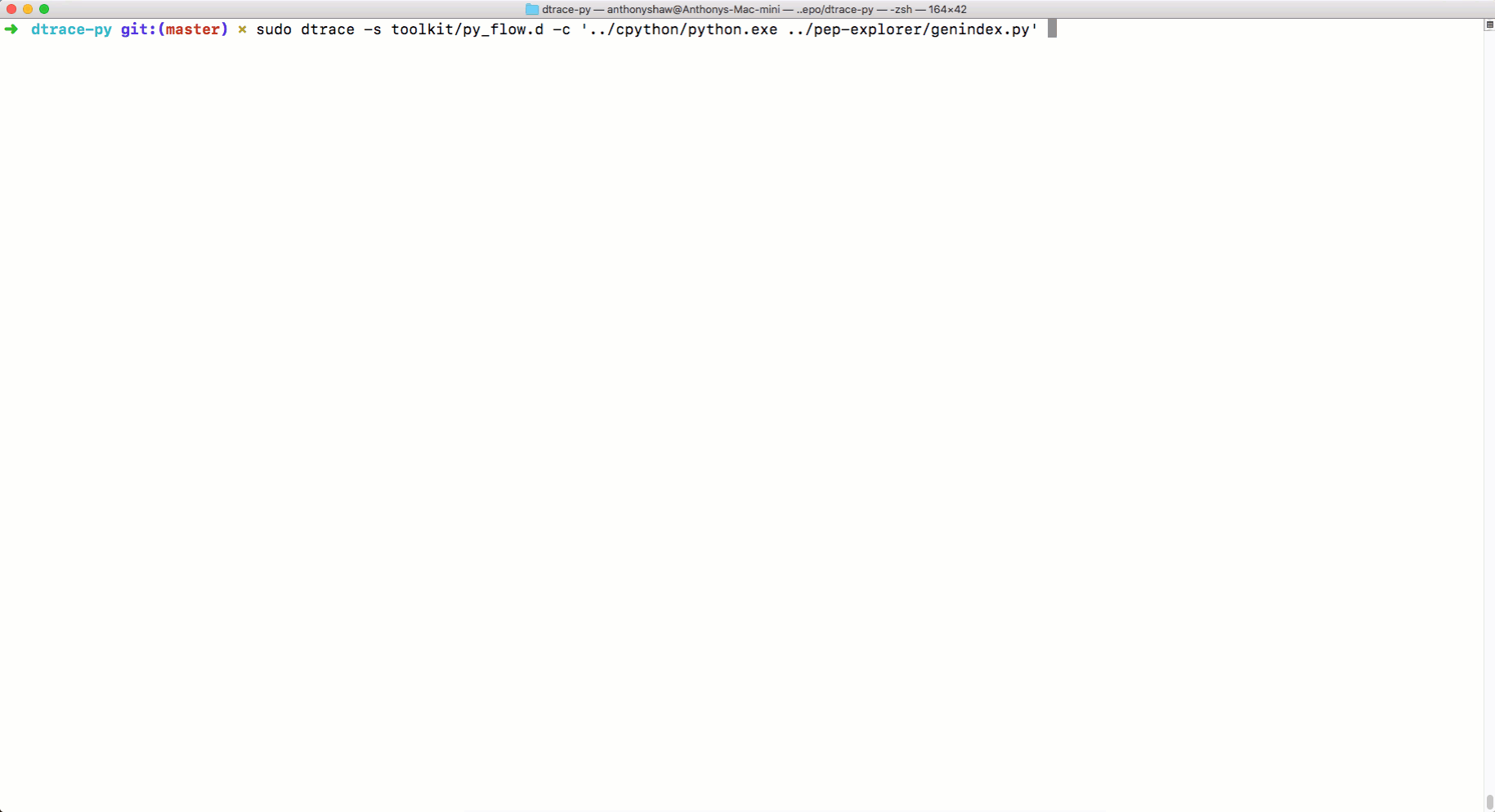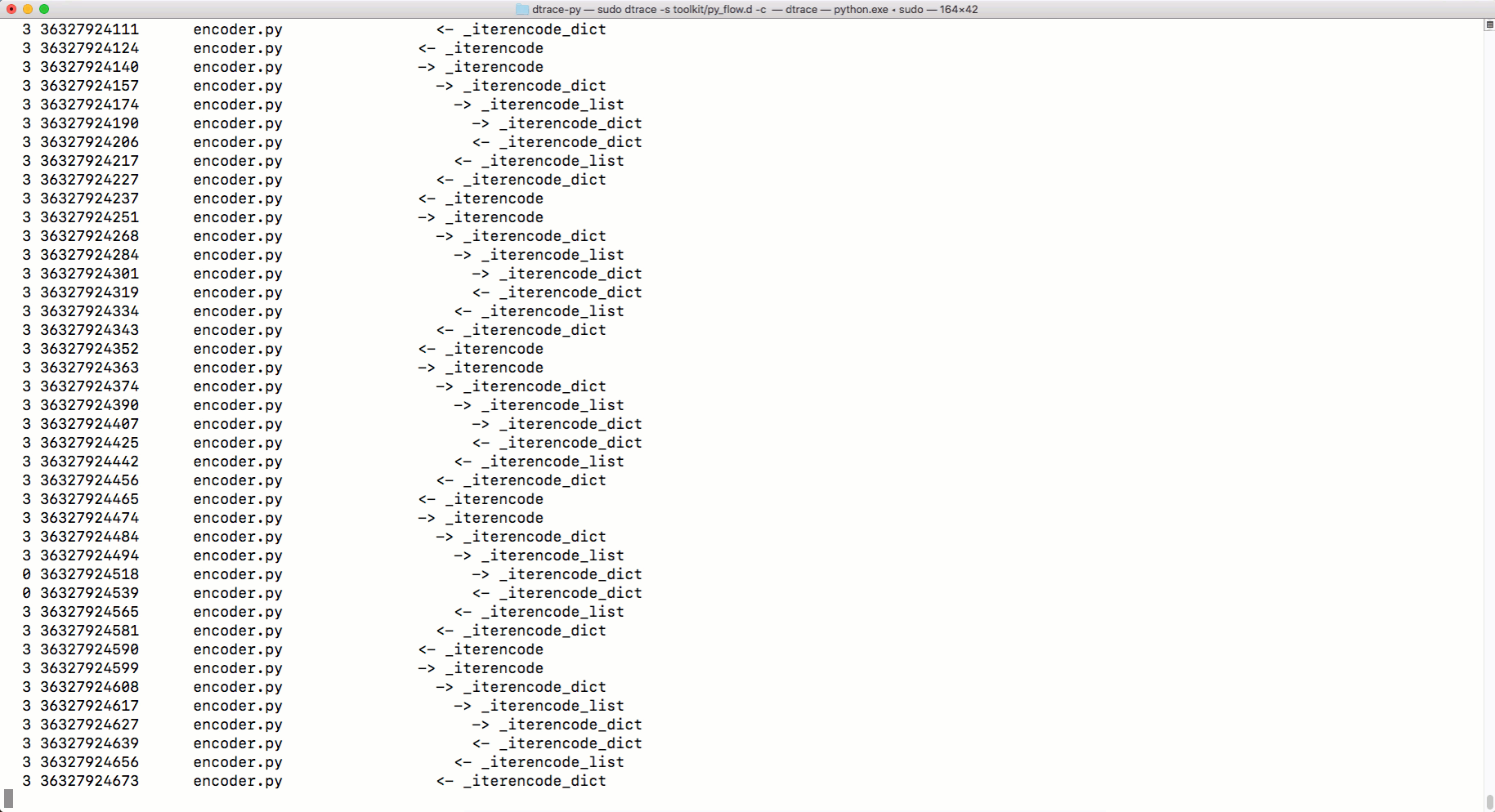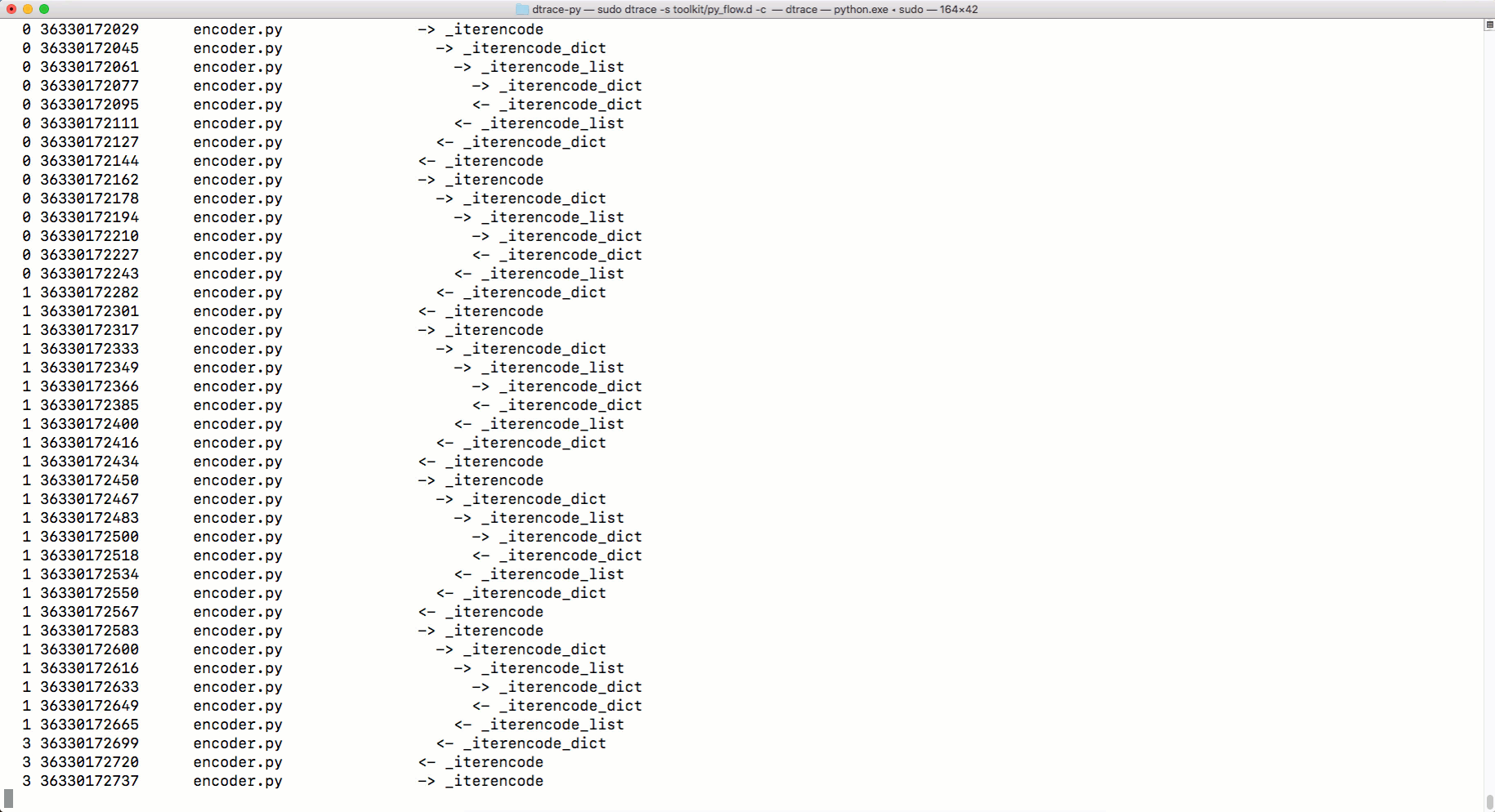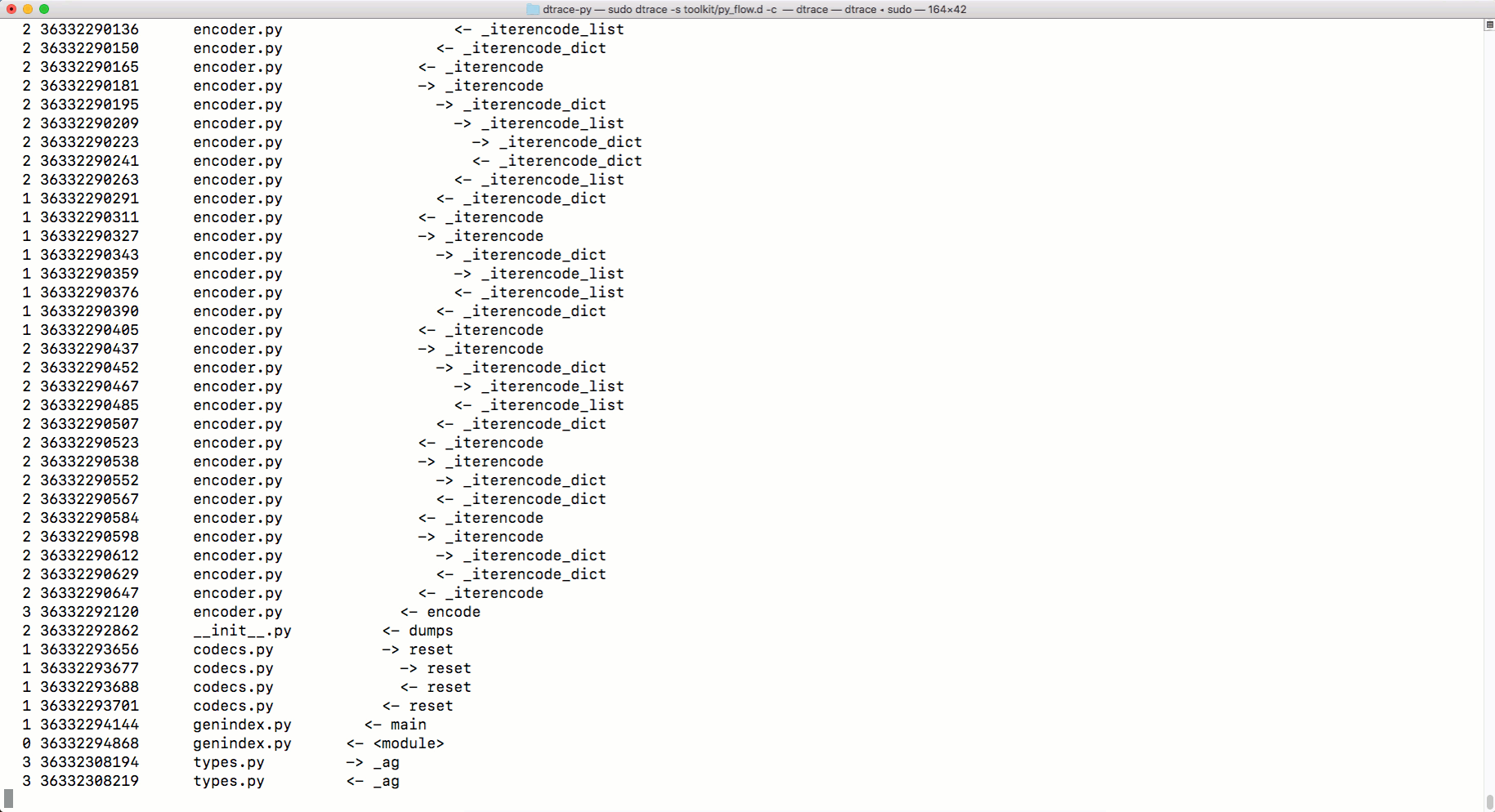
Tracing with DTrace
Now let's answer the question of whether dynamic typing affects Python performance. Here are some thoughts on this:
The reason for the poor performance of Python is its dynamic nature and versatility. It can be used as a tool for solving various tasks. To achieve the same goals, you can try to search for more productive, better optimized tools. Perhaps it will be possible to find them, perhaps not.
Applications written in Python can be optimized using the capabilities of asynchronous code execution, profiling tools, and by choosing the right interpreter. So, in order to optimize the speed of applications that run without any importance, and whose performance can benefit from using the JIT compiler, consider using PyPy. If you need maximum performance and are ready for the limitations of static typing, take a look at Cython.
Dear readers! How do you solve poor Python performance problems?

General provisions
How does Java, in terms of performance, relate to C or C ++? How to compare C # and Python? Answers to these questions seriously depend on the type of applications analyzed by the researcher. There is no perfect benchmark, but studying the performance of programs written in different languages can be a good starting point for the project The Computer Language Benchmarks Game.
I refer to The Computer Language Benchmarks Game for more than ten years. Python, in comparison with other languages such as Java, C #, Go, JavaScript, C ++, is one of the slowest . This includes languages that use JIT compilation (C #, Java), and AOT compilation (C, C ++), as well as interpreted languages such as JavaScript.
Here I would like to note that saying “Python”, I mean the reference implementation of the Python interpreter - CPython. In this material we will touch on its other implementations. In fact, here I want to find the answer to the question of why Python takes 2-10 times more time than other languages to solve comparable tasks, and whether it can be done faster.
Here are the main theories trying to explain the reasons behind Python's slow work:
- The reason for this is in GIL (Global Interpreter Lock, global interpreter lock).
- The reason is that Python is an interpretable, not a compiled language.
- The reason is dynamic typing.
Let us analyze these ideas and try to find the answer to the question of what has the greatest impact on the performance of Python applications.
GIL
Modern computers have multi-core processors, and sometimes multi-processor systems are also found. In order to use all this computing power, the operating system uses low-level structures, called threads, while processes (for example, the Chrome browser process) can run multiple threads and use them accordingly. As a result, for example, if a process is particularly in need of processor resources, its execution can be divided among several cores, which allows most applications to quickly solve the problems they face.
For example, my Chrome browser, at the moment when I write this, has 44 open threads. It is worth considering here that the structure and API of the threading system differs in operating systems based on Posix (Mac OS, Linux) and in the Windows operating system family. The operating system is also involved in scheduling work flows.
If you have never met with multithreaded programming, now you need to get acquainted with the so-called locks. The meaning of locks is that they provide the system behavior when, in a multi-threaded environment, for example, when a variable in a memory changes, access to the same memory area (for reading or change) cannot receive several threads simultaneously.
When the CPython interpreter creates variables, it allocates memory, and then counts the number of existing references to these variables. This concept is known as reference counting. If the number of links equals zero, then the corresponding section of memory is freed. That is why, for example, creating “temporary” variables, say, within the scope of cycles, does not lead to an excessive increase in the amount of memory consumed by the application.
The most interesting thing begins when several threads share the same variables, and the main problem here is how CPython performs reference counting. This is where the “global interpreter blocking” action manifests itself, which carefully controls the execution of threads.
An interpreter can perform only one operation at a time, no matter how many threads there are in the program.
▍How does GIL affect Python application performance?
If we have a single-threaded application running in the same Python interpreter process, then GIL does not affect performance in any way. If, for example, get rid of GIL, we will not notice any difference in performance.
If, within the same Python interpreter process, you need to implement parallel data processing using multi-threading mechanisms, and the threads used will heavily use an I / O subsystem (for example, if they work with a network or with a disk), then you can observe the consequences how GIL manages threads. Here is how it looks in the case of using two threads, intensively loading processes.
Visualizing GIL work (taken from here )
If you have a web application (for example, based on the Django framework) and you use WSGI, then each request to the web application will be serviced by a separate Python interpreter process, that is, we have only 1 lock on request. Since the Python interpreter starts slowly, some implementations of WSGI have a so-called “daemon mode”, using which the interpreter processes are maintained in a working state, which allows the system to serve requests faster.
▍ How do other Python interpreters behave?
In PyPy there GIL, it is usually more than 3 times faster than CPython.
In Jython no GIL, since Python Jython flows are presented in the form of Java threads. Such threads use JVM memory management capabilities.
▍ How is flow control organized in javascript?
If we talk about JavaScript, then, first of all, it should be noted that all JS-engines use mark-and-sweep garbage collection algorithm . As already mentioned, the main reason for using GIL is the memory management algorithm used in CPython.
There is no GIL in JavaScript, however, JS is a single-threaded language, so there is no need for such a mechanism in it. Instead of parallel code execution in JavaScript, asynchronous programming techniques are used, based on the event loop, promises and callbacks. In Python, there is something similar represented by the module
asyncio.Python - Interpretable Language
I have often heard that the poor Python performance is due to the fact that it is an interpreted language. Such statements are based on a crude simplification of how CPython actually works. If, in the terminal, enter a command like
python myscript.py, then CPython will start a long sequence of actions, which consists in reading, lexical analysis, parsing, compiling, interpreting and executing the script code. If you are interested in the details - take a look at this material. For us, when considering this process, it is especially important that here, at the compilation stage, a
.pycfile is created , and a sequence of byte codes is written to a file in a directory __pycache__/that is used in both Python 3 and Python 2.This applies not only to the scripts we have written, but also to the imported code, including third-party modules.
As a result, most of the time (unless you write code that runs only once) Python is doing the execution of the finished bytecode. If we compare this with what is happening in Java and in C #, it turns out that Java code is compiled into “Intermediate Language”, and the Java virtual machine reads the byte code and performs its JIT compilation into machine code. The “intermediate language” .NET CIL (this is the same as the .NET Common-Language-Runtime, CLR) uses JIT compilation to go to the machine code.
As a result, both in Java and in C # some "intermediate language" is used and there are similar mechanisms. Why, then, does Python show much worse results in benchmarks than Java and C #, if all these languages use virtual machines and some kinds of bytecode? First of all - due to the fact that in .NET and in Java JIT-compilation is used.
JIT compilation (Just In Time compilation, “on-the-fly” or “just-in-time” compilation) requires an intermediate language in order to allow code breaking into fragments (frames). AOT-compilation systems (Ahead Of Time compilation, compilation before execution) are designed to ensure that the code is fully operational before the interaction of this code with the system begins.
By itself, the use of JIT does not speed up the execution of the code, since, as in Python, some bytecode fragments arrive at execution. However, JIT allows you to perform code optimizations during its execution. A good JIT optimizer is able to identify the most loaded parts of an application (such a part of an application is called a “hot spot”) and optimize the corresponding code fragments, replacing them with optimized and more efficient variants than those used previously.
This means that when an application again and again performs certain actions, such optimization can significantly speed up the execution of such actions. In addition, do not forget that Java and C # are languages with strong typing, so the optimizer can make more code for the assumptions that can improve program performance.
The JIT compiler is in PyPy, and, as already mentioned, this implementation of the Python interpreter is much faster than CPython. Details regarding the comparison of different Python interpreters can be found in this article.
▍ Why not use the JIT compiler in CPython?
JIT compilers have drawbacks. One of them is launch time. CPython is already relatively slow to launch, and PyPy is 2-3 times slower than CPython. The long launch time of a JVM is also a well-known fact. The .NET CLR bypasses this problem, starting up during the boot process, but here it should be noted that both the CLR and the operating system in which the CLR runs are developed by the same company.
If you have one Python process that runs for a long time, while in such a process there is code that can be optimized, since it contains heavily used areas, then you should seriously look at the interpreter that has the JIT compiler.
However, CPython is an implementation of a general-purpose Python interpreter. Therefore, if you are developing, using Python, a command line application, then the need to wait a long time for the JIT compiler to run every time you start this application will slow down greatly.
CPython is trying to provide support for as many Python usage options as possible. For example, there is the possibility of connecting the JIT compiler to Python, however, the project , in which this idea is implemented, is not developing very actively.
As a result, you can say that if you, using Python, write a program whose performance can improve with the JIT compiler, use the PyPy interpreter.
Python - dynamically typed language
In statically typed languages, when declaring variables, it is necessary to specify their types. Among such languages are C, C ++, Java, C #, Go.
In dynamically typed languages, the concept of a data type has the same meaning, but the type of a variable is dynamic.
a = 1
a = "foo"In this simplest example, Python first creates the first variable
a, then the second with the same name and type str, and frees the memory that was allocated to the first variable a. It may seem that writing in languages with dynamic typing is more convenient and easier than in languages with static typing, however, such languages are not created by whim. In their development, the features of computer systems are taken into account. Everything that is written in the text of the program, as a result, comes down to the processor instructions. This means that the data used by the program, for example, in the form of objects or other types of data, is also converted to low-level structures.
Python performs such conversions automatically, the programmer does not see these processes, and he does not need to take care of such conversions.
The absence of the need to specify the type of a variable when it is declared is not a feature of the language that makes Python slow. The architecture of the language allows you to make almost anything dynamic. For example, at run time, you can replace the methods of objects. Again, during the execution of the program, you can use the technique of "monkey patches" as applied to low-level system calls. In Python, almost everything is possible.
It is the Python architecture that makes it extremely difficult to optimize.
In order to illustrate this idea, I'm going to use a tool for tracing system calls in MacOS, which is called DTrace.
There is no DTrace support mechanism in the finished CPython distribution, so CPython will need to be recompiled with the appropriate settings. Version 3.6.6 is used here. So, we use the following sequence of actions:
wget https://github.com/python/cpython/archive/v3.6.6.zip
unzip v3.6.6.zip
cd v3.6.6
./configure --with-dtrace
makeNow, using it
python.exe, you can use DTRace to trace the code. You can read about using DTrace with Python here . And here you can find scripts to measure using DTrace various performance indicators of Python-programs. Among them are the parameters for calling functions, program execution time, processor usage time, information about system calls, and so on. Here is how to use the command dtrace:sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe script.py’But how the tracing tool
py_callflowshows the function calls in the application.Tracing with DTrace
Now let's answer the question of whether dynamic typing affects Python performance. Here are some thoughts on this:
- Type checking and conversion are hard operations. Each time a variable is accessed, read or written, the type is checked.
- A language with such flexibility is difficult to optimize. The reason why other languages are so much faster than Python is because they make some sort of compromise, choosing between flexibility and performance.
- The Cython project combines Python and static typing, which, for example, as shown in this material , results in a 84-fold increase in performance compared to conventional Python. Pay attention to this project if you need speed.
Results
The reason for the poor performance of Python is its dynamic nature and versatility. It can be used as a tool for solving various tasks. To achieve the same goals, you can try to search for more productive, better optimized tools. Perhaps it will be possible to find them, perhaps not.
Applications written in Python can be optimized using the capabilities of asynchronous code execution, profiling tools, and by choosing the right interpreter. So, in order to optimize the speed of applications that run without any importance, and whose performance can benefit from using the JIT compiler, consider using PyPy. If you need maximum performance and are ready for the limitations of static typing, take a look at Cython.
Dear readers! How do you solve poor Python performance problems?