MIT course "Security of computer systems". Lecture 3: "Buffer overflow: exploits and protection", part 2
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems." Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Control of hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
It is interesting that the attacker can not jump to a specific address, despite the fact that we mainly use hard-coded addresses. What he does is called heap attack, and if you are a bad person, then it will be pretty fun for you. With such an attack, the hacker begins to dynamically allocate tons of shell code and simply enter it randomly into memory. This is especially effective if you use dynamically high-level languages such as JavaScript. Thus, the tag reader is in a narrow loop and simply generates a large number of lines of shell code and then fills them with a bunch.
The attacker cannot determine the exact location of the lines, he simply allocates 10 MB lines of shell code and makes a random jump. And if he can somehow control one of the ret pointers , there is a chance that he will "land" in the shell code.

You can use one trick called NOP slide , NOP sled or NOP ramp , where NOP is no-operation instructions , or empty idle commands. This means that the processor's instruction flow “slips” to its final, desired destination whenever the program goes to the memory address anywhere on the slide.
Imagine that if you have a line of shell code and you move to a random place in this line, it may not work, because it does not allow you to deploy the attack in the right way.
But maybe this stuff you put on the pile is basically just a ton of NOP , and at the very end you have the shell code. This is actually quite clever, because it means that now you can actually get to the right place to jump. Because if you jump into another of these NOPs , it’s just “boom, boom, boom, boom, boom, boom, boom”, and then you get into the shell code.
It looks like this is coming up with the people you probably see in our team. They invent something like that, and that's the problem. So this is another way to get around some random things, just making the randomization of your codes sustainable, if that makes sense.
So, we have discussed some types of accidents that you can use. There are some stupid ideas that people also had. So now you know that when you want to make a system call, for example, use the syscall libc function , you basically pass on any unique number representing the system call you want to make. So maybe the fork function is 7, sleep is 8, or something like that.
This means that if an attacker can figure out the address of this syscall instruction and go to it in some way, he or she can actually just substitute the number of the system call that they want to use directly. You can imagine that every time the program is running, you actually create a dynamic assignment of syscall numbers to actual syscalls , in order to make it more difficult for an attacker to capture.

There are even some avant-garde proposals to change the hardware so that the equipment contains the xor encryption key , which is used for the dynamic functions xor. Imagine that every time you compile a program, all instruction codes receive a certain key xor . This key is stored in the hardware register when you initially load the program, and after that, whenever you execute an instruction, the equipment automatically performs an xor operation with it before continuing with this instruction. In this approach, it is good that now, even if the attacker can generate shell code, he does not recognize this key. So it will be very difficult for him to figure out exactly what needs to be put into memory.
Audience: but if he can get the code, he can also use xor to turn the code back into instruction.
Professor:Yes, that is the canonical problem, right. This is somewhat similar to what happens during the BROP attacks , when we seem to have randomized the location of the code, but the attacker can “find” him and find out what is happening. One can imagine that, for example, if an attacker knows some sub-sequence of code that he expects to find in a binary file, then he will try to use the xor operation for this file in order to extract the key.
Essentially, we discussed all types of randomization attacks that I wanted to tell you about today. Before we proceed to programming, it is worth discussing the question of which of these methods of protection are used in practice. It turns out that both GCC and Visual Studio by default include the approachstack canaries . This is a very popular and very famous community. If you look at Linux and Windows, they also use such things as memory non-executable and address space randomization. True, the baggy bounds system is not so popular with them, probably because of the cost of memory, processor, false alarms, and so on, which we have already spoken about. So basically, we have examined how things are going with preventing the buffer overflow problem.
Now we talk about ROP, backward-oriented programming. Today I have already told you that it is in terms of randomizing the address space and preventing data from being executed - it is read, write and execute. In fact, these are very powerful things. Because randomization prevents the possibility that the attacker will understand where our hard-coded addresses are located. And the ability to prevent data from being executed ensures that even if you put the shell code on the stack, the attacker will not be able to just jump to it and execute it.
All this looks quite progressive, but hackers are constantly developing methods of attacking such progressive security solutions.
So what is the essence of reverse-oriented programming?
What if, instead of just creating a new code during an attack, an attacker could merge the existing pieces of code together and then merge them together in an abnormal manner? After all, we know that the program contains tons of such code.

So, fortunately, or unfortunately, it all depends on which side you are on. If you can find enough interesting code snippets and merge them together, then you can get something like the Turing language , where the attacker can essentially do whatever he wants.
Let's look at a very simple example, which at first will seem familiar to you, but then quickly turn into something crazy.
Suppose we have the following program. So, let us have some kind of function and, which is convenient for an attacker, here we have this nice function of the run shell . So this is just a call to the system, it will execute the bin / bash command and this will end. Next, we have a canonical buffer overflow process, or, sorry, a function that will announce the creation of a buffer, and then use one of these unsafe functions to fill the buffer with bytes.

So, we know that there is a buffer overflow without any problems. But what is interesting is that we have this run shell function , but it is difficult to get to it using methods based on buffer overflow. So how can an attacker invoke this run shell command ?
First of all, an attacker can disassemble a program, run GDB , and find out the address of this item in the executable file. You are probably familiar with these methods from lab work. Then, during a buffer overflow, an attacker can take this address, place it in the generated buffer overflow, and make sure that the function returns to the run shell .
To be clear, I'll draw it. So, you have a stack that looks like this: below there is an overflowed buffer, above it is a saved break pointer, above it is the return address for prosess_msg. From the bottom left we have a new stack pointer, which initiates the execution of the function, above it a new break pointer, then a stack pointer to be used, and even higher is the break pointer of the previous frame. It all looks pretty familiar.

As I said before, GDB was used during the attack to find out what the address of the run shell was . Thus, with a buffer overflow, we can simply put the address of the run shellright here on the right. In fact, this is a fairly simple extension of what we already know how to do. In essence, this means that if we have a command that starts the shell, and if we can disassemble the binary file to find out where this address is, we can simply put it into this flooded array located at the bottom of the stack. It is quite simple.
So, it was an extremely frivolous example, because the programmer, for some crazy reason, put this function here, thereby presenting the attacker with a real gift.
Now suppose that instead of calling this thing run_shell , we will call it run_boring , and then it will simply execute the command / bin / ls. However, we did not lose anything, because at the top we will have the string char * bash_path , which will show us the path to this bin / bash .

So the most interesting thing about this is that an attacker who wants to run ls can "parse" the program and find the location of run_boring , and this is not at all fun. But in fact, we have a line in memory that indicates the path of the shell, in addition, we know something else interesting. This is that even if the program does not call the system with the argument / bin / ls , it still makes some kind of call.
So, we know that the system should be somehow connected with this program - system (“/ bin / ls”). Therefore, we can use these two void operations to actually associate the system with this argument char * bash_path . The first thing we do is go to GDB and find out where this system (“/ bin / ls”) is in the image of the binary process. So, you just go to GDB , just type print_system and get information about its offset. It's pretty simple, and you can do the same for bash_path . So you simply use GDB to find out where this thing lives.
Once you are done, you need to do something else. Because now we really have to somehow figure out how to call the system with the help of the argument that we chose. And the way we do this is essentially to falsify the calling frame for the system. If you remember, a frame is what the compiler and hardware both use to make a stack call.
We want to organize on the stack something like what I depicted in this drawing. In fact, we're going to fake a system that should have been on the stack, but right before it actually executes its code.
So, here we have the system argument, this is the string we want to execute. At the bottom we have a line where the system should return to when the mentioned line with the argument is executed. The system expects the stack to look just like that just before the execution begins.

We used to assume that there are no arguments when you pass a function, but now it looks a little different. We just have to make sure the argument is in the overflow code that we create. We just have to make sure that this fake calling frame is in this array. Thus, our work will be as follows. Recall that the stack overflow goes from bottom to top.

First, we are going to put the system address here. And on top we will post some junk return address junk return address . This is the place where the system will return after it is finished. This address will be a random collection of bytes. Above it, we place the address bash_path . What happens when the buffer overflows now?
After prosess_msg reaches the finish line, he will say: “OK, here is the place where I should return”! The system code continues to execute, it moves higher and sees the fake call frame we created. For the system, nothing amazing will happen, she will say: “Yeah, here it is, the argument that I want to perform is bin / bash", She performs it, and you're done - the attacker has captured the shell!
What have we done now? We took advantage of the knowledge of the calling agreement, the calling convention , as a platform for creating fake stack frames, or fake frame names, I would say. Using this fake calling frame , we can perform any function that is referenced and which is already defined by the application.
The next question we have to ask is: what if the program does not have this line char * bash_path at all ? I note that this line is almost always present in the program. However, suppose that we live in an inverted world, and there it is still not there. So what could we do to put this line into a program?
The first thing to do is to specify the correct address for bash_path , placing it higher, in this compartment of our stack, inserting three elements, each of which is 4 bytes in size:
/ 0
/ pat
/ bin

But in any case, our pointer comes here and - boom! - It is done. So you can now invoke the arguments by simply placing them in the shell code. Awful, isn't it? And all this is built up before the full BROP attack. But before you point to the full BROPattack, you have to understand how you just hook together things that already exist inside the code. When I place this waste return address here, we just want to access the shell. But if you are an attacker, you could send this return address, or return address, to something that could really be used. And if you did this, you could string several functions in a row in a row, several features of the function in a row. This is really a very powerful option.
Because if we just set the return address for the jump, then after that the program usually crashes, which we maybe don’t want. Therefore, it is worth linking together some of these things in order to do more interesting things with the program.
Suppose our goal is that we want to call the system an arbitrary number of times. We don't just want to do it once, we will do it any number of times. So how can this be done?
For this we use two pieces of information that we already know how to get. We know how to get the address of the system - you just need to look at GDB and find it there. We also know how to find the address of this line, bin / bash . Now, to initiate this attack using several calls to the system, we need to use gadgets. This brings us closer to what is happening in BROP .
So what we need now is to find the address of these two code operations: pop% eax and ret. The first one removes the top of the stack and places it in the eax register , and the second places it in the eip instruction pointer . This is what we call a gadget. It looks like a small set of assembly instructions that an attacker can use to build more ambitious attacks.
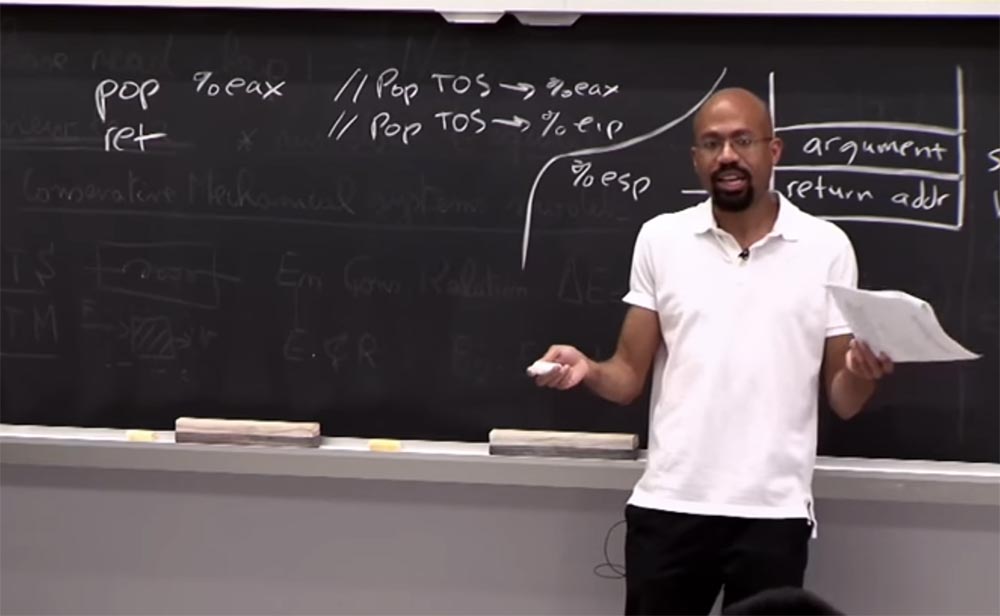
Such gadgets are standard tools that hackers use to find things like binary files. It’s also easy to find one of these gadgets, assuming that you have a copy of a binary file, and we didn’t bother with randomization. These things are very easy to find, as well as very easy to find the address of the system and stuff like that.
So, if we have one of these gadgets, why can we use it? Of course, to cause evil! To do this, you can do the following.
Suppose we change our stack so that it will look like this, the exploit, as before, is directed upwards. The first thing we do is locate the system address here, and above it put the address of the gadget pop / ret . Even higher, we will put the address of bash_path , and then we will repeat everything: from above we will again place the address of the system, the address of the gadget pop / ret and the address of bash_path .

What will happen here now? It will be a little difficult, so the notes of this lecture are available on the Internet, but for now you can just listen to what is happening here, but when I first understood this, it was like understanding that Santa Claus does not exist!
We begin here this place, where there is a record entry , go back to a system where the instruction ret going to remove an item from the stack with the command pop , so that now the top of the stack pointer is located here. So, we remove the element with pop , then ret returns the ret procedure , which transfers control to the return address selected from the stack, and this return address is placed there with the call command. So, we again make a call to the system, and this process can be repeated again and again.
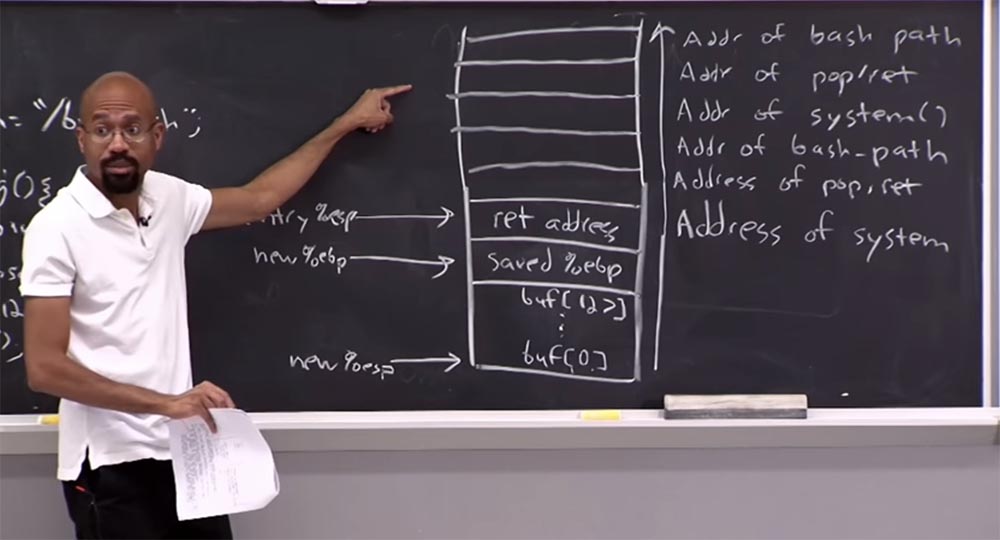
It is clear that we can link this sequence to perform an arbitrary number of things. In essence, the kernel gets what is called reverse-oriented programming. Notice that we didn’t do anything in this stack. We did what allowed us to prevent the execution of data without destroying anything. We just made some sort of unexpected jumps to do what we want. In fact, it is very, very, very, smart.
And what is interesting is that at a high level we have defined this new model for calculations. In a traditional, non-malicious program, you have an instruction pointer that points to some linear sequence of instructions. And you increase the instruction pointer to figure out what to do next. Essentially, reverse-oriented programming uses the stack pointer as an instruction pointer. When we move the stack pointer, we point it to other blocks of code that we are going to execute. But then at the end of the gadget, we return again to the stack pointer, which shows the next block of code to execute. This way you can prevent things that are undesirable for us. This shows how to get around this non-executable bit on the pages. So the next thing we want to dostack canaries.
If you remember, this “canary” was what we were going to push onto the stack. Thus, it is possible to imagine that the canary will be placed in the ret address or saved% ebp , and this will prevent someone from redefining the return address without suppressing the canary. It can be assumed that before the system jumps to the ret address , it can check if the canary had changed before that, that is, if something bad had happened. This is how stack canaries works .
Let's think about how to get around the canary. To do this, we need to make a few assumptions about how the system works. So, how do we beat this canary?
The first thing we can assume is that the server has a buffer overflow vulnerability.
The second thing we can assume is that the server will “crash” and reboot if we set the “bad” value to canary.
And the third thing we are going to assume is that after the reboot, the canary and any random address space we made will not be re-randomized.
Therefore, we assume that if we can somehow break the server, then after it is restarted, the canary will retain its value and all the randomly distributed address space, the heap and code will also be located in the original places. You may wonder why this is so? Why, after a reboot, the server does not create a new location for these things?
The reason is that most servers are written using fork to create new processes. If you remember, fork actually inherits the parent address space. This is a copy of the written pages that change the content, if the heir updates it, but if you use fork here , instead of executing the whole new process, each time the parent server process forms new heirs, they will have the same canary values in the database addresses. This is what the assumptions are about, with the help of which we are going to defeat stack canaries .
So how can we beat the canary? In fact, the attack is quite simple. Imagine that the stack grows upwards, we have an overflow of the buffer located below the canary. Usually a canary consists of several bytes. So you can start exploring these bytes one by one and try to guess their meaning.

Suppose the stack looks like the one shown in the figure — a buffer overflow occurs at the bottom, and the top of the canary string is located above. You start guessing the value in these lines from the bottom up, for example, in the bottom line let it be 0. If you did not guess, the server will “fall” as soon as the overflow touches this line. If this does not happen, you will say:
“Aha, I guessed the meaning of the first byte of the canary! Continue guessing further and assume that the second byte is also equal to 0. The server has "fallen"! We substitute 1 - again "fell", we substitute 2 - everything is in order. Great, you guessed the value of the 2nd byte. Thus, you can pick up all the values of the bytes that make up the "canary".

A server crash tells the attacker that he was wrong, and continuing to work indicates that he correctly guessed the value.
If you know the exact location of the canary, then overflowing the buffer, you can quickly destroy it, without resorting to the selection of values. However, the problem is that if the address space is randomly located, the hacker does not know in advance where the “canary” is located in the stack.
57:10 min.
Continuation:
MIT course "Computer Systems Security". Lecture 3: "Buffer overflow: exploits and protection", part 3
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read aboutКак построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?