Life in the era of "dark" silicon. Part 2

Other parts: Part 1 . Part 3 . .
This post is a continuation of the story "Life in the era of" dark "silicon . " The previous part talked about what “dark” silicon is and why it appeared. Two of the four main approaches that allow microelectronics to flourish in the era of "dark" silicon were also considered. It was told about the role of new discoveries in the field of production technology, about how to increase energy efficiency due to parallelism, and also, why a decrease in the area of the processor chip seems unlikely. This time around, the next approach is on the agenda.
“The Dim Horseman” or energy and temperature management.
“We will fill the chip with homogeneous cores
that would exceed the power budget
but we will underclock them (spatial dimming),
or use them all only in bursts (temporal dimming)
...“ dim silicon ”.
Since a reduction in the crystal area is unlikely, we will consider how to effectively use the "dark" regions of silicon. Here, the developers have a choice: to use general or special purpose logic? This time we will consider a variant of universal logic, busy with work only a small part of the time, and which can be used for a wide range of tasks. For logic that used on most of the time running at lower frequencies, the term "dim» (dim) silicon. [1]
Consider several design methods associated with the use of "dull" silicon.
Near-Threshold Voltage processors. One of the recent approaches is the use of logic operating at low voltage levels close to the threshold (Near-Threshold Voltage, NTV) [2]. The logic operating in this mode, although losing in absolute terms of performance, but gives the best performance per unit of power consumption.
In the previous part, this idea was considered using one comparator as an example. If we talk about its larger uses, recently NTV implementations of SIMD processors have attracted attention [3]. SIMD is the most successful form of concurrency for this approach. Also studied multi-core [4] and x86 (IA32) [5] NTV processors.
The performance of NTV processors drops faster than the corresponding energy savings in one operation. For example, an 8x performance drop with a 40x overall reduction in power consumption or a 5x decrease in each operation. Loss of performance can be compensated by using a larger number of parallel processors. But this will be effective, only assuming perfect parallelization, which is more consistent with SIMD than other architectures.
Going back to Moore's Law, NTV to offer a 5x increase in performance, while maintaining the same power consumption, but using 40 times b of greater area (approximately eleven generations of process technology).
Using NTV creates a variety of technical issues. One of these problems is an increase in the sensitivity of the circuit to variations in the process parameters. The lithography process consists of applying multiple layers of topology to the silicon surface ( alloying ). But the thickness and width of the lines in the resulting layers may vary slightly, and this leads to a spread in the threshold voltage of the transistors. Reducing the operating voltage, we get a greater spread of frequencies at which transistors can operate. This creates a lot of inconvenience - usually SIMD uses tightly synchronized parallel blocks, which is difficult to achieve in such conditions.
There are other problems, for example, the difficulty of creating SRAM memory operating at lower voltages.
Cache increase. An often suggested alternative is to simply use dark areas of silicon to place the cache. After all, you can easily imagine the growth of the cache at a speed of 1.4-2x for each generation of the process technology. A larger cache for tasks with frequent cache misses can improve both performance and economy - accessing memory outside the chip requires a lot of energy. The frequency of cache misses mainly determines the expediency of increasing the cache. According to a recent study, the optimal cache size is determined by the point where system performance is no longer limited by bandwidth and becomes limited by power consumption. [6]
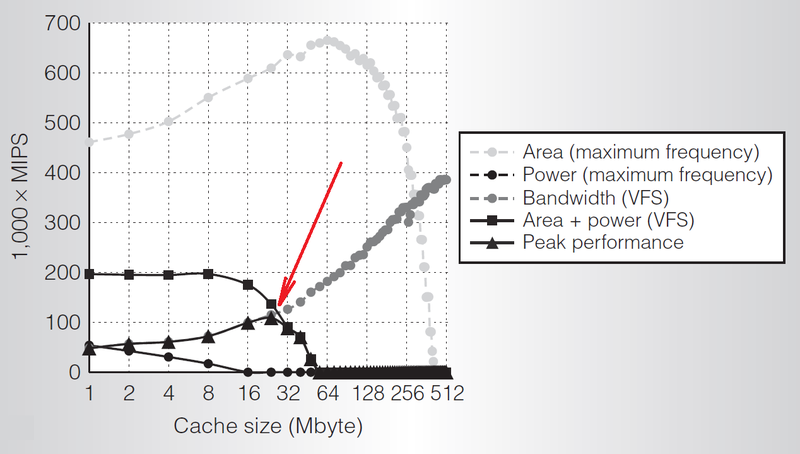
Dependence of performance on cache size under various restrictions
However, non-chip memory interfaces are becoming more energy efficient, and 3D memory integration speeds up access to it. This is likely to reduce future gains from large cache sizes.
Coarse-Grained Reconfigurable Arrays.Using reconfigurable logic is not a new idea. But its use at the bit level, as occurs in FPGA, is associated with high overhead power consumption. The most promising option is the use of coarse-grained reconfigurable arrays (Coarse-Grained Reconfigurable Arrays, CGRAs). Such arrays are configured to perform an operation on a whole word. The idea is to place the logic elements in the order corresponding to the natural order of calculations, which reduces the length of the signal links and the costs associated with multiple multiplexing of communication lines. [7] In addition, the CGRA duty cycle is very small, most of the time its logic is inactive, which makes it attractive for use as a “dull” logic.
Research in the field of CGRA has been carried out before, they continue now, in the era of dark silicon. The commercial success of the technology was very limited, but new issues often force us to take a fresh look at old ideas. :)
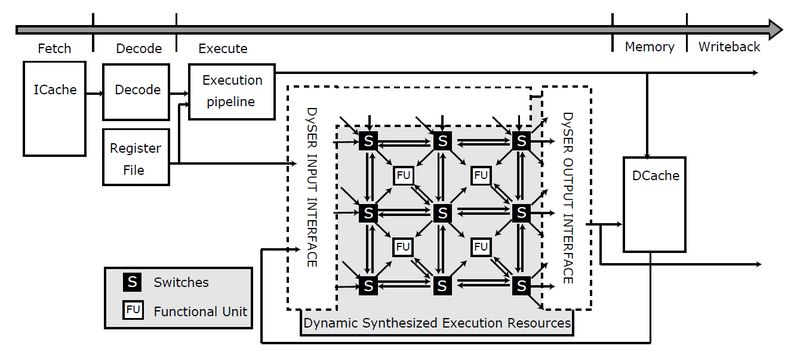
Using reconfigurable arrays as part of the
Computational Sprinting processor and Turbo Boost.The approaches described above used spatial dimming of silicon, when some area of the logic is designed so that it runs at very low frequencies all the time or for the most part is idle. But there are a number of methods based on temporary dimming of silicon. For example, a processor can provide a short (<1 min.), But a substantial increase in performance by increasing the clock speed. At the same time, the thermal budget is temporarily exceeded (~ 1.2-1.3 TDP), but the calculation is made on the thermal capacity of the chip and the radiator, as a means of increasing the temperature. After some time, the frequency returns to its original value, allowing the radiator to cool. Turbo Boost technology [8] uses exactly this approach to increase productivity at the right time.
Computational sprinting, and with it the Turbo Boost 2.0 version, takes a step forward compared to the original idea, allowing you to get a much larger (~ 10x) performance increase, but only for a split second.

And now a little practice, so as not to be unfounded . What can be achieved in modern processors using these and other approaches. Effectively using a variety of methods of both spatial and temporal dimming, energy consumption can vary by more than 50 times depending on the load.
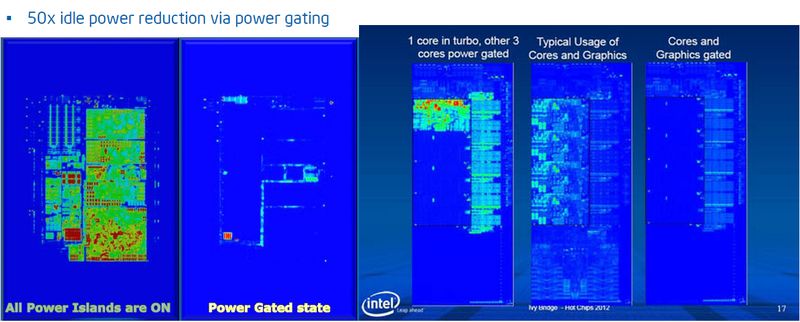
Infrared images of processors in various power configurations
However, the system providing this is very, very complex. In addition to the corresponding design solutions, the microprocessor contains a lot of temperature sensors (red dots on the right side of the figure). For example, in Sandy Bridge, there are 12 sensors for each processor core, and a considerable number of them are located outside the processor cores. In addition, the processor includes a specialized unit (PCU - Package Control Unit), which runs firmware that controls power consumption. At the same time, the readings of temperature sensors are used not only for temperature control, but also, for example, to estimate leakage currents, and the PCU has an interface for communicating with the outside world, which allows the operating system and user applications to monitor data and manage energy consumption.

Also interesting is the following feature of multi-core processors. At light load, redundant processor cores can be turned off to save energy. But Uncore (the part of the processor that does not include processor cores - a communication factory, shared cache, memory controller, etc.) cannot be disabled, because This will completely stop the processor. At the same time, the power consumption of Uncore is comparable to the power consumption of several processor cores.

Uncore
Desired energy savings can be achieved by controlling the Uncore clock speed. In the case when the frequency is higher than necessary (point 1), Uncore performance requirements are fully met, but energy is wasted and the frequency can be reduced without sacrificing performance. In the case when the frequency is lower than necessary (point 2), performance suffers and the frequency should be increased. Our goal is to find the optimal point for the current load (point 3) and maintain it. This is not easy, because for efficient operation, performance requirements must be predicted and the clock frequency changed in advance.
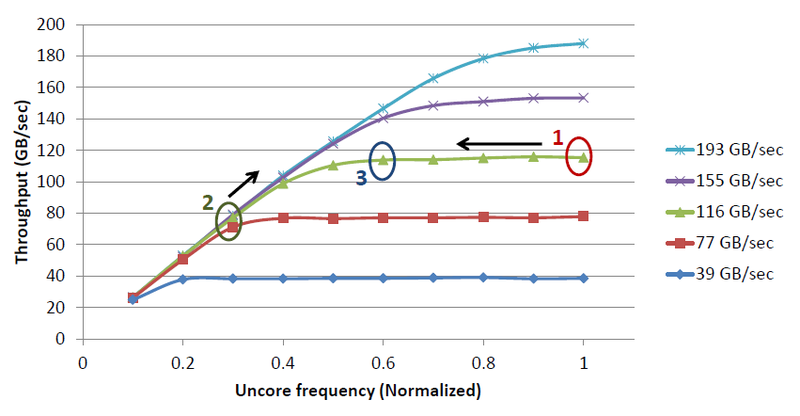
Uncore performance curves from clock speed at different loads
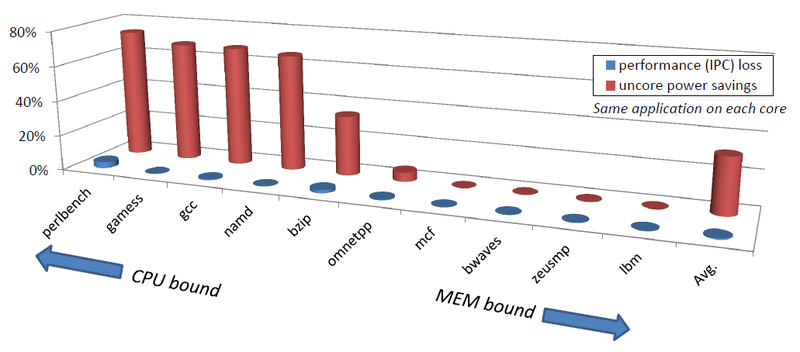
Loss of performance and energy savings for various tasks
Various Uncore frequency control algorithms can achieve, for example, 31% energy savings, losing only 0.6% of performance, or 73% savings due to 3.5% of performance, respectively.
To be continued .
Sources
1. W. Huang, K. Rajamani, M. Stan, and K. Skadron. ”Scaling with design constraints: Predicting the future of big chips." IEEE Micro, july-aug. 2011.
2. R. Dreslinski et al " Near-threshold computing: Reclaiming moore's law through energy efficient integrated circuits. " Proceedings of the IEEE, Feb. 2010.
3. Hsu, Agarwal, Anders et al. “A 280mv-to-1.2v 256b reconfigurable simd vector permutation engine with 2-dimensional shuffle in 22nm cmos." In ISSCC, Feb. 2012.
4. D. Fick et al. “Centip3de: A 3930 dmips / w configurable near- threshold 3d stacked system with 64 arm cortex-m3 cores. " In ISSCC, Feb. 2012.
5. Jain, Khare, Yada et al. “A 280mv-to-1.2v wide-operating-range ia-32 processor in 32nm cmos." In ISSCC, Feb. 2012.
6. N. Hardavellaset al. “Toward dark silicon in servers.” IEEE Micro, 2011.
7. V. Govindaraju, C.-H. Ho, and K. Sankaralingam. “Dynamically specialized datapaths for energy efficient computing." In HPCA, 2011.
8. E. Rotem. ”Power management architecture of the 2nd generation Intel core microarchitecture, formerly codenamed sandy bridge." In Proceedings of Hotchips, 2011.