How did I roll back the system a month ago and return everything? Experience using ESXi. Or how not to do
Hello. This may seem to someone an instructive history of how not to do and why some important technical work at one o'clock (in a system in which you do not understand much) can lead to a huge collapse and downtime for two days.

A small note-story of an amateur system administrator who is just beginning to dive into the world of virtualization. The story of how snapshots did not help, but prevented and rolled back the system for a month, and then I downed out all the files from there in 2 days and returned the system.
Prehistory
After two years of sitting on nixsystems, and in particular on the ubuntu server (16.04 LTS), I decided to try myself in virtualization. An acquaintance advised ESXi as a free solution for small servers (my case: 1 processor + 8 GB RAM in total). The process of moving was complicated by the fact that it was necessary first to raise the vmware workstation together with the vmware converter on a windows-computer, transfer the finished system there, then esxi on the server and then transfer the system to esxi after a familiar converter. Here is such a long and painful path. The main error in the transfer, which I made and which still sounds to me, is that I used a thin-disk. That is, being on a clean ubuntu server with a disk formatted in exfat-4, I had somewhere 223.8 GB of space on ssd. Moving to esxi and formatting the disk in their incomprehensible format, I lost only 300 MB,
Start
I used to break firewood with a ubuntu server (when I “studied” it), rolling back and reinstalling the system once a month or two. Now I break wood with ESXi. I think the problem of thin-disks is not necessary to describe (if briefly, they do not “narrow” it in the opposite direction after expanding their space. They can also go beyond the physical amount of disk memory). Firstly, I used swap on the same ssd disk, without having configured it properly in ESXi. He ate memory, wrote some temporary files there, while thin grew.
Secondly, for some reason I made snapshots. At that moment I was guided by the fact that "well, this is convenient, fast, and all that." Still not knowing what kind of bjaku and what slow bomb they laid to me. Thirdly, I did not follow the rapidly decreasing amount of disk memory.

Outset
The first bell was the main machine stop on July 17th. I received a notification in the mail about the fall of the host. Going to esxi to raise it (well, suddenly something could happen), the virtual machine gave me a good news (there is no screenshot, unfortunately). The free retelling of the pop-up window was like this: “Sorry, disk space is over. Your virtual machine is stopped. Clean the place and you can continue to use the VM. Repeat Cancel. At that time, the problem was solved by removing the second VM, which occupied about 16GB. But it was a temporary solution, as every day somewhere 5GB still disappeared somewhere, although there was no increase in these files in the system.
As a result, on July 19 in the evening of cool Thursday, I first wrote to the toaster about this problem. There was no answer. I think this is because of the unpopular esxi tag. After unsuccessful googling, after - removal of snapshots. At this point, 5 gigabytes disappeared, free-space became more, but not so much to forget about this problem.
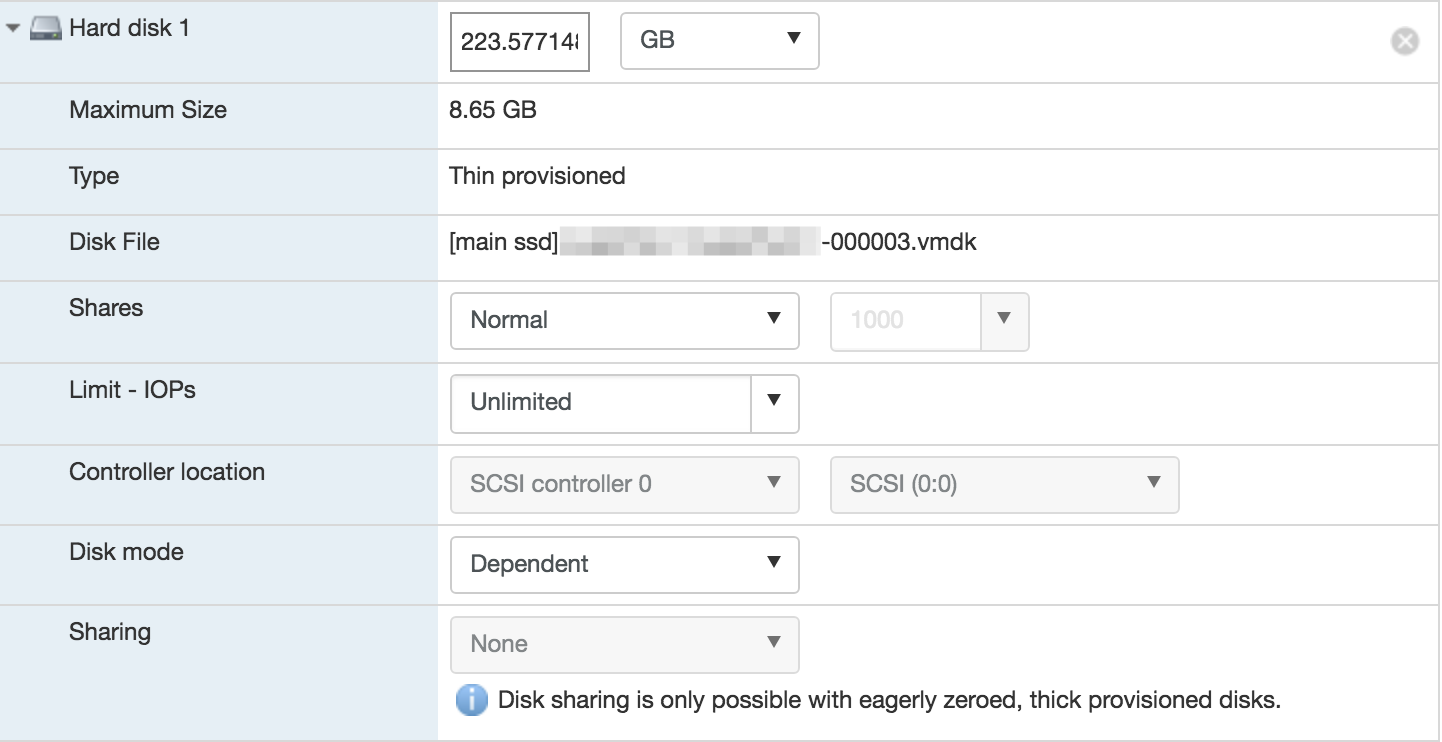
After, having thought hard, I began to study the hierarchy of snapshots. The last one, 000003, occupied 12GB of space at that time. In the VM settings, it was listed as the active disk file from which the machine was loaded. Without thinking twice, I deleted the hard disk 1 disk file with the active snapshot disk and in its place inserted the parent-disk of the entire virtual machine.
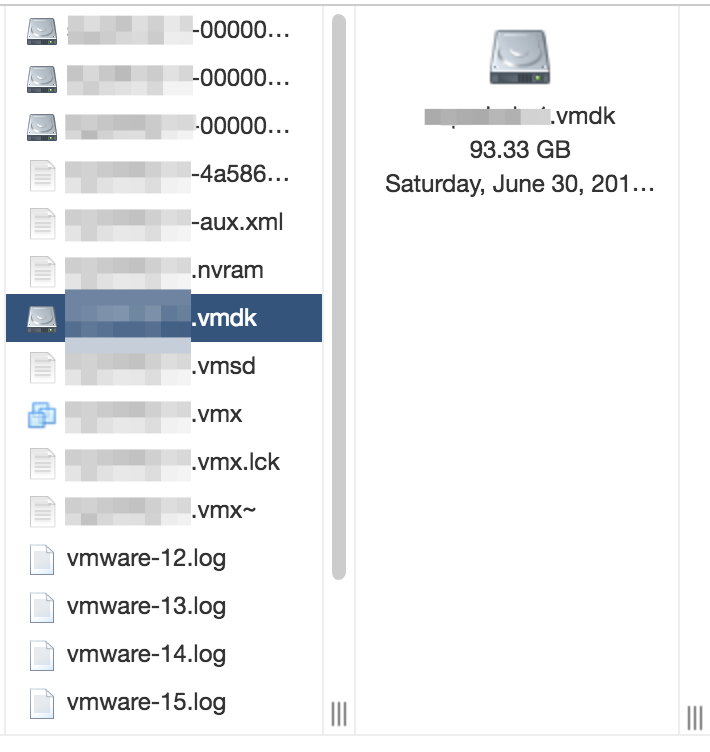
The system booted (hurray), and with it the files for June 30th. Last modified date for all files on parent disk. I suspect it was on this day that I created the first snapshot. Places, which is logical, did not increase. In the free-space is still about 5GB, and the files are gone.
The first thoughts are logical: what I have done, all files have evaporated until July 19. Then I saw that the snapshot files were not deleted. However, when trying to download them as the main disk, ESXi swore at the changed parent-disk, which should not be “My parent virtual disk has been modified since my child was created” for the next two days.
Googling
The time approached two o'clock at night, and I left all the vain attempts to get at least some information from these unfortunate * -0000? -. Vmdk snapshots files.
Friday morning began with active, really active googling like “how to pull files out of vmdk”. Articles, Linux reader (windows program) and everything like that came across very often. I transferred these 223 gigabytes from the server to the windows-laptop over a 100 Mbps channel, which was very painful. I tried to mount a vmware format ssd disk to a linux system, roll vmware-tools onto it, it cursed version incompatibility (the last one supported was 5, and I had 6.5). Attempts to open through windows and java, too, were in vain.
And even after I managed to access (using the Linux reader program on windows) the file * -flat.vmdk, I received the files only until June 30th. All further attempts to mount the snapshot files did not give anything, the program swore at the invalid disk and refused to work further.
Output found
Friday was over, I was exhausted, and also upset that the files could not be returned. But Saturday began successfully. For buggy errors (why I didn’t do it right away - unknown) "The parent virtual disk has been modified since the child was created" in the very first line of Google issued a link to the vmware page. A bunch of scary characters, red lines and everything like that immediately scared. I opened the link and left it in the hope that I would find something more understandable.
And it was found. https://communities.vmware.com/thread/323730 Russian-language VmWare forum and a similar problem met me on the Internet. Probably, this is not the same case as mine, but after squandering down and reading the comments, I tried to do this.
In a text editor, having connected to esxi via SFT, I opened the file with the settings of the parent disk. .vmdk (not -flat.vmdk) I recognized the CID of the disk, and then got into * -00001.vmdk, doing as described by the apavlyuchenko user on the forum.
In the first snapshot in the CID and parentCID fields, it was worthwhile to specify the CID of the parent disk. And then in the .vmx
file in the fields
scsi0: 1.present = "false"
scsi0: 1.fileName = " .vmdk"
scsi0: 1.deviceType = "scsi-hardDisk"
change the FALSE parameter to TRUE and .vmdk to -00001. vmdk.
And indeed, after that the car was loaded and did not swear at the error anymore. And lo and behold! Files appeared before creating the second snapshot!
At the forum, a friend described a way to recover files from just one snapshot. But my case is difficult (apparently because of my illness, which is called “poking everything with your hands on the working machine”). And I had not one snapshot, but three. Which is logical, it was necessary to continue to change files.
So my actions.
Open the parent disk. We recognize his CID. Next, copy the CID of the parent disk to the parentCID line of the -00001.vmdk disk (first snapshot). In the same place, we look at the CID of this snapshot and copy it to the string parentCID of the -00002.vmdk disk (second snapshot). There we look at the CID of this snapshot and copy it to the parentCID line of the -00003.vmdk (third snapshot) disk , well, and then we climb into .vmx and in the fileName line specify the name of the snapshot file (in my case * -0003.vmdk)
The result was the following.
* .vmdk
CID = 387edddf
parentCID = ffffffff
* -00001.vmdk
CID = 0284jf712 (I took all the CIDs from bold)
parentCID = 387edddf
* -00002.vmdk
CID = 732fhhtud
parentCID = 0284jf712
* -00003.vmdk
CID = 3747jfj4ff
parentCID = 732fhhtud
.vmx
scsi0: 1.present = "true"
scsi0: 1.fileName = " -00003.vmdk"
scsi0: 1.deviceType = "scsi-hardDisk"
I turn on the VM, I see that the data has been restored. It seems to let go. I copy everything to another server, stop the machine (it is already screaming about the malfunction of the disks and some other critical problems), return the * .vmx settings back and copy the files back to the working machine. Hooray.
Conclusion
This story has taught me several golden truths that have never been understood before.
First, backup everything always and everywhere and not on the disk inside the virtual machine, as I did before. It is necessary to have one or even two backup drives so that there is no such two-day idle time. (deleted files? We roll back, copy files from backup, and idle time - not 48 hours, but 2 hours from strength) Secondly, not to do anything on a heavy head at one in the morning (go to sleep, I would come with a clean head on Friday would be to another exit, and not broke the wood in the second hour of the night) Third, do not make any important amendments to the working machines. Roll up the second virtual machine, make a snapshot there, then make the parent disk the main one and see what happens after that - that’s how it should have been done. And fourth, make even more backups. Not just the VM, but the esxi itself as a whole.
PS resources that helped me in the end:
The very forum with amazing apavlyuchenko (we are not familiar, if that)
A vmvare knowledge base page describing my problem and how to solve it
if anyone is interested, I can leave in the comments those resources whose articles did not help me
Pss
Unfortunately, the problem of the disappearance of the place is still relevant. If you have a thought or desire to help me deal with this, please comment. We can talk about it there. Or if you know another way to restore files from snapshots disks and also want to share them, then it will be interesting for me to read this. thank