How we automated testing applications on canvas
My colleagues have already written about developing TeamLab online editors on canvas. Today we look at the workflow through the eyes of testing experts, because not only the product from the point of view of the developers was innovative due to the chosen technology, but the task of checking the quality of the product turned out to be a new one that has not yet been solved by anyone.

The last 8 months of my life, my colleagues and I spent testing a completely new document editor written in HTML5. Testing innovative products is difficult, if only because no one has done this before.
To implement all our ideas, we needed third-party tools:
And then it started the most important and interesting. Click on the button and enter the text is quite simple, but how to verify what was created? How to check that everything performed by automatic tests is done correctly?
Many copies were broken in the process of finding the right method of comparison with the standard. As a result, we came to the conclusion that information on the actions performed and, accordingly, on the success of passing the tests can be obtained in two ways:
1. Using the API of the application itself.
2. Using your own document parser.
Positive sides:
Negative sides:
Positive sides:
Negative sides:
As a result, we chose both options, but used them in different proportions: about 90% of the test verification was implemented using the parser and only 10% - through the API. This allowed us to quickly write the first tests using the API and gradually develop functional tests in conjunction with the development of the parser.
DOCX was chosen as the format for parsing. This is due to the fact that:
We could not find a third-party library for parsing DOCX, which would support the set of functions we needed. Subsequently, a similar situation developed with a different format, when testing the table editor we needed the XLSX parser.
Only one specialist is responsible for the parser. The main backbone of the functional was implemented in about a month, but it is still constantly supported - bugs are fixed (which, by the way, there are almost none left for the existing functional), and support is added for the new functional introduced in the document editor.
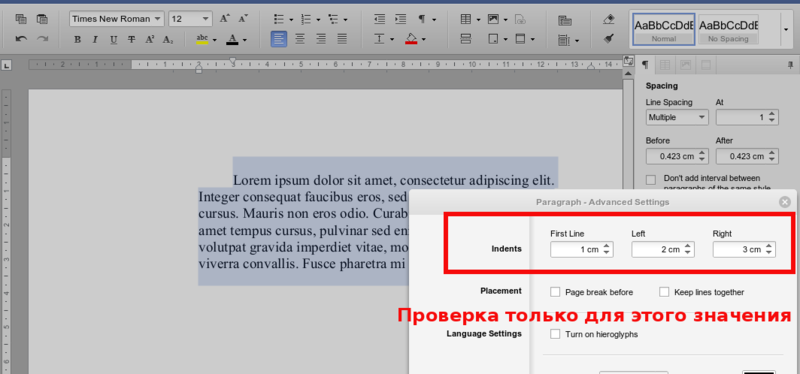
Example:
Consider a simple example: a single paragraph document with a text size of 20, the Times New Roman font and the Bold and Italic options set. For such a document, the parser will return the structure below:

The document consists of a set of elements (elements) - these can be paragraphs of text, images, tables.
Each paragraph consists of several character_styles - pieces of text with completely identical properties in a given section. Thus, if in one paragraph all the text is typed in one style, then there will be only one character_style in it. If, for example, the first word of the paragraph is highlighted in bold and the rest is in italics, then the paragraph will consist of two character_style: one for the first word, the second for all the others.
Inside character_style are all the necessary text properties, such as size = 20 - font size, font = "Times New Roman" - font type, font_style - a class with font style properties (Bold, Italic, Underlined, Strikeout), as well as all other properties document.
As a result, in order to verify this document, we should write this code:
doc.elements.first.character_styles_array.first.size.should == 20
doc.elements.first.character_styles_array.first.font.should == "Times New Roman "
doc.elements.first.character_styles_array.first.font_style.should == FontStyle.new (true, true, false, false)
In order to have a representative selection of files in the DOCX format, it was decided that you also need to write a DOCX file generator - an application that would allow you to create documents with arbitrary contents and with arbitrary parameter values. For this, one specialist was also allocated. The generator was not considered as a key part of the testing system, but rather as a kind of auxiliary utility that would allow us to increase test coverage.
Based on its development, the following conclusions were made:
When creating or automating tests, do not try to cover all possible format functionality at once. This will create additional difficulties, especially at an early stage of development of the application under test.
It is difficult to distinguish incorrect results from tests whose functionality is not yet supported by the application.
And as a consequence of the previous paragraphs: writing a generator should be closer to the end of the development of the test application (and not at the beginning, as we did), when the maximum number of functions in the editor will be implemented.
Despite the above, the generator made it possible to find errors that were almost impossible to find during manual testing, for example, incorrect processing of parameters whose values are not included in the set of permissible ones.
As a basis for the framework was taken Selenium Webdriver. On Ruby there is a great alternative for it - Watir, but it so happened that at the time of the creation of the framework we did not know about it. The only time we regretted not using Watir was when integrating the tests into the most beloved and best browser - IE. Selenium simply refused to click on the buttons and do anything, in the end I had to write a crutch so that in the case of running tests on IE, the Watir methods would be called.
Prior to the development of this framework, testing of web applications was built in Java, and all XPath elements and other object identifiers were moved to a separate xml file so that when changing XPath it was not necessary to recompile the entire project.
Ruby could not have such a problem with recompilation, therefore, already in our next automation project, we abandoned a single XML file.
Functions in Selenium Webdriver were overloaded, because you had to work with a file containing 1200 xPath elements. We recycled them:
It was
Has become
In our opinion, it is very important, before starting automation, to analyze the identifiers of objects on the page, and if you can see that they are generated automatically (id like "docmenu-1125"), be sure to ask developers to add id that will not change, otherwise will have to redo XPath with every new build.
More specific functions have been added to the SeleniumCommands class. Some of them were already present in Watir by default, but then we did not know this yet, for example, clicking on the serial number of one of several elements, receiving one attribute from several elements at once. It is important that only one testing specialist is allowed to work with such a key class as SeleniumCommands, otherwise, even an insignificant error occurs, the whole project may fall, and, of course, this will happen exactly when you need to quickly run all the tests.
A higher level of framework is working with the program menu, application interface. This is a very large (about 300) set of functions distributed over classes. Each of them implements a certain function in the interface that is available to the user (for example, font selection, line spacing, etc.).
All these functions have the most simple descriptive names and take arguments in the simplest form (for example, when it is possible to pass not just any class, but just String objects, you need to pass them). This makes writing tests much easier, so even manual testers without programming experience can handle it. This, by the way, is not a joke or an exaggeration: we have working tests written by a person who is completely zero in programming.
In the process of writing these functions, the first category of Smoke tests was created, the script of which for all functions looks like this:
1. A new document is created.
2. One (just one) written function is called, which is passed some specific correct value (not random, but specific and correct in order to discard at this step a functional that works correctly only on a part of possible values)
3. Download document
4 We verify
5. We enter the results into the reporting system
6. PROFIT!
So, to summarize, let's look at the categories of tests that are present in our project.
1. Smoke tests.
Their goal is to test the product on some small amount of input data and, most importantly, to verify that the Framework itself works correctly on the new build (have xPath elements been changed, have the logic for constructing the application interface menu changed?
This category of tests is good it works, but sometimes the tests freeze at incomprehensible moments in anticipation of some interface elements.When repeating the test script manually, it turned out that the tests were freezing due to errors in the menu interface, for example, when you click the open font list button with m list does not show up. So there was a second category of tests.
2. Interface Tests
This is a very simple set of tests whose task is to verify that when you click on all controls, an action occurs for which this control is responsible (at the interface level). That is, if we click on the Bold button, we do not check whether the selection worked in bold, we only check that the button began to appear as pressed. Similarly, we check that all drop-down menus and all lists open.

3. Enumerating all parameter values
For each parameter, all possible values are set (for example, all font sizes are searched), and then this is verified. Only one change of one parameter should be present in one document; no linkages are tested. Subsequently, another subcategory of tests appeared from these tests.
3.1 Visual Rendering Verification
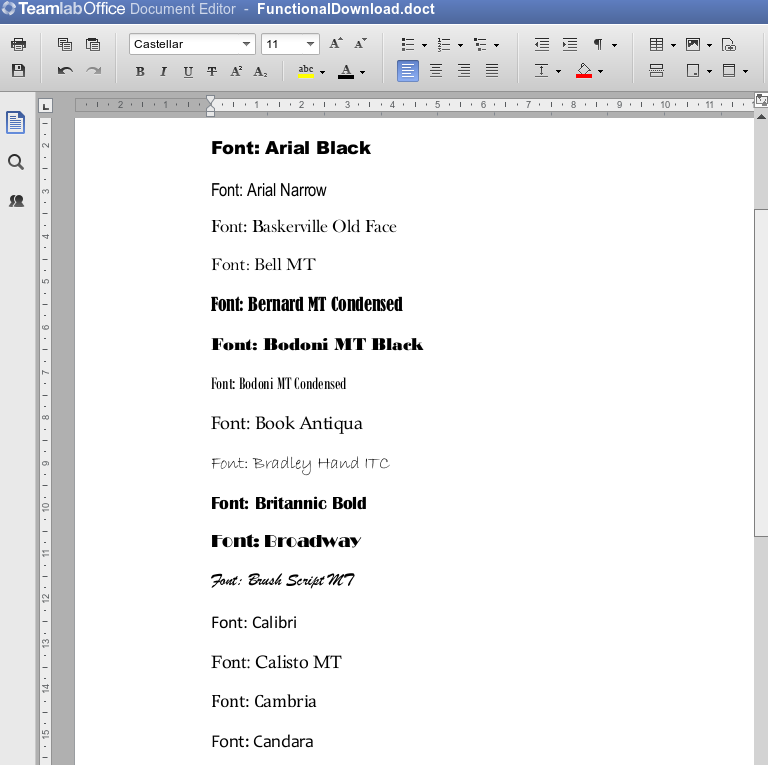
In the process of running tests to sort through all parameter values, we realized that it was necessary to verify the rendering of all parameter values visually. The test sets the parameter value (for example, the font is selected), takes a screenshot. At the output we have a group of screenshots (about 2 thousand) and a displeased handbrake who will have to watch a large slideshow.
Subsequently, we did the verification of the rendering using the system of standards, which allowed us to track the regression.
4. Functional tests
One of the most important categories of tests. Covers all the functionality of the application. For best results, scripting should be done by test designers.
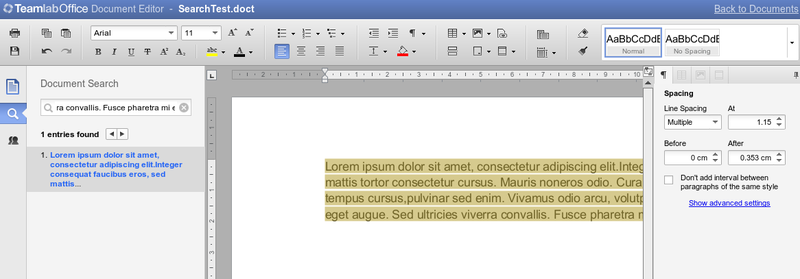
5. Pairwise
Tests for checking parameter bundles. For example, a full check of typefaces with all styles and sizes (two or more functions with parameters). Are generated automatically. They are launched very rarely due to their duration (at least 4-5 hours, some even longer).

6. Regular tests on a production server.
The latest category of tests that appeared after the first release. Basically, this is a check of the correct operation of the communication of components, namely the fact that files of all formats are opened for editing and correctly downloaded to all formats. Tests are short, but run twice a day.
At the beginning of the project, all reporting was collected manually. Tests were run directly from RubyMine from memory (or notes, comments in the code), it was determined whether the new build became worse or better than the previous one, and in words the results were passed to the testing manager.
But when the number of tests grew (which happened quickly enough), it became clear that this could not continue for long. The memory is not rubber, it is very inconvenient to keep a bunch of data on pieces of paper or manually enter it into an electronic tablet. Therefore, it was decided to choose Testrail as the reporting server , which is almost perfect for our task - to store reporting for each version of the editor.
Adding reporting occurs through the testrail API. At the beginning of each test on Rspec, a line is added that is responsible for initializing TestRun to Testrail. If a new test is written that is not yet present on Testrail, it is automatically added there. Upon completion of the test, the result is automatically determined and added to the database.
In fact, the entire reporting process is fully automated, you should only go to Testrail to get the result. It looks like this:

In conclusion, some statistics:
Project age - 1 year
Number of tests - about 2000
Number of completed cases - about 350 000
Team - 3 people
Number of bugs found - about 300
The last 8 months of my life, my colleagues and I spent testing a completely new document editor written in HTML5. Testing innovative products is difficult, if only because no one has done this before.
To implement all our ideas, we needed third-party tools:
- Ruby language for automation. It is scripted, works great with large amounts of data, and, I will not dissemble, had little experience working with it.
- Gem Rspec for test run
- Selenium Webdriver driver for working with browsers
1. Verification
Many copies were broken in the process of finding the right method of comparison with the standard. As a result, we came to the conclusion that information on the actions performed and, accordingly, on the success of passing the tests can be obtained in two ways:
1. Using the API of the application itself.
2. Using your own document parser.
API
Positive sides:
- Quick results, as there is no need for unnecessary access to the server when downloading documents.
- Ability to work directly with API functions. For us, this was the best solution - we work in a friendly climate with programmers, and they quickly provided us with these functions.
Negative sides:
- The lack of the ability to clearly localize the bug in the program, i.e. in the code of the editors or when calling / implementing the interface, i.e. in the interface code.
- Dependence on programmers. If the developers have such a situation that the API methods change a lot or stop working at all, the automatic testing process will also get up. But server-side API patching can be far from a priority (given that this is not a public API and is used only for tests).
- The inability to automate testing all the functionality in the existing application architecture.
Parsing a downloaded document
Positive sides:
- A reliable approach, because we will check the final result of the application.
- Independence from developers. We wrote the opening of the docx format with our tools, relatively speaking, created our own small document converter.
- The ability to implement tests of any difficulty level, as all the functionality existing in the application is supported.
Negative sides:
- Difficulty in implementation.
Final Verification
As a result, we chose both options, but used them in different proportions: about 90% of the test verification was implemented using the parser and only 10% - through the API. This allowed us to quickly write the first tests using the API and gradually develop functional tests in conjunction with the development of the parser.
DOCX was chosen as the format for parsing. This is due to the fact that:
- In the editor itself, support for the DOCX format was best implemented, the maximum number of functions was supported, and saving to it was carried out most qualitatively and reliably.
- The DOCX format itself, unlike the DOC, is more open and has a simpler structure. In essence, this is a ZIP archive with XML files.
We could not find a third-party library for parsing DOCX, which would support the set of functions we needed. Subsequently, a similar situation developed with a different format, when testing the table editor we needed the XLSX parser.
Only one specialist is responsible for the parser. The main backbone of the functional was implemented in about a month, but it is still constantly supported - bugs are fixed (which, by the way, there are almost none left for the existing functional), and support is added for the new functional introduced in the document editor.
Example:
Consider a simple example: a single paragraph document with a text size of 20, the Times New Roman font and the Bold and Italic options set. For such a document, the parser will return the structure below:
The document consists of a set of elements (elements) - these can be paragraphs of text, images, tables.
Each paragraph consists of several character_styles - pieces of text with completely identical properties in a given section. Thus, if in one paragraph all the text is typed in one style, then there will be only one character_style in it. If, for example, the first word of the paragraph is highlighted in bold and the rest is in italics, then the paragraph will consist of two character_style: one for the first word, the second for all the others.
Inside character_style are all the necessary text properties, such as size = 20 - font size, font = "Times New Roman" - font type, font_style - a class with font style properties (Bold, Italic, Underlined, Strikeout), as well as all other properties document.
As a result, in order to verify this document, we should write this code:
doc.elements.first.character_styles_array.first.size.should == 20
doc.elements.first.character_styles_array.first.font.should == "Times New Roman "
doc.elements.first.character_styles_array.first.font_style.should == FontStyle.new (true, true, false, false)
2. Document generator
In order to have a representative selection of files in the DOCX format, it was decided that you also need to write a DOCX file generator - an application that would allow you to create documents with arbitrary contents and with arbitrary parameter values. For this, one specialist was also allocated. The generator was not considered as a key part of the testing system, but rather as a kind of auxiliary utility that would allow us to increase test coverage.
Based on its development, the following conclusions were made:
When creating or automating tests, do not try to cover all possible format functionality at once. This will create additional difficulties, especially at an early stage of development of the application under test.
It is difficult to distinguish incorrect results from tests whose functionality is not yet supported by the application.
And as a consequence of the previous paragraphs: writing a generator should be closer to the end of the development of the test application (and not at the beginning, as we did), when the maximum number of functions in the editor will be implemented.
Despite the above, the generator made it possible to find errors that were almost impossible to find during manual testing, for example, incorrect processing of parameters whose values are not included in the set of permissible ones.
3. Framework for running tests
Interaction with Selenium
As a basis for the framework was taken Selenium Webdriver. On Ruby there is a great alternative for it - Watir, but it so happened that at the time of the creation of the framework we did not know about it. The only time we regretted not using Watir was when integrating the tests into the most beloved and best browser - IE. Selenium simply refused to click on the buttons and do anything, in the end I had to write a crutch so that in the case of running tests on IE, the Watir methods would be called.
Prior to the development of this framework, testing of web applications was built in Java, and all XPath elements and other object identifiers were moved to a separate xml file so that when changing XPath it was not necessary to recompile the entire project.
Ruby could not have such a problem with recompilation, therefore, already in our next automation project, we abandoned a single XML file.
Functions in Selenium Webdriver were overloaded, because you had to work with a file containing 1200 xPath elements. We recycled them:
It was
get_attribute(xpath, attribute)
@driver.find_element(:xpath, xpath_value)
attribute_value = element.attribute(attribute)
return attribute_value
end
get_attribute('//div/div/div[5]/span/div[3]', 'name')
Has become
get_attribute(xpath_name, attribute)
xpath_value =@@xpaths.get_value(xpath_name)
elementl = @driver.find_element(:xpath, xpath_value)
attribute_value = element.attribute(attribute)
return attribute_value
end
get_attribute('admin_user_name_xpath', 'name')
In our opinion, it is very important, before starting automation, to analyze the identifiers of objects on the page, and if you can see that they are generated automatically (id like "docmenu-1125"), be sure to ask developers to add id that will not change, otherwise will have to redo XPath with every new build.
More specific functions have been added to the SeleniumCommands class. Some of them were already present in Watir by default, but then we did not know this yet, for example, clicking on the serial number of one of several elements, receiving one attribute from several elements at once. It is important that only one testing specialist is allowed to work with such a key class as SeleniumCommands, otherwise, even an insignificant error occurs, the whole project may fall, and, of course, this will happen exactly when you need to quickly run all the tests.
Menu interaction
A higher level of framework is working with the program menu, application interface. This is a very large (about 300) set of functions distributed over classes. Each of them implements a certain function in the interface that is available to the user (for example, font selection, line spacing, etc.).
All these functions have the most simple descriptive names and take arguments in the simplest form (for example, when it is possible to pass not just any class, but just String objects, you need to pass them). This makes writing tests much easier, so even manual testers without programming experience can handle it. This, by the way, is not a joke or an exaggeration: we have working tests written by a person who is completely zero in programming.
In the process of writing these functions, the first category of Smoke tests was created, the script of which for all functions looks like this:
1. A new document is created.
2. One (just one) written function is called, which is passed some specific correct value (not random, but specific and correct in order to discard at this step a functional that works correctly only on a part of possible values)
3. Download document
4 We verify
5. We enter the results into the reporting system
6. PROFIT!
4. Tests
So, to summarize, let's look at the categories of tests that are present in our project.
1. Smoke tests.
Their goal is to test the product on some small amount of input data and, most importantly, to verify that the Framework itself works correctly on the new build (have xPath elements been changed, have the logic for constructing the application interface menu changed?
This category of tests is good it works, but sometimes the tests freeze at incomprehensible moments in anticipation of some interface elements.When repeating the test script manually, it turned out that the tests were freezing due to errors in the menu interface, for example, when you click the open font list button with m list does not show up. So there was a second category of tests.
2. Interface Tests
This is a very simple set of tests whose task is to verify that when you click on all controls, an action occurs for which this control is responsible (at the interface level). That is, if we click on the Bold button, we do not check whether the selection worked in bold, we only check that the button began to appear as pressed. Similarly, we check that all drop-down menus and all lists open.
3. Enumerating all parameter values
For each parameter, all possible values are set (for example, all font sizes are searched), and then this is verified. Only one change of one parameter should be present in one document; no linkages are tested. Subsequently, another subcategory of tests appeared from these tests.
3.1 Visual Rendering Verification
In the process of running tests to sort through all parameter values, we realized that it was necessary to verify the rendering of all parameter values visually. The test sets the parameter value (for example, the font is selected), takes a screenshot. At the output we have a group of screenshots (about 2 thousand) and a displeased handbrake who will have to watch a large slideshow.
Subsequently, we did the verification of the rendering using the system of standards, which allowed us to track the regression.
4. Functional tests
One of the most important categories of tests. Covers all the functionality of the application. For best results, scripting should be done by test designers.
5. Pairwise
Tests for checking parameter bundles. For example, a full check of typefaces with all styles and sizes (two or more functions with parameters). Are generated automatically. They are launched very rarely due to their duration (at least 4-5 hours, some even longer).
6. Regular tests on a production server.
The latest category of tests that appeared after the first release. Basically, this is a check of the correct operation of the communication of components, namely the fact that files of all formats are opened for editing and correctly downloaded to all formats. Tests are short, but run twice a day.
5. Reporting
At the beginning of the project, all reporting was collected manually. Tests were run directly from RubyMine from memory (or notes, comments in the code), it was determined whether the new build became worse or better than the previous one, and in words the results were passed to the testing manager.
But when the number of tests grew (which happened quickly enough), it became clear that this could not continue for long. The memory is not rubber, it is very inconvenient to keep a bunch of data on pieces of paper or manually enter it into an electronic tablet. Therefore, it was decided to choose Testrail as the reporting server , which is almost perfect for our task - to store reporting for each version of the editor.
Adding reporting occurs through the testrail API. At the beginning of each test on Rspec, a line is added that is responsible for initializing TestRun to Testrail. If a new test is written that is not yet present on Testrail, it is automatically added there. Upon completion of the test, the result is automatically determined and added to the database.
In fact, the entire reporting process is fully automated, you should only go to Testrail to get the result. It looks like this:
In conclusion, some statistics:
Project age - 1 year
Number of tests - about 2000
Number of completed cases - about 350 000
Team - 3 people
Number of bugs found - about 300